One Head, Many Models: Cross-Attention Routing for Cost-Aware LLM Selection
(2509.09782v1)
Published 11 Sep 2025 in cs.LG
Abstract: The proliferation of LLMs with varying computational costs and performance profiles presents a critical challenge for scalable, cost-effective deployment in real-world applications. We introduce a unified routing framework that leverages a single-head cross-attention mechanism to jointly model query and model embeddings, enabling dynamic selection of the optimal LLM for each input query. Our approach is evaluated on RouterBench, a large-scale, publicly available benchmark encompassing diverse LLM pools and domains. By explicitly capturing fine-grained query-model interactions, our router predicts both response quality and generation cost, achieving up to 6.6% improvement in Average Improvement in Quality (AIQ) and 2.9% in maximum performance over existing routers. To robustly balance performance and cost, we propose an exponential reward function that enhances stability across user preferences. The resulting architecture is lightweight, generalizes effectively across domains, and demonstrates improved efficiency compared to prior methods, establishing a new standard for cost-aware LLM routing.
Sponsor
Organize your preprints, BibTeX, and PDFs with Paperpile.
The paper introduces a decision-making router leveraging cross-attention to balance LLM performance and computational cost for optimal query handling.
It employs both linear and exponential reward formulations, with empirical results showing superior performance-cost trade-offs via higher AIQ scores than traditional methods.
The framework demonstrates scalability and generalizability on diverse datasets, promising efficient, real-time LLM deployment in dynamic environments.
One Head, Many Models: Cross-Attention Routing for Cost-Aware LLM Selection
Introduction
The paper "One Head, Many Models: Cross-Attention Routing for Cost-Aware LLM Selection" introduces an innovative framework for selecting the most appropriate LLM for a given query, balancing computational cost and response quality. Leveraging a cross-attention mechanism, the framework jointly models query and LLM embeddings, facilitating dynamic selection of the optimal LLM for each input query. This approach addresses the challenge of efficiently deploying LLMs with varying costs and performance profiles in real-world applications.
Methodology
Problem Formulation
The paper designs a decision-making LLM router that assigns queries from a user space Q to models in a pool M, optimizing a trade-off between response quality and computational cost. The guiding principle is cost-efficiency; a query should only use a more expensive model if less costly alternatives cannot provide satisfactory results and the user is willing to bear the additional cost.
Predictor-Based Routing Framework
To predict the performance and cost of candidate models, the framework employs a cross-attention mechanism. Specifically, user queries are encoded as query vectors q, while model representations serve as keys k and values v, capturing the latent expertise of each LLM.
The attention mechanism computes the attention score using:
Attention(q,k,v)=softmax(dvq⋅kT)v
This similarity-based routing allows the model to generalize across different LLM pools by learning complex interactions between inputs and models.
Reward Functions
Two reward formulations are proposed for evaluating cost-performance tradeoffs:
Linear Trade-off (R1): Balancing quality and cost linearly, defined as R1=s−λ1c, where s is the performance score, c is the cost, and λ is the user's willingness to pay.
Exponential Trade-off (R2): Offering more stable outcomes by using R2=s×exp(−λ1c), demonstrating lower sensitivity to user parameter variations.
Empirical results show the robustness of the exponential formulation over the linear counterpart due to its bounded cost-effectiveness.
