- The paper introduces a modular framework using frozen MoE-LoRA stacks to enable continual, interference-free LLM learning.
- It employs residual boosting and null-space projection to prevent catastrophic forgetting while enabling efficient cross-domain composition.
- Empirical results demonstrate faster convergence and zero forgetting, indicating that reusable cognitive primitives can be effectively modularized.
Brainstacks: Frozen MoE-LoRA Stacks for Modular Continual LLM Learning
Introduction and Motivation
Brainstacks (2604.01152) introduces a modular approach for continual multi-domain fine-tuning in LLMs, treating domain capabilities as independently trained, permanently frozen Mixture-of-Experts Low-Rank Adaptation (MoE-LoRA) stacks that add residually atop a shared frozen base model. Unlike classical fine-tuning paradigms, which bake all domain knowledge into a monolithic parameter set and suffer catastrophic forgetting or interference when expanded, Brainstacks enables sequential, selective, and compositional capability addition without corrupting or degrading existing domains. This architecture integrates residual boosting, null-space projection for zero-forgetting, and outcome-driven selective routing to achieve domain isolation and efficient cross-domain composition.
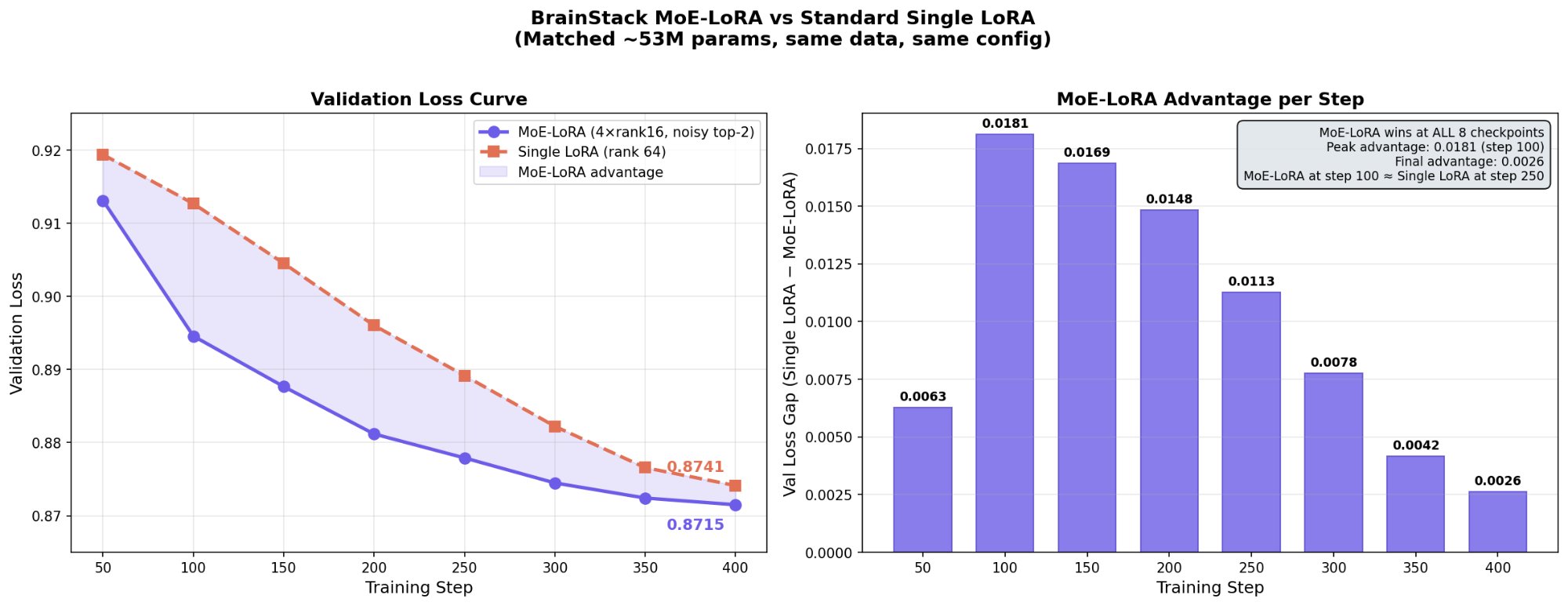
Figure 1: Brainstacks’ architecture: modular stacks trained per domain are residually composable atop a frozen base, enforced by null-space projection and gated by a meta-router.
Methodological Contributions
MoE-LoRA Stack Architecture
Brainstacks frames each domain as a stack of independently trained MoE-LoRA adapters. Each MoE-LoRA module applies Shazeer-style noisy top-2 routing with learnable noise injection to all seven transformer projections (attention and FFN), utilizing QLoRA 4-bit quantization and rsLoRA scaling. This design allows parameter-efficient, sparsely activated delta computation, and, critically, enables future extensibility required for continual learning.
Residual Boosting and Continual Stacking
Within each domain, an inner loop sequentially trains adapter stacks in a residual-boosting fashion—each subsequent stack minimizes the residual error not captured by previous stacks. In the outer loop, domains are trained sequentially, with stacks from previous domains permanently frozen.
Null-Space Gradient Projection
Before training each new domain, Brainstacks computes the principal directions of previous stacks’ activations at each layer via randomized SVD and enforces strict orthogonality by projecting the new stack’s updates into the null space of those prior directions. This hard geometric constraint prevents interference and guarantees zero forgetting when domains are evaluated in isolation.
