- The paper introduces ParetoBandit, which uses a contextual bandit framework to maximize response quality under strict budget limits in fluctuating environments.
- It combines LinUCB-based reward estimation, online budget pacing, and geometric forgetting to dynamically adjust to real-time cost and quality variations.
- Empirical tests demonstrate robust budget compliance, rapid adaptation to quality regressions, and efficient onboarding and management of new LLM models.
ParetoBandit: Budget-Constrained, Adaptive Routing for Non-Stationary LLM Serving
ParetoBandit addresses the complex problem of real-time routing across multi-model LLM portfolios characterized by large cost disparities, non-stationary dynamics, and open-world runtime requirements. The core challenge is to maximize utility (response quality) relative to an operator-specified dollar budget ceiling amid environmental drift—model price changes, silent quality regressions, and dynamic portfolio membership—under strict constraints precluding retraining or downtime.
The contextual bandit framework with partial observability is adopted: at each round, the router dispatches a prompt to one model based on context embeddings, observes only the realized reward and cost for the chosen action, and iteratively refines dispatch policy. The objective is formally stated as:
πmax E[t=1∑Trt,π(xt)],s.t.T→∞limsupT1t=1∑Tcπ(xt)≤B
where B is the maximum average cost per request. This operationalization directly reflects deployment practice, contrasting with finite-horizon or batch-resource approaches previously common in the literature.
System Design
ParetoBandit integrates four primary mechanisms:
- LinUCB-based contextual reward estimation: Per-arm (per-model) regression tracks historical quality performance by context.
- Online budget pacing via primal-dual control: A closed-loop Lagrangian mechanism (with EMA smoothing) dynamically adjusts cost penalties, enforcing an average per-request cost ceiling regardless of request stream length or drift in conditions.
- Non-stationarity adaptation through geometric forgetting: Sufficient statistics for each arm are exponentially down-weighted over time, allowing rapid override of stale information in response to drift.
- Warmup priors and runtime dynamic portfolio management: Supports bootstrapping from offline characterized priors (controllable via effective sample size), fast onboarding of new models, and live arm addition/removal with minimal overhead and bounded exploration.
Upon prompt arrival, the system encodes the context using a lightweight transformer and PCA-reduced representation, computes per-arm contextual reward and uncertainty (LinUCB's upper confidence bound), and incorporates a dynamic, log-normalized cost penalty. Arm selection blends exploitation, exploration (inflated upon staleness), and both static and dynamic cost aversion. Budget violations trigger a hard safety ceiling and an increased Lagrangian cost penalty, ensuring robust compliance.
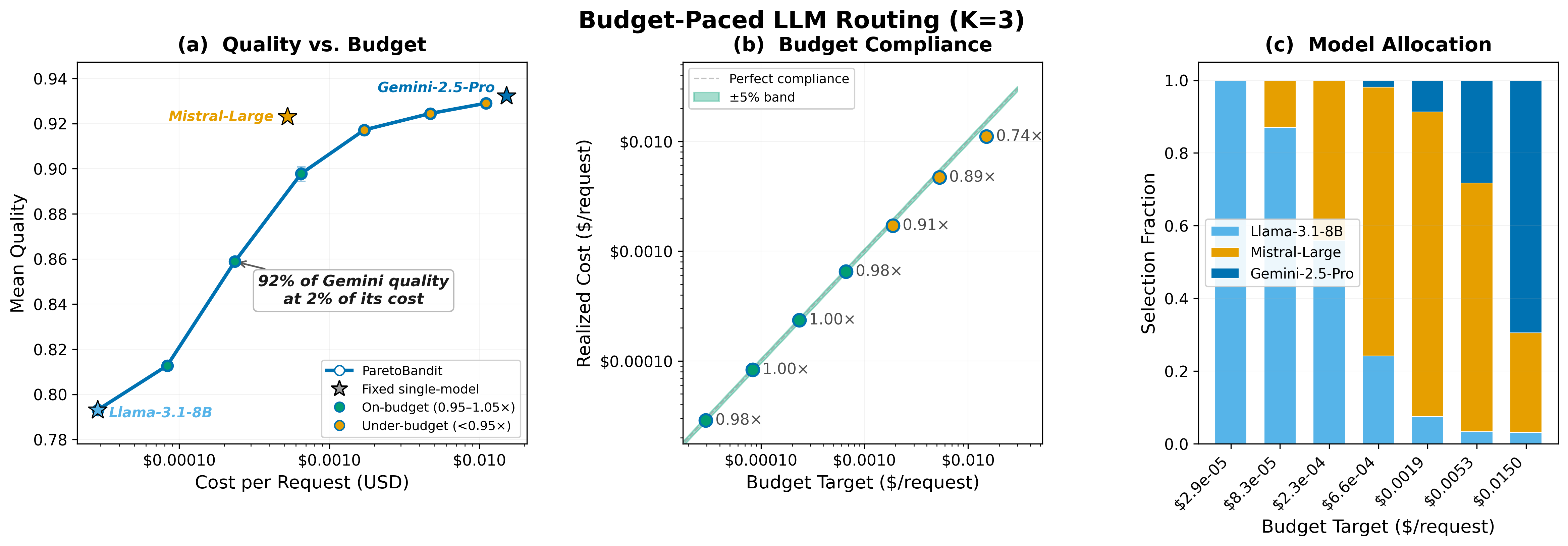
Figure 1: Quality–cost Pareto frontier showing how the router interpolates between fixed single-model operating points, dynamically mixing arms to achieve quality gains beneath arbitrary budget ceilings.