Evaluation
Datasets and Baselines
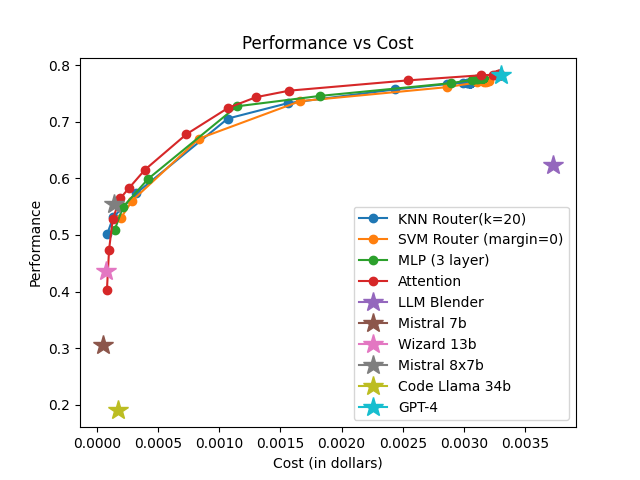
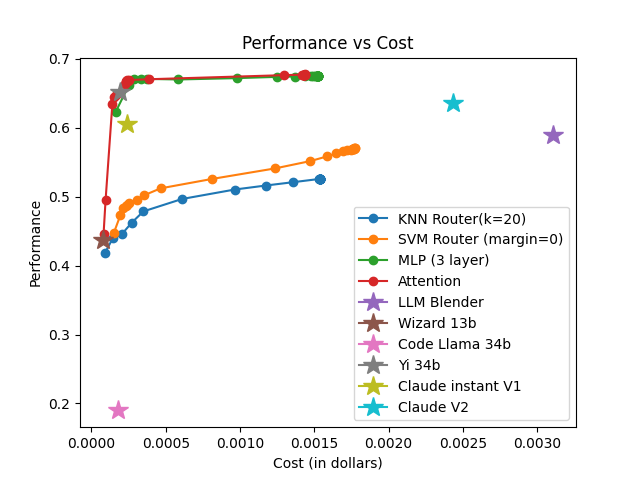
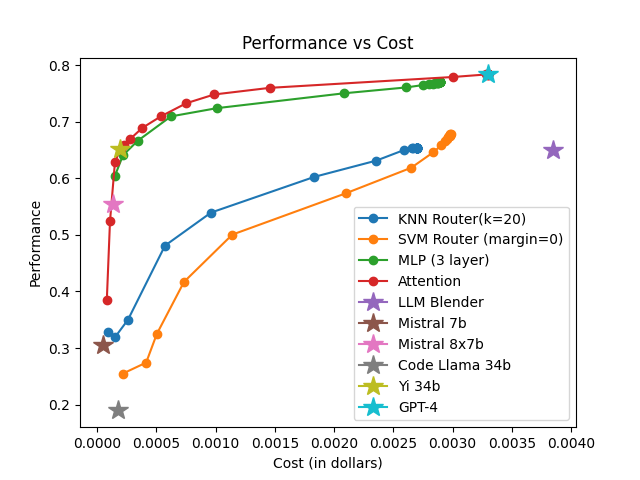
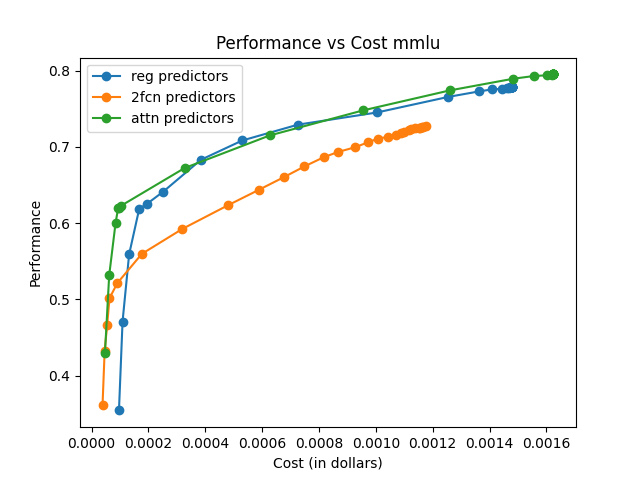
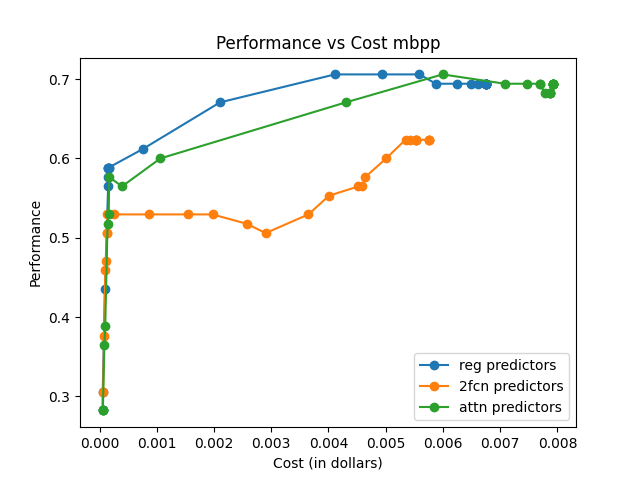
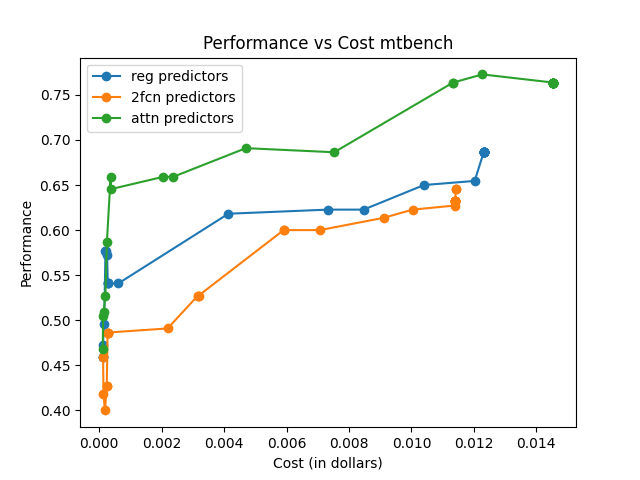
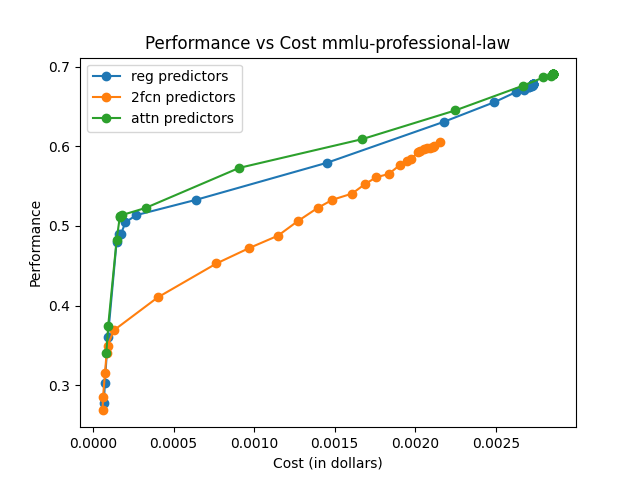
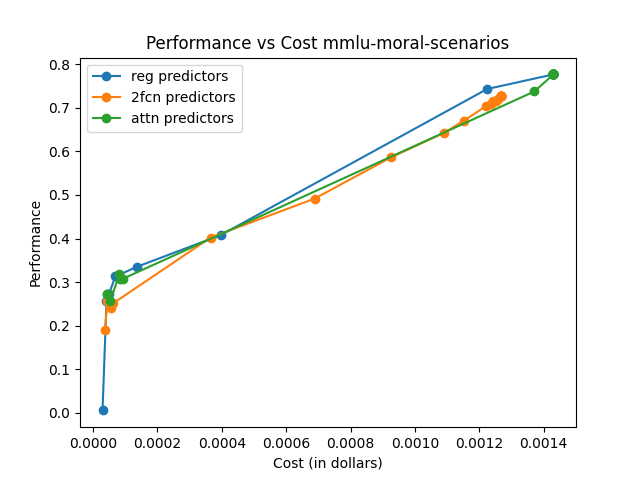
