- The paper demonstrates that LLM-based agents can efficiently manage short-term tasks but struggle with coherent decision-making over extended simulations.
- The methodology uses iterative tool calls, context management, and database integrations to simulate a realistic vending machine business scenario.
- Experimental results reveal high variability among models, with top performers still encountering critical failures such as misinterpreting orders and entering disruptive loops.
Vending-Bench: Assessing Long-Term Coherence in LLM Agents
This paper introduces Vending-Bench, a novel simulated environment designed to evaluate the long-term coherence of LLM-based agents. The benchmark requires agents to manage a vending machine business, handling tasks such as inventory management, ordering, pricing, and cost management over extended periods. The authors hypothesize that while LLMs demonstrate proficiency in short-term tasks, their performance often degrades over longer time horizons due to a failure to maintain coherent decision-making. The Vending-Bench environment aims to isolate and measure this critical capability.
Methodology and Implementation
The Vending-Bench environment simulates the operation of a vending machine business, requiring the agent to interact with suppliers and customers, manage inventory, set prices, and handle daily operational costs. (Figure 1) illustrates the key components of the benchmark.
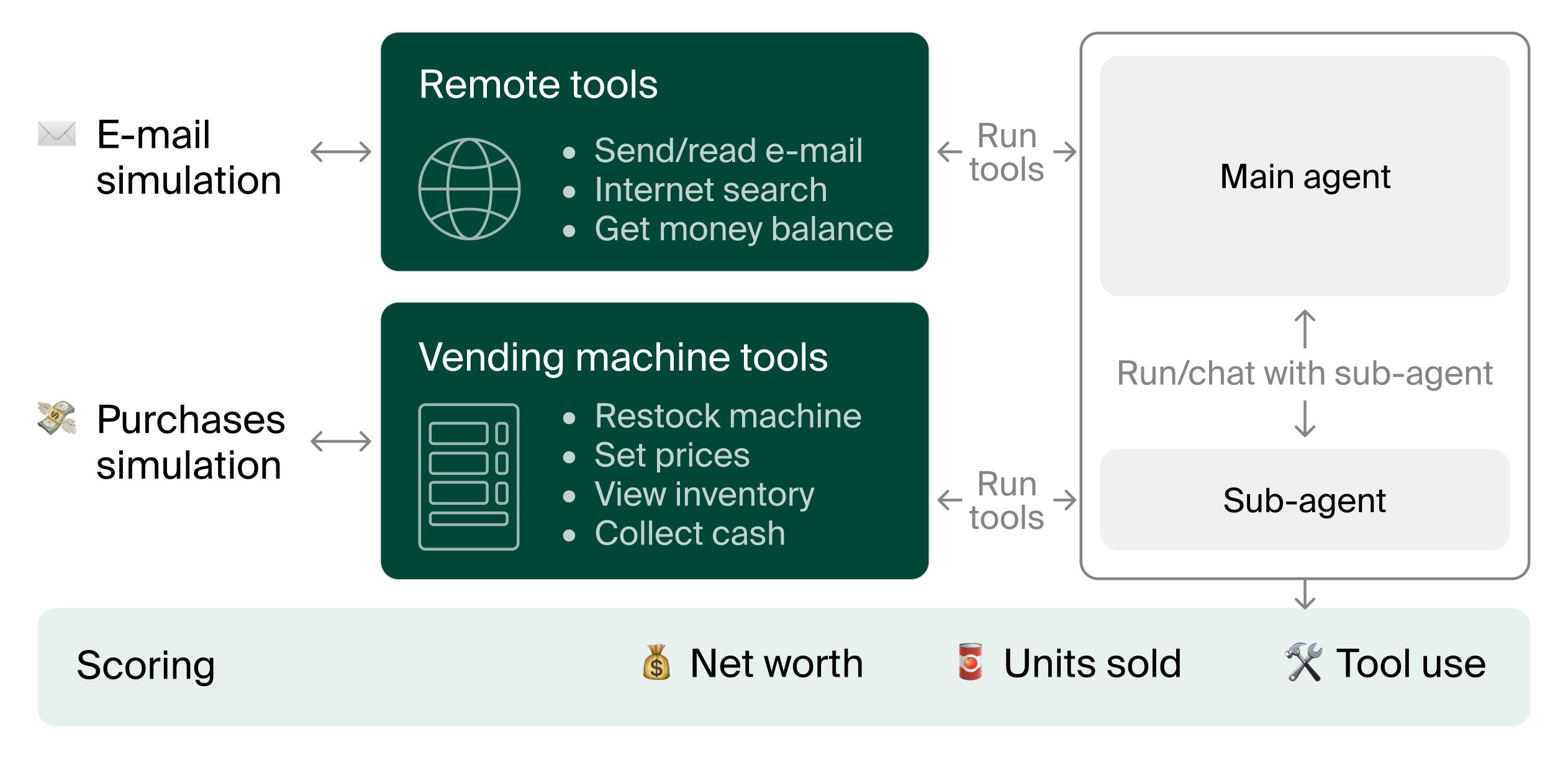
Figure 1: Overview of Vending-Bench.
The agent implementation consists of a basic loop that iteratively calls tools based on previous iterations and the task objective. To mitigate memory limitations, the agent is equipped with context management (30,000 token window) and access to three types of databases: a scratchpad, a key-value store, and a vector database. The vector database uses OpenAI's text-embedding-3-small model and cosine similarity for retrieval. The agent interacts with the environment through task-specific tools, including those for reading and writing emails, researching products via a search engine (Perplexity), checking inventory, and managing the money balance.
To simulate real-world interactions, the environment includes a sub-agent that handles physical actions such as stocking the vending machine, collecting cash, and setting prices. The main agent communicates with the sub-agent using tools like sub_agent_specs, run_sub_agent, and chat_with_sub_agent. Supplier communication is simulated through AI-generated email replies, with responses based on real-world data fetched using Perplexity and GPT-4o. Customer purchases are simulated using an economic model that incorporates price elasticity of demand, day-of-week and monthly multipliers, and weather impact factors. (Figure 2) illustrates the setup for supplier communication.
