- The paper introduces a diagnose-and-repair framework that localizes failures and applies targeted, minimal-cost repairs in Agentic RAG.
- It decomposes error remediation into taxonomy-constrained diagnosis and tool-conditioned local repair, achieving significant EM, F1, and ROUGE-L gains.
- DR-RAG reduces token consumption and computational overhead by reusing validated reasoning prefixes, improving efficiency across multiple datasets.
Doctor-RAG: Failure-Aware Repair for Agentic Retrieval-Augmented Generation
Introduction
Agentic Retrieval-Augmented Generation (Agentic RAG) paradigms have matured to address complex multi-hop question answering and knowledge reasoning through the dynamic interleaving of search, retrieval, and reasoning actions during inference. However, as reasoning trajectories lengthen and tasks become more compositional, failures accumulate due to diverse factors, from retrieval gaps to local reasoning missteps. Current methods for failure remediation predominantly resort to full trajectory re-execution or diagnostic-only approaches, both incurring significant overhead or failing to yield practical gains. "Doctor-RAG: Failure-Aware Repair for Agentic Retrieval-Augmented Generation" (2604.00865) introduces DR-RAG, a systematized diagnose-and-repair architecture that targets these limitations by modularizing failure handling into explicit error localization and minimal-cost, locally focused repair operations.
Agentic RAG Failures: Characterization
Empirical analysis demonstrates that error sources in Agentic RAG under ReAct-style baselines are multifactorial, spanning reasoning, searching, retrieval, and formatting. As illustrated by the error statistics on HotpotQA under the ReAct paradigm, error frequencies are distributed across multiple types—no single category dominates. This reveals the necessity of handling failures with fine-grained, category-aware interventions, as monolithic or unconditional rerun protocols are inherently inefficient.
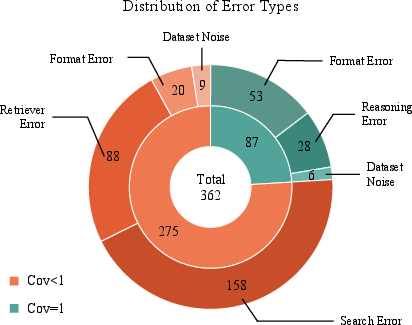
Figure 1: Distribution of error types in Agentic RAG (ReAct baseline, HotpotQA), revealing significant heterogeneity and motivating localized failure repair.
DR-RAG Framework
DR-RAG decomposes post hoc failure remediation in Agentic RAG into two fundamental stages: (1) taxonomy-constrained diagnosis and localization and (2) tool-conditioned local repair.
The first stage operationalizes failure attribution via a coverage-gated error taxonomy, supported by an LLM-based evidence sufficiency judge. Failures are mapped to categories: format error, reasoning logic error, retriever error, or search error. Moreover, DR-RAG localizes the error along the trajectory, identifying the earliest infeasible step using observable state signals, thereby partitioning the trajectory into a reusable prefix and a discarded suffix.
The second stage leverages error-type-specific repair operators that minimize recomputation:
- For format errors, targeted answer rewriting suffices.
- For reasoning logic errors under full coverage, reasoning is regenerated from the localized failure point using retained evidence.
- For retriever and search errors under partial coverage, query rewriting, augmented retrieval, or planning-based re-execution is performed beyond the localized failure site.
This architecture maximizes validated prefix reuse, averting the cost of trajectory-wide reruns and avoiding regeneration of correct prior reasoning/evidence modules.
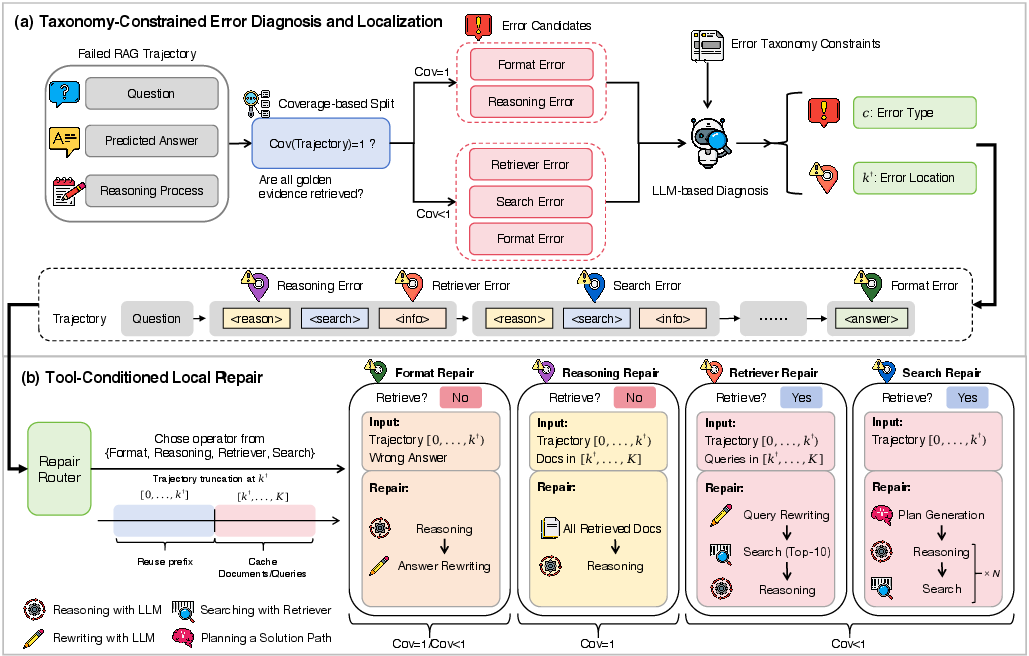
Figure 2: Overview of DR-RAG's workflow, emphasizing diagnosis/localization followed by tool-conditioned, prefix-reusing local repair at the failure point.
