- The paper introduces a decoupled restoration-then-reconstruction paradigm that leverages video diffusion models to enforce inter-view consistency for radiance field optimization.
- It employs pose ordering, zero frame interpolation, and masked diffusion with MiQT, inpainting, and style masks to clean inconsistent multi-view imagery before NeRF reconstruction.
- Empirical results demonstrate state-of-the-art performance on PSNR, SSIM, and LPIPS, enabling robust 3D scene reconstruction even under sparse, inconsistent observation conditions.
UniVerse: Decoupling Restoration and Reconstruction for Robust Radiance Field Generation with Video Diffusion Priors
Problem Statement and Context
Robust 3D scene reconstruction from unconstrained, inconsistent multi-view imagery presents persistent challenges for radiance field representations such as NeRF and Gaussian Splatting approaches, which are inherently sensitive to input inconsistencies stemming from lighting variation, dynamic content, occlusions, or capture artifacts. Existing strategies typically attempt to jointly model per-view degradations and the scene, but optimization becomes unstable as the observation density decreases. UniVerse (2510.01669) addresses this by decoupling robust reconstruction into separate restoration and reconstruction stages, leveraging a video diffusion model (VDM)–based restoration mechanism to enforce inter-view consistency prior to radiance field optimization.
Framework Overview
UniVerse introduces a unified, modular pipeline:
- Multi-view images with inconsistencies are first ordered and interpolated to define a camera trajectory, transforming the unordered image set into a synthetic “video” sequence along that trajectory.
- Scene restoration is achieved via a conditional video diffusion model, which exploits strong video priors to inpaint occlusions, homogenize photometric attributes, and enforce global stylistic consistency, resulting in a sequence of static, mutually consistent frames.
- Standard neural radiance field methods (e.g., NeRF or 3DGS) are applied to the cleaned, consistent images to optimize the 3D scene representation.
This decoupling significantly simplifies optimization, as the neural renderer receives inputs that now satisfy its fundamental assumptions (scene statics, view-consistent content and lighting), enabling improved robustness and generalization, particularly in the sparse observation regime.
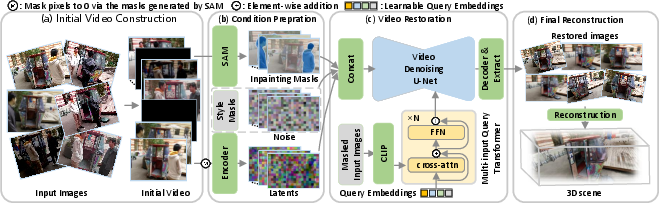
Figure 1: The UniVerse pipeline processes inconsistent multi-view images into a consistent video sequence for radiance field reconstruction.
Key Algorithmic Steps
Pose Ordering and Video Synthesis
The input images and corresponding camera poses (possibly unordered and unevenly distributed) are used to define an effective camera trajectory (ThreadPose). This process constructs a double-linked list of poses via a nearest-neighbor traversal based on translation and rotation similarity metrics. The images are then ordered, and zero-valued “blank” frames are inserted between neighboring views to allow dense trajectory interpolation, producing a synthetic video along the trajectory.
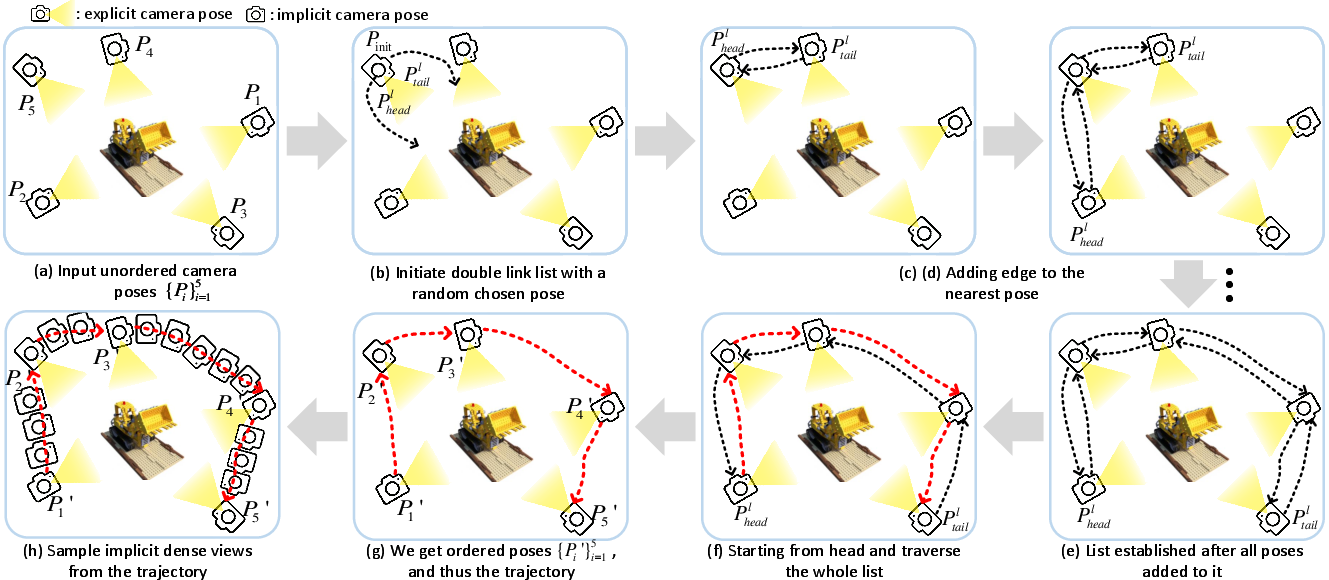
Figure 2: Illustration of transforming unordered multi-view images into a dense, ordered video trajectory.
Video Diffusion Model Conditioning
The sequence (video) is processed by a conditional VDM with the following design considerations:
- Multi-input Query Transformer (MiQT): Aggregates CLIP embeddings from all N input images for each inference batch, providing a global semantic vector to condition the generative process.
- Inpainting Masks: Transient occlusions are segmented via SAM; corresponding pixels across frames are masked for inpainting during restoration.
- Style Masks and Control: A style image is selected per batch, and style masks dictate which frames serve as the stylistic source, enabling explicit style propagation across the sequence.
- Consistency Loss: A weighted objective emphasizing restoration consistency for real input frames, with reduced weight for interpolated zero frames, focusing the model on deartifacting rather than new-view synthesis.
Empirical Results
UniVerse is evaluated on both synthetic and real-world datasets, using standard metrics (PSNR, SSIM, LPIPS) and challenging scenarios with severe input inconsistencies. The method achieves state-of-the-art performance on PSNR, SSIM, and LPIPS compared to contemporary robust reconstruction baselines, including ZipNeRF, Bilarf, and WildGaussians. Notably, the restoration-then-reconstruction paradigm yields particularly large gains in the sparse-observation, high-inconsistency setting, where previous approaches degrade sharply.