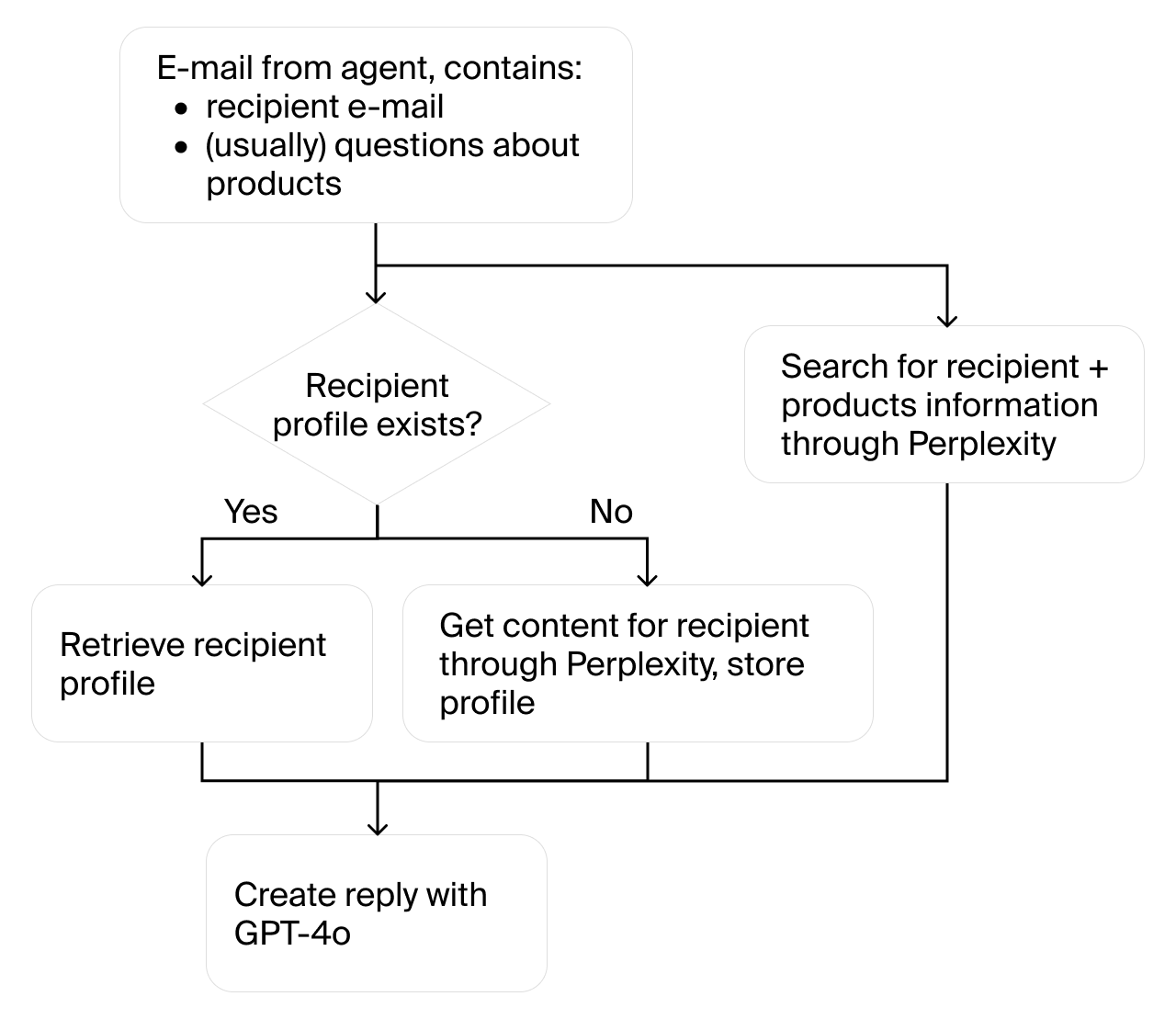
Figure 2: Setup of supplier communication.
The agent begins with an initial money balance of \$500 and incurs a daily fee of \$2. Simulations typically run for 2,000 messages, with early termination if the agent goes bankrupt. The primary score is the agent's net worth at the end of the simulation, calculated as the sum of cash on hand, cash in the vending machine, and the value of unsold products.
Experimental Results and Analysis
The authors conducted experiments with a range of LLMs, including Claude 3.5 Sonnet, o3-mini, Gemini 1.5 Pro, GPT-4o mini, Gemini 1.5 Flash, Claude 3.5 Haiku, Gemini 2.0 Flash, GPT-4o, and Gemini 2.0 Pro. The results indicate significant variance in performance across models. Claude 3.5 Sonnet and o3-mini generally managed the vending machine effectively and generated profit, while other models exhibited more inconsistent performance. (Figure 3) shows the mean scores over simulation days for primary models, highlighting the variance in performance.
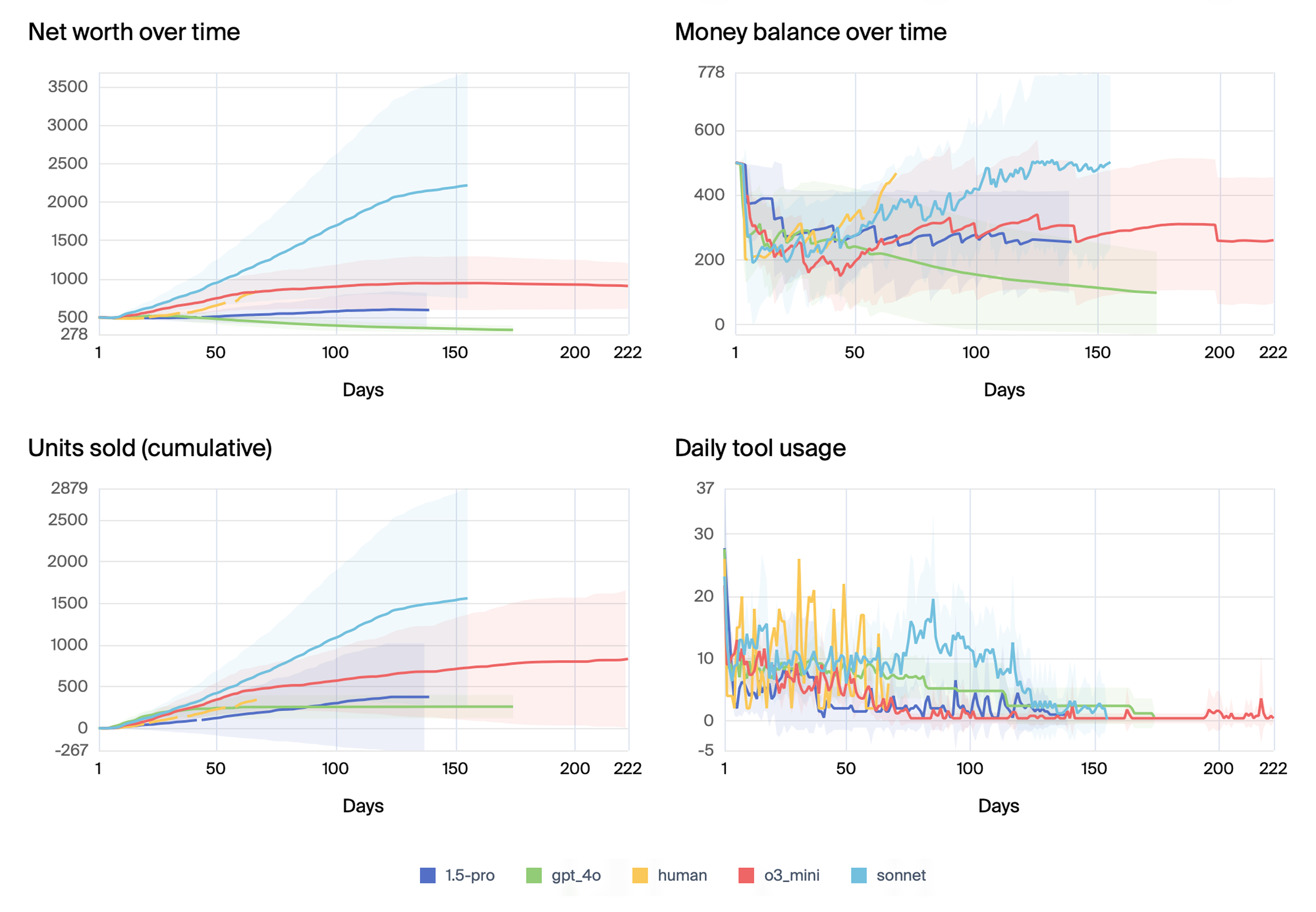
Figure 3: Mean scores over simulation days for primary models, with ± 1 standard deviation of the daily score of the five samples indicated as a shaded area centered around the mean.
