- The paper presents a novel gray-to-RGB reasoning paradigm that detects anomalies by identifying chromatic and structural discrepancies in video frames.
- The paper introduces a hybrid encoder-decoder architecture combining Transformer, Mamba, and CNN modules with a vector quantization bottleneck to achieve state-of-the-art performance at 133 FPS.
- The paper achieves remarkable efficiency by halving computational requirements while maintaining high AUC on challenging datasets like Ped2 (99.6%), Avenue (91.9%), and ShanghaiTech (77.1%).
VADMamba++: Efficient Video Anomaly Detection via Gray-to-RGB Hybrid Modeling
Introduction
VADMamba++ introduces a novel framework for unsupervised Video Anomaly Detection (VAD), targeting high accuracy alongside real-time inference efficiency. Unlike previous works that rely on computationally expensive auxiliary modalities (such as optical flow) and hybrid task fusion, VADMamba++ formulates anomaly detection as a single proxy task based on a Gray-to-RGB (G2R) reasoning paradigm. This architecture compels the model to infer chromatic representations from grayscale structural cues, exposing anomalies through joint inconsistencies in structure and color. By leveraging an efficient hybrid backbone that integrates Mamba, Transformer, and CNN blocks, VADMamba++ captures multi-scale spatiotemporal representations, yielding superior detection accuracy with competitive computational efficiency.
