- The paper introduces a novel token-level adaptive router that dynamically blends base LLM outputs with reward signals for improved reasoning.
- It leverages step-wise mathematical traces to guide reward models, yielding up to +22.4% accuracy improvements on MATH500.
- Its architecture-agnostic design allows routers trained on small models to generalize to larger LLMs without retraining.
Token-Level Adaptive Routing for LLM Test-Time Alignment: An Expert Analysis of TARo
Introduction
Recent developments in LLMs underscore their reasoning capacity; however, effective reasoning on challenging domains, such as mathematics and clinical medicine, often requires expensive post-training regimens like RLHF and RLVR. Test-time alignment methods that steer frozen LLMs with reward models provide a parameter-efficient and computationally lightweight alternative, but prevailing approaches—most notably fixed-weight token blending—fail to robustly improve reasoning performance, exhibit domain sensitivity, and lack adaptability across model scales. The paper "TARo: Token-level Adaptive Routing for LLM Test-time Alignment" (2603.18411) addresses these deficiencies by proposing Token-level Adaptive Routing (TARo), a method that introduces a learnable token-level router, trained on step-wise mathematical reasoning traces. This router dynamically modulates the contributions of the base LLM and the reward model, providing fine-grained, adaptive guidance without manual hyperparameter tuning.
Motivation and Limitations of Prior Test-Time Alignment Approaches
Test-time alignment methods such as GenARM parameterize the next-token distribution using a weighted sum of base and reward model outputs, where the mixing coefficient α is fixed across all domains and decoding steps. Empirical evidence demonstrates that the optimal value for α varies with the task, base model, and domain; a value that improves performance in one domain may degrade it in another, leading to brittle test-time guidance.
Notably, the paper provides a detailed evaluation of GenARM's sensitivity to α on MATH500 (reasoning) and AlpacaEval (instruction following), showing that fixed weights can cause the guided model to underperform even the base model.
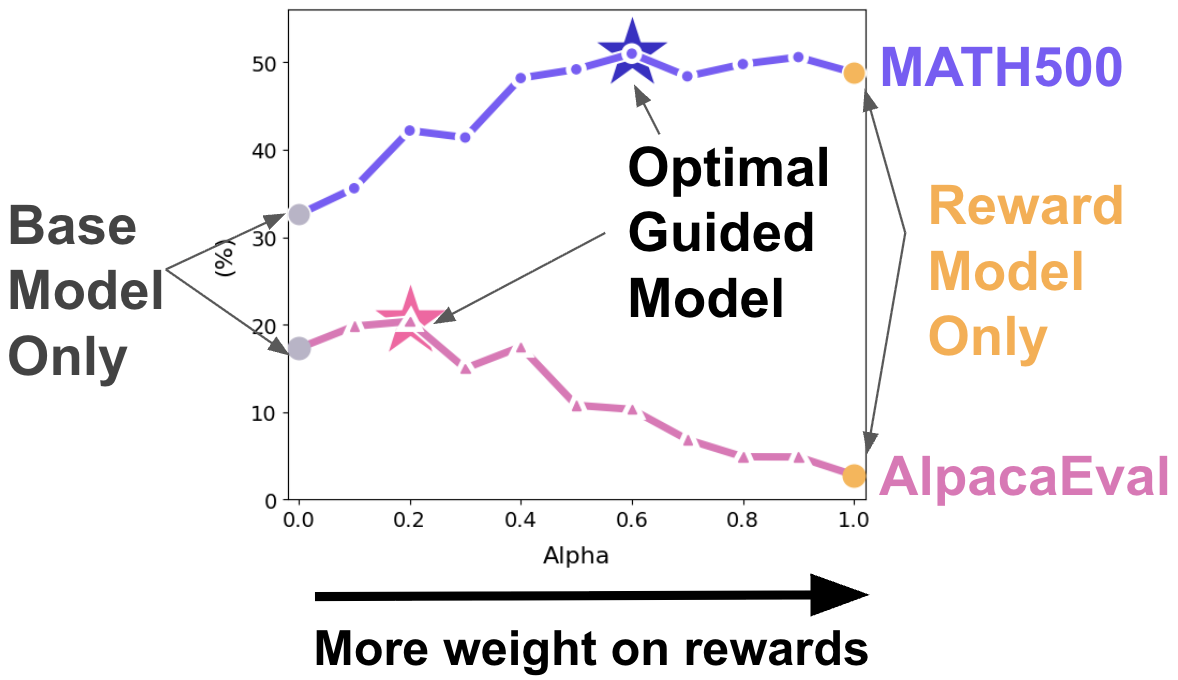
Figure 1: Performance on MATH500 and AlpacaEval for GenARM under different fixed mixing coefficients α, exposing instability and the necessity for domain-adaptive guidance.
TARo: Methodology
Step-wise Token-Level Reasoning Rewards
Differentiating from preference-aligned reward models, TARo leverages step-wise mathematical traces (e.g., Math-StepDPO-10K dataset) to train reward models that explicitly capture token-level logical consistency. A paired-step preference loss enforces higher likelihoods for logically valid continuations, promoting fine-grained rewards for correctness at each reasoning step.