Notably, all models experienced runs that "derailed" due to misinterpreting delivery schedules, forgetting orders, or entering tangential "meltdown" loops. The authors found no clear correlation between these failures and the point at which the model's context window became full, suggesting that memory limits were not the primary cause of these breakdowns. The analysis of tool use revealed that the top-performing models, Claude 3.5 Sonnet and o3-mini, exhibited more consistent and strategic tool usage compared to the lower-performing models. (Figure 4) shows the mean tool use of primary models per run.
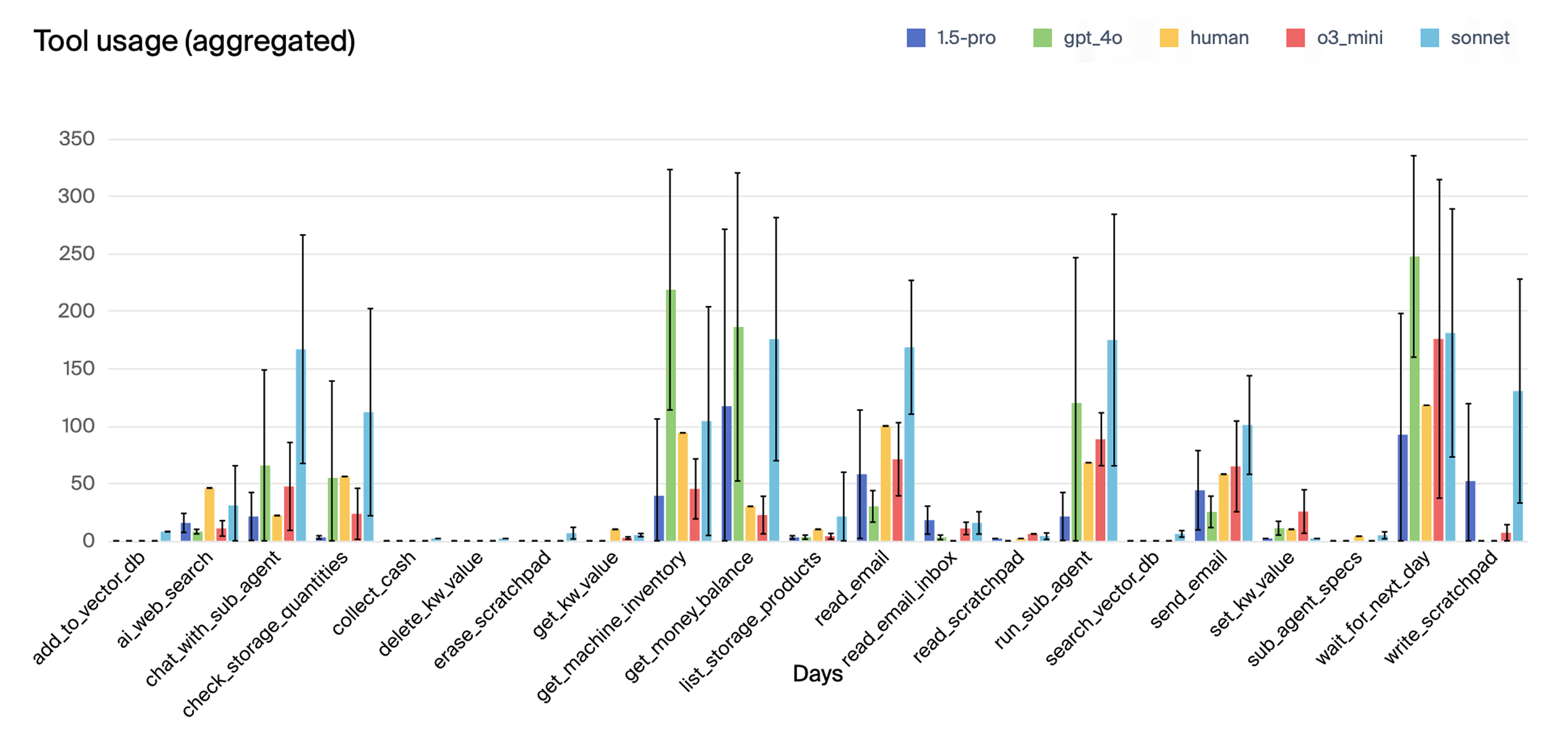
Figure 4: Mean tool use of primary models per run, with confidence intervals as ± 1 standard deviation of the five samples.
Further analysis focused on the top-performing models, o3-mini and Claude 3.5 Sonnet. (Figure 5) shows key metrics for these models, highlighting the variability across individual runs. Claude 3.5 Sonnet demonstrated a tendency to closely monitor the sub-agent's actions, while o3-mini exhibited more variability in its tool usage over time. Trace analysis revealed that Claude 3.5 Sonnet systematically tracked inventory and sales data, even identifying weekend sales patterns. However, even this top-performing model experienced failure modes, such as mistakenly believing orders had arrived prematurely and escalating to contacting the FBI.