Gray-to-RGB Reasoning Paradigm
The central technical advance in VADMamba++ is the G2R paradigm, which replaces conventional RGB-to-RGB reconstruction with the task of colorizing grayscale video frames as future-frame prediction. This setup forces the underlying model to learn both how structured normal scenes manifest in color and, crucially, which chromatic patterns are atypical given spatial geometry. The paradigm is distinct from auxiliary color-masking or direct RGB modeling, as it explicitly leverages reasoning failures in the colorization step as strong signals of abnormality.
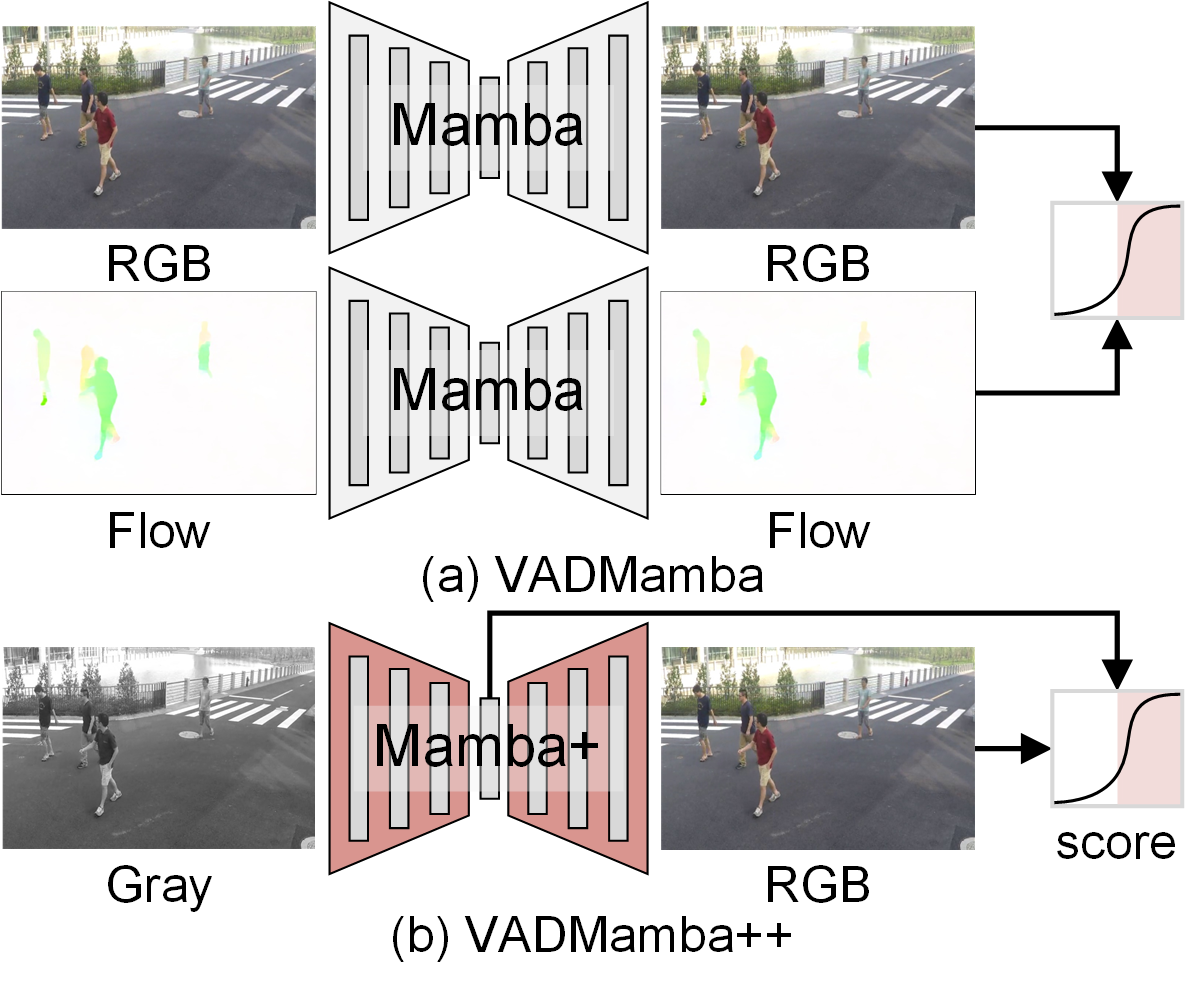
Figure 2: Pipeline comparison between (a) VADMamba and (b) VADMamba++. This highlights evolution toward single-input, single-task, and intra-task fusion.
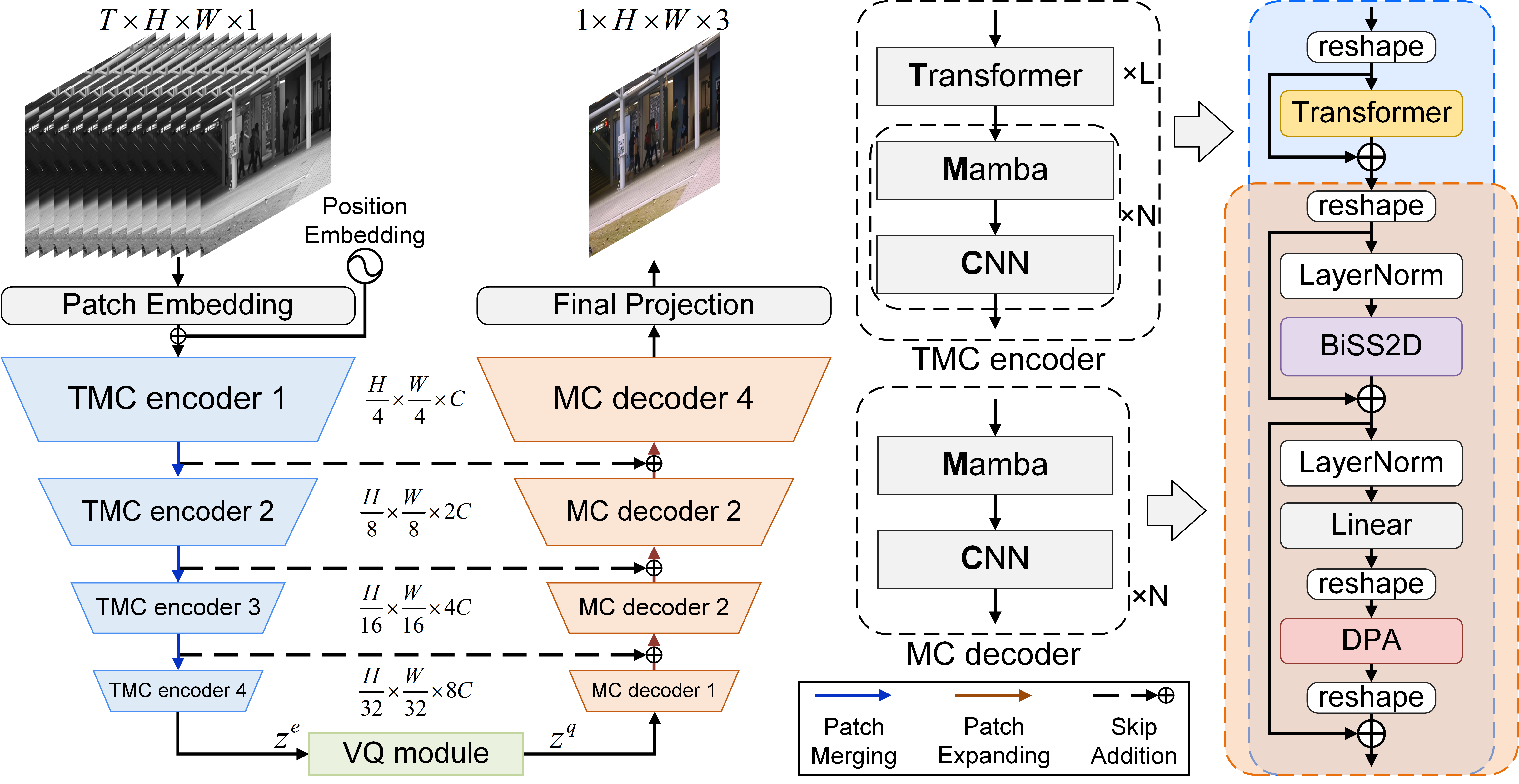
Hybrid Encoder-Decoder Architecture
VADMamba++ employs an asymmetric U-Net-like encoder-decoder architecture:
The ablation studies substantiate that the specific module ordering of Transformer→Mamba→CNN yields optimal accuracy, outperforming alternatives that alter this hierarchy.
Scoring: Explicit and Implicit Fusion