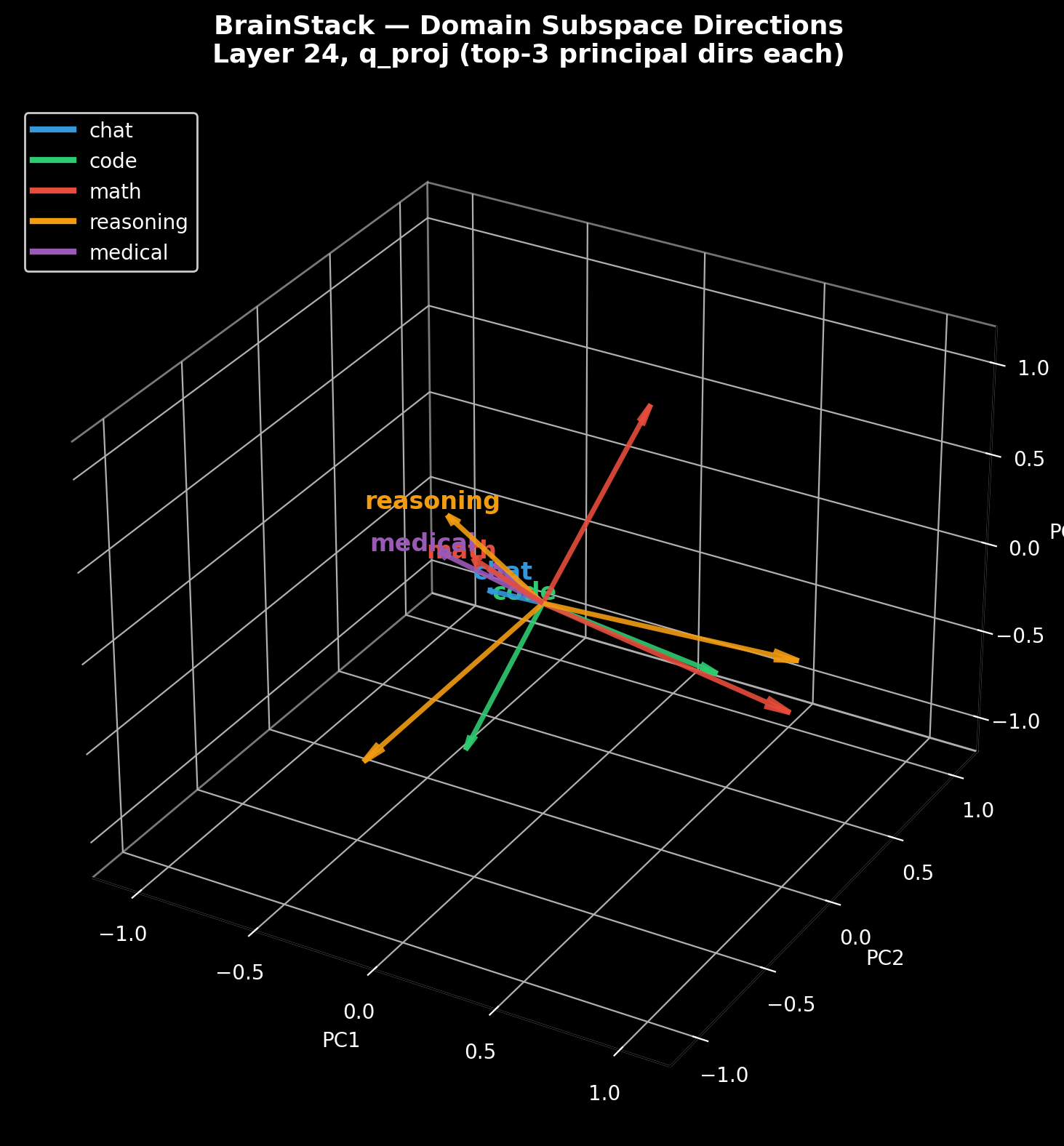
Figure 2: Domain subspace directions (layer 24 q_proj): null-space projection enforces orthogonality, with some partial overlap reflecting data similarity.
At inference, a lightweight neural network meta-router computes deep-semantic prompt features and outputs independent sigmoid weights per domain stack. Instead of using domain labels, routing targets are empirically discovered via exhaustive loss minimization over stack combinations on each prompt. This enables non-exclusive cross-domain composition and empirically demonstrates that “domains” encode reusable cognitive primitives, not strictly domain-specific knowledge.
Empirical Findings and Analysis
On TinyLlama-1.1B and Gemma 3 12B IT, MoE-LoRA achieves 2.5× faster convergence than parameter-matched single LoRA (Figure 3), and residual stacking consistently improves validation loss over single-stack baselines (Figure 4).
