- The paper introduces a framework that orchestrates diverse agents with unique tool-use strategies for iterative refinement at test time.
- The approach uses message-passing among agents and an adaptive LLM-as-Judge mechanism to optimize termination and accuracy while reducing inference costs.
- Empirical results on HLE, GPQA, and AIME benchmarks show significant gains, with up to a 3.55% accuracy improvement over state-of-the-art baselines.
Introduction and Motivation
The integration of external tools such as code interpreters and web search has become a critical axis for enhancing the reasoning capabilities of LLMs. However, the optimal orchestration of these tools—especially in the context of diverse, open-ended questions—remains an open problem. The "TUMIX: Multi-Agent Test-Time Scaling with Tool-Use Mixture" paper introduces a framework that addresses this challenge by leveraging a heterogeneous ensemble of agents, each with distinct tool-use strategies, and orchestrating their iterative collaboration and refinement at test time. The approach is evaluated on high-difficulty benchmarks (HLE, GPQA, AIME), demonstrating significant improvements over prior tool-augmented and test-time scaling baselines.
TUMIX Framework: Architecture and Mechanisms
TUMIX operates by instantiating a pool of diverse agents, each defined by a unique combination of reasoning modality (textual, code, search, or hybrid) and tool-use policy. At each refinement round, all agents receive the original question concatenated with the previous round's responses from all agents, enabling cross-agent information flow and iterative answer refinement. The process continues until a termination criterion is met, after which a final answer is selected via majority voting or LLM-based selection.
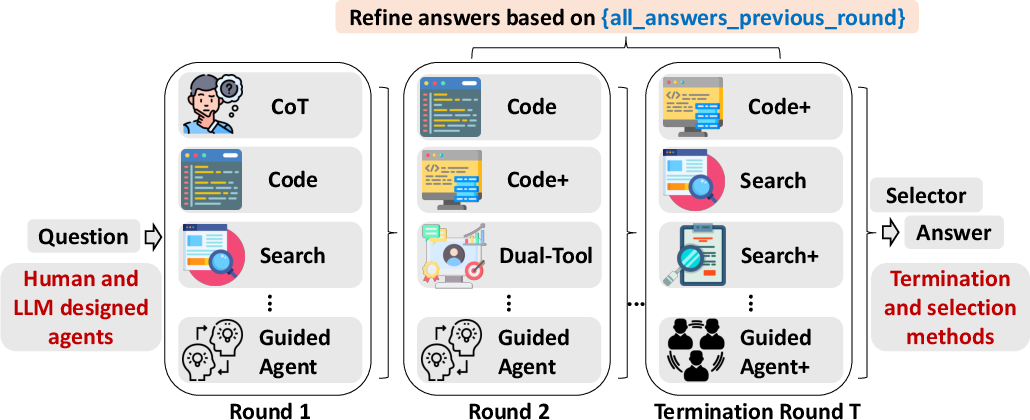
Figure 1: The TUMIX framework iteratively aggregates and refines agent responses, with each round's prompt including the original question and all prior answers.
The agent pool is constructed to maximize both diversity and quality. The default configuration uses 15 pre-designed agents, including variants with access to code interpreters, web search, or both, as well as guided agents that leverage steering modules. Each agent is parameterized by its tool-access policy and prompt engineering, and agents with search capabilities instantiate multiple variants based on the underlying search API.
Iterative Refinement Dynamics
The iterative message-passing mechanism in TUMIX is central to its performance. In each round, agents independently generate new solutions conditioned on the evolving context. Empirical analysis reveals that coverage (the probability that at least one agent produces a correct answer) decreases monotonically with rounds, while average accuracy initially increases and then plateaus or declines, depending on the benchmark.