VADMamba++ introduces an intra-task fusion scoring strategy. Rather than relying on heuristic combinations of error metrics from disparate proxy tasks, the explicit reconstruction error (between ground truth and prediction in RGB space) and the implicit quantized latent feature error (from the VQ bottleneck) are adaptively fused. This approach provides two complementary anomaly cues:
- Explicit reconstruction error (SE): Captures visual disparities.
- Implicit quantized feature error (SI): Highlights latent inconsistencies often overlooked by only explicit measures.
The weighted combination of PSNR-transformed errors serves as the final anomaly score, yielding robust temporal continuity and sensitivity across diverse anomaly types.
VADMamba++ achieves state-of-the-art single-task AUC on the challenging Ped2, Avenue, and ShanghaiTech datasets (99.6%, 91.9%, and 77.1%, respectively) at 133 FPS, notably exceeding or matching multi-task and auxiliary-input methods while halving their computational/memory requirements.
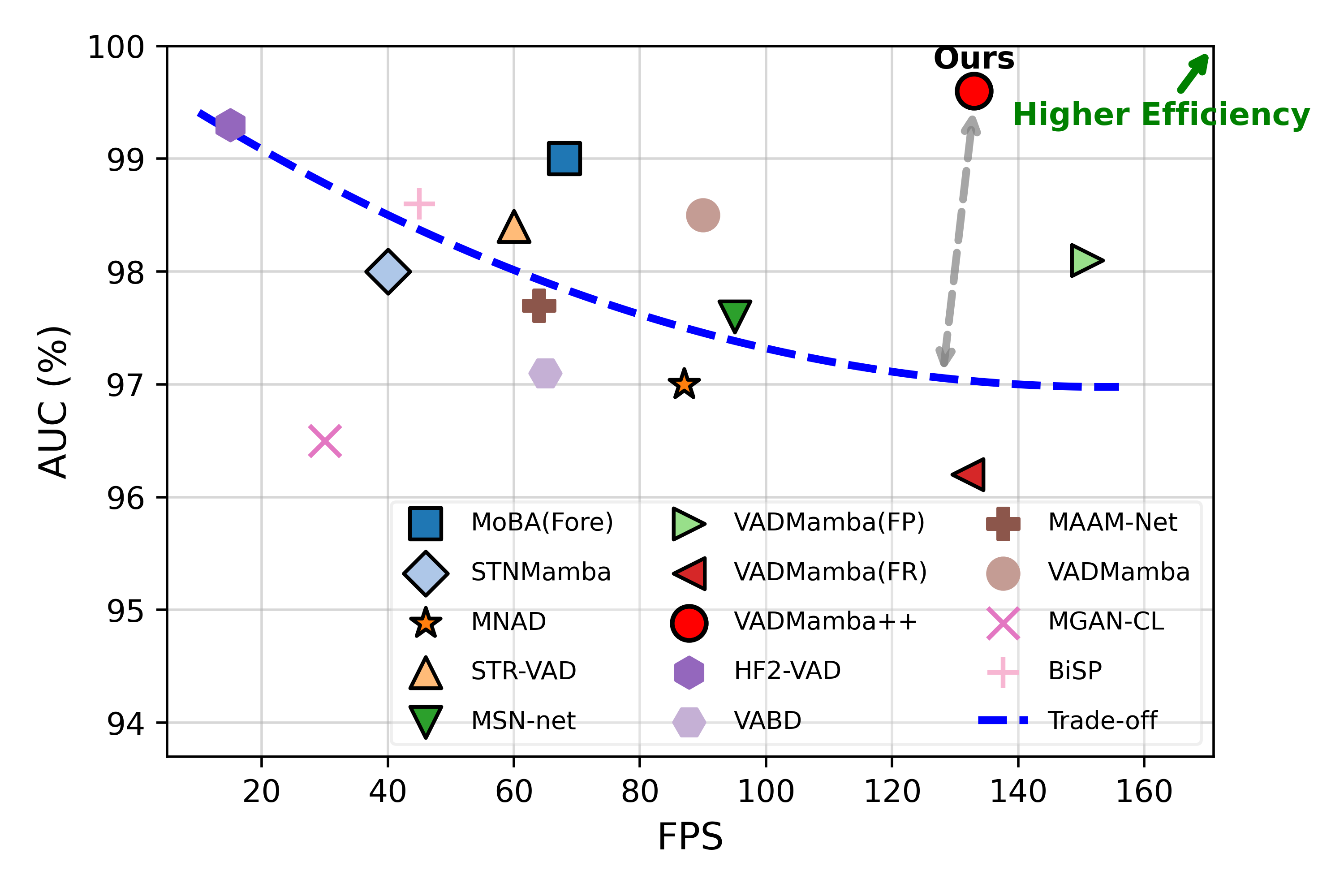
Figure 3: VADMamba++ uniquely breaks the prevalent speed–accuracy tradeoff, achieving high AUC at real-time FPS in comparison to prior methods.
Compared to prior Mamba-based works and multi-task fusion models (including VADMamba and HF2-VAD), VADMamba++ secures superior accuracy and resource control. Importantly, ablation analyses demonstrate that the G2R paradigm, intra-task fusion, module ordering, and the composite loss substantially contribute to detection efficacy and robustness.
Qualitative Analysis

Figure 5: Example qualitative results—abnormal regions manifest as larger errors in reconstruction, visualized as bright regions in explicit error maps.

Figure 4: Side-by-side comparison highlighting VADMamba++'s superior discrimination of normal (green box) and anomalous (red box) regions; G2R paradigm amplifies chromatic deviations.
The G2R approach reveals clear failure modes when the predicted color appearance deviates substantially from expected structure-conditioned chromaticity, especially for colored anomalies or texture/appearance changes not observed under normal training.
Scoring Dynamics and Sensitivity
Figure 6: Frame-level anomaly scores: fusion (solid line) better delineates abnormal periods with higher peaks and smoother transitions, compared to explicit or implicit-only approaches.
Parameter studies confirm that the fusion is robust to hyperparameter variations, and moderate top-k and λ values maintain high AUC across diverse datasets and scene complexities.
