- The paper demonstrates that observation representation selection is critically dependent on model capability and token budget, directly impacting task success rates.
- The paper finds that high-capability models gain up to 17.5% success improvement with detailed HTML inputs, whereas lower-capability models perform better with reduced a11y representations.
- The paper reveals that incorporating observation history, particularly diff-based representations, enhances performance by efficiently tracking context while reducing token costs.
Revisiting Observation Reduction in Web Agents: Model Capability, Token Budget, and Representation Tradeoffs
Introduction
Recent developments in LLM-based web agents have been accompanied by an implicit assumption that reducing observation verbosity—i.e., simplifying the input representation of each web page—is universally beneficial for agent performance and efficiency. "Read More, Think More: Revisiting Observation Reduction for Web Agents" (2604.01535) systematically evaluates this assumption with detailed empirical analysis. By dissecting interactions between model capability, observation representation, and inference-time reasoning budget, the work provides nuanced guidelines for next-generation LLM-driven web automation.
The study frames LLM-based web agenting as a POMDP, where the agent observes the web environment (typically as HTML, a11y tree, or screenshots), acts upon it, and iterates until task completion. The central questions addressed are:
- How does the choice of observation representation (HTML, a11y, screenshots, and combination) impact task success under varying model capabilities?
- What is the effect of increasing the "thinking token" budget?
- How does incorporating observation history (full or diff-based) affect performance?
Experiments are primarily conducted on WorkArena L1, a challenging web automation benchmark.
Observation Representation: Model Competence and Token Budget Interactions
Historically, most approaches have adopted observation reduction strategies, motivated by the prohibitive length and redundancy of raw HTML. The authors’ findings reveal that the optimal observation representation is strongly model- and inference-budget-dependent rather than universally optimal.
For lower-capability, open-source models, reducing the size of the observation (e.g., using a11y rather than HTML) significantly improves task success, likely due to their limited context processing ability and propensity for confusion or hallucination under verbose inputs. In contrast, higher-capability, proprietary frontier models benefit substantially from richer observation formats; these models exploit the nuanced structure and layout cues present in HTML to ground actions more accurately.
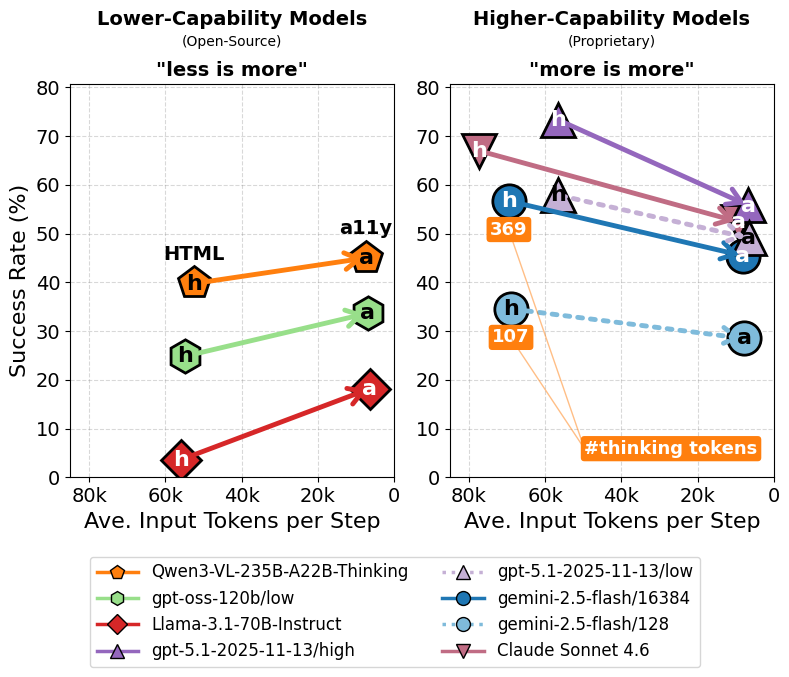
Figure 1: Success rate in WorkArena L1 as a function of observation representation and model capability. For lower-capability models, reducing observation size improves performance; for higher-capability models, more detail yields higher performance.
The performance gap between a11y and HTML grows as the agent’s token budget for "thinking" (inference-time computation) increases. For instance, gpt-5.1 (high reasoning effort) achieves a +17.5% absolute gain in success rate when provided with raw HTML over a11y. This gain amplifies with an increased thinking token budget across model families.
Error Analysis: Hallucination versus Grounding
The investigation of agent action grounding exposes fundamentally different failure modes contingent on observation choice and model competency. Higher-capability models with access to HTML can exploit layout-relevant information (e.g., CSS z-index) to avoid execution errors such as "intercepted clicks" caused by element overlap.
By contrast, lower-capability models subjected to long HTML inputs register marked increases in hallucinated references—such as specifying nonexistent element IDs—resulting in more "not found" errors and degraded task success.