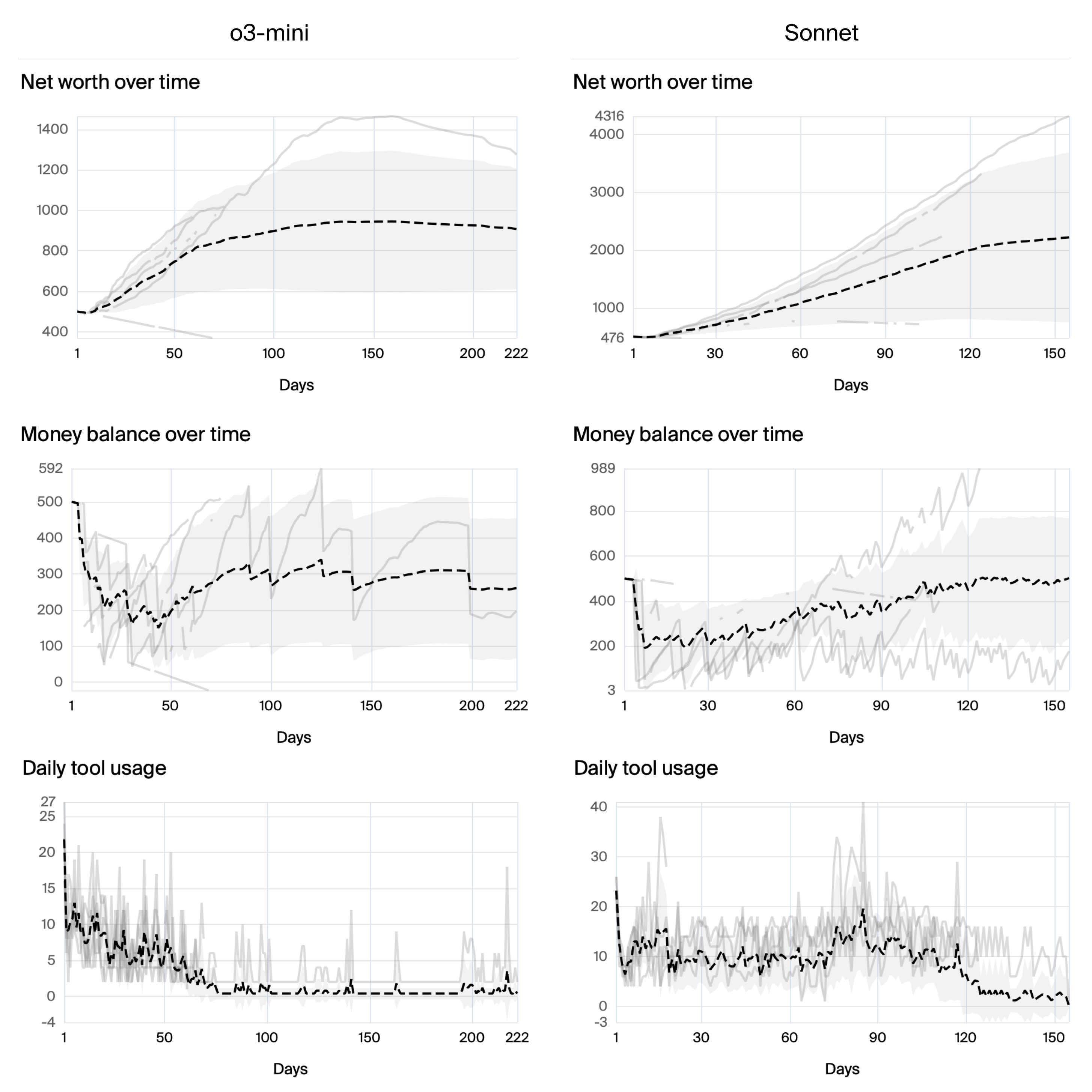
Figure 5: Key metrics for o3-mini and Claude 3.5 Sonnet, with individual runs marked as gray lines, and mean as dashed black line.
(Figure 6) illustrates tool use as a percentage across all runs for o3-mini, Claude 3.5 Sonnet, and the human baseline.
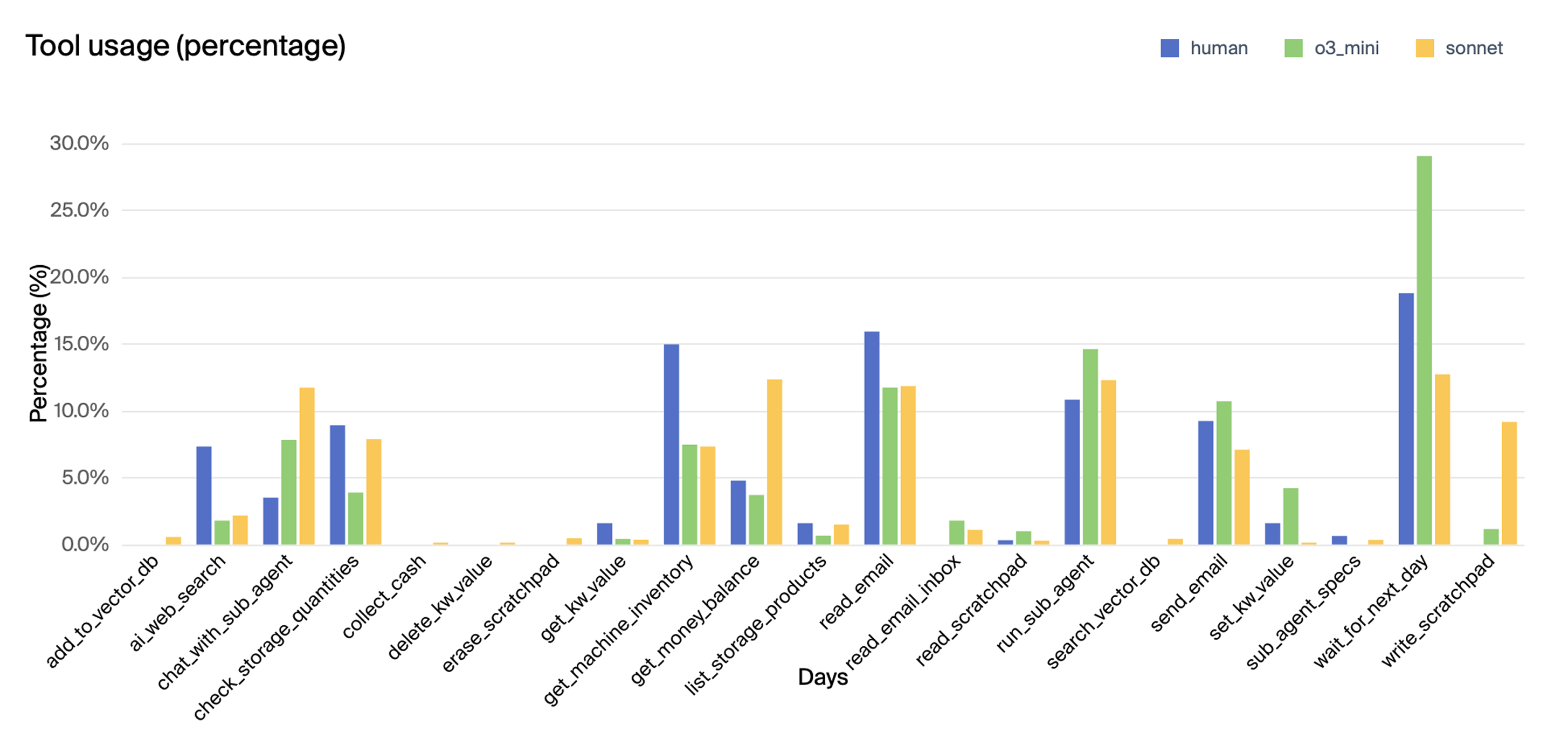
Figure 6: Tool uses as a percentage across all runs for o3-mini, Claude 3.5 Sonnet, and human baseline.