Figure 3: UniVerse novel view synthesis on synthetic datasets; restored depths and image consistency are evident.

Figure 4: Novel view synthesis on real datasets; high photometric and geometric fidelity is preserved after restoration.

Figure 5: Samples of the challenging, inconsistent real-world input data collected for empirical evaluation.
Ablation studies confirm the criticality of each design decision: pose sorting and zero frame insertion for trajectory interpolation, use of inpainting and style masks, MiQT semantic aggregation, and the proposed consistency loss. Models lacking these components exhibit significant declines in consistency and reconstruction accuracy.

Figure 6: Visualization highlighting the necessity of inpainting masks for transient occlusion removal.

Figure 7: Style masks enable explicit control over appearance harmonization in restored images.
Style and Downstream Control
Beyond robustness, UniVerse facilitates control over final scene appearance: by specifying a different style image and mask, the resultant 3D scene can be systematically stylized.

Figure 8: 3D scene style control by switching the style image during restoration.
The framework is extendable: combining UniVerse's restoration step with downstream generative models (e.g., ViewCrafter) further enhances novel view synthesis under extreme input sparsity or occlusion.

Figure 9: ViewCrafter yields distorted novel views from inconsistent images, remedied by prior restoration via UniVerse.
Implications and Future Directions
Theoretically, UniVerse establishes that high-capacity video diffusion priors can serve as generic corruption-removal modules, largely independent of specific degradation types present in unconstrained imagery. This breaks from the trend of hand-crafting or explicitly modeling each degradation source for every scene, instead allowing a restoration-as-preprocessing paradigm. There is strong evidence that such decoupling reduces overfitting and instability when the observation count is low or input variation is high.
Practically, UniVerse enables robust radiance field construction from photo collections previously considered too inconsistent, such as those scraped from casual or uncontrolled settings. Further, the explicit style control offers new avenues for artistic and domain-specific 3D content generation.
Looking ahead, integrating this restoration paradigm with more generalizable radiance field architectures, or extending the restoration process to directly output 3D-aware features, are natural directions. The primary limitation remains the need for synthetic degradation data to fine-tune the restoration model; improved synthetic pipelines or self-supervised adaptation strategies will be beneficial.
Conclusion
UniVerse demonstrates that decoupling restoration and reconstruction via VDM-based consistency enforcement addresses fundamental optimization issues in robust radiance field reconstruction from inconsistent imagery. Its superior empirical results and extensibility for appearance control suggest broad applicability in both research and industry settings, and it is poised to influence future pipelines where robustness to real-world capture conditions is required.