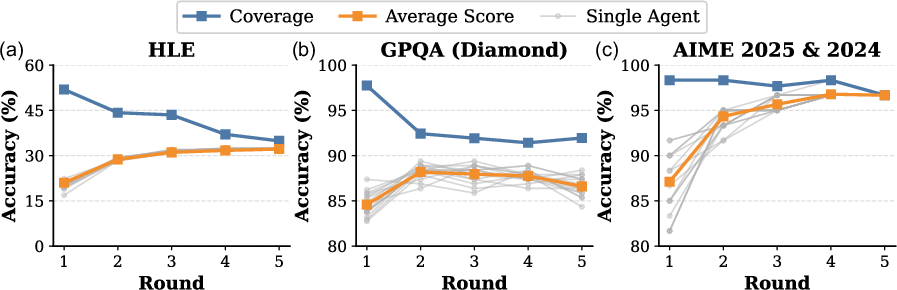
Figure 2: Coverage decreases and average score plateaus or declines after initial rounds, indicating convergence and potential loss of diversity.
A Sankey diagram of agent correctness across rounds further illustrates that initial rounds promote exploration and diversity, but subsequent rounds drive convergence—often prematurely—toward a single answer, which may be correct or incorrect.
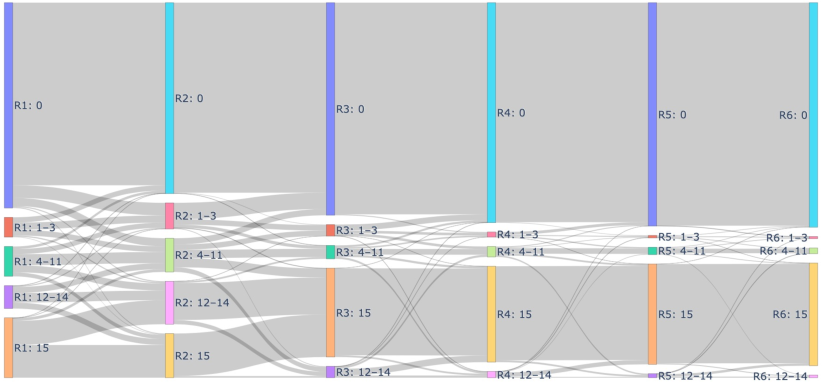
Figure 3: Sankey diagram showing the evolution of agent correctness categories across refinement rounds.
Termination and Answer Selection Strategies
A key insight is that excessive refinement can degrade performance by discarding correct but minority answers. TUMIX introduces an LLM-as-Judge mechanism to adaptively determine the optimal stopping round, balancing marginal accuracy gains against inference cost. This approach achieves near-optimal accuracy at only 49% of the inference cost compared to fixed-round or majority-stabilization strategies.
Majority voting is used for final answer selection, with LLM-based selection providing marginal gains only when agent answers remain diverse in later rounds.
Empirical Results and Comparative Analysis