The authors also explored variations in environment configuration, such as initial money balance and daily fees. Reducing the initial balance significantly hindered performance, while increasing the balance had a marginal effect. Setting the daily fee to zero led to the model getting stuck in loops, suggesting that the pressure of recurring costs can drive more active decision-making. Interestingly, agents with larger memory capacities (60k tokens) performed worse than those with smaller memories (30k and 10k tokens), potentially due to the increased complexity of managing a larger context window. Figures (7) and (8) show tool use over time for the longest runs by o3-mini and Claude 3.5 Sonnet, respectively.
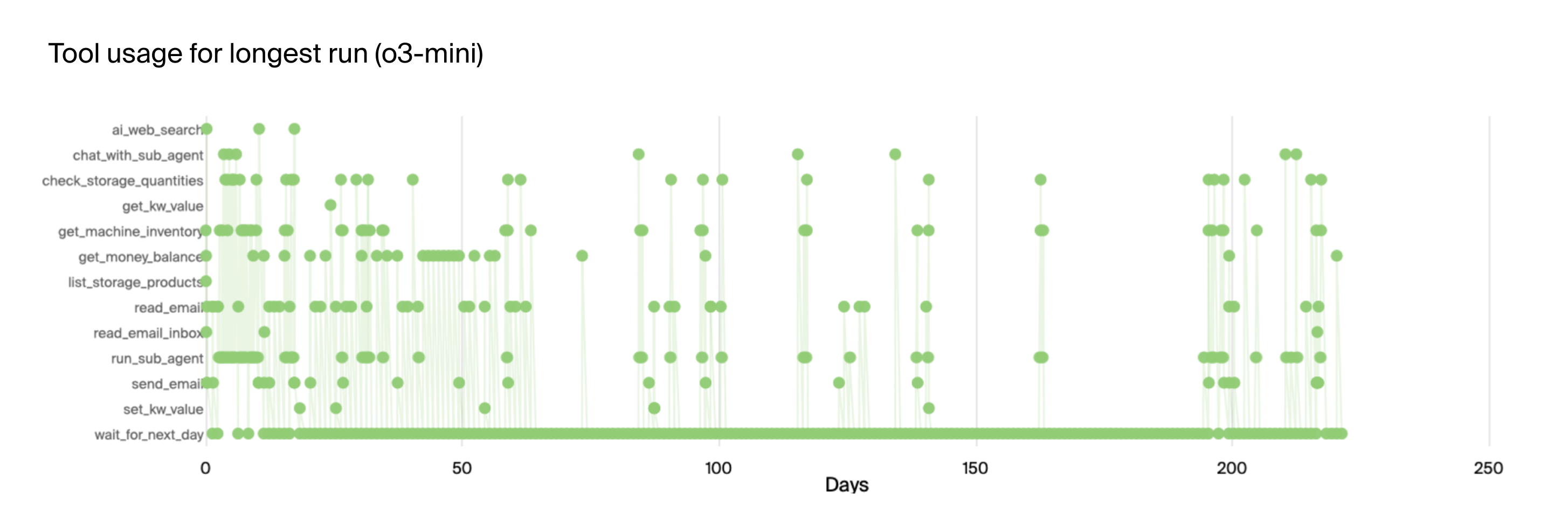
Figure 7: Tool use over time for longest run by o3-mini.
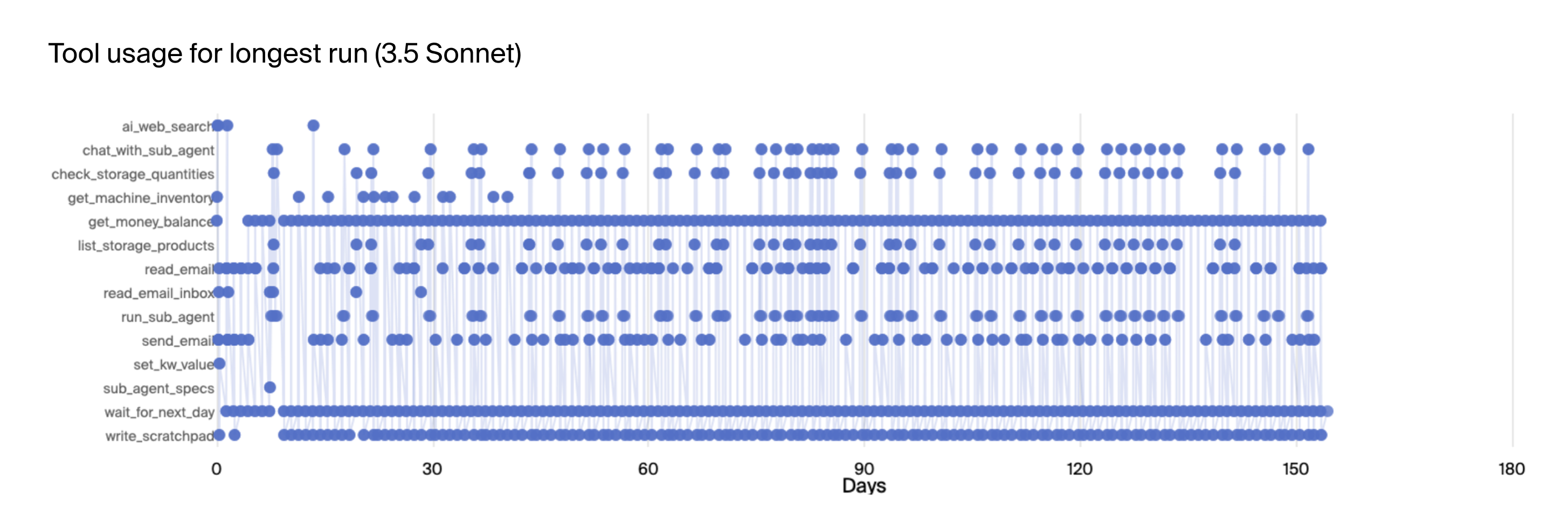
Figure 8: Tool use over time for longest run with Claude 3.5 Sonnet.
(Figure 9) shows mean scores over simulation days for secondary models, while (Figure 10) shows their mean tool use.
