- The paper proposes a graph-based synthetic data method that significantly improves LLMs’ logical reasoning by structuring multi-hop tasks.
- It details a random walk algorithm to sample reasoning chains and transforms them with heuristic verbalizers for effective supervised fine-tuning.
- Experiments on CLUTRR and StepGame benchmarks demonstrate enhanced performance and accuracy in complex reasoning tasks for LLMs.
Enhancing Logical Reasoning in LLMs through Graph-based Synthetic Data
Introduction
The paper "Enhancing Logical Reasoning in LLMs through Graph-based Synthetic Data" (2409.12437) addresses the persistent challenges that LLMs face in logical reasoning tasks, particularly those requiring multi-hop reasoning. Despite advances in techniques such as post-training and prompting, LLMs often struggle with tasks that involve complex chains of logic and are sensitive to input variations. Prior works have attempted to address these issues by introducing synthetic data generated by more robust LLMs. However, the generation process lacks control and reliability, resulting in uncertain question quality and labels.
This paper proposes leveraging graph-based synthetic data to enhance LLMs' reasoning capabilities, aiming to overcome the barriers in generating effective synthetic reasoning signals. The approach is grounded in a random walk sampling algorithm that generates synthetic reasoning data in a structured form, which is then used for training LLMs, thereby improving their performance on complex reasoning tasks without degrading baseline performance on other benchmarks.
Methodology
The paper introduces a graph-based approach to improve logical reasoning in LLMs. The authors propose a method to represent reasoning tasks as relational graphs with nodes and edges, where multi-step reasoning can be captured as traversals in these graphs. The methodology encompasses:
- Relational Graph Construction: Logical reasoning tasks are abstracted into graphs where vertices represent entities, and edges denote relationships governed by logical rules. This graph serves as the basis for generating reasoning chains.
- Sub-Graphs Sampling: A random walk algorithm is employed to sample reasoning chains of desired lengths from these graphs. This method ensures that data samples maintain necessary logical complexity without superfluous information.
- Graph Synthetic Data for LLM Tuning: The sampled reasoning chains are transformed into synthetic datasets suitable for supervised fine-tuning. The conversion employs heuristic verbalizers for transforming graph relations into natural language text. Further, the introduction of task-specific prompting techniques, such as ETA-P (Extract then Answer), guides LLMs to first extract relational information from text before computing answers.
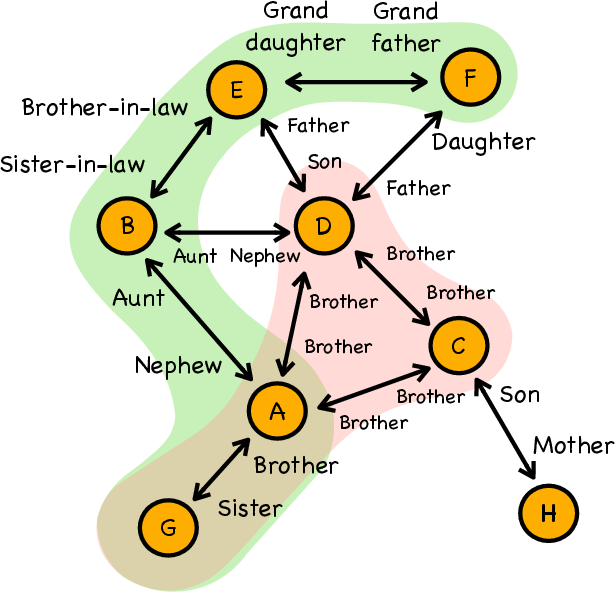
Figure 1: Illustration of a kinship graph highlighting a reasoning chain sampled by our algorithm (green) for LLM adaptation, and an ignored simpler chain (red).
Experimental Setup and Results
The experiments are conducted on two logical reasoning benchmarks, CLUTRR and StepGame, each with unique challenges in inductive and spatial reasoning respectively. Several experimental configurations are tested:
- Few-shot (FS) Setting: Evaluated on GPT-4o and Mistral-7B models without additional tuning.
- Supervised Fine-Tuning (SFT): Involves training on either the original story datasets or augmented with synthetic graph-based data to explore performance gains.