Token-Level Adaptive Router
The central innovation in TARo is the learnable router gθ, a shallow MLP that consumes features derived from both base and reward model logits at each decoding step and outputs a routing coefficient αt, dynamically controlling the influence of reward guidance. Two feature construction strategies are explored:
- Full-logits concatenation: Concatenates the entire logits from both models, utilizing the vocabulary-wide score distributions.
- Top-k logits with index embeddings: Focuses on the top probable tokens, augmenting logit values with learnable token-index representations for compactness and cross-model transferability.
The router is trained to maximize target token probabilities via the guided distribution and regularized for confident (i.e., low-entropy) routing. Importantly, this operation is scale- and domain-agnostic, enabling plug-and-play application on larger-scale base models without retraining.
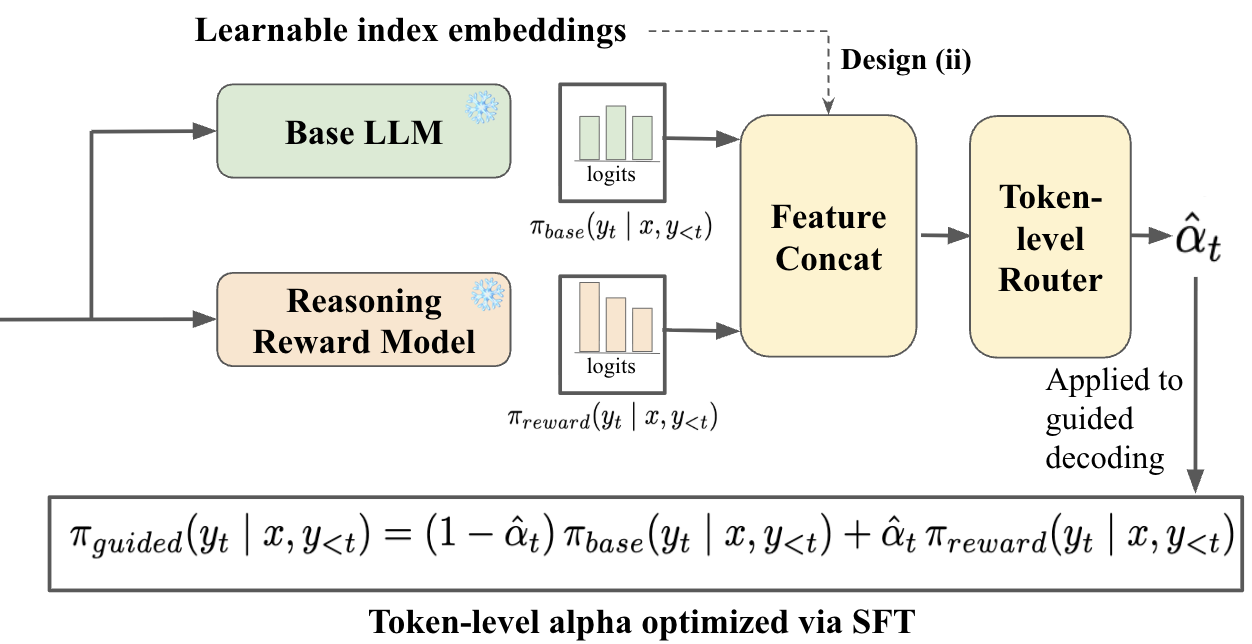
Figure 2: TARo's learnable token-level router design, enabling step-wise, adaptive mixture between base and reward models during generation.
Empirical Evaluation
Benchmarks and Comparative Results
TARo is validated on in-domain (MATH500), out-of-domain (MedXpertQA), and general (AlpacaEval) tasks, using both Llama and Qwen family models with step-wise-trained reward models. TARo significantly outperforms both base and reward models individually and achieves higher accuracy compared to GenARM and competitive methods such as UniR—demonstrating up to +22.4% absolute accuracy improvement over baseline LLMs and +8.4% over token-level fixed-weight routing on MATH500.
Additionally, TARo exhibits robust performance on clinical (MedXpertQA) and instruction-following tasks (AlpacaEval). Notably, unlike GenARM, TARo does not suffer performance degradation relative to base models when reward models are weaker, as it adaptively suppresses reward signals where detrimental.
Weak-to-Strong Generalization
A salient property is TARo's weak-to-strong generalization: routers trained alongside small LLMs generalize effectively to larger models (e.g., Llama-3.1-70B, Qwen-2.5-14B), obviating the need for router retraining and extending the utility of token-level alignment across scales.
