- The paper introduces an RL framework that reframes topology selection as a cooperative multi-agent problem using QMIX value factorization.
- It achieves superior performance with up to 72.73% accuracy and notable token efficiency improvements across seven challenging benchmarks.
- Empirical and ablation studies demonstrate robust adaptability and decentralized policy guarantees that ensure global optimality in agent coordination.
Agent Q-Mix: Reinforcement Learning for Adaptive Topology Selection in LLM Multi-Agent Systems
The paper "Agent Q-Mix: Selecting the Right Action for LLM Multi-Agent Systems through Reinforcement Learning" (2604.00344) addresses the core problem of adaptive topology selection in LLM-based Multi-Agent Systems (MAS). In complex domains such as mathematics, code generation, and reasoning, static or centrally generated communication topologies underperform due to their inability to adapt inter-agent communication to task complexity or to allow decentralized social adaptation. Previous methods are hindered by either fixed agent interaction patterns, leading to token inefficiency and fragile performance, or by reliance on a centralized topology generator, which introduces a single point of failure and prevents per-agent local communication strategies.
Agent Q-Mix: Methodological Advances
The central methodological contribution is the reframing of communication topology selection as a cooperative Multi-Agent Reinforcement Learning (MARL) problem, solved with a QMIX value factorization scheme. In Agent Q-Mix, each agent independently selects from a discrete set of six communication actions, which collectively induce the round-specific communication graph for message passing.
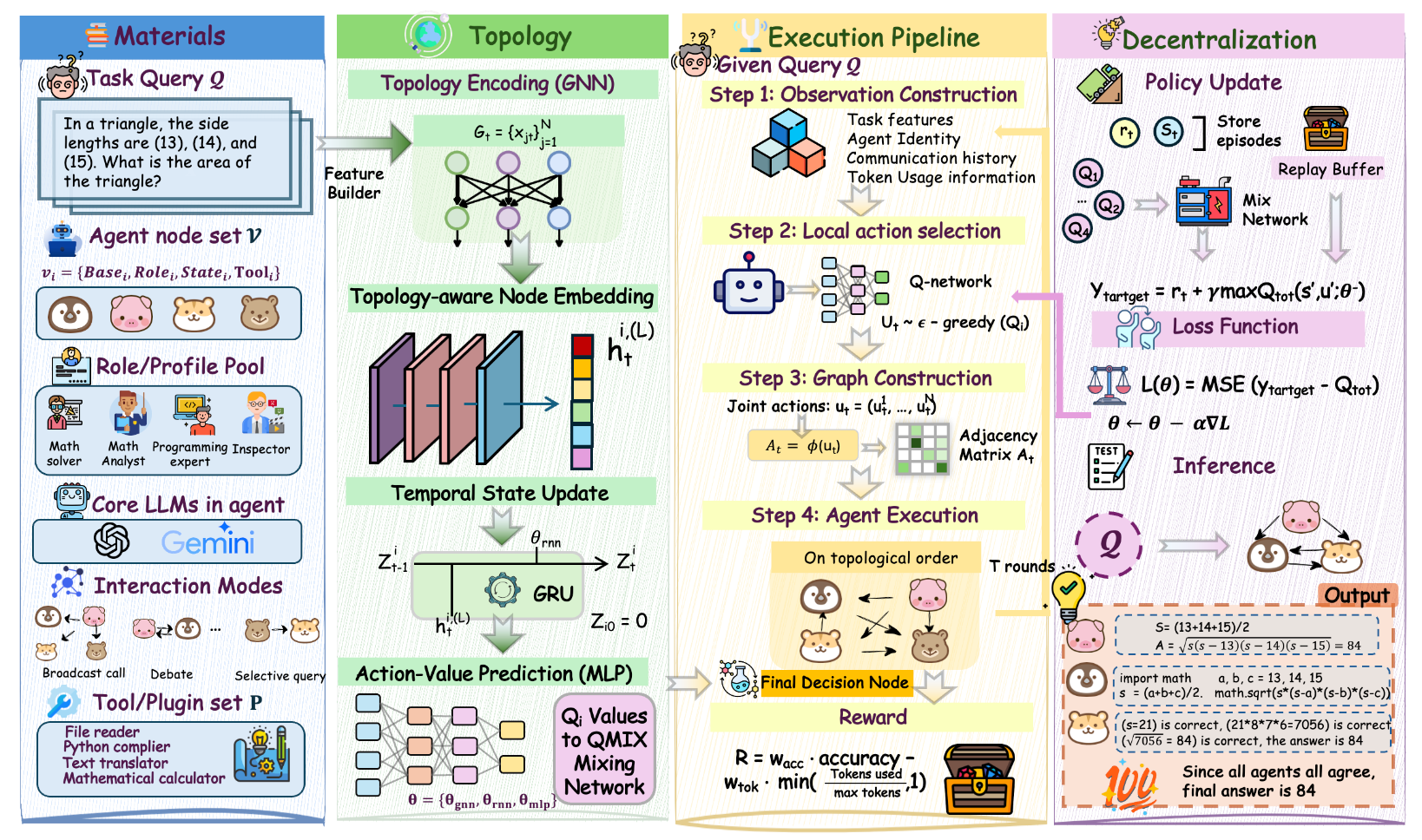
Figure 1: Overview of Agent Q-Mix, in which agents select communication actions in each round, forming a communication graph through which they exchange information and ultimately produce a team output under centralized training and decentralized execution.