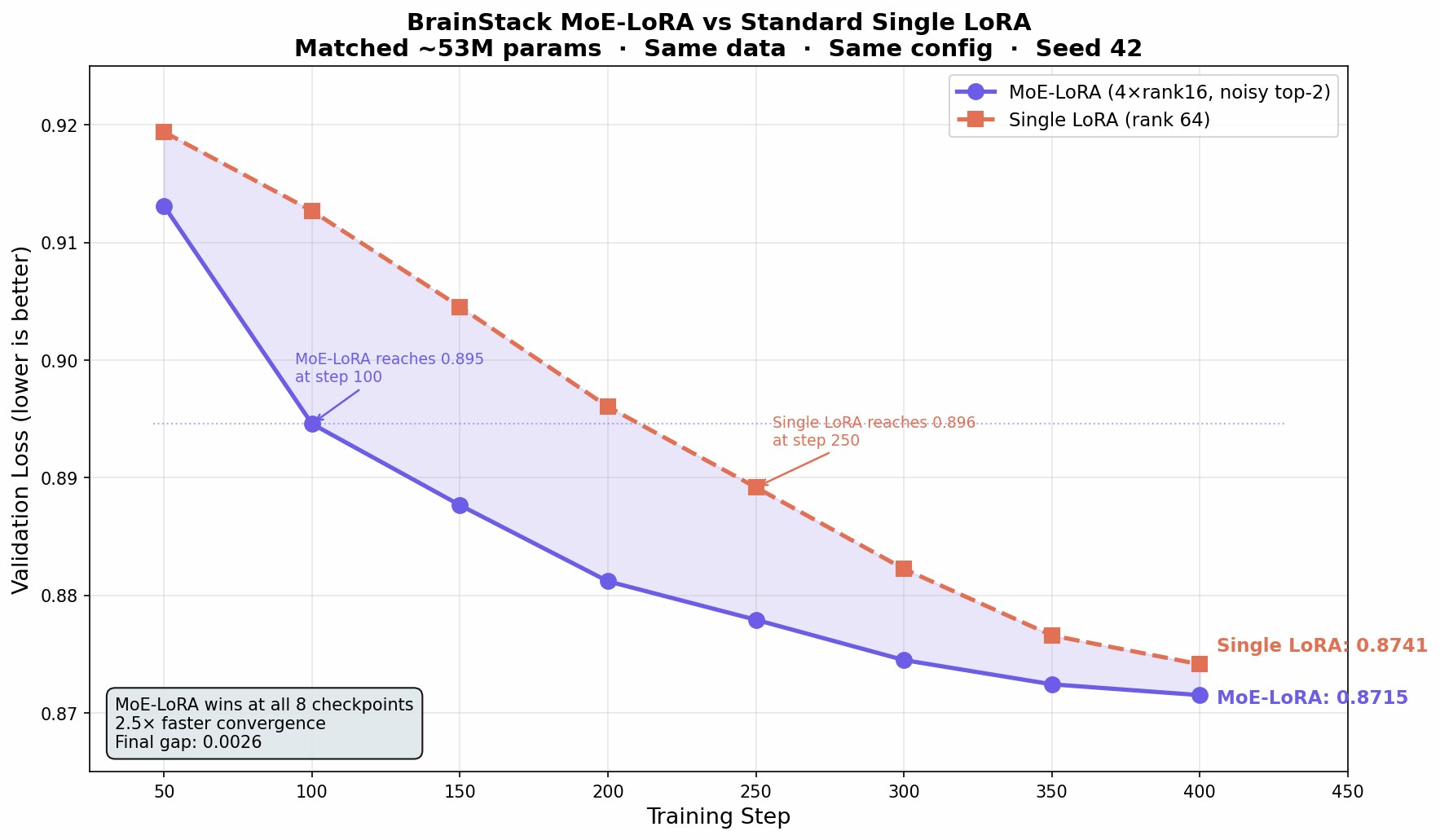
Figure 3: MoE-LoRA achieves faster per-step convergence in validation loss compared to standard LoRA.
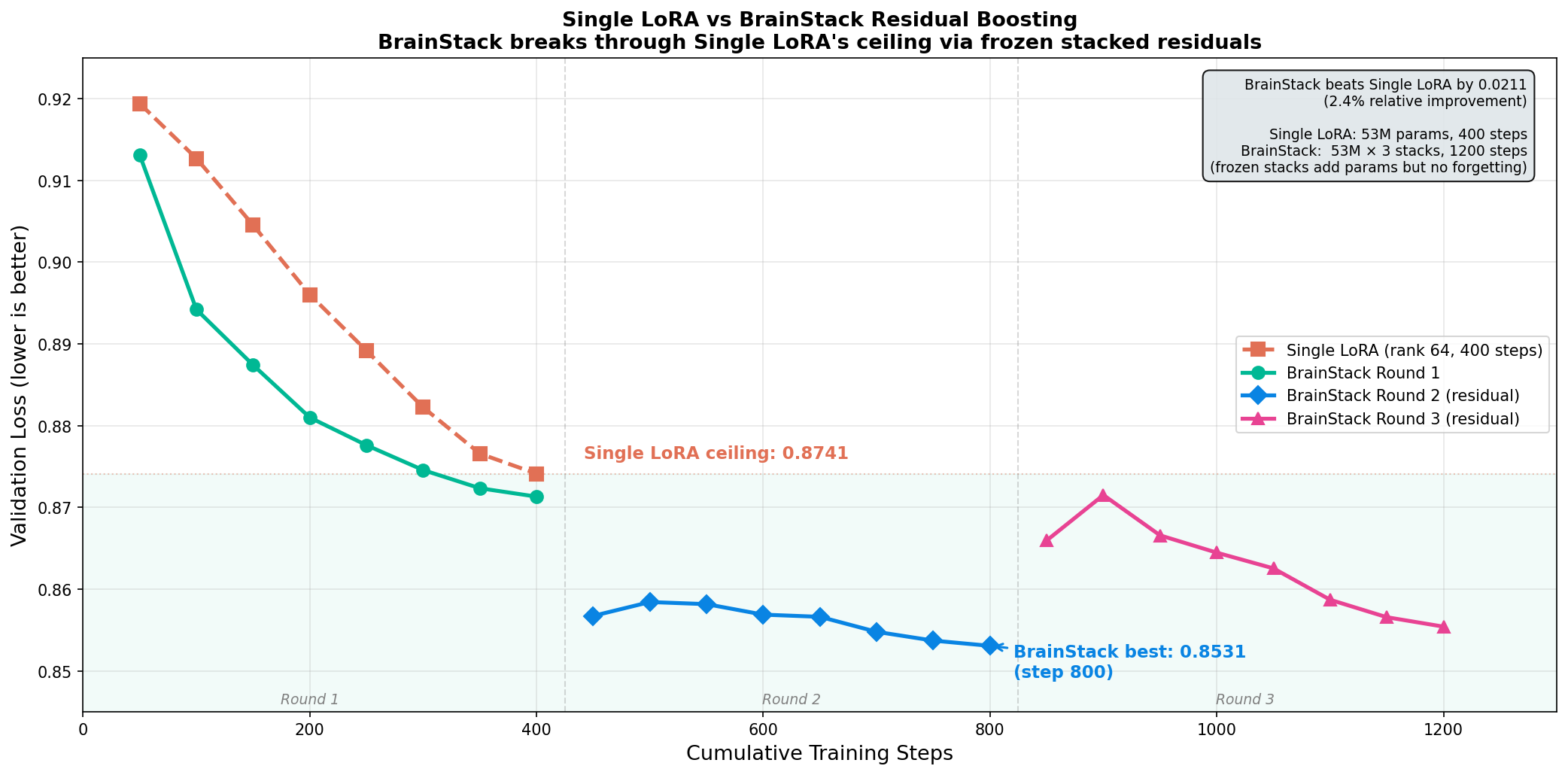
Figure 4: Residual boosting with Brainstacks surpasses single LoRA’s performance ceiling for the chat domain.
