- The paper introduces a unified bilevel framework that integrates test-time optimization with feed-forward 3D Gaussian Splatting to produce robust Gaussian initializations.
- The paper employs an efficient differentiable optimization layer using implicit gradients and a PCG solver, achieving notable PSNR improvements on datasets like RE10K and ScanNet++.
- The paper incorporates uncertainty-aware proximal regularization to adaptively modulate Gaussian updates, effectively reducing overfitting in ambiguous, sparse-view scenarios.
Diff3R: Optimization-Aware and Uncertainty-Regulated 3D Gaussian Splatting
Introduction
Diff3R proposes a unified framework that explicitly integrates test-time optimization (TTO) into the training of feed-forward 3D Gaussian Splatting (3DGS) networks, addressing critical limitations in sparse-view novel view synthesis. The method is grounded in a bilevel optimization paradigm, training networks not to directly predict final Gaussian parameters, but to predict optimal initializations for downstream optimization. The central contributions are: (i) an efficient, model-agnostic differentiable optimization layer utilizing implicit gradients and a scalable Preconditioned Conjugate Gradient (PCG) solver, and (ii) a data-driven uncertainty-aware proximal regularization scheme to mitigate overfitting during under-constrained optimization.
This approach is motivated by the observation that feed-forward 3DGS, though fast and generalizable, suffers from poor zero-shot reconstructions and catastrophic overfitting upon naive TTO, especially in highly ambiguous, sparse-view regimes. Diff3R fundamentally revisits the model’s objective: optimizing explicit scene representations not for immediate quality, but for downstream adaptability within robust, differentiable optimization.
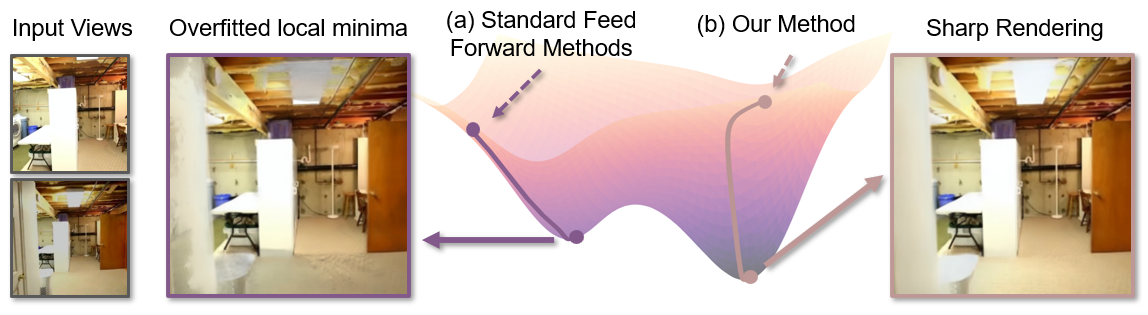
Figure 1: Comparison between standard feed-forward 3DGS, which suffers from artifacts after TTO in sparse-view settings, and Diff3R, which learns an optimization-aware initialization via implicit gradients.
Differentiable 3DGS Optimization Layer
At training, Diff3R unrolls a two-level process: the inner loop performs brief TTO (minimizing photometric + proximal losses with regularization toward the feed-forward prior), and the outer loop backpropagates novel-view errors to network parameters. Rather than differentiating through all inner iterations, which is infeasible due to the scale of 3DGS (millions of parameters), Diff3R exploits the Implicit Function Theorem to derive an analytical optimality condition for the inner loop, employing the Gauss-Newton Hessian approximation.
The backward pass reduces to solving a large but tractable linear system using a matrix-free PCG approach, where the regularization/damping term is naturally coupled to the proximal loss, structurally paralleling Levenberg-Marquardt optimization. The result is end-to-end supervision on the entire pipeline with negligible memory overhead compared to direct unrolling, and computational complexity that scales efficiently with scene size.
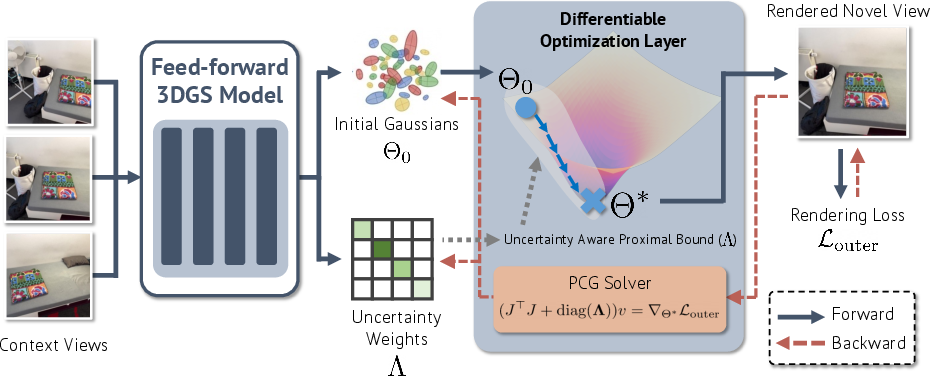
Figure 2: Overview of the differentiable 3DGS optimization framework, where network-predicted Gaussians are refined via a differentiable optimization layer with learnable uncertainty weights.
Uncertainty-Aware Proximal Regularization
Static, global proximal regularization is ill-suited for heterogeneous input reliability; over-constraining all parameters limits TTO effectiveness, while under-constraining leads to local overfitting and floaters in ambiguous regions. Diff3R introduces learnable per-Gaussian, per-attribute uncertainty weights, predicted alongside the Gaussian parameters by the feed-forward network itself and updated indirectly via outer-loop supervision. These uncertainty values act as adaptive anchors, selectively modulating the optimization trajectory of each Gaussian according to the network’s intrinsic prediction confidence—without access to ground-truth uncertainty maps.
Gradients with respect to these uncertainty parameters are analytically derived (again via IFT), resulting in efficient updates that penalize overconfident adaptation and promote flexibility where necessary. This mechanism substantially improves robustness to input outliers and exposure/illumination inconsistencies, especially in the sparse-view regime.