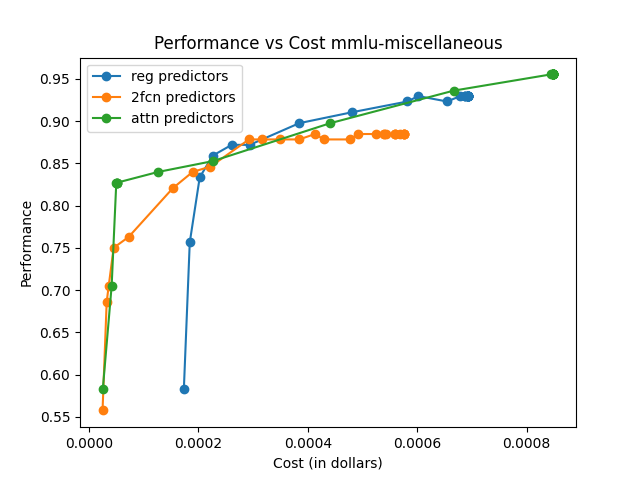
The framework is evaluated on RouterBench, a large-scale benchmark featuring multiple LLM pools and domains. Comparisons are made against traditional routing techniques like KNN, MLP, and SVM, highlighting superior AIQ (Average Improvement in Quality) scores and demonstrating notable performance-cost trade-offs.