In the continual fine-tuning setting, the null-space projection consistently reduces cross-domain interference over standard stacking (Figures 5–7), with difference gains reaching up to −0.143 on the math domain following full stacking. Importantly, when stacks are evaluated individually (with the meta-router), validation losses for each domain match the value witnessed at train time, confirming zero-forgetting.
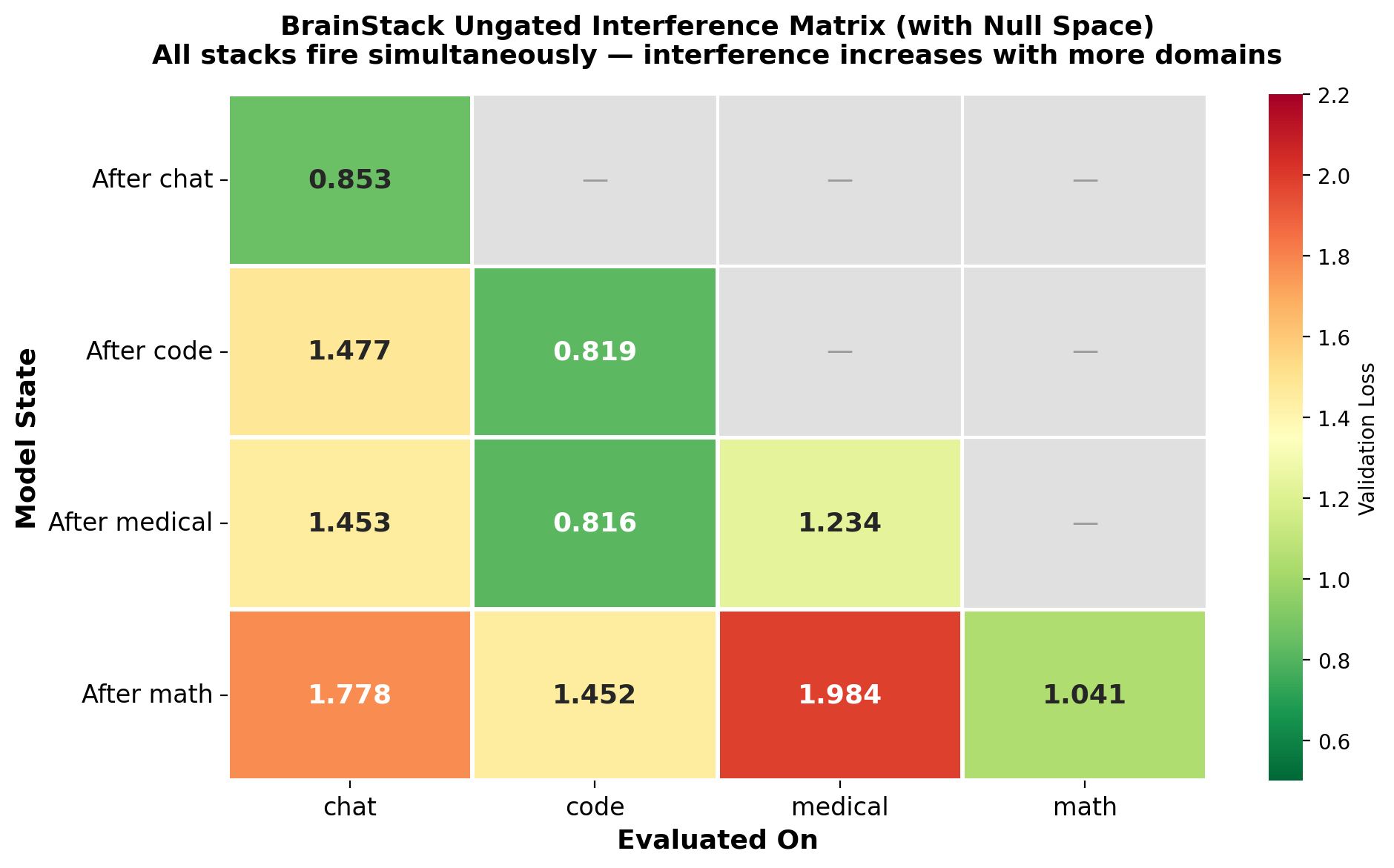
Figure 5: Ungated interference matrix (with null-space projection)—additive domain stacking increases magnitude, but not forgetting, as frozen weights are unchanged.