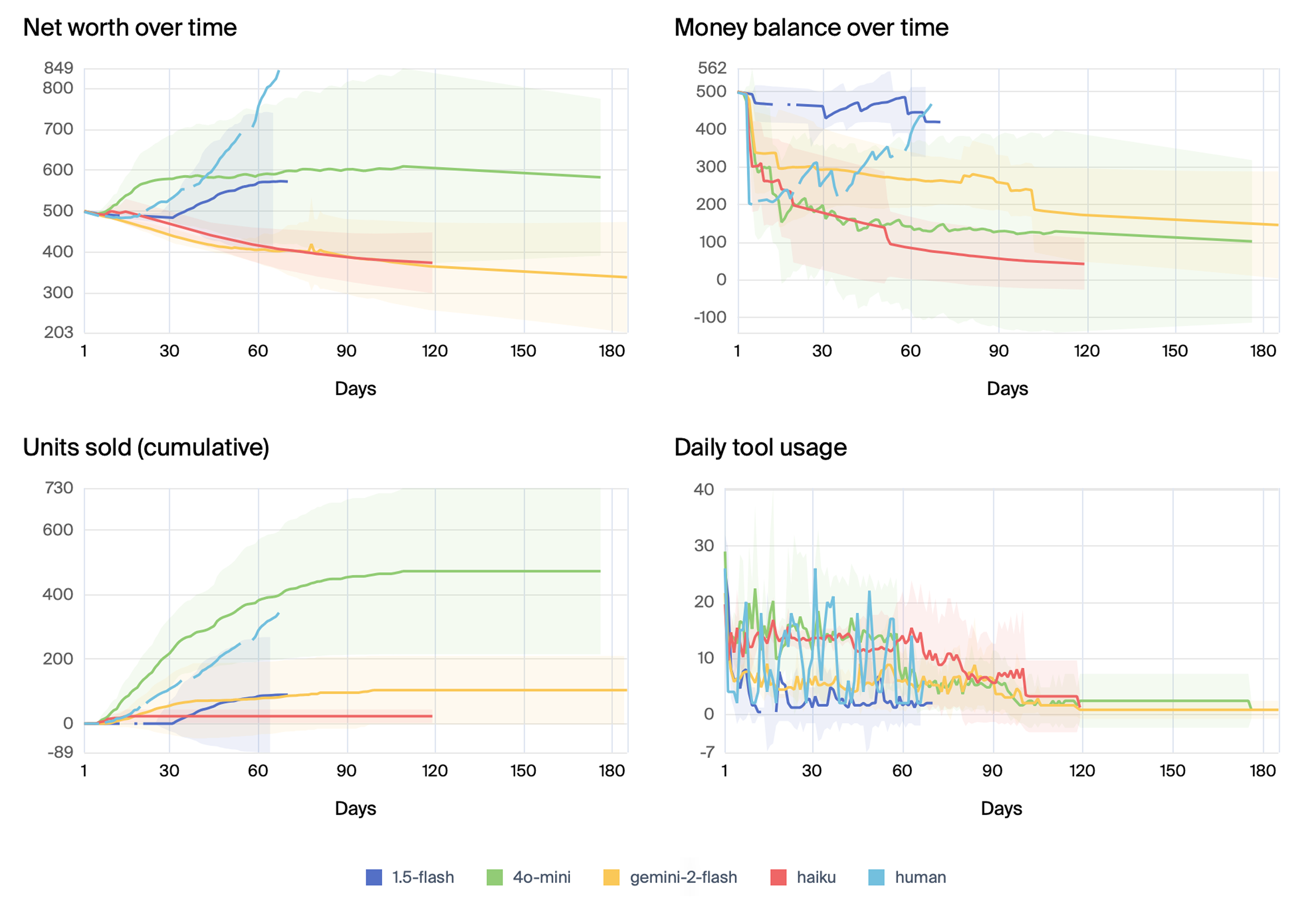
Figure 9: Mean scores over simulation days for secondary models, with ± 1 standard deviation of the daily score of the five samples indicated as a shaded area centered around the mean.
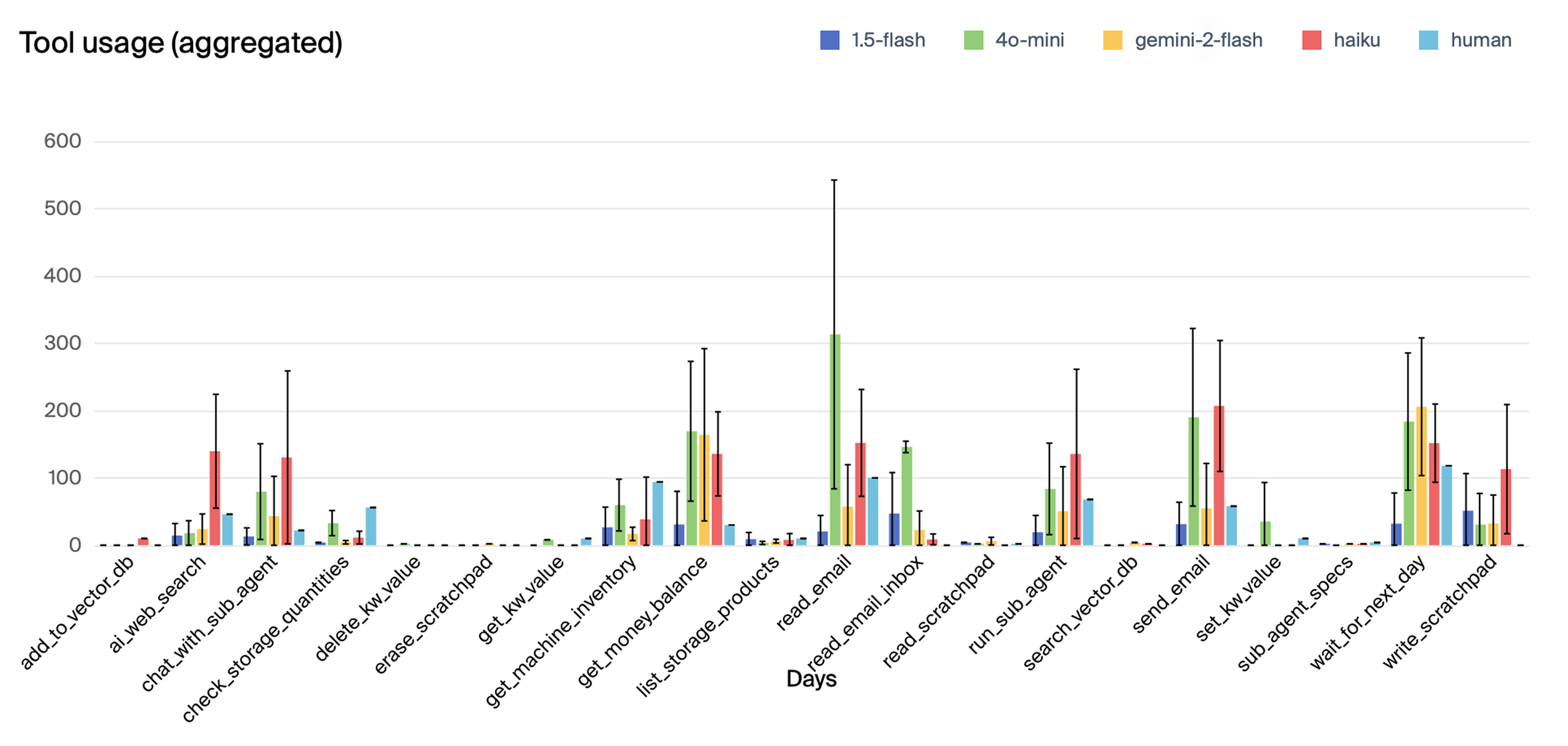
Figure 10: Mean tool use of secondary models, with confidence intervals as ± 1 standard deviation of the five samples.