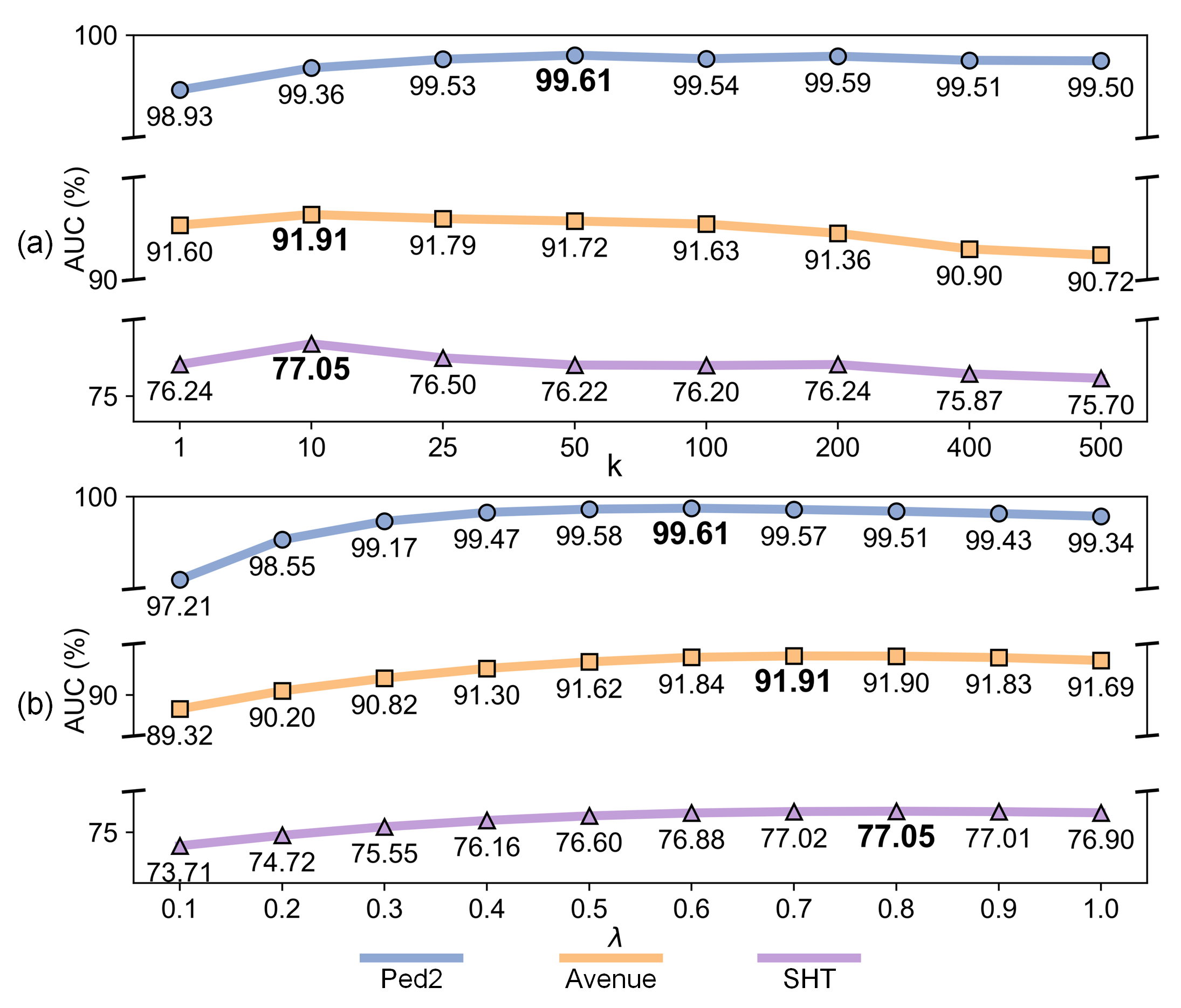
Figure 7: Sensitivity analysis for top-k and λ parameters; consistent trends and stable AUC reflect framework robustness.
Theoretical and Practical Implications
VADMamba++ represents an evolution for unsupervised VAD by emphasizing reasoning-based explicit-implicit fusion and a single-task G2R paradigm. The results and analysis suggest several implications:
- Resource-constrained deployment: Drastic parameter/FLOPs reduction at matched accuracy enables real-time surveillance across edge platforms.
- Removal of optical flow/auxiliary input dependence: Simplifies upstream processing pipelines, enabling broader applicability and system design flexibility.
- Cross-modal reasoning: Integrating explicit chromatic reconstruction with implicit latent evaluation exposes new research directions for compact generative anomaly detection in video and potentially other time-series domains.
The architectural insights—particularly hybridization of Transformer, Mamba, and CNN with asymmetric encoder-decoder tailoring—generalize to other dense prediction tasks requiring joint temporal and spatial modeling.
Conclusion
VADMamba++ sets a new efficiency-standard in video anomaly detection, demonstrating that a single-task G2R paradigm augmented with hybrid Mamba/Transformer/CNN modeling and explicit–implicit fusion scoring can outperform multi-proxy, multi-modal approaches in both accuracy and resource demand. The comprehensive experiments, qualitative analysis, and ablation studies collectively highlight the method’s robustness, practical real-time potential, and further research avenues in sequence-based generative modeling for anomaly detection.