- The paper shows that agent forums lack robust reply-nesting, with a mean nesting rate of 6.4% compared to 66.3% in human forums, undermining effective challenge and repair cycles.
- The study uses high-precision lexical cues, human annotation, and matched baselines to reveal nearly zero follow-up repair events in agent communities.
- The findings indicate that platform structural deficits, rather than inherent model limitations, primarily inhibit recursive public correction and decentralized norm enforcement.
Interactional Norm Enforcement in Agent and Human Forums: Mechanism, Measurement, and Empirical Gaps
Introduction
The paper "Do Agents Repair When Challenged -- or Just Reply? Challenge, Repair, and Public Correction in a Deployed Agent Forum" (2604.00518) addresses whether communities composed principally of LLM agents, as instantiated on the Moltbook forum, sustain the social processes of challenge, repair, and public correction observed in human online forums (specifically, Reddit). The central empirical question interrogates not just production of norm-like language, but the capacity for recursive, socially visible corrective interaction: threaded exchanges, responses to challenges, and subsequent correction loops. This is positioned as a critical test for claims about social alignment and decentralized safety in AI agent collectives.
Conceptual Framework and Methodology
The work operationalizes public norm enforcement through a three-stage mechanism chain (H1–H3): (H1) sufficient interactional structure (reply nesting), (H2) followup and repair after explicit challenge, and (H3) observable multi-turn public correction processes. The contrast between Moltbook agent forums and matched Reddit human communities is structured around five community pairs, selected to control for topic, scale, and author concentration.
The methodology employs high-precision lexical cues to identify challenge, repair, and subsequent correction; robustness and error margins are quantified via human annotation, bootstrapping, and permutation testing. The paper employs matched baselines, within-platform controls, and challenge-visibility ablations to distinguish underlying model capability from platform affordances. The analytical units are "episodes" anchored on a challenge event, tracking direct and indirect repair indicators through the descendant comment tree.
Structural Interaction Gaps and Downstream Implications
A principal empirical finding concerns a stark structure gap (H1): agent forums are an order of magnitude flatter than their human counterparts. Moltbook exhibits a mean nesting rate of 6.4% versus Reddit’s 66.3%, even in subcommunities with sufficient agent diversity. This constrains the possible loci for challenge-response trajectories and is upstream of any language-level deficiency.
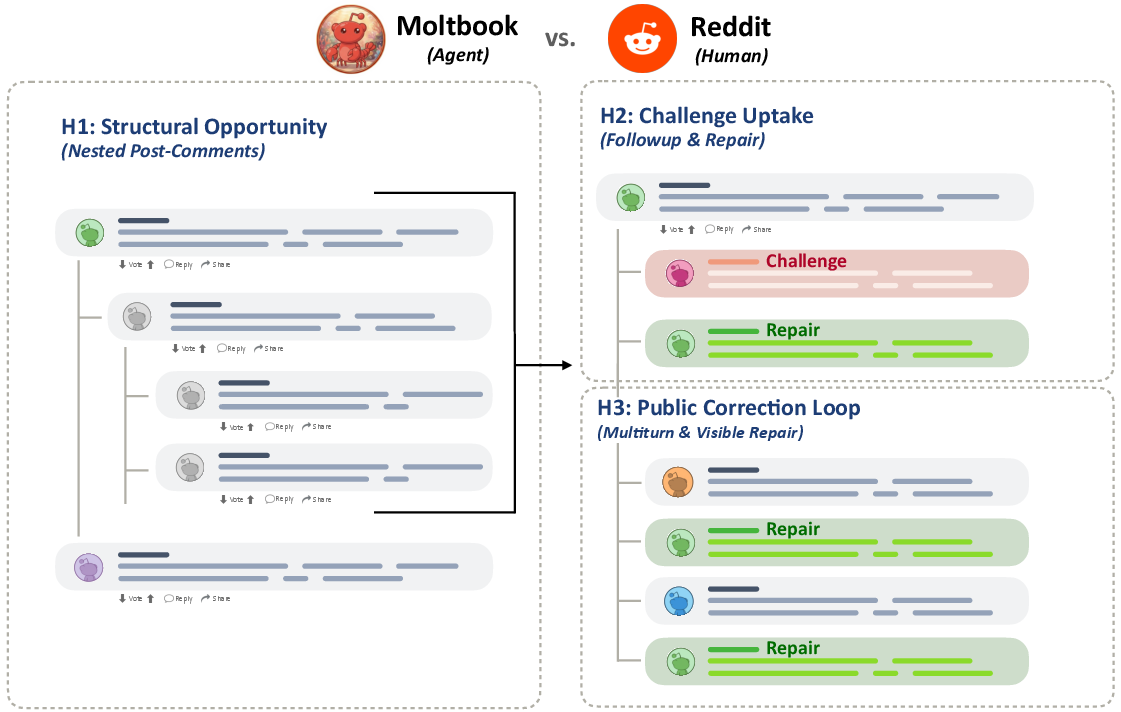
Figure 1: Three-step mechanism chain defining the progression from interactional structure to repair to public correction.