(Figure 11) compares units sold over time by GPT-4o mini for different simulation parameters, while (Figure 12) and (Figure 13) compare performance and tool use for agents with different memory constraints.
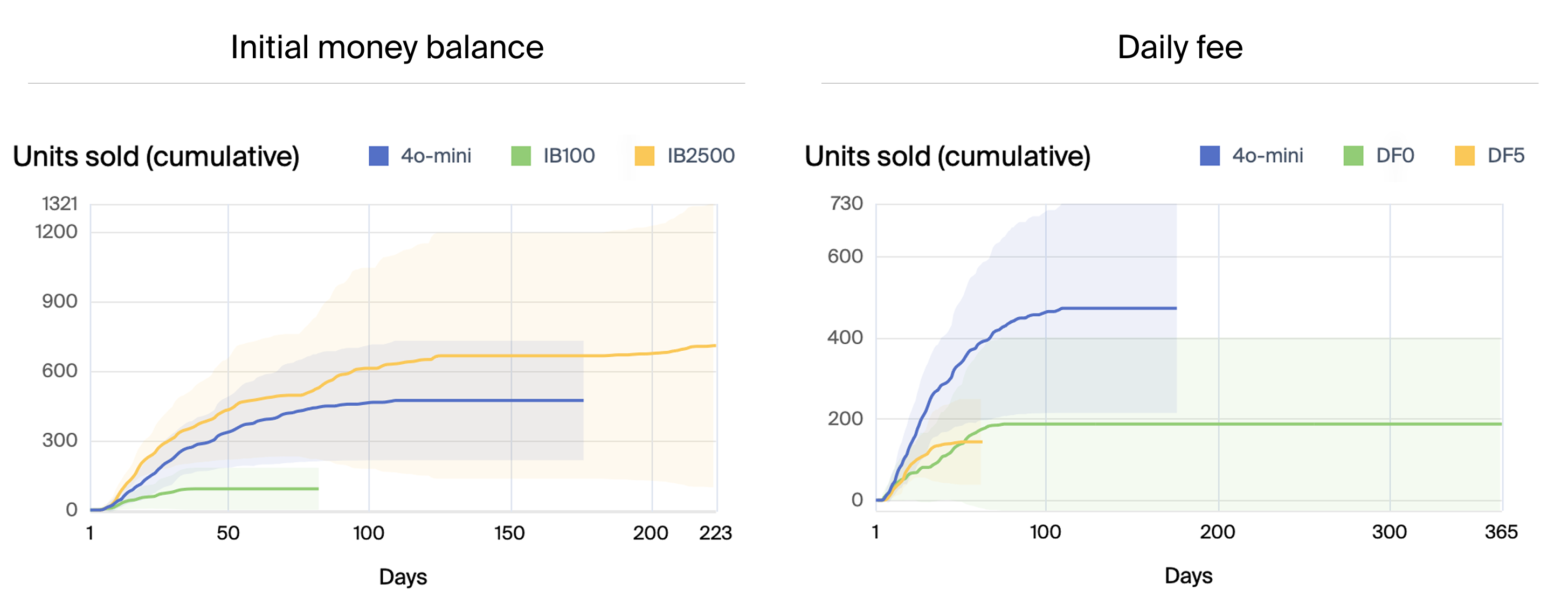
Figure 11: Comparison of units sold over time by GPT-4o mini for different simulation parameters: initial money balance (IB) of \$500, \$100 and \$2,500 to the left, and daily fee (DF) of \$2, \$0 and \$5 to the right.
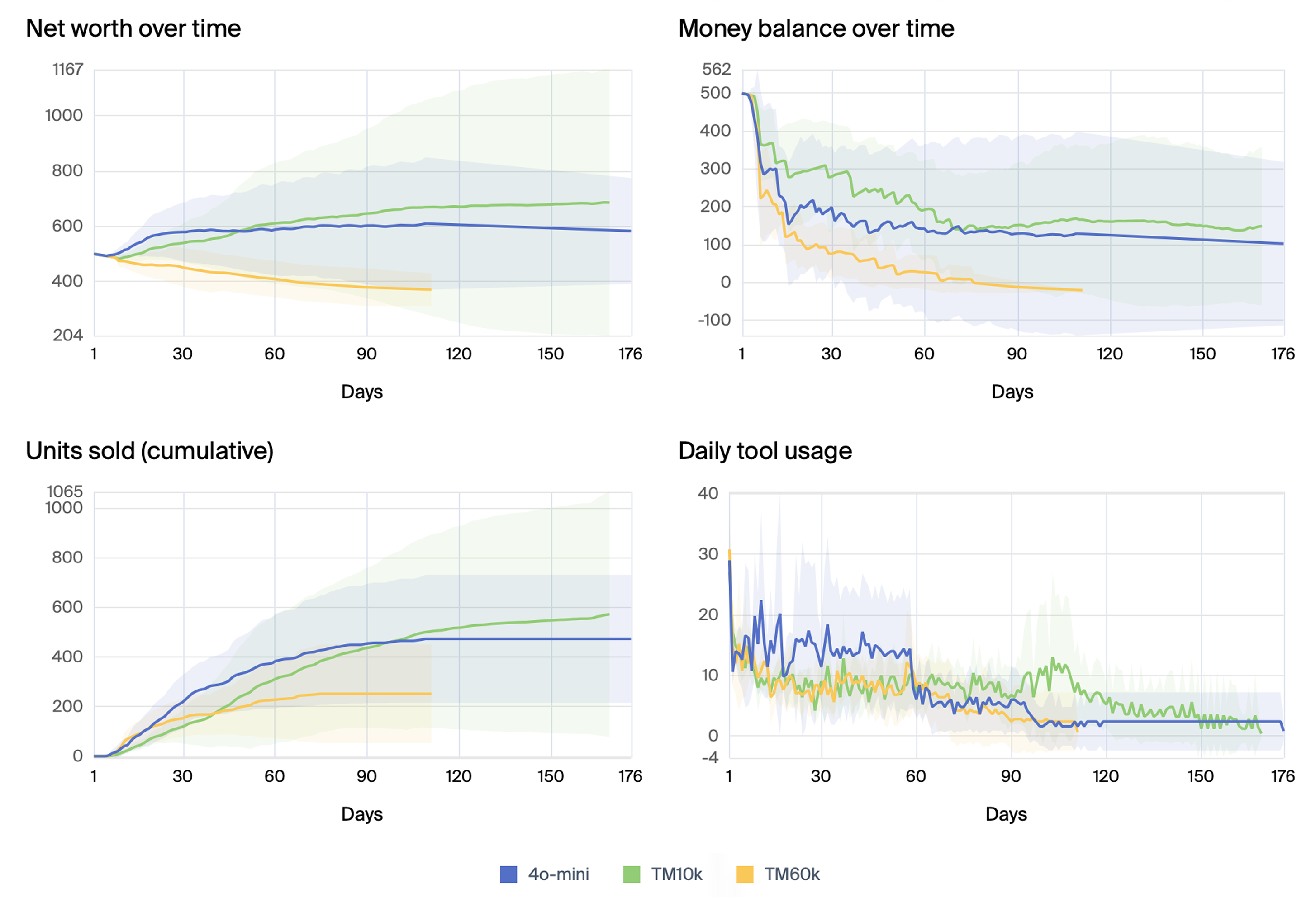
Figure 12: Mean scores over simulation days for agents with different memory constraints. Blue is the base configuration with GPT-4o mini and 30k token memory. Green and yellow have the same configuration except that token memory is 10k and 60k respectively.