Adaptive Budget Pacing and Non-Stationary Robustness
Unlike most published methods, ParetoBandit’s budget enforcement is closed-loop and horizon-free: pacing adjustments are continuously updated based on recent spend via an EMA-tracked cost signal, allowing seamless adaptation to external changes—including prompt-distribution shift, abrupt price cuts, or model onboarding.
Further, the geometric forgetting factor is calibrated via a Pareto knee-point protocol, ensuring a tradeoff between stationary efficiency and rapid adaptation to severe shifts. Empirical results demonstrate that this regime avoids the pathologies of both fixed (“naive”) and ablated (“no pacer”) bandit baselines, which can egregiously violate budget constraints upon drift.
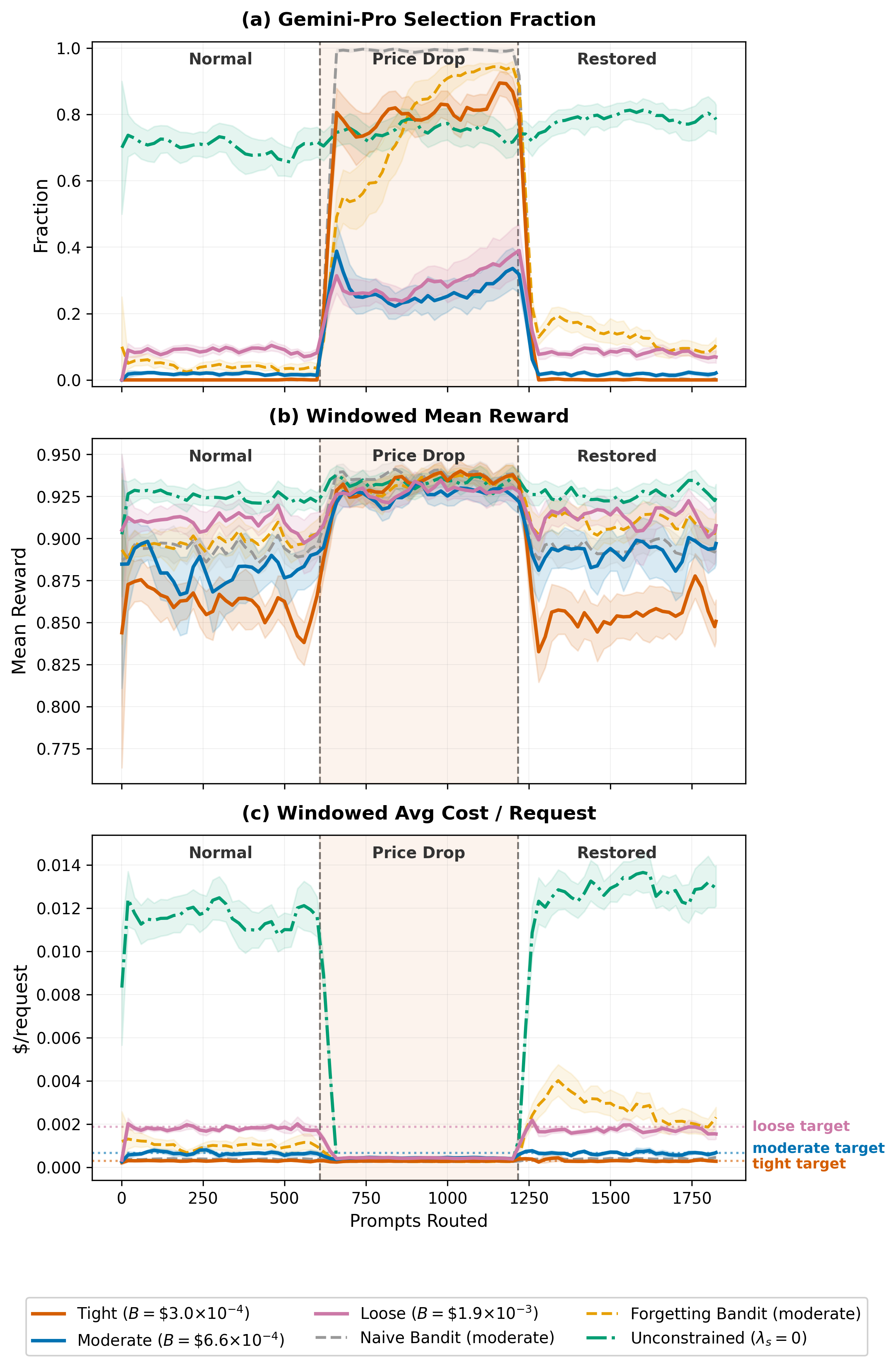
Figure 2: Dual-variable dynamics and adaptation after mid-deployment model price reduction, showing exploitation of freed budget and subsequent recovery when price is restored.
Empirical Evaluation and Deployment Implications