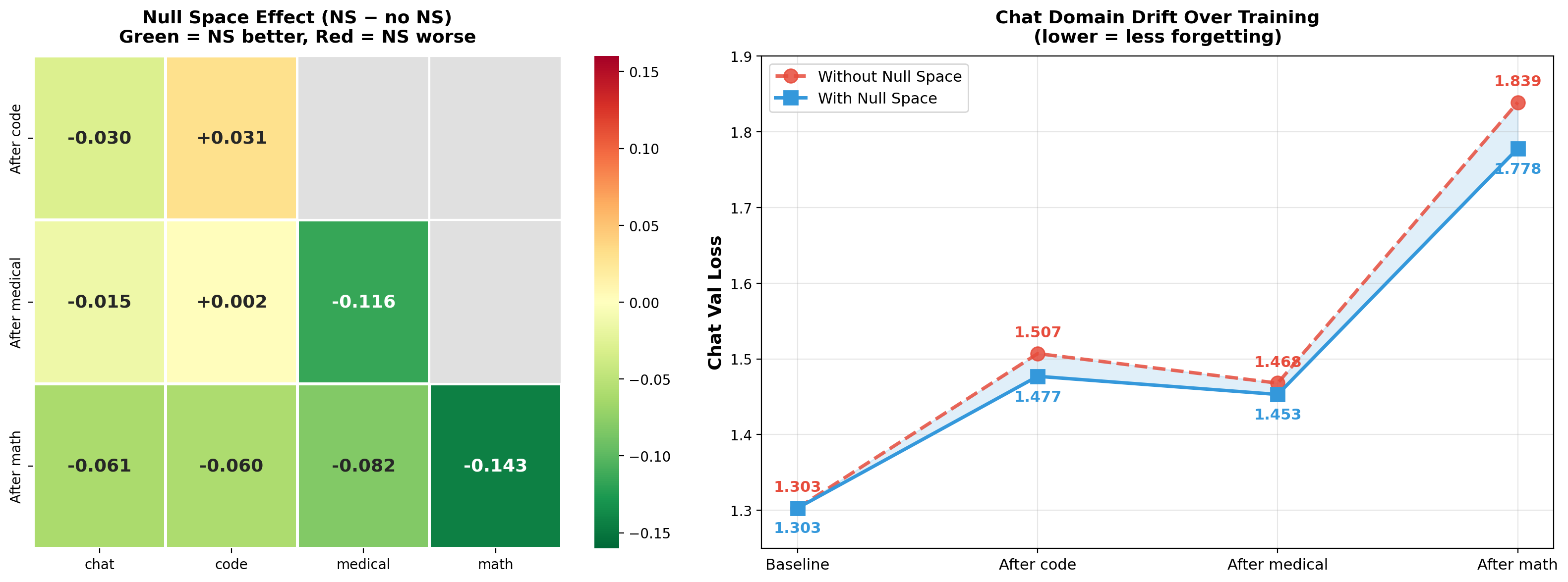
Figure 6: Null-space projection consistently protects prior domains from interference; larger benefit as additional domains are stacked.
Zero-shot evaluation on eight benchmarks shows that the routed Brainstacks system maintains base LLM performance across all tasks, with per-benchmark differences falling within sampling noise and no catastrophic degradation from accumulating stacks (Figure 7).
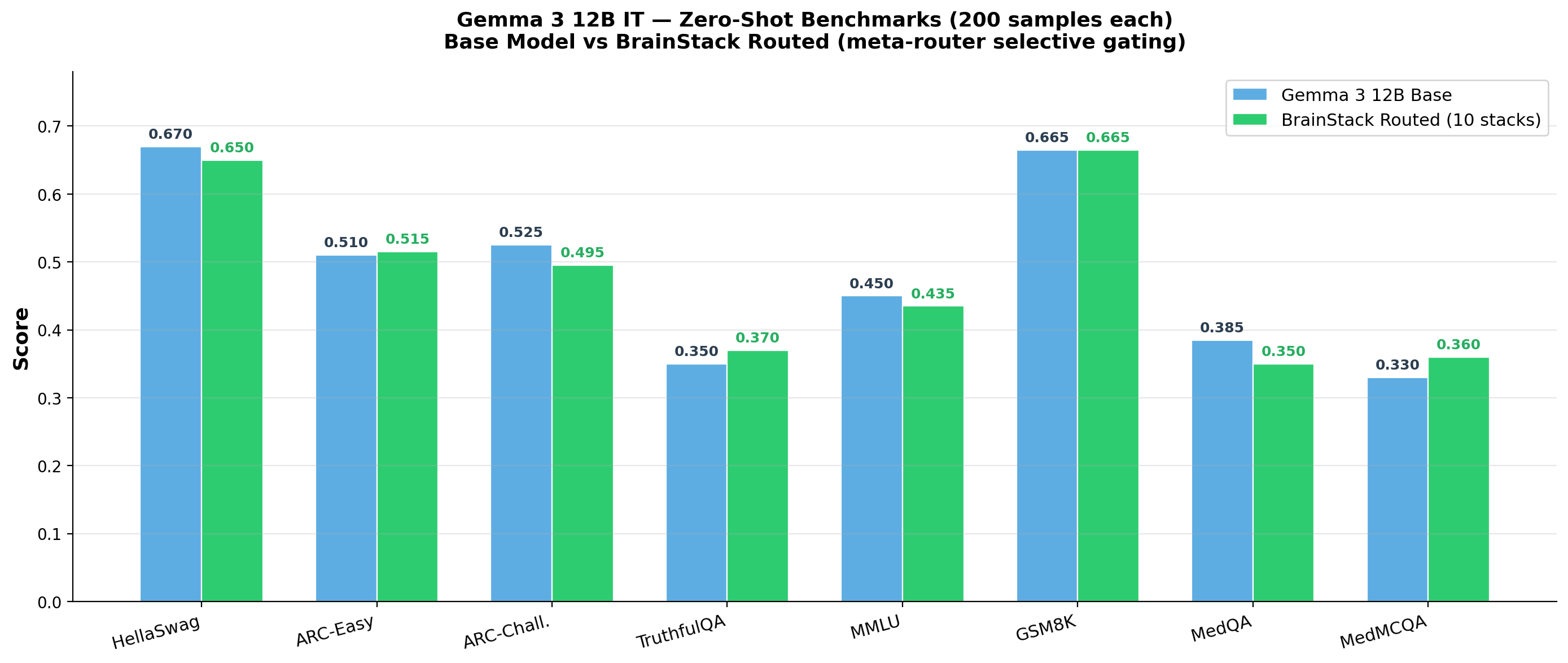
Figure 7: Zero-shot performance parity between base model and Brainstacks with routed meta-composition on Gemma 3 12B IT.