Empirical Evaluation
Main Results
DR-RAG was evaluated across HotpotQA, 2Wiki, and MuSiQue, using Qwen3-8B, LLaMA-3.1-8B-Instruct, and Qwen3-4B backbones on strong agentic baselines (ReAct, Search-o1, Search-R1). Compared to rerun, step-wise retry, and RAG-Critic methods, DR-RAG yields:
- Substantial EM, F1, and ROUGE-L improvements: e.g., on Qwen3-8B/ReAct, DR-RAG improves EM on HotpotQA by 25.8% over baseline.
- Severe reduction in token cost: DR-RAG's token consumption is 26.8% lower than full rerun, providing practical compute and wall-clock savings.
DR-RAG's improvements are robust across models and scales. Gains are amplified on smaller models, indicating utility for both strong and resource-constrained LLM deployments.
Efficiency
Both token and inference time efficiency are validated across datasets and agent frameworks. The DR-RAG approach uniformly achieves the lowest computational overhead. This is attributed to effective prefix reuse and intervention only at localized failures, aligned precisely with the error taxonomy and localization mechanism.
Diagnosis Reliability
Automated diagnosis achieves 60–70% accuracy against human annotation (stratified by evidence coverage). Most confusions occur only between adjacent error types, particularly under partial coverage where missing evidence can obscure true causal attribution. However, the sufficiency of diagnosis quality for practical downstream repair is empirically confirmed.
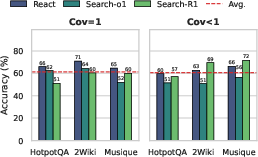
Figure 3: Automated diagnosis accuracy versus human annotation, stratified by dataset and agentic RAG baseline.
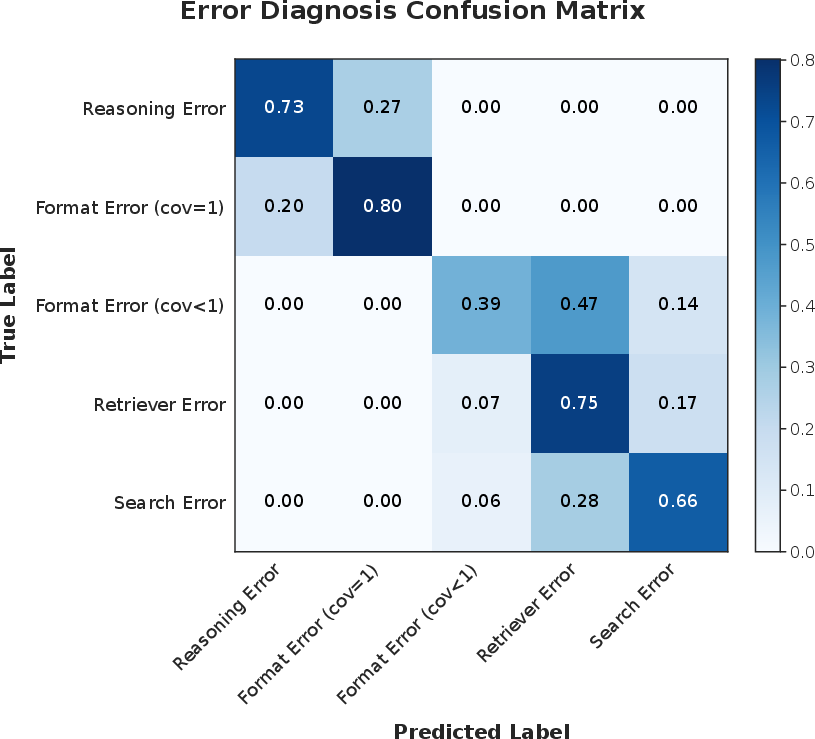
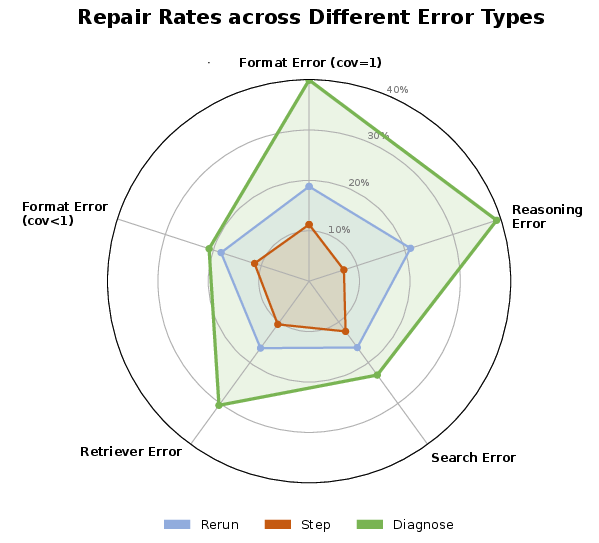
Figure 4: Confusion matrix of automated diagnosis, demonstrating high precision in major error categories with ambiguities primarily between closely related types.