TUMIX is evaluated on Gemini-2.5-Pro and Gemini-2.5-Flash across HLE, GPQA, and AIME. It consistently outperforms strong baselines, including Self-MoA, Symbolic-MoE, DEI, SciMaster, and GSA, with an average accuracy improvement of up to 3.55% over the best prior method at comparable inference cost.
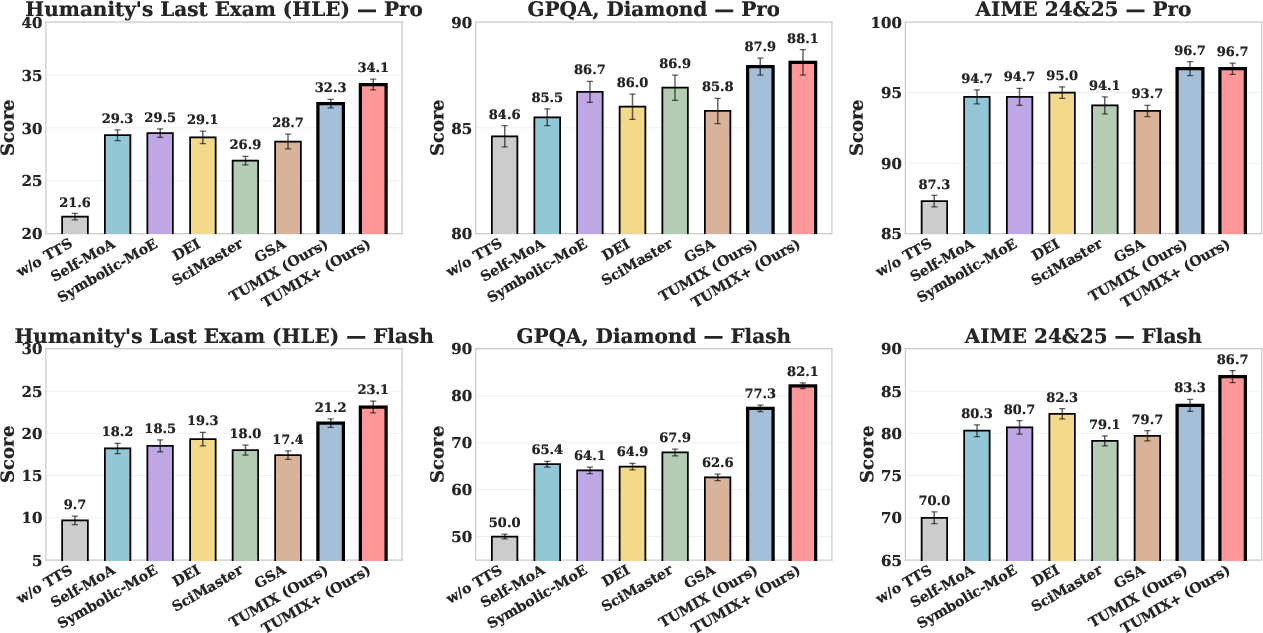
Figure 4: TUMIX achieves higher accuracy than all baselines across multiple benchmarks and models, with comparable inference and token costs.
Scaling analysis demonstrates that TUMIX achieves superior performance per unit inference and token cost, and further scaling (TUMIX+) yields additional gains at higher cost.
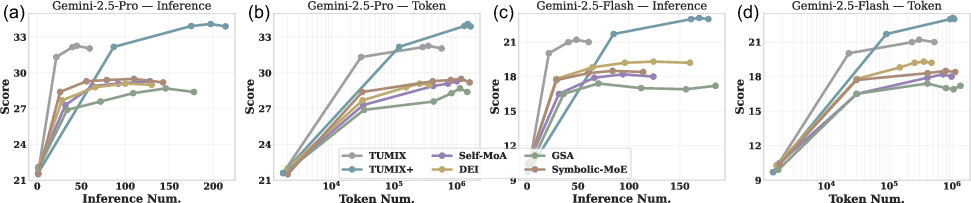
Figure 5: TUMIX exhibits favorable scaling of HLE scores with respect to inference and token cost compared to other methods.
Agent Diversity, Quality, and Automated Agent Design
Ablation studies confirm that agent diversity and quality are critical. Increasing the number of distinct agent types yields substantial improvements in both coverage and average score, with diminishing returns beyond 12–15 agents.
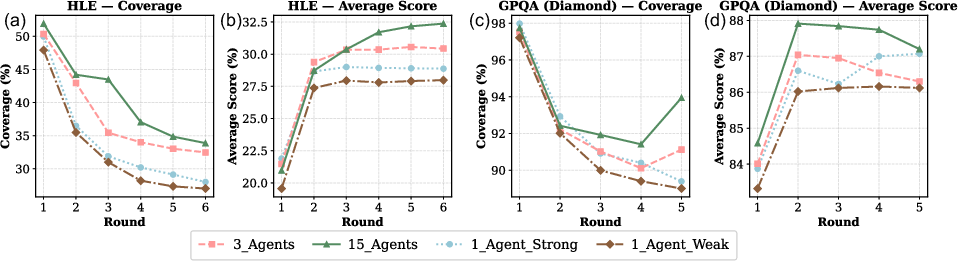
Figure 6: Coverage and average score improve with increased agent diversity and quality.
Integrating both code and search capabilities within agents further enhances answer diversity and group performance.