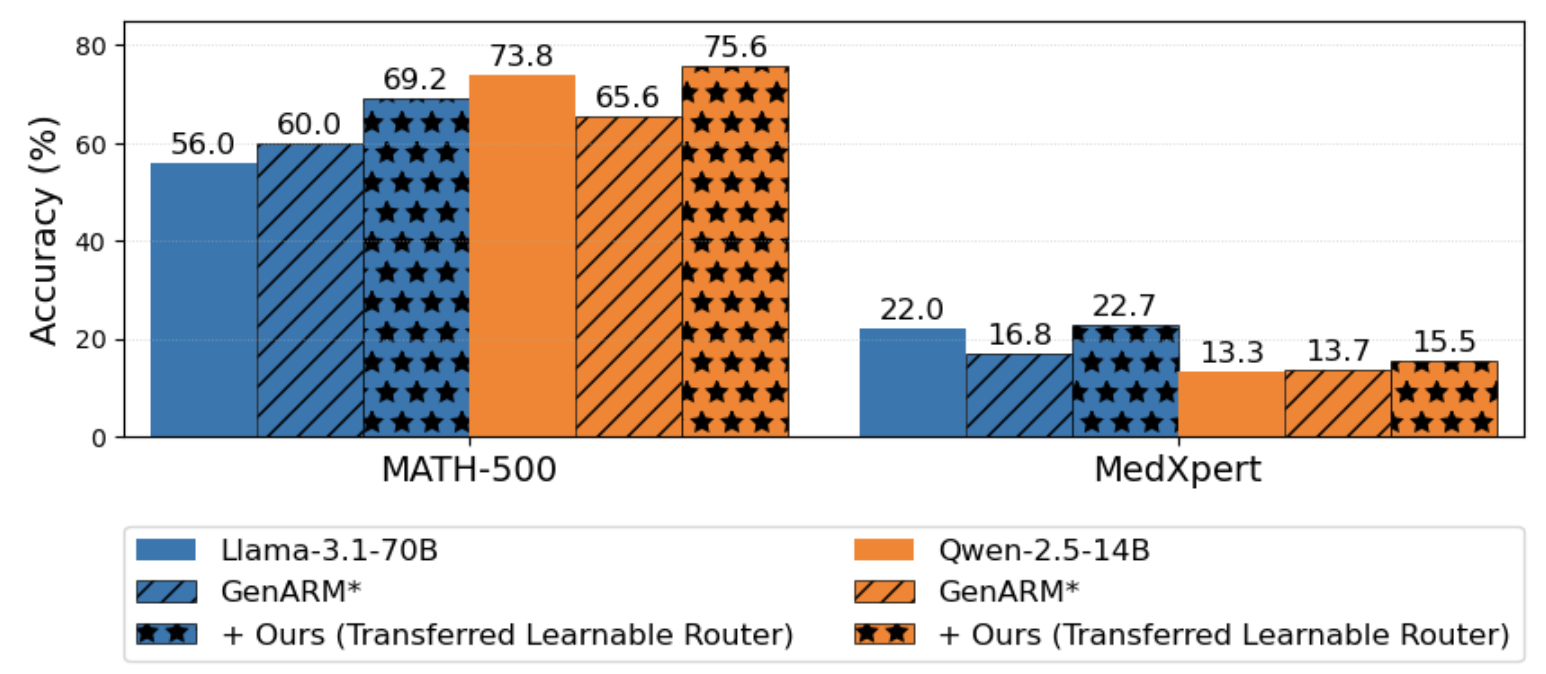
Figure 3: Weak-to-strong generalization—routers and reward models trained on small base models transfer to large backbones without retraining, yielding significant performance gains.
Router Behavior and Analysis
Token-level αt analysis reveals that the router preferentially delegates mathematically salient or structural tokens (e.g., operators, scaffolding) to the reward model, while the base model handles context tokens, preserving both domain-general fluency and logic. Ablation studies show that router designs using logits rather than hidden states are both architecture-agnostic and more performant; token-level granularity is critical, as prompt-level interpolation fails to capture the requisite reasoning control.
Theoretical and Practical Implications
TARo demonstrates that fine-grained, step-wise reward signals—when modulated adaptively at the token level—can robustly enhance LLM reasoning without post-training. This architecture-agnostic, plug-and-play mechanism facilitates rapid deployment of reward-guided alignment across diverse tasks and model sizes, a critical property as LLMs scale and application scenarios diversify. Its inference-time cost is competitive with prior work, and its lightweight router (on top of frozen models) is suitable for industrial deployment scenarios where frequent retraining is infeasible.
Theoretically, TARo bridges mixture-of-experts style adaptive gating and test-time alignment for LLMs, opening up possibilities for dynamic, compositional control over LLM outputs—such as incorporating multiple domain-specific reward models or integrating dynamic reward guidance with agentic behaviors.
Future Directions
TARo's modular framework invites further exploration into multi-reward model routing, domain-adaptive router objectives, and structured routing for tool-usage and reasoning decomposition tasks. Deeper integration with LLM agentic frameworks, as well as theoretical analyses of the optimality of token-level adaptive mixtures, are promising research directions.
Conclusion
TARo establishes a new test-time alignment paradigm by combining reasoning-aware reward models and a learnable token-level router, enabling robust, compute-efficient reasoning modulation for frozen LLMs. This approach overcomes key limitations of fixed-weight test-time alignment and sets a precedent for scalable, domain-agnostic reasoning optimization without the prohibitive costs of large-scale post-training (2603.18411).