The six communication actions—solo_process, broadcast_all, selective_query, aggregate_refine, execute_verify, and debate_check—allow the system to represent a combinatorial spectrum of communication topologies, ranging from fully disconnected to dense cliques, and to express heterogeneous inter-agent protocols within a single round.
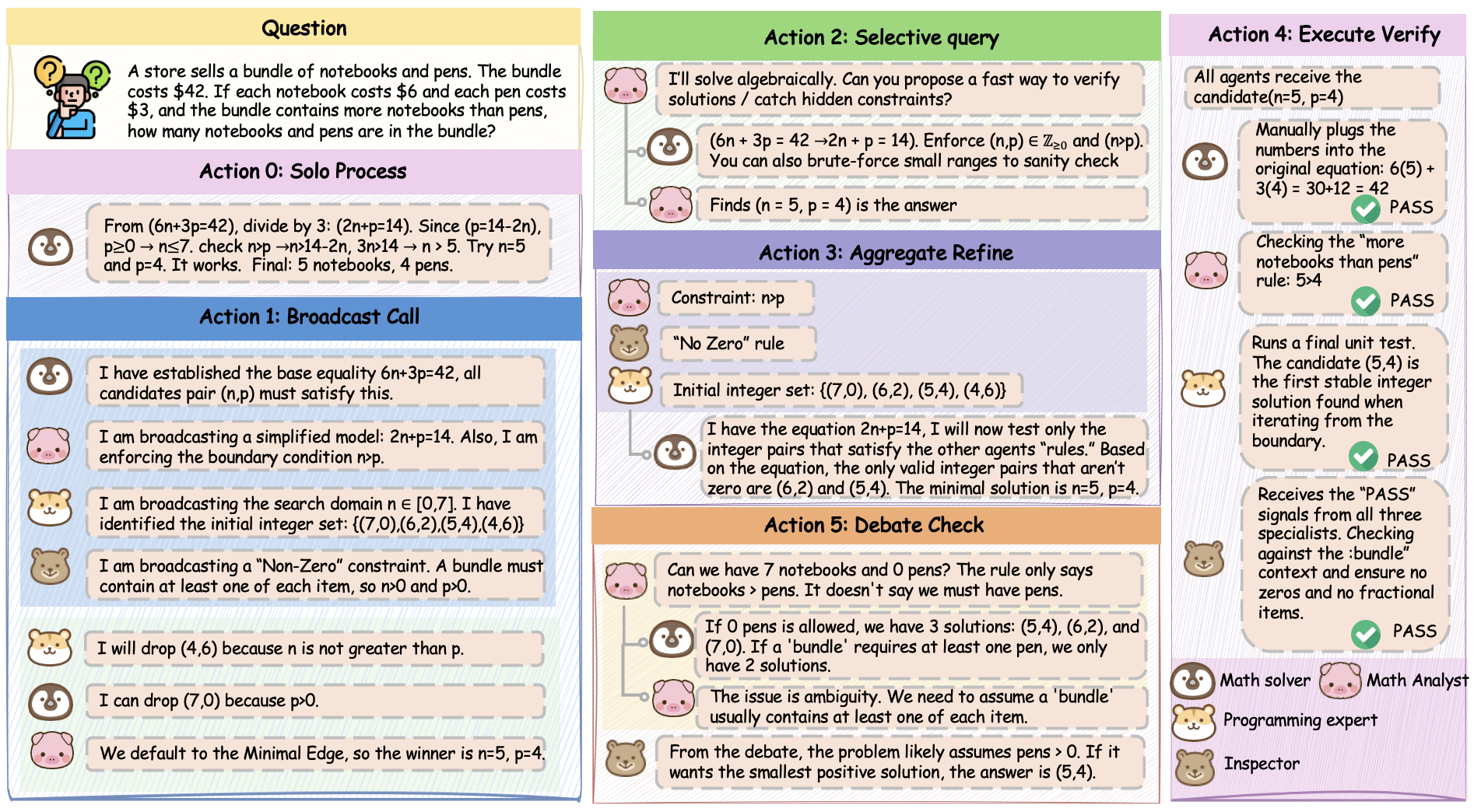
Figure 2: The action space of Agent Q-Mix, highlighting the induced topologies for solo, broadcast, selective query, aggregate/refine, minimal verification, and debate patterns.