Figure 1: LLM pool 1
Performance Metrics
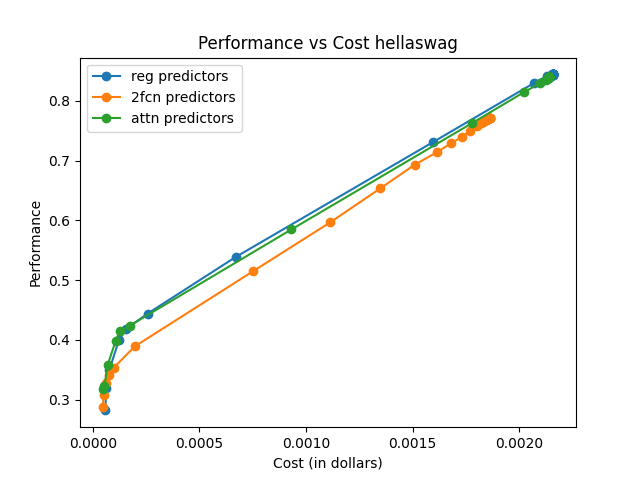
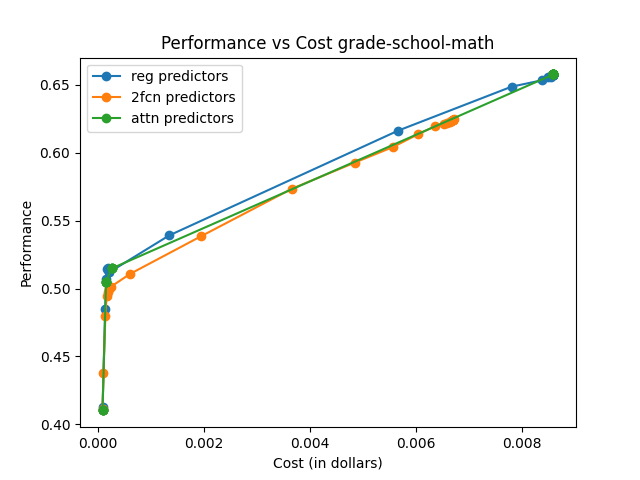
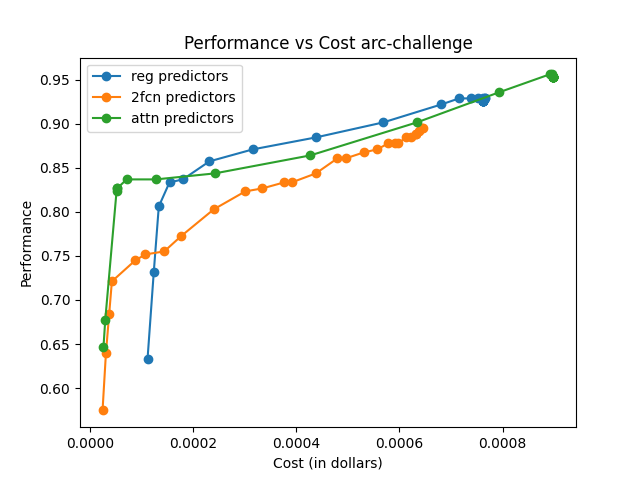
