- The paper introduces a dual-stream transformer architecture that separates global context aggregation from local fine-detail recovery, achieving efficient 3D geometry estimation.
- It employs a lightweight Adapter module to fuse multi-scale features using cross-attention, integrating high-frequency details with global scene structure.
- Experiments demonstrate state-of-the-art performance in depth sharpness, point error, and scalability across diverse high-resolution video datasets.
Dual-Stream Geometry Estimation: DAGE Architecture and Its Implications
Introduction and Motivation
The paper "DAGE: Dual-Stream Architecture for Efficient and Fine-Grained Geometry Estimation" (2603.03744) addresses the dual challenge of high-fidelity 3D scene reconstruction and efficient camera pose estimation from unposed, high-resolution, multi-view video sequences. Existing feed-forward visual-geometry networks achieve multi-view consistency but are severely bottlenecked by the quadratic scaling of global attention, which limits input resolution and temporal length. Single-view estimators, while highly detailed at high resolutions, lack cross-frame coherence and do not predict camera trajectories. The DAGE framework proposes a dual-path design, isolating the demands for global consistency and local detail, and introduces a lightweight integration mechanism to enable both sharp 3D geometry and scalable inference.
DAGE's principal innovation is the architectural separation of global and fine-grained geometric reasoning via two parallel transformer streams, each optimized for a different aspect of the estimation task.
The low-resolution (LR) stream processes aggressively downsampled image sequences using a global transformer with alternating global and frame-wise attention. This design captures scene-level context and enables efficient, permutation-equivariant pose regression over long sequences.
Simultaneously, the high-resolution (HR) stream leverages a pre-trained Vision Transformer to process each frame individually at its native resolution, enabling preservation of high-frequency spatial detail and sharp geometric features.
A critical component is the Adapter: a lightweight, cross-scale fusion module that injects multi-view-consistent context from the LR stream into the HR stream using cross-attention and self-attention blocks.
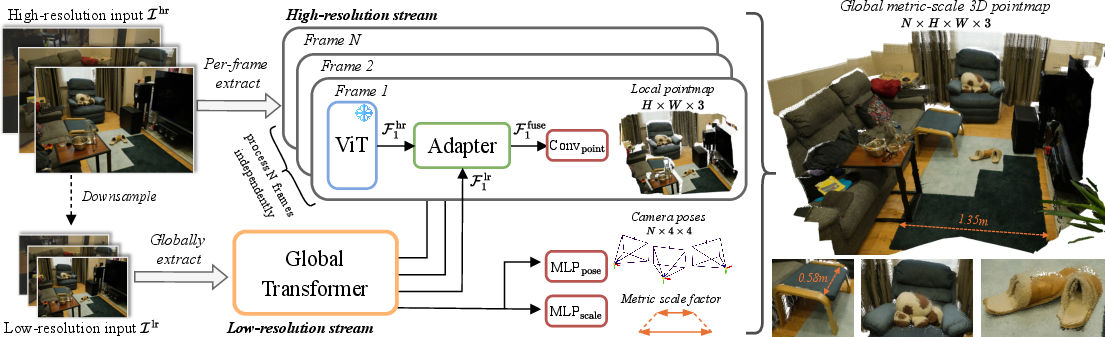
Figure 1: The DAGE dual-stream architecture separates global context aggregation (via LR stream) from detail-preserving per-frame inference (via HR stream), merging them with a scalable Adapter.
The LR stream is initialized via knowledge distillation from a pre-trained baseline, ensuring stable representation during aggressive downsampling. Rotary positional encodings (RoPE) are adapted via interpolation or grid snapping to maintain alignment between scales and avoid degradation at high input resolutions.
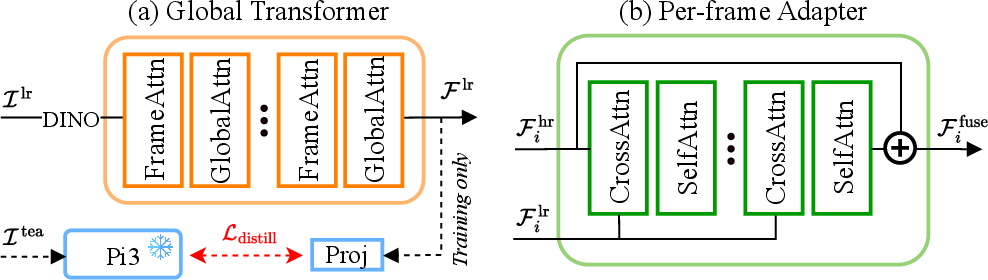
Figure 2: The global transformer (left) applies scalable attention patterns, while the Adapter (right) enables efficient multi-scale token fusion for geometric prediction.