A Graph Neural Network (GNN) encoder is used to derive topology-dependent agent embeddings at each round. These are fused with recurrent GRU state across rounds to form individual Q-heads for decentralized action selection. During centralized training, shared parameters are optimized using temporal-difference (TD) updates in the QMIX framework, which ensures the joint value function satisfies the Individual-Global-Max (IGM) property. This property is critical as it guarantees that greedy decentralized per-agent action selection is globally optimal under the learned value decomposition.
Multi-Round Execution and Policy Analysis
The execution consists of multiple communication rounds (T), with agent observations encoding task features, communication history, and token usage statistics. Each agent independently chooses a communication action; the resulting adjacency matrix governs message routing for that round. Empirical analysis shows that the learned policy dynamically adapts topologies across rounds and tasks—for example, mathematics tasks induce denser, multi-round topologies, while high-confidence code tasks utilize sparse interaction to minimize token cost.
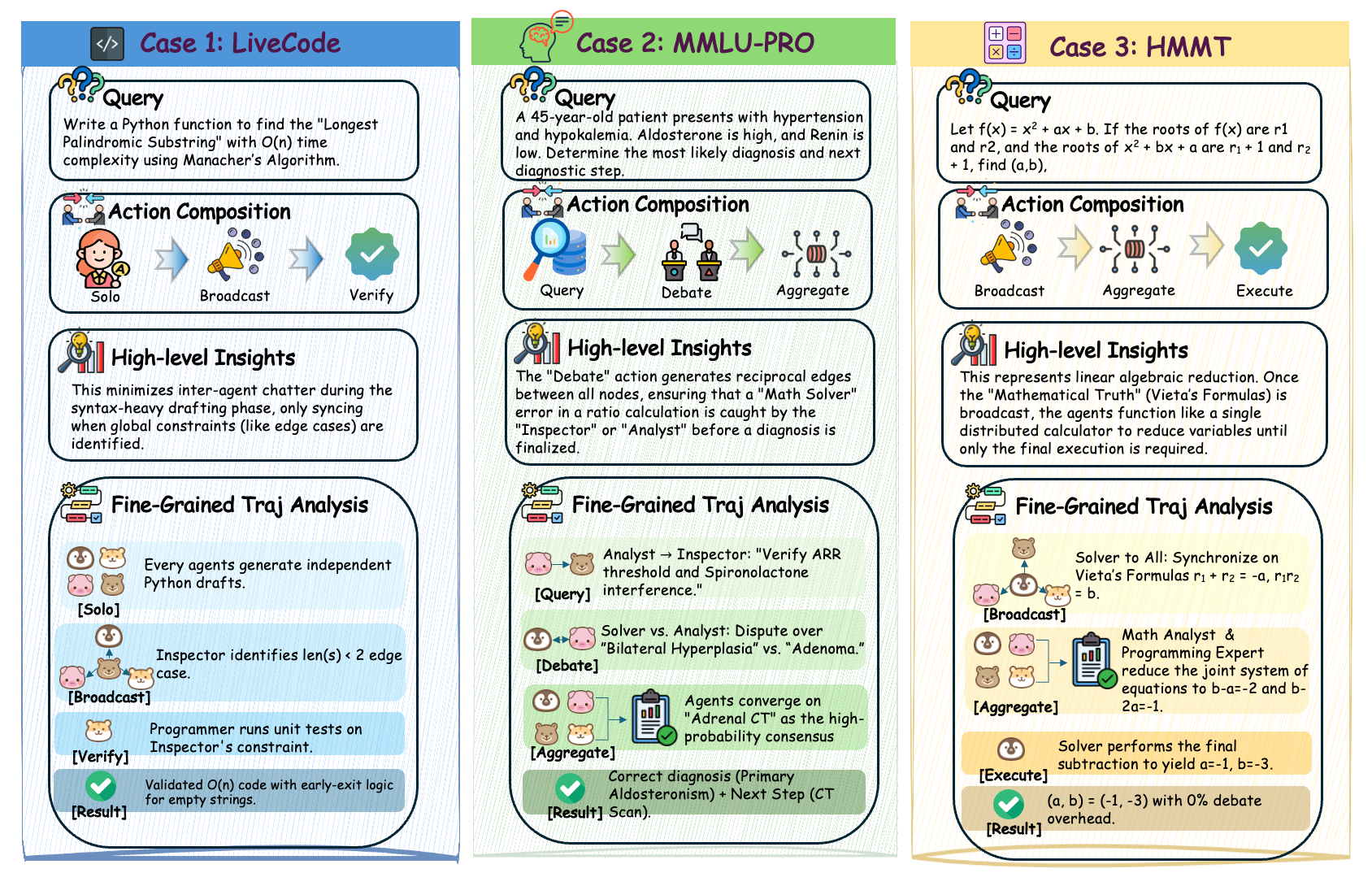
Figure 3: A representative communication and reasoning trajectory showing the evolution of the induced communication graph across rounds and domains.