Comprehensive tests are conducted across four scenarios:
- Stationary budget-constrained routing: ParetoBandit reliably fills the quality gap between fixed-operating-point baselines. For instance, with budgets permitting only a minority of high-cost allocations, the system achieves 92% of the highest-quality model’s reward at only 2% of its cost. Budget ceilings are held to within 0.4% in all cases, converting operator-defined dollar constraints into a continuous quality dial.
- Cost drift exploitation: Following an abrupt (10x) price reduction for the previously expensive model, the dual variable quickly decays, utilization shifts to the newly cost-effective model, with quality potentially boosted by +0.071 under tight limits, all while never sacrificing compliance during the full round-trip.
- Silent quality regression: If a model’s reward deteriorates (e.g., an 18% drop), geometric forgetting enables rapid rerouting away from the degraded model with budget compliance always preserved. Upon recovery of the model's quality, staleness-triggered exploration and rapid forgetting enable the system to re-adopt the model, with phase-3 reward within 97.5% of the pre-degradation baseline.
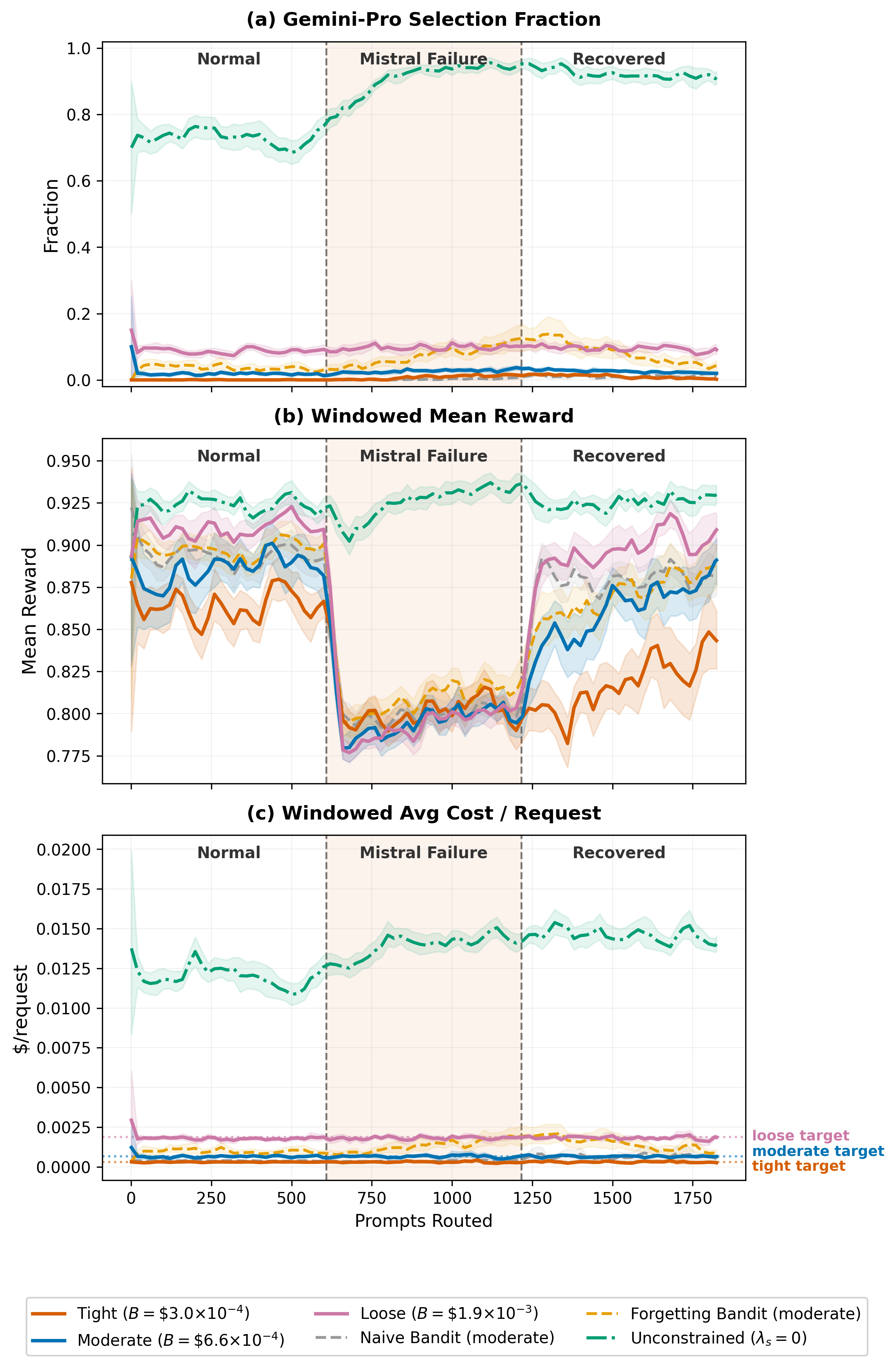
Figure 3: Recovery trajectory after silent model quality regression, showing budget adherence and dynamic reallocation away from the degraded model, then recovery upon restoration.
- Online model onboarding and portfolio change: The system supports adding/removing models at runtime, with bounded forced exploration for newly registered arms. Adoption and allocation of the added model reflect both its realized quality and the operator's budget constraint. The system discriminates rather than over-allocating to newly introduced models regardless of their cost or quality.
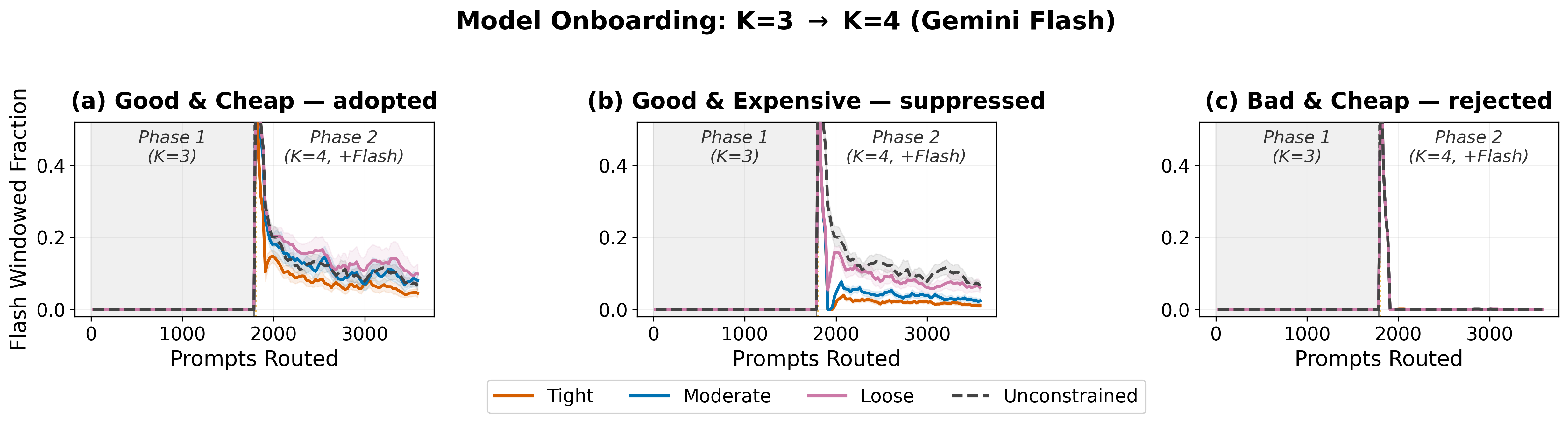
Figure 4: Adoption dynamics of a new model introduced online, with budget-limited, data-driven allocation without violating budget ceilings.