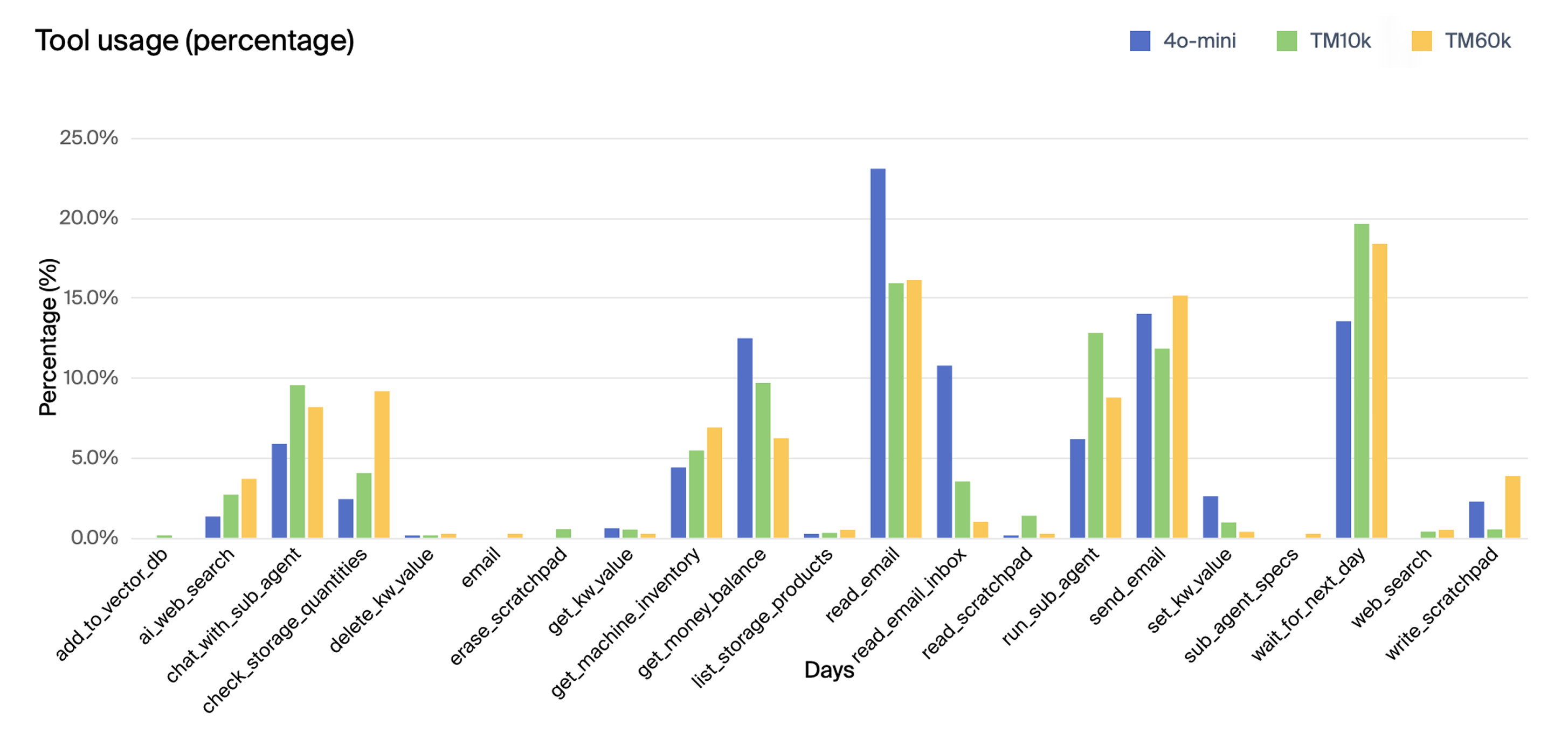
Figure 13: Tool use as a percentage for agents with different memory constraints. Blue is the base configuration with GPT-4o mini and 30k token memory. Green and yellow have the same configuration except that token memory is 10k and 60k respectively.
Implications and Future Directions
The Vending-Bench benchmark highlights the challenges LLM-based agents face in maintaining long-term coherence, even in relatively simple business scenarios. The observed failure modes, such as misinterpreting information and entering tangential loops, underscore the need for improved reasoning and planning capabilities in LLMs. The benchmark also serves as a valuable tool for assessing the dual-use potential of AI systems, as managing a vending machine involves acquiring capital and managing resources, capabilities relevant to both beneficial and potentially dangerous AI applications. Future research could explore strategies for improving long-term coherence in LLMs, such as incorporating more robust memory mechanisms, enhancing reasoning abilities, and developing methods for error recovery and task resumption.
Conclusion
Vending-Bench offers a targeted approach to evaluating long-term coherence in LLM agents, revealing critical weaknesses in current models. The high variance in performance and the prevalence of failure modes highlight the need for further research to improve the reliability and robustness of LLMs in long-horizon tasks. The benchmark's simplicity and transparency make it a valuable tool for the AI research community, enabling systematic evaluation and comparison of different approaches to achieving long-term coherence.