Cognitive Primitives Beyond Knowledge Storage
A central claim, evidenced by empirical routing data and ablation studies, is that domain stacks encapsulate reusable cognitive primitives—such as instruction-following, stepwise reasoning, and procedural logic—rather than merely memorizing domain-specific knowledge. For example, medical prompts routed to chat+math stacks in 97% of test cases, despite those stacks never being exposed to medical data. Transfer arises from the acquisition of fundamental compositional abilities that are leveraged across domains, as opposed to classical domain-knowledge isolation.
Orthogonality and Subspace Analysis
Principal subspace analyses confirm the enforced separation of domain-induced directions (Figures 5, 9, 10, 11), with distributed singular value spectra indicating that most domain information is captured in top SVD directions, leaving considerable hidden-dimension capacity for further domain addition. Per-layer orthogonality measurements exhibit robust domain separation across transformer depth.
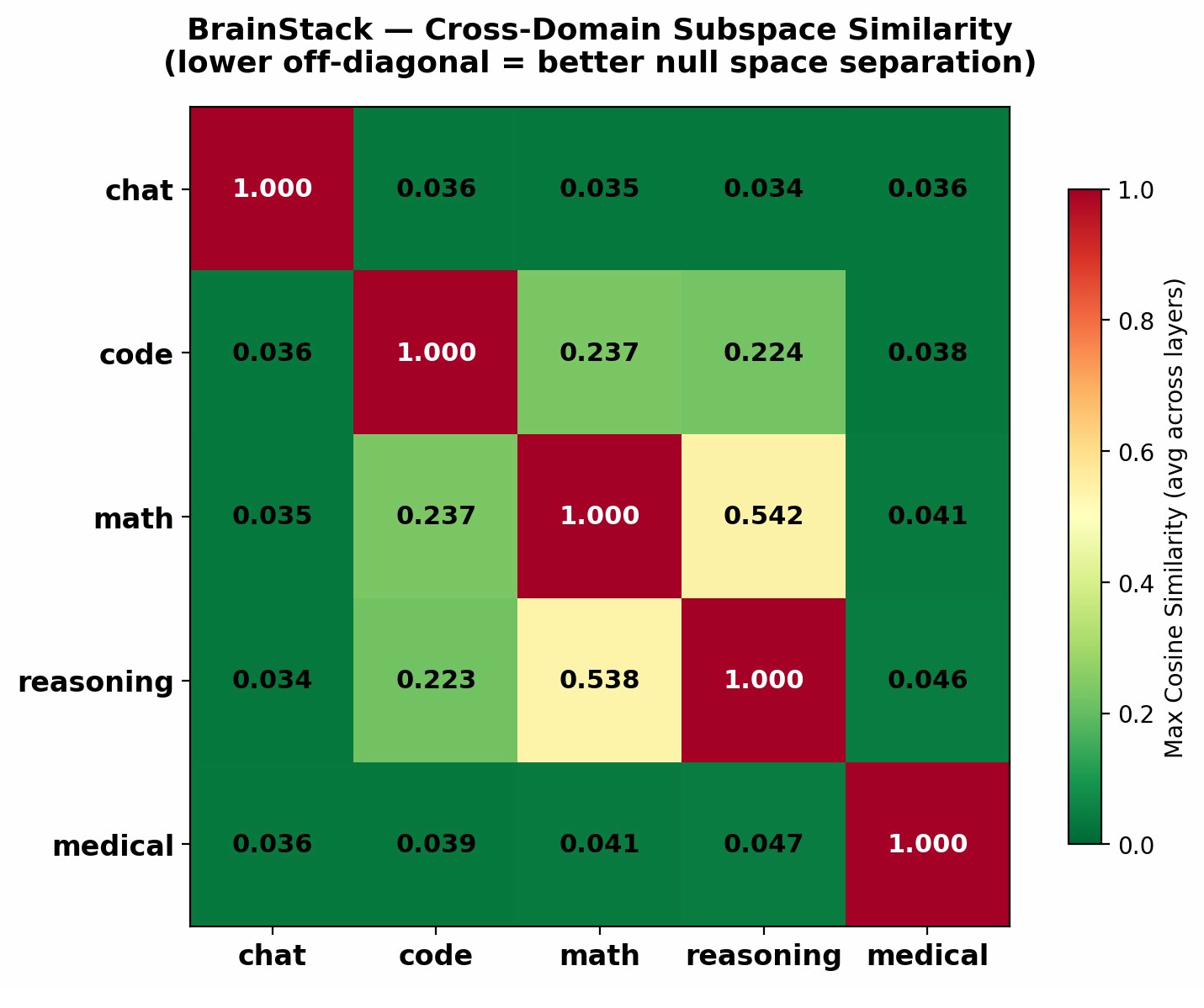
Figure 8: Cosine similarities of principal subspace directions are low, supporting orthogonal separation.