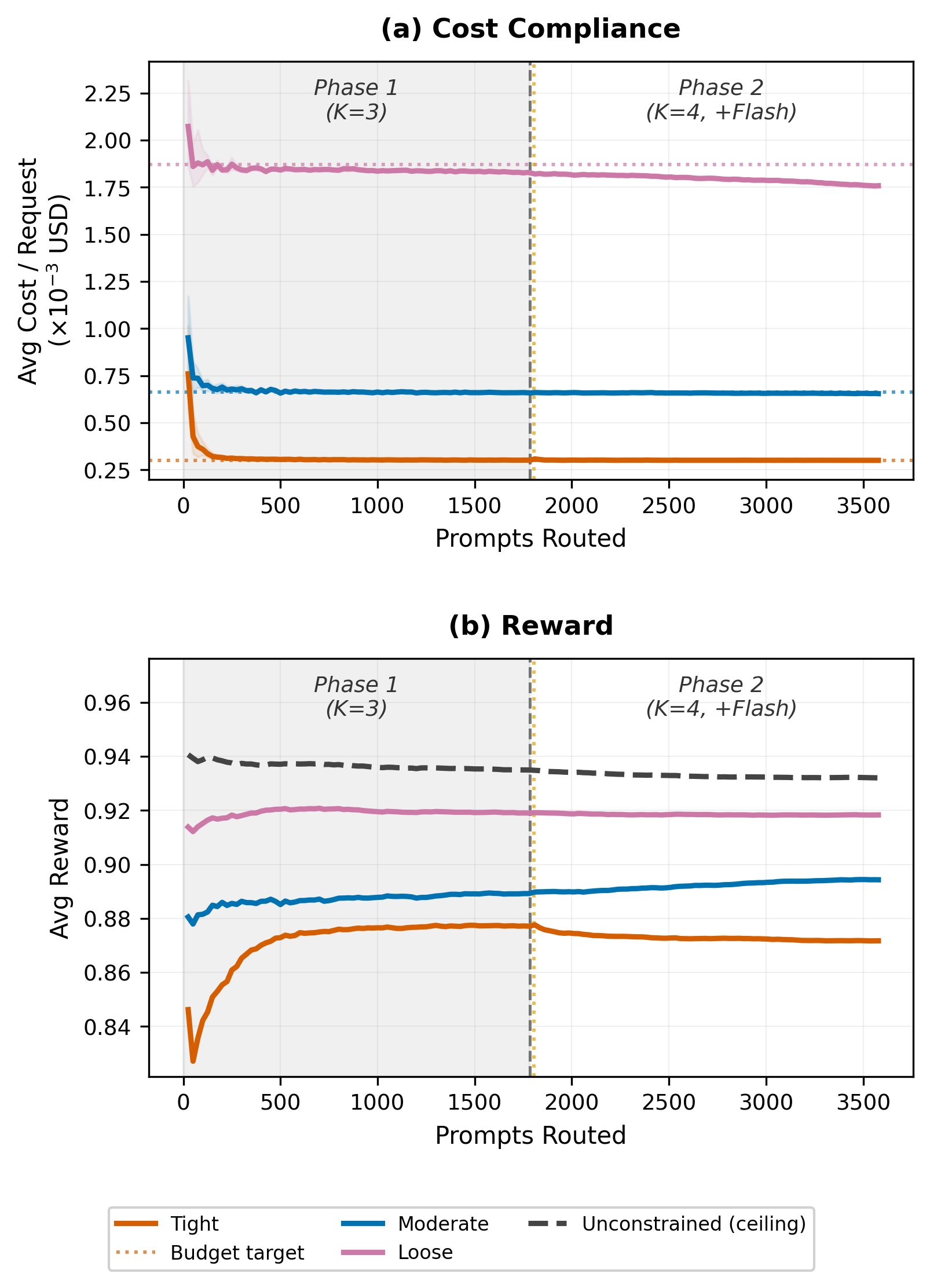
Figure 5: Cost compliance over the onboarding window, showing continuous enforcement across model transitions.