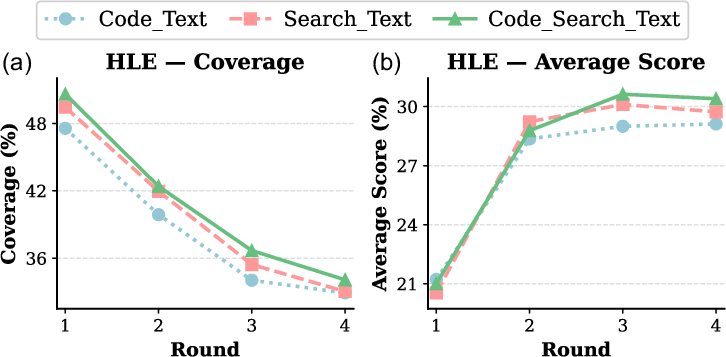
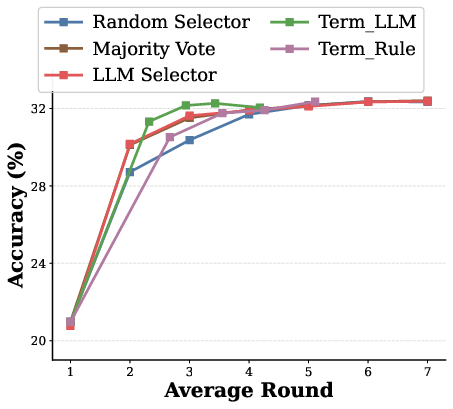
Figure 7: Agent groups with access to both code and search outperform those with only one modality.
The paper also demonstrates that LLMs can be prompted to generate new, high-quality agent designs, which, when mixed with human-designed agents, further improve TUMIX performance. Sampling from a pool of 30 agents (15 pre-designed, 15 LLM-generated) and selecting top-performing combinations yields higher coverage and average score than the original agent set.
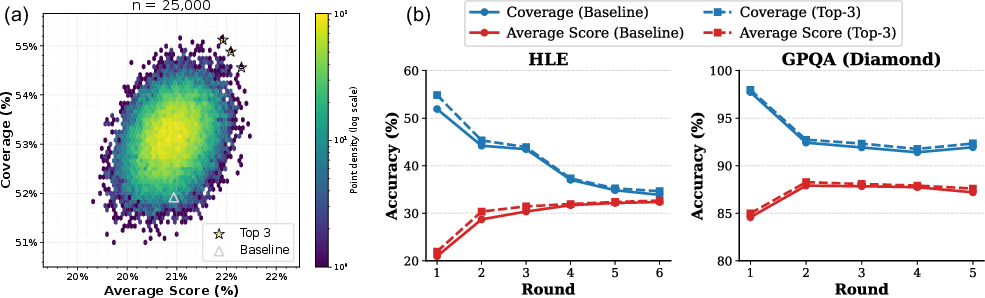
Figure 8: Mixed groups of pre-designed and LLM-generated agents achieve superior joint performance.
Theoretical and Practical Implications
The results challenge prior claims that repeated sampling from a single best agent suffices for optimal performance in test-time scaling. Instead, TUMIX demonstrates that structured agent diversity, tool augmentation, and adaptive refinement are essential for maximizing LLM reasoning capabilities, especially on tasks requiring both symbolic and retrieval-based reasoning.
The framework is modular and generalizable, supporting dynamic agent composition, automated agent design, and flexible termination/selection policies. The approach is compatible with any LLM supporting tool-use APIs and can be extended to new tools or reasoning modalities.
Limitations and Future Directions
While TUMIX achieves strong gains, the marginal benefit of additional agent types saturates, and further scaling incurs substantial inference and token costs. The selection of correct answers from a noisy candidate pool remains a bottleneck, particularly for open-ended tasks. The framework's reliance on LLM-based termination and selection introduces additional inference overhead, though this is offset by reduced total rounds.
Future work may explore more sophisticated aggregation mechanisms, dynamic agent specialization, and integration with training-time tool-use optimization. The automated agent design pipeline could be extended to discover novel reasoning strategies beyond prompt engineering.
Conclusion
TUMIX establishes a new state-of-the-art in tool-augmented test-time scaling for LLMs by orchestrating a diverse ensemble of agents with complementary tool-use strategies and iterative refinement. The framework's principled approach to agent diversity, adaptive termination, and automated agent design yields substantial accuracy and efficiency gains across challenging reasoning benchmarks. These findings underscore the importance of structured diversity and selective refinement in maximizing the capabilities of tool-augmented LLMs and provide a foundation for future advances in agentic AI systems.