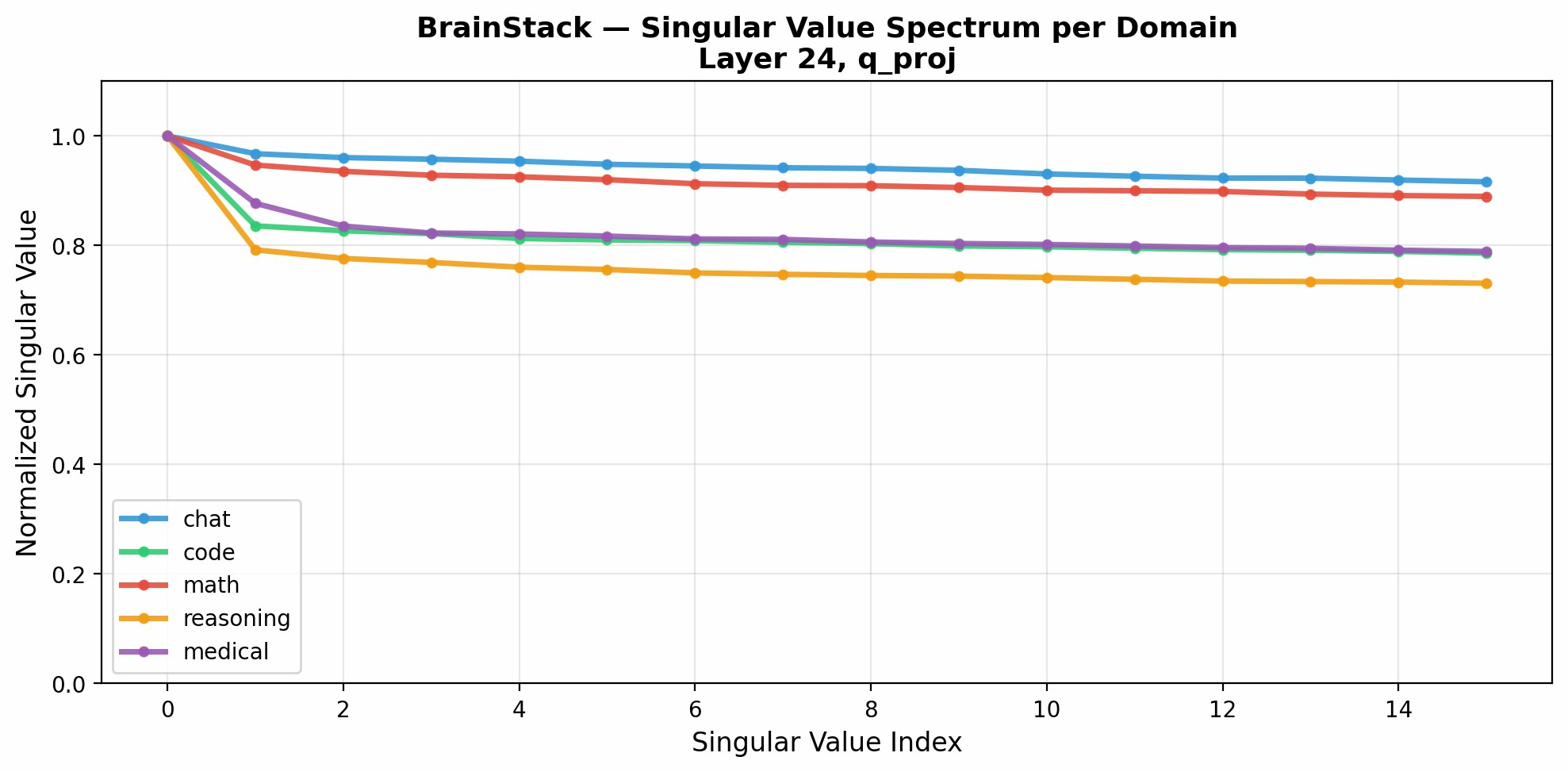
Figure 9: Singular value spectra per stack show that most information is highly concentrated in a subset of directions.
