- The paper demonstrates that RISC-V exhibits up to 14× slower single-core performance and 25× scaling slowdowns compared to x86-64, revealing critical vectorization and memory design gaps.
- The methodology leverages HPX-enabled asynchronous tiled Cholesky decomposition and multiple BLAS backends to benchmark Gaussian Process workloads across heterogeneous architectures.
- The study highlights that while ARM’s mature SVE and high-bandwidth memory offer strong scaling, RISC-V requires significant improvements to be viable for production ML workloads.
Assessing RISC-V for Machine Learning: Portable Gaussian Processes with Asynchronous Tasks
Introduction
This paper systematically quantifies the practical viability of RISC-V as a platform for machine learning applications, specifically Gaussian Process Regression (GPR), in comparison with established x86-64 and ARM architectures. The authors present novel architectural benchmarks and extend the GPRat C++ library, leveraging the asynchronous many-task parallel programming model provided by HPX, to enable seamless portability and robust performance evaluations across x86-64, ARM, and RISC-V hardware. The study critically examines node-level strong scaling and problem-size scaling for Gaussian Process prediction and hyperparameter optimization. Emphasis is placed on vectorization, memory system design, and the impact of BLAS backend optimizations, delineating the state-of-the-art and outstanding challenges for emerging hardware in high-performance machine learning.
HPX and GPRat: Task-Based Parallelism for Portable Gaussian Processes
The GPRat library targets the principal computational bottleneck in GP inference and learning: Cholesky factorization of dense covariance matrices. The implementation exploits asynchronous, fine-grained parallelism with HPX-driven tiled Cholesky decomposition, permitting dynamic task scheduling via HPX futures and dataflow constructs. This approach effectively expresses computational dependencies, achieves high hardware occupation, and accommodates heterogeneous architectures without relying on thread-level parallel BLAS kernels.
The versatility of GPRat is realized through modular support for different BLAS/LAPACK backends: Intel oneMKL (optimized for x86-64) and OpenBLAS (open-source, with ARM and RISC-V support). For RISC-V, current vectorization support is limited (restricted to RVV 0.7.1 via non-standard toolchains), while ARM (A64FX) offers mature SVE vectorization, and x86-64 provides AVX2/AVX-512 acceleration.
Methodology and Experimental Setup
Benchmarks are conducted on three flagship CPUs:
- x86-64: AMD EPYC 7742 (64 cores, AVX2 SIMD, 2 TB DDR4).
- ARM: Fujitsu A64FX (48 cores, SVE-512, HBM2 stacked memory, no L3 cache).
- RISC-V: SOPHON SG2042 (64 cores, RVV 0.7.1, 128 GB DDR4).
Workloads correspond to typical GPR use: training and inference (including full-covariance predictions) on data generated by a nonlinear mass-spring-damper system. Three kernels (POTRF, TRSM, GEMM) are the main compute hotspots. Benchmarks characterize (1) strong scaling as a function of utilized cores, and (2) scaling with data size.
Strong Scaling Across Architectures
Strong scaling analyses isolate the impact of architectural efficiency and BLAS backend optimizations. On x86-64, OpenBLAS yields up to 19% faster runtimes than MKL for GPRat workloads despite the perception of MKL's superior single-thread performance—a non-trivial empirical observation in parallel workload regimes.
Notably, single-core performance on ARM lags behind x86-64 by 58%. However, more efficient parallel scaling is observed on the ARM Fujitsu A64FX: at full node utilization (48 ARM vs. 64 x86-64 cores), ARM outpaces x86-64 by 9%, reflecting superior memory and vector subsystems and high-bandwidth HBM2.
Conversely, the RISC-V SOPHON SG2042 demonstrates clear limitations: single-core performance is up to 14× slower than x86-64. As the number of utilized cores increases, RISC-V fails to scale, with large parallel workloads exhibiting slowdowns up to 25×. These deficits are attributed to both inadequate vectorization (with current OpenBLAS lacking full RVV support) and suboptimal memory subsystem engineering.