Error-Type-Specific Repair Analysis
DR-RAG's substantial repair success is concentrated in localized errors—format and reasoning logic errors under full coverage—where 40–100% of cases are successfully repaired in several task configurations. Performance on retriever and search errors is lower, as these are confounded by fundamental evidence or planning limitations.
Case Study
A representative example underscores the benefit of localized repair. Given a multi-hop geographical comparison question (HotpotQA), an agent retrieves the correct evidence but performs an incorrect reasoning step, producing a wrong answer. DR-RAG successfully localizes the failure at the reasoning step (not the retrieval), repairs only the misstep while reusing the evidence, and provides the correct answer without redundant querying or answer regeneration.
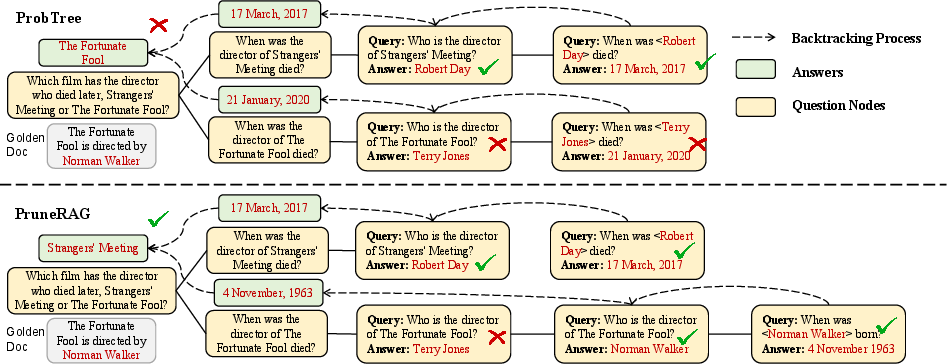
Figure 5: Reasoning logic error (full evidence coverage) case study, showcasing DR-RAG's precise error localization and minimal-cost repair via evidence reuse and targeted re-reasoning.
Oracle Upper Bound and Implications
Oracle-guided DR-RAG—using perfect diagnosis and localization—indicates substantive remaining headroom, especially on challenging datasets like MuSiQue. Advances in diagnosis (not necessarily in repair protocols) will likely drive further gains in agentic RAG robustness and sample efficiency.
Theoretical and Practical Implications
The explicit formulation of failure correction as a trajectory-level diagnosis followed by targeted repair reframes Agentic RAG as a system amenable to fine-grained introspection, structured intervention, and cost-aware iterative improvement. This approach enables robust large-scale deployment of multi-hop and agentic RAG models in realistic, error-prone environments. Importantly, it decouples error analysis from model-specific idiosyncrasies, providing a blueprint for future work on model-agnostic failure correction and efficient LLM orchestration.
Advancements will likely emerge in diagnosis fidelity (taxonomy refinement, counterfactual trace analysis), as well as in adaptive repair mechanisms that balance minimality with exploration, especially as LLMs become more prevalent in high-stakes knowledge reasoning systems.
Conclusion
DR-RAG presents a framework that achieves simultaneous gains in repair accuracy and efficiency in Agentic Retrieval-Augmented Generation by formalizing failure remediation as taxonomy-constrained diagnosis and prefix-reusing, error-localized repair. The approach obviates the overhead of full reruns inherent in prior work and empirically demonstrates strong improvements across models and benchmarks. This research establishes DR-RAG as an effective methodology for scalable, robust, and efficient agentic RAG deployments and provides a foundation for more advanced failure-aware and introspective agentic reasoning architectures.