Results demonstrate significant improvements in reasoning performance when using graph-based synthetic data, especially on the CLUTRR and StepGame datasets. For instance, augmenting the training data with graph-based samples led to pronounced accuracy improvements at higher reasoning complexities.
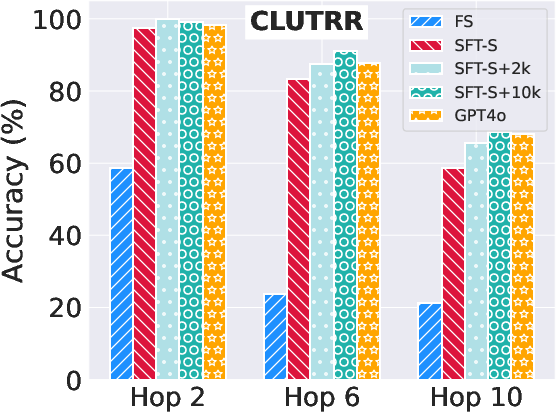
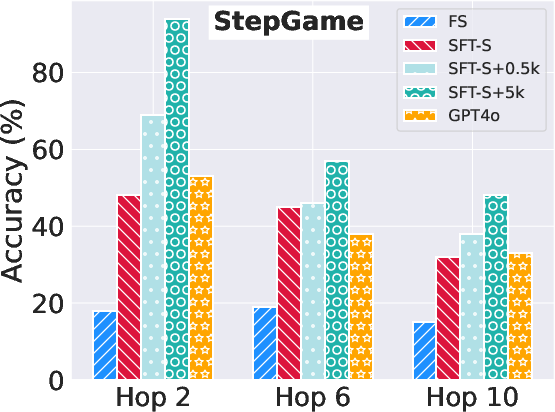
Figure 2: System performance on the CLUTRR (top) and StepGame (bottom) datasets for 2, 6, and 10 hop.
Further analysis indicates the proposed ETA-P prompting mechanism serves as a valuable complement to in-domain SFT, significantly improving LLMs' reasoning abilities beyond standard prompting methods.
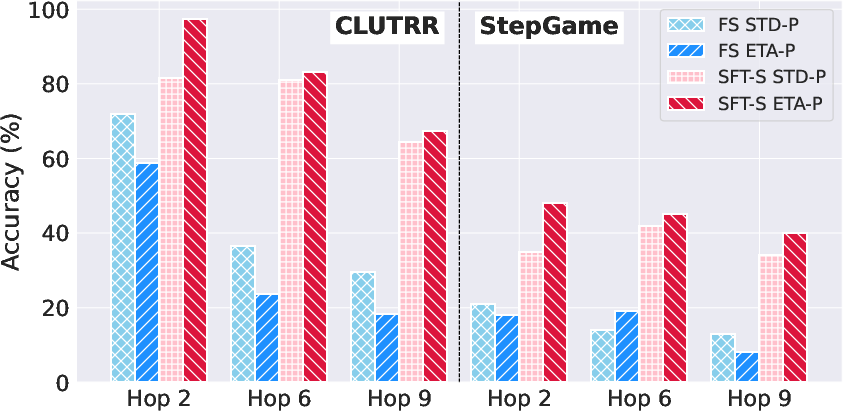
Figure 3: Mistral-2-7B performances on CLUTRR (left) and StepGame (right) datasets under FS and SFT-S settings when using STD-P and ETA-P prompting.
Implications and Future Directions
The results provided in this paper illustrate that synthetic graph data can effectively augment standard datasets to improve LLMs' reasoning capacities. This approach highlights the importance of structured, high-quality synthetic data generation in logical tasks, which may pave the way for more adaptive LLM fine-tuning strategies.
The implications are significant for both theoretical and practical applications, suggesting new pathways for improving LLM performance on complex reasoning tasks. Future developments might involve integrating larger datasets, testing with larger LLMs, and refining verbalizers or automated prompting strategies to ensure robustness across diverse reasoning challenges.
Conclusion
In summary, this study offers a novel strategy for enhancing logical reasoning in LLMs through structured graph-based synthetic data. The combined approach of using graph constructs and specialized prompting provides a robust framework for tackling logical reasoning tasks, offering promising directions for future research in augmenting LLM capabilities.