Figure 3: Visualization of learned uncertainty weights, indicating higher regularization in regions lacking multi-view coverage, which prevents overfitting during TTO.
Experimental Results
On RealEstate10K (RE10K) and ScanNet++, Diff3R is consistently superior to leading feed-forward baselines and recent meta-learned 3DGS variants under both pose-given and pose-free conditions. After TTO, Diff3R achieves:
- +0.27 dB PSNR improvement versus DepthSplat on RE10K (pose-given, 2 views).
- +0.76 dB PSNR improvement versus AnySplat on RE10K (pose-free, 4 views).
- +0.35 dB PSNR gain versus DA3 on ScanNet++ (DSLR modality).
Notably, baseline feed-forward models generally either do not improve or degrade after TTO due to overfitting, whereas Diff3R systematically increases rendering metrics post-optimization. Qualitative inspection confirms that Diff3R yields sharper, artifact-free novel views, with marked resilience to exposure discrepancies and ambiguous geometry.

Figure 4: Qualitative comparison on RE10K, demonstrating that Diff3R improves detail and artifact suppression after optimization.

Figure 5: ScanNet++ results where Diff3R reduces artifacts and enhances sharpness compared to Depth Anything v3 after TTO.
Ablative Analysis
Removing the proximal term (i.e., unconstrained optimization) results in less consistent and sometimes worse performance due to runaway updates in ill-conditioned regions. Disabling uncertainty-aware regularization (using a global scalar) makes the optimization overly conservative, suppressing potential gains and aligning with standard feed-forward limitations. Both mechanisms are essential; only their combination enables substantial and robust improvement in both zero-shot initialization and post-optimization quality.
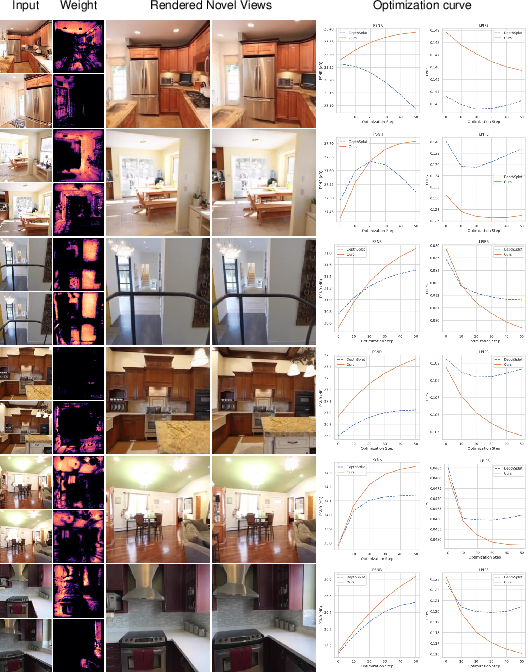
Figure 6: Predicted uncertainty weights penalize updates in non-overlapping regions, aiding robust TTO and effective initialization.
Practical and Theoretical Implications
By bridging meta-learned feed-forward models with flexible, uncertainty-regularized test-time optimization, Diff3R sets a new standard for 3DGS under data/constraint-limited settings. Its model-agnostic optimization layer can be retrofitted to diverse architectures, including both pose-given and pose-free pipelines, making it highly practical and extensible. The uncertainty modeling technique is equally general, offering a differentiable mechanism for confidence-calibrated parameter updates in any large-scale differentiable optimization pipeline.
Theoretically, Diff3R demonstrates that bilevel optimization via implicit differentiation and adaptive regularization provides a scalable solution to the classic stability-plasticity dilemma in learned reconstruction models—a pertinent insight for future high-dimensional geometric learning systems. The method’s computational bottleneck remains in training due to repeated TTO steps; however, no runtime penalty is incurred at inference, preserving real-time deployment viability.
Conclusion
Diff3R effectively merges the speed of feed-forward approaches with the fidelity of optimization-based methods for 3D Gaussian Splatting. Its differentiable, uncertainty-aware optimization layer allows networks to learn optimal TTO-aware initializations; per-parameter adaptive regularization mitigates overfitting and enhances adaptability—particularly in sparse, ambiguous scenarios. While the training cost increases modestly, the approach generalizes broadly across 3D vision tasks and architectures, with significant implications for robust, adaptive, uncertainty-calibrated scene representation learning. Future directions include dynamic/temporal scene extension, SLAM, and joint optimization of cameras and geometry under uncertainty.