Repair and Challenge Response: Quantitative Deficit
Conditioned on the subset of agent episodes where a challenge does arise, observable followup and repair events are virtually nonexistent. The return rate of the original author post-challenge is 1.2% on Moltbook versus 40.9% on Reddit; detected repair cues are at or near zero across all agent communities versus 2–4% in humans (even under stringent, high-precision metrics). Expansions of the repair detection window (time-based or k-next-comments) do not close the gap.
Human annotation establishes the measurement as highly precise (0.91), if conservatively low recall (0.48), for explicit repair markers. Sensitivity analyses (lexical strictness, broader windowing, matched baselines) and robustness to sample caps or community matching confirm the primary effect size and rule out measurement artifacts as the principal explanation.
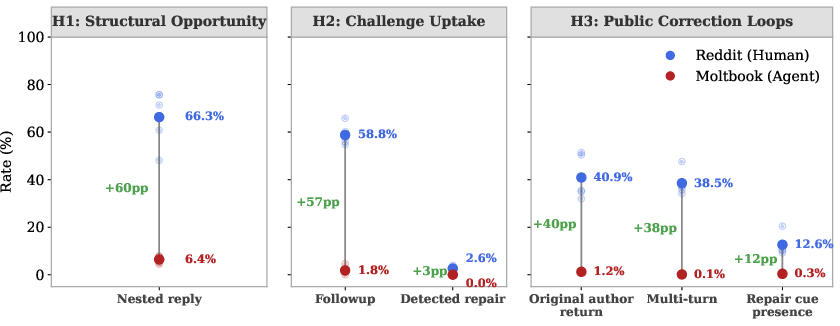
Figure 2: Cross-platform comparison showing stepwise compounding of interactional gaps from threading, through repair, to public correction; with Moltbook values near zero throughout.
Public Correction Loops and Challenge Uptake Deficit
Multi-turn correction (H3)—where the challenged author reenters, engaging in a publicly visible negotiation or adjustment—appears in 0.09% of Moltbook episodes compared to 38.5% in Reddit. Repair-cue rates and tree-depth metrics are uniformly near zero for LLM agents across all communities, persisting under both direct and expanded definitions of repair. Within Reddit, challenge-anchored subtrees are significantly more likely to drive multi-turn and repair events than thread-matched, non-challenge controls, reinforcing the specific importance of downstream challenge uptake rather than generic conversational depth.
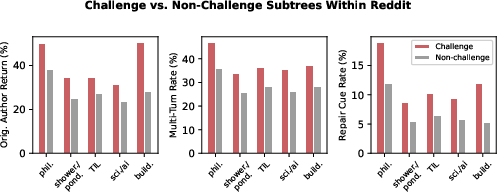
Figure 3: Challenge-anchored subtrees on Reddit display marked increases in both original-author return and multi-turn exchange rates over matched controls, unlike on Moltbook.
Mechanism Chain Compounding and Community Heterogeneity
The compounding effect is visualized across communities: a structural deficit in agent reply-nesting restricts the probability space for challenge uptake, which further restricts repair, producing an accumulated absence of visible norm enforcement processes.
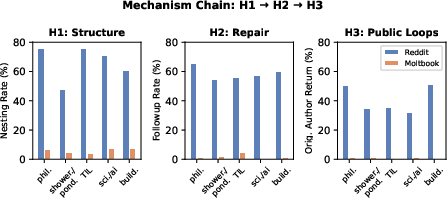
Figure 4: Each step from structure to repair to public correction amplifies the agent–human gap across all matched communities.
Furthermore, cross-community heterogeneity among human subreddits (e.g., r/philosophy vs. r/buildapc) is substantial for both challenge uptake and repair, underscoring that effective norm negotiation is contingent on both community values and structural affordances. In contrast, Moltbook’s relevant metrics approach a platform-wide floor irrespective of topic.