Robustness, Practicalities, and Limitations
Key claims are further validated:
- Cost penalty heuristic validity: The static, log-normalized arm cost heuristic strongly preserves true per-request cost ordering in portfolios with cost ratios of at least 10×.
- Judge-robust reward signal: Alternative LLM judges (GPT-4.1-mini, Claude-3.7-Sonnet) deliver the same expected-reward model ordering; cross-judge oracle performance is within a few percent.
- Latency efficiency: Routing (including embedding and transformation) is <0.4% of median LLM inference time, imposing negligible runtime overhead.
- Hyperparameter determinism: The adaptation horizon parameter (Tadapt) reliably determines tradeoff between fast adaptation and stationary reward, reducing operational uncertainty in production deployment.
Limitations include exclusive reliance on offline datasets (with simulated non-stationarity and delayed feedback yet to be fully validated in live systems), lack of human-in-the-loop reward noise, and focus on per-request rate constraints over aggregate spend. The current system is quality-maximizing under budget, while some deployments may require cost minimization under quality constraints or multi-dimensional (e.g., latency-aware) routing.
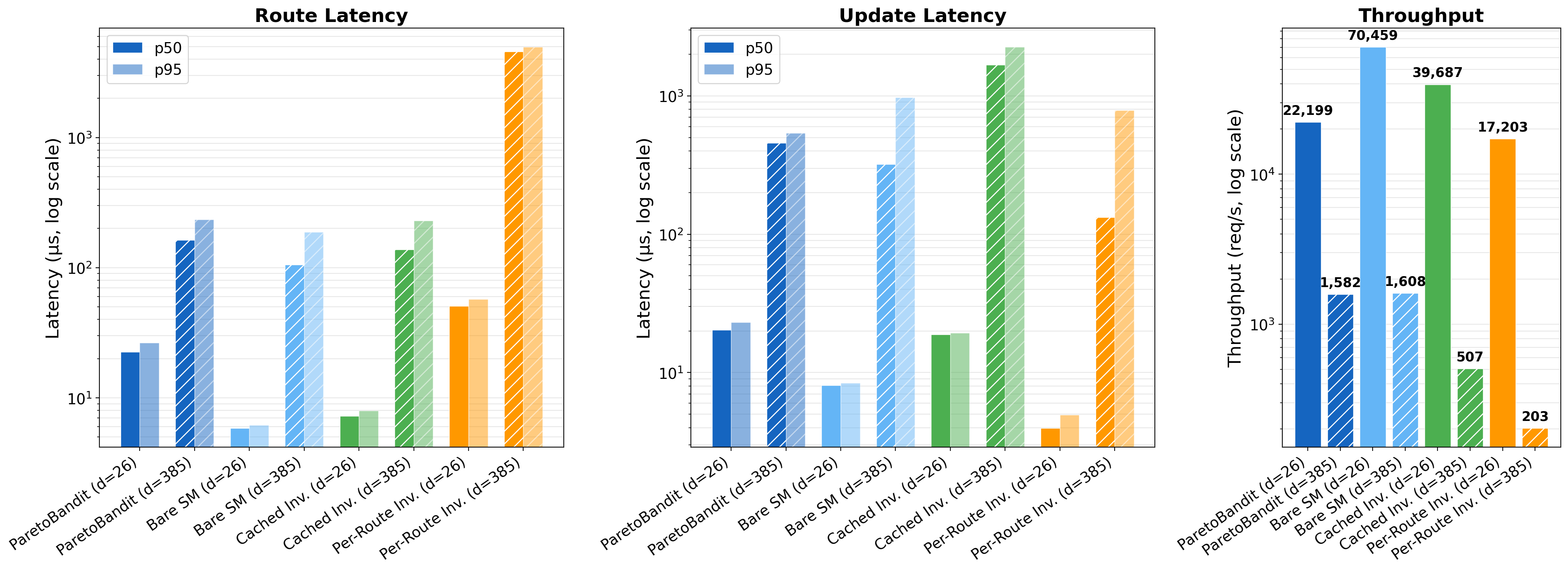
Figure 6: Microbenchmarking of routing latency and update efficiency, demonstrating production latency far below LLM inference.