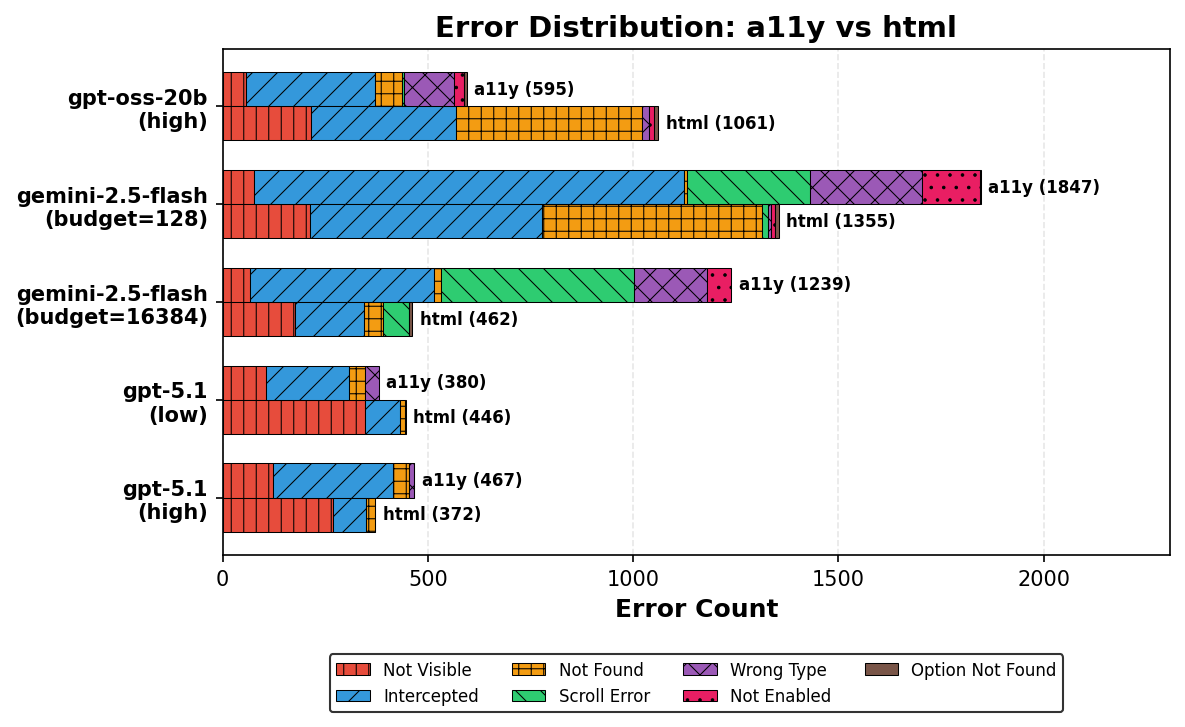
Figure 2: Breakdown of grounding error types for a11y and HTML inputs. High-capability models show reduced errors with HTML; low-capability models suffer from increased hallucination under verbose input.
These results substantiate the claim that observation reduction is not generically beneficial: the context length burden becomes a source of confusion for weaker models but creates an avenue for richer planning and grounding for stronger ones.
Effect of Observation History and Diff-based Representations
Incorporation of observation history uniformly improves performance for almost all models and settings, highlighting the importance of temporal context and task state tracking in web automation. While full-history inclusion can tax input length budgets, the authors show that diff-based representations—where only incremental textual differences between consecutive observations are retained—achieve comparable or superior results at a fraction of the token cost.
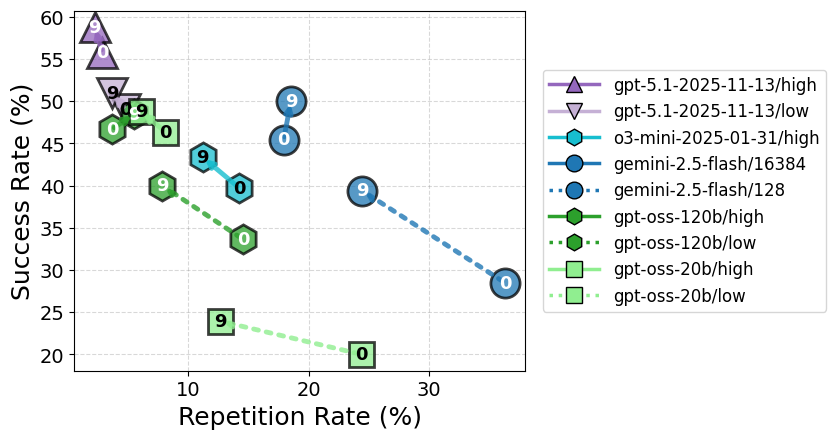
Figure 3: Lower action repetition rates, enabled by use of observation history, align with higher task success across models.
Notably, higher-capability models (e.g., o3-mini, gemini) accrue compound gains via longer history windows, while token-efficient diff histories close most of the gap for resource-constrained inference.
Implications for Design and Future Directions
The empirical results support a set of practical system design guidelines. Observation representation should be selected adaptively, conditioned on model class and available inference-time token budget. For high-capability, high-budget deployments, detailed HTML input is preferable. Lower-tier agents benefit from aggressive reduction (a11y, or pre-filtered subsets). Critically, observation history—preferably diff-based—is universally beneficial and facilitates better agent memory and less redundant actioning.
These findings have direct implications for web agent architecture in real-world deployment, where mixed-model stacks and dynamic resource allocation are the norm. The results also indicate potential for further research in adaptive observation tailoring, learned selection of salient content conditioned on both model state and task, and the interplay between multimodal input (e.g., HTML + vision) and long-context reasoning.
Conclusion
This work decisively refutes the blanket prescription of observation reduction for LLM web agents. The relationship between observation detail, model capability, and reasoning token budget is nonlinear and must be explicitly accounted for. Agents built on high-capacity models can realize large improvements—up to 17.5% increased success—when furnished with full HTML, whereas weaker models can be harmed by excessive input verbosity. Incorporating observation history robustly improves performance, and diff-based representations offer a tractable, token-efficient pathway. These insights inform both theory and engineering of advanced web agents and motivate continued research in model-adaptive input representations and efficient long-context utilization.