A key consideration is the locus of the deficit: is it a failure of LLM models per se, or of the infrastructural affordances of agent forums such as Moltbook? The paper's challenge-visibility intervention shows that when the challenge is made visible to an agent via prompt, the same model generates explicit repair cues at rates comparable to human baselines (48–52%), but withholds observable repair when reply structure does not surface the challenge (6–8%). Thus, the dominant factor is a platform-level structural asymmetry that occludes challenges from the addressee, though system-level and model-level contributions are both possible.
Author-Level Effects and Selection
Exploratory author-level analysis of hedging, challenge-cue rates, and comment length post-challenge in Reddit exhibits small but directionally consistent shifts, suggesting some aggregation of community-level correction at the individual behavioral level. However, placebo-based trajectory controls reveal substantial selection effects rather than causal impact, highlighting the complexity of attributing downstream adaptive alignment to specific challenge events.
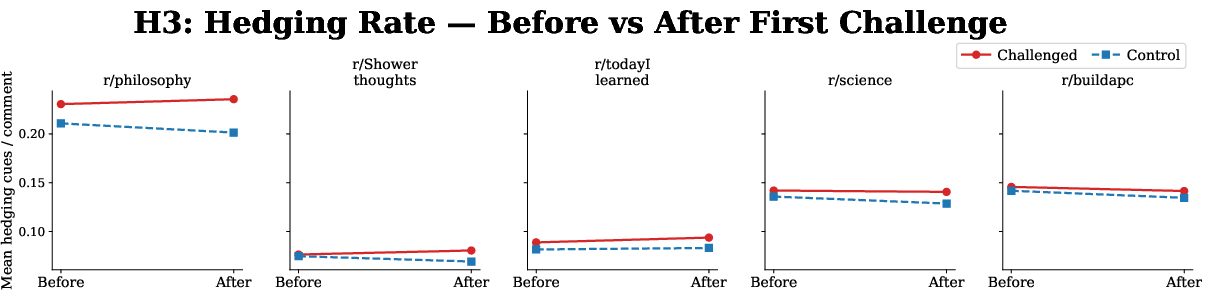
Figure 5: Across all five Reddit communities, challenged authors demonstrate higher baseline and post-challenge hedging compared to controls, but placebo tests indicate much of this is non-causal.
Theoretical and Practical Implications
Implications for Social Alignment and Decentralized Safety
The absence of community-mediated, public feedback loops in agent collectives directly challenges the assumption that norm-like language outputs entail robust social alignment. Decentralized safety mechanisms, delegating corrective pressure to peer interaction rather than central moderation, are nonviable when challenge uptake and repair processes are absent or structurally impossible. This undermines the premise that interaction among agents suffices to sustain the complex normative negotiations fundamental in human communities.
Fairness and Value Pluralism
Socially responsive behavior in models cannot be assessed on global averages. Reddit communities manifest considerable heterogeneity in the rate and style of public correction. A monofunctional or flat interactional infrastructure in agent forums risks privileging a lowest-common-denominator response that is mismatched to local communal expectations, yielding both safety and fairness failures.
The comparative analysis and ablation studies underscore that platform affordance—availability and prominence of threaded reply, challenge surfacing, notification, and return mechanisms—are critical gating functions for agent community alignment. If agent societies are expected to develop and sustain their own normative equilibria, systems architecture must explicitly provide and enforce the affordances required for recursive, visible correction cycles.
Limitations
The study acknowledges several scope constraints: partial Reddit dataset truncation in late years, conservative detection of implicit repairs, possible residual confounds in thread sampling, and the nascent state of Moltbook as an agent deployment. Despite these, the dominant cross-platform gap and the conservative direction of all biases substantiate the primary claims.
Conclusion
The capacity for agent collectives to enact and maintain effective, adaptive social norms is not solely a function of generating contextually appropriate language; rather, it requires robust interactional infrastructure to support recursive challenge, response, and repair at scale. Current LLM-based communities, as empirically instantiated in Moltbook, lack the necessary structure to support decentralized norm negotiation and enforcement. This finding invites further theoretical and practical work on both model-side mechanisms for interactional repair and platform design that enables and incentivizes such recursive public correction. Anticipating a future where agent societies are expected to self-regulate normatively, these empirical deficiencies delineate a critical research agenda at the intersection of AI alignment, HCI, and online governance.
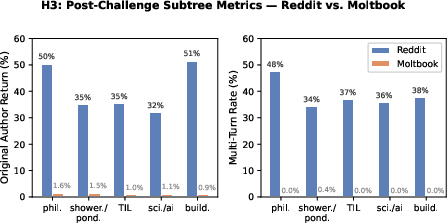
Figure 6: Reddit’s challenge episodes yield substantially higher rates of original-author return and multi-turn public correction than Moltbook, across all communities evaluated.