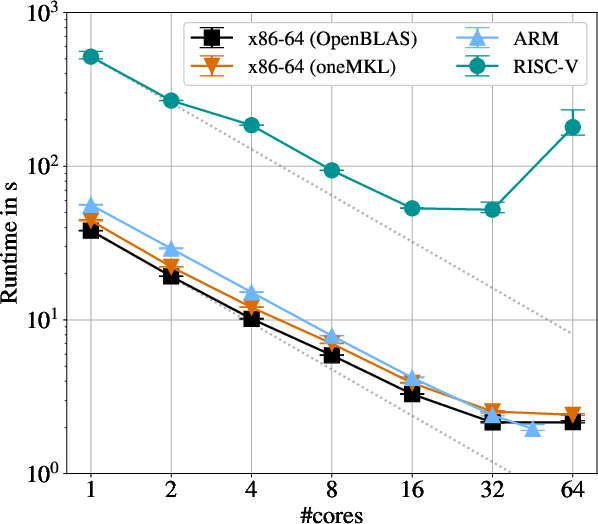
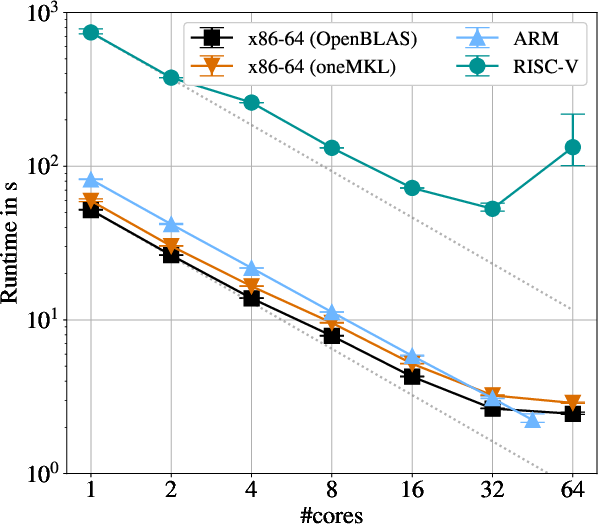
Figure 1: Strong scaling runtimes for hyperparameter optimization indicate that RISC-V (SG2042) falls markedly behind x86-64 and ARM, with scaling inefficiencies compounding with core count.
Problem-Size Scaling Results
When varying the data size, x86-64 and ARM maintain similar absolute performance, with the ARM platform operating within a 23–25% performance window compared to x86-64, even as matrix sizes scale beyond 213. This attests to the maturity of ARM's SVE and memory system for irregular, compute- and memory-bound ML workloads.
For RISC-V, performance for small, sequential workloads is only a factor of ~3 behind x86-64—a reflection of the baseline instruction, pipeline, and memory subsystem efficiency at low concurrency. However, as problem size and parallelism increase, vectorization and memory handling discrepancies dominate: in worst cases, RISC-V becomes 25× slower. This persistent gap is robust under different tiling strategies and persists even after controlling for optimal core allocation.
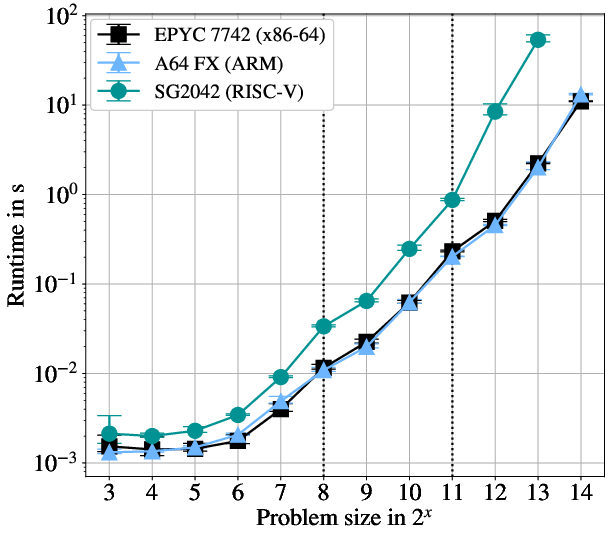
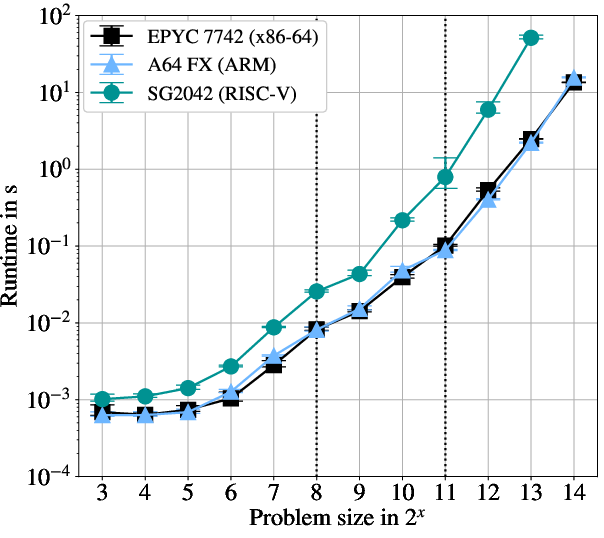
Figure 2: Problem size scaling demonstrates minimal x86-64/ARM performance gap, but exponential slowdowns for RISC-V as tile count and matrix size increase.