Agent Q-Mix is evaluated on seven challenging benchmarks—including LiveCodeBench, HumanEval, MMLU-Pro, AIME, HMMT, Beyond-AIME, and HLE—using both open and proprietary LLM backbones (GPT-OSS:120B, Gemini-3.1-Flash-Lite).
Key empirical findings:
- Highest average accuracy on GPT-OSS:120B (72.73%), outperforming the best adaptive-topology baseline (GTD, 60.37%) and commercial framework baselines (e.g., AutoGen, 68.60%), representing gains of +12.36 and +4.13 points, respectively.
- On the HLE benchmark, Agent Q-Mix achieves 20.8% accuracy on Gemini-3.1-Flash-Lite, surpassing Microsoft Agent Framework (19.2%), LangGraph (19.2%), AutoGen, and Lobster.
- Substantial improvements on mathematics evaluation: 53.33% on HMMT versus best prior (43.33%), and 42.00% on Beyond-AIME, with analogous superiority in token efficiency.
- On HumanEval and LiveCodeBench, Agent Q-Mix maintains near-perfect accuracy while minimizing unnecessary agent communication.
Additionally, token usage is significantly reduced compared to prior multi-agent baselines. For instance, on MMLU-Pro, Agent Q-Mix achieves its accuracy profile with 112K tokens (only 15% above the single-agent baseline), compared to 471K--2.71M tokens by baseline systems.
Robustness and Ablation
Agent Q-Mix demonstrates enhanced robustness to adversarial agents: the accuracy drop on MMLU-Pro with an injected adversarial agent is only 2.86 points, substantially less than the 8.57–10 point drops of previous methods. Policy analysis reveals the emergent behavior of subgraph isolation, whereby the system minimizes influence propagation from unreliable agents.
Ablation studies systematically analyze the effects of agent team size, data efficiency, reward weights, and communication rounds. The policy is sample-efficient (competitive accuracy with only 15 training tasks per domain) and dynamically prunes communication under easy instances, allocating capacity only as required by task complexity.

Figure 4: Ablation studies showing sensitivity to agent count, training data size, reward weighting, and number of rounds, as measured on accuracy and token usage metrics.
Theoretical and Practical Implications
Agent Q-Mix operationalizes a reinforcement learning-based, topology-aware communication strategy for LLM-based MAS, establishing a strong empirical and formal basis for decentralized, adaptive interaction policy design. Theoretically, the use of monotonic value function factorization ensures that decentralized action selection is consistent with global optimality—a nontrivial guarantee in high-dimensional MARL settings.
Practically, the approach enables scalable MAS architectures that are robust to partial failure, resource-constrained (token-efficient), capable of domain transfer, and adaptive to dynamic task demands. The explicit and discrete communication action space yields interpretable policies with domain-agnostic applicability, facilitating policy analysis and future transfer learning.
Further, the demonstrated robustness to agent quality variation and communication efficiency directly address key deployment concerns for LLM-based agentic frameworks in production contexts.
Future Perspectives
Future directions include scaling to larger agent pools, exploring more expressive or hierarchical communication action spaces, integrating structured priors for domain specialization, and combining policy distillation techniques to improve train-time sample efficiency. Extending this framework to include agents operating with partial or asynchronous observability, as well as the inclusion of heterogeneous agent types, may further enhance system-level performance and generalizability.
Conclusion
Agent Q-Mix provides a unified, RL-driven approach to learned topology optimization in LLM-based multi-agent systems, delivering consistently superior accuracy and efficiency across diverse domains. The combination of interpretable communication actions, strong theoretical guarantees, and empirically validated robustness establishes a new foundation for decentralized adaptation and coordination within agentic LLM ecosystems.