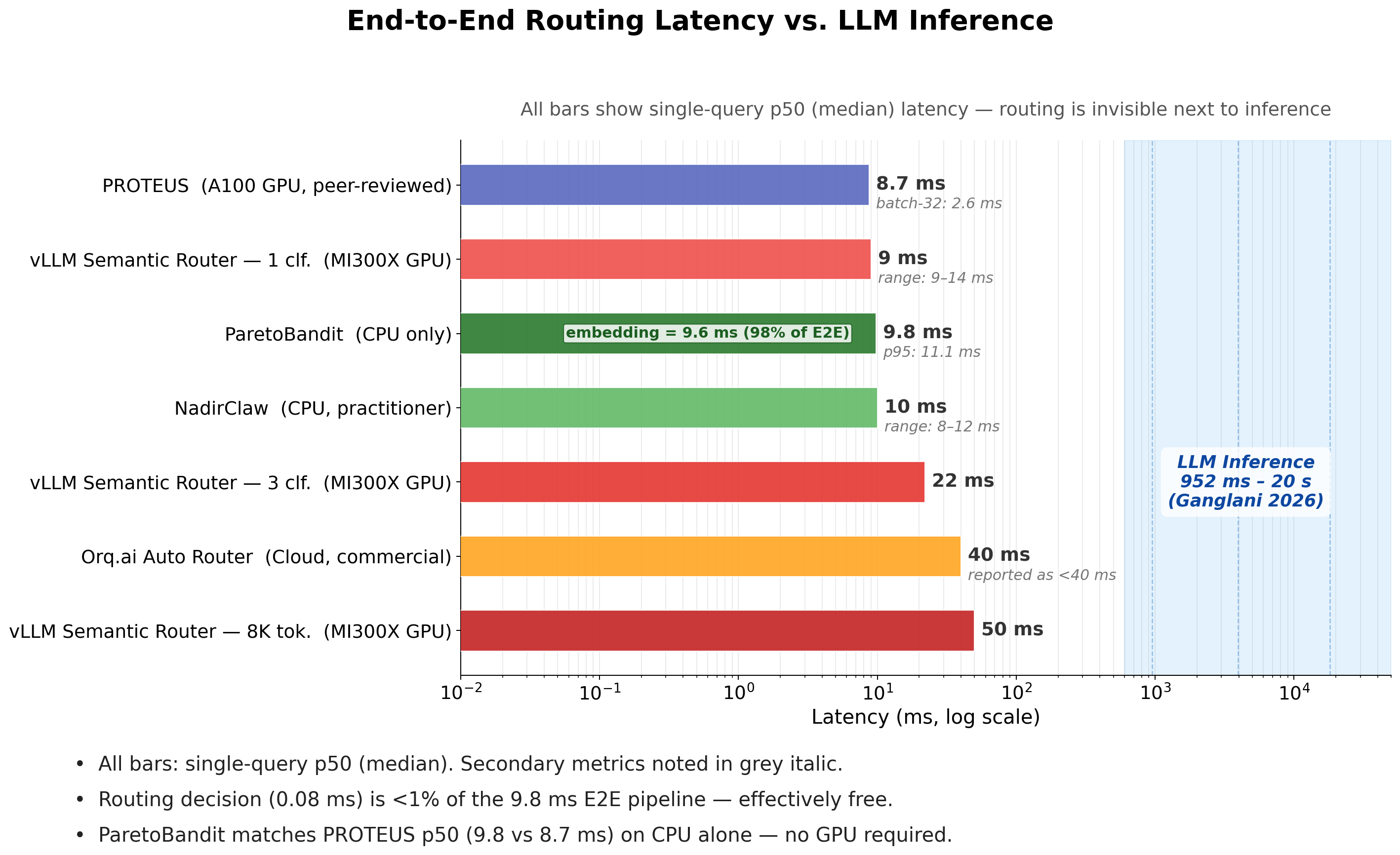
Figure 7: ParetoBandit routing latency compared to LLM inference, confirming sub-percentile overhead.
Conclusion
ParetoBandit is the first LLM router to provide online budget-pacing, non-stationarity adaptation, and live portfolio management within a contextual bandit framework tailored for open-ended, real-world LLM serving. Experiments demonstrate robust, precise budget adherence, data-driven exploitation of mid-deployment changes, resilience to model degradation, and practical deployment readiness evidenced by sub-millisecond routing latency and portfolio flexibility.
The practical implication is that closed-loop, adaptive contextual bandit routing is essential for reliable, cost-efficient, and agile LLM serving in production environments characterized by evolving model landscapes and volatile cost-quality tradeoffs.