DAGE is trained with a comprehensive loss suite, including ℓ1 penalties on scene-normalized pointmaps, geometric normal losses, gradient matching losses on inverse depth, metric scale regression, and relative pose losses. Notably, global alignment constraints are enforced over all frames per sequence, eschewing the patch-wise independent alignment used in some high-detail monocular pipelines, which mitigates cross-view drifting. The adaptation of loss regimes from both single-view and multi-view paradigms ensures both local sharpness and global spatial coherence.
Experimental Analysis and Empirical Results
DAGE achieves state-of-the-art performance across multiple axes:
- Video Geometry and Depth Sharpness: DAGE attains the top average rank in both relative point error (Relp) and inlier ratio (δp) across eight diverse datasets, including high-resolution and large-scale indoor/outdoor scenes. Notably, it maintains strong performance on large, uncurated datasets where competing methods either degrade in detail or fail to scale.
- Reconstruction Quality: DAGE matches or outperforms prior methods in accuracy, completeness, and normal consistency on 3D reconstruction benchmarks, simultaneously preserving sharp object boundaries (Figure 3) and capturing fine/depth edges, even for small and distant structures.

Figure 4: Visual comparison of video depth estimation on in-the-wild data; DAGE preserves sharpness and structure absent in competing models.

Figure 3: DAGE reconstructs detailed, globally consistent pointmaps with stronger preservation of thin structures compared to global-attention baselines.
- Disparity and Depth Contours: Via boundary F1 and depth-edge error metrics, DAGE exhibits significant improvements in depth contour recovery and temporal sharpness. The impact of monocular priors and gradient losses is elucidated via targeted ablations, establishing the necessity of each module for retention of both sharpness and global alignment.
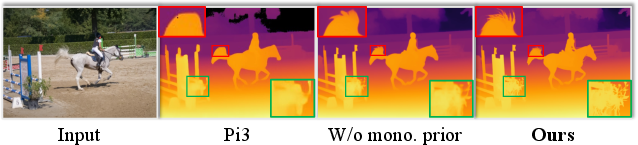
Figure 5: Disparity and depth-edge sharpness, highlighting DAGE’s ability to resolve fine spatial contours.
- Scalability: Unlike prior global-attention systems, throughput remains practical at 2K resolution and on 1000-frame sequences, with inference speed gains (2× to 28× over baselines) and lower GPU memory consumption.
Ablations and Attention Analysis
Adapter design ablations confirm that late fusion via cross-attention/self-attention yields superior global consistency and minimizes artifacts compared to interpolation or recurrent intermediate injections. Ablation on LR stream resolution demonstrates that most of the pose and structural supervision can be offloaded to the low-resolution path without significant loss, further supporting the dual-path approach.
Critical analysis of positional encoding design illustrates that naïve scaling of token context in global attention results in high-entropy, unspecific attention maps and depth collapses at high resolutions. The use of interpolated RoPE and snapping mitigates such failures, sustaining attention localization and correspondence.
Theoretical and Practical Implications
DAGE’s architectural decoupling of global and local reasoning addresses a critical bottleneck in geometric foundation models: quadratic scaling in global attention has been the primary factor limiting joint high-resolution and large temporal window processing. The demonstration that consistent, sharp geometry and accurate camera poses can be attained via such a decoupled structure has implications for the design of large-scale 3D geometric perception systems.
By enabling both sharpness and consistency in multi-frame settings, DAGE broadens the applicability of learned visual geometry models in domains where single-view, post-hoc-aligned, or handcrafted geometric pipelines are impractical—such as real-time AR/VR, large-scale urban reconstruction, or embodied perception for robotics.
Future Directions
Potential follow-ups include:
- Modeling Non-Rigid or Low-Overlap Motion: Current limitations include degraded performance in highly dynamic scenes or rapid, non-rigid transformations. Extensions incorporating explicit non-rigid motion modeling or learned feature flow could augment generalization.
- Efficient Dynamic Scene Modeling: Integrating robust temporal dynamics modules to address temporal inconsistencies and reconstruct high-fidelity temporally-evolving 3D structures in unconstrained video.
- Expanded Memory and Context Handling: Further research into the optimization of attention structures for even longer sequences or higher spatial resolutions could further push practical boundaries using newer memory architectures.
Conclusion
DAGE (2603.03744) presents a robust, efficient, and scalable architecture for 3D geometry estimation from multi-view, high-resolution image sets. Its dual-stream design demonstrates that global context aggregation and detail preservation can be achieved simultaneously without prohibitive resource demands. Empirical evaluations show consistently superior performance in video geometry, depth boundary sharpness, multi-view reconstruction, and camera pose estimation. These advances position DAGE as an influential architectural template for future work in large-scale, high-fidelity geometry prediction systems.