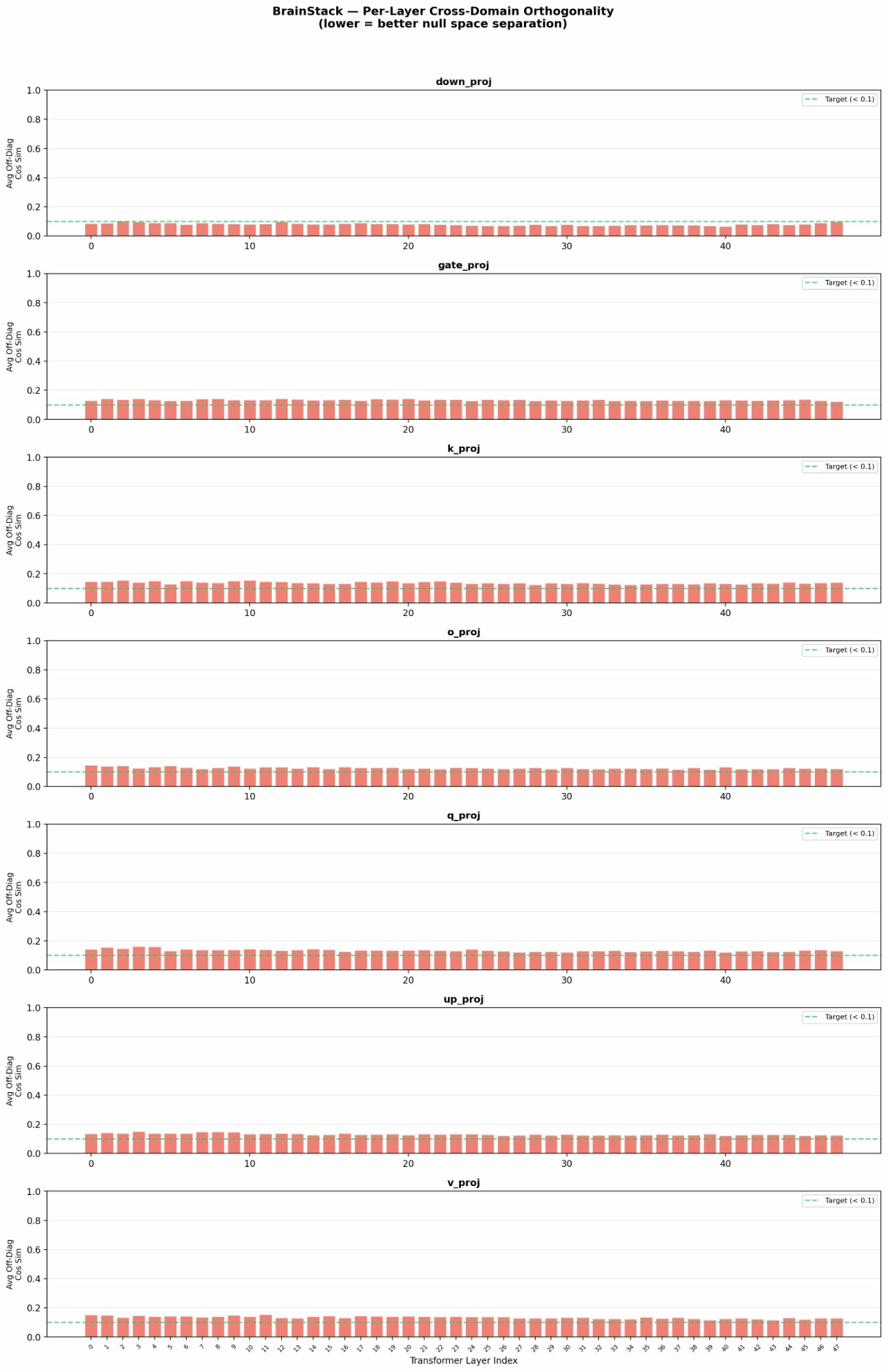
Figure 10: Orthogonality between domain stacks is maintained across all transformer layers.
Modular Inference and Superposition Principle
Stacked adapters are disk-resident and loaded on-demand as determined by the meta-router, enabling a form of “Superposition LLM” where GPU memory overhead remains constant regardless of the number of domain plugins present on disk.
Implications and Future Directions
Brainstacks embodies several core implications for scalable, modular AI systems:
- Zero-forgetting guarantee: Orthogonality and freezing ensure that new domains do not corrupt existing capabilities, addressing catastrophic forgetting at both algorithmic and architectural levels.
- Transfer via capability injection: The practical observation that stacks encode cognitive skills rather than pure knowledge fundamentally shifts the framing of adapter-based LLMs—future scaling can prioritize compositional capability injection and precise control over knowledge transfer.
- Composable expertise: Empirically discovered cross-domain compositions suggest that a modest inventory of cognitive primitives, each with a dedicated stack, can combine to address an exponentially larger set of practical tasks, dramatically increasing efficiency of continual learning.
- Route-aware distillation and compression: The modular, routed ensemble design is amenable to knowledge distillation techniques for compact, deployment-friendly models, but distilled objectives must respect expert compositionality for high-fidelity student performance.
- Scaling and resource efficiency: Hidden-dimension capacity scaling allows stacking of tens to possibly hundreds of domains on large LLMs, with projected singular vectors consuming only a fraction of the subspace per domain.
Among several future directions, latent-space compression (e.g., LatentMoE), full continual domain pretraining (Partitioned Subspace Networks), robust per-domain RL, and autonomous capability expansion via gap detection are particularly promising.
Conclusion
Brainstacks presents a unified framework for modular, continual LLM learning with mathematically enforced domain separation and empirically driven compositional routing. The combination of residual stacking, null-space projection, and outcome-gated inference yields a system that robustly preserves, composes, and scales domain-specific and cross-domain capabilities without interference or catastrophic forgetting. The key empirical finding—that adapters encode generalizable cognitive primitives rather than only domain-specific content—reorients future research toward compositionality and modularity, with significant implications for lifelong learning, AI safety, and deployment at scale.