Future Prospects
Essential research directions include: live deployment validation under stochastic feedback and traffic, multi-objective extensions incorporating downstream metrics (latency, user satisfaction), aggregate budget window enforcement, and quality-constrained routing. Integrating human-in-the-loop feedback and delay-aware reward prediction are natural augmentations, as is extending the framework to support richer operator constraints and multiple orthogonal resource budgets.
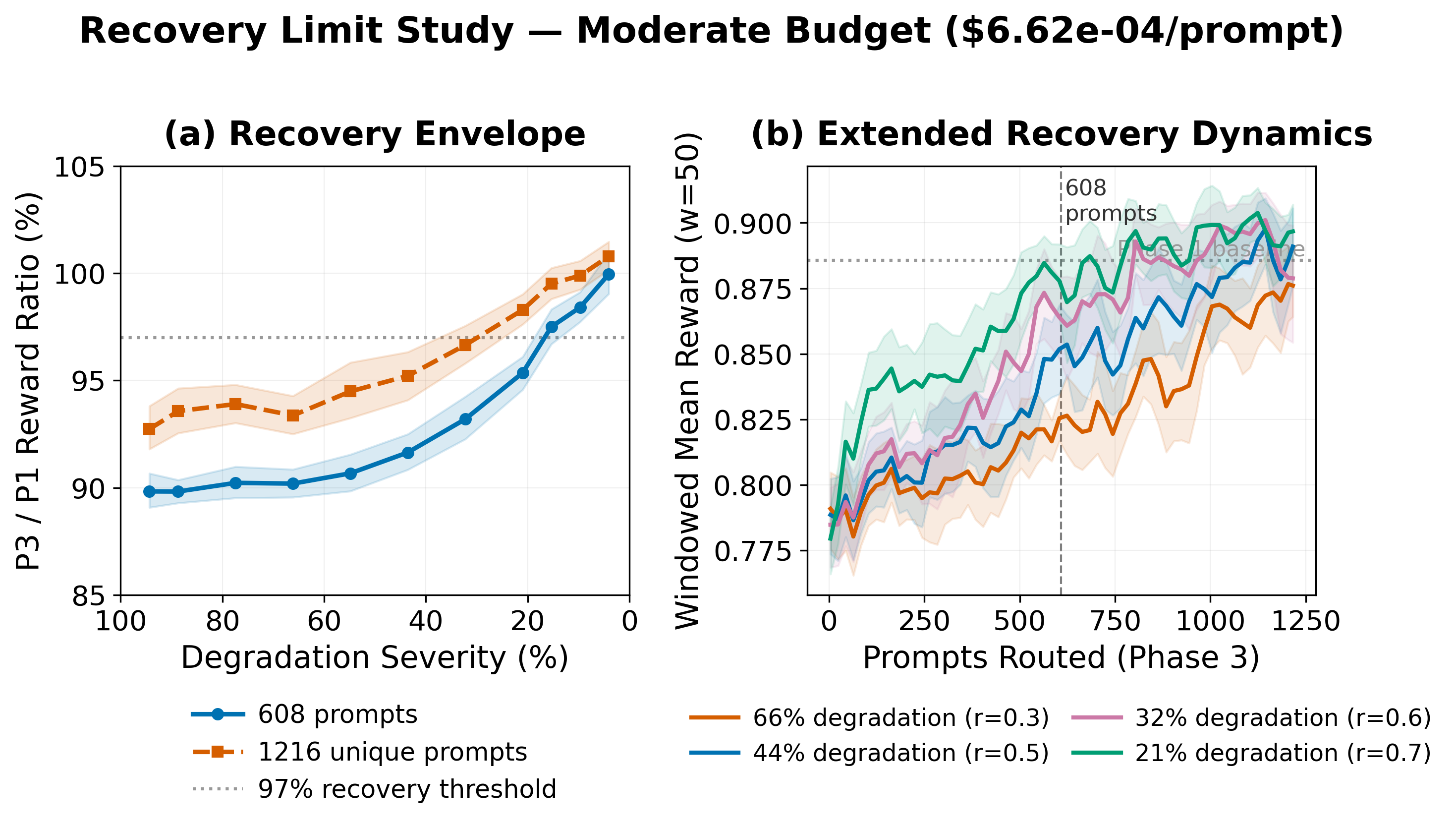
Figure 8: Characterization of recovery dynamics after varying levels of silent model degradation—evidence for practical feasibility of adaptation within bounded data.
References
- Taberner-Miller, A. "ParetoBandit: Budget-Paced Adaptive Routing for Non-Stationary LLM Serving" (2604.00136)