Discussion and Architectural Implications
The results provide several actionable insights:
- ARM A64FX demonstrates that RISC design principles—if coupled with advanced SVE vectorization and HBM2—yield strong competitiveness in ML and HPC domains. The ARM system's performance scalability, even outperforming x86-64 at the node level, underscores the efficacy of synchronous many-task models and modern memory architectures for GPR-like workloads.
- RISC-V, in its current instantiation (SG2042, RVV 0.7.1, generic OpenBLAS), is fundamentally encumbered in both vector throughput and memory subsystem sophistication. Even under optimistic assumptions of future vectorization acceleration (factor of two with full 128-bit RVV), large performance and scaling penalties persist.
- Parallel GPR workloads accentuate the criticality of wide-register SIMD utilization and efficient cache/memory systems. The inability of RISC-V to leverage even partial vectorization for key BLAS routines, alongside NUMA and memory controller inefficiencies, are central bottlenecks.
Theoretical and Practical Implications
Practically, these findings inform several streams:
- Software engineers should treat RISC-V as an experimental backend for ML until mature vectorized BLAS/LAPACK libraries and improved silicon are widespread. Absent these prerequisites, it cannot substitute ARM or x86-64 for production-scale GPR or related ML workloads.
- The argument for asynchronous many-task (AMT) models (as enabled by HPX) is reinforced by these benchmarks: explicit, portable task graphs expose concurrency and enable robust cross-architecture codebases. However, library-level vectorization and memory optimizations remain paramount.
- On the theoretical front, hardware-aware algorithm design and backend selection are necessary for future GPR implementations. Scaling studies must systematically account for the variance of vector/memory subsystems rather than focusing solely on FLOP counts or core numbers.
Outlook and Future Directions
Future RISC-V platforms may close the performance gap. The SOPHON SG2044 introduces RVV 1.0 and improved memory bandwidth, and initial studies report substantial gains. The ARM landscape is evolving with Fujitsu’s forthcoming Monaka platform, which will adopt disaggregated chiplet designs. Researchers targeting portable ML frameworks and high-performance GPR should monitor these hardware evolutions, coupling AMT programming models with thorough backend benchmarking.
Efforts toward standardized, high-performance RVV-enabled BLAS/LAPACK implementations for RISC-V, tighter integration of AMT task granularity with architectural specifics, and memory hierarchy optimizations (particularly for non-Von-Neumann and chiplet architectures) are expected research trajectories.
Conclusion
Through systematic benchmarking and library engineering, this study exposes the architectural, software, and practical limitations and latent potential of RISC-V for machine learning, as witnessed in GPR workloads. ARM-based HPC platforms are already competitive with x86-64 for portable, compute-intensive ML; meanwhile, RISC-V requires substantial vectorization and system-level improvements to be viable for these use cases. The research offers rigorous empirical baselines and indicates critical directions for both hardware architects and ML systems engineers as processor heterogeneity becomes central in scientific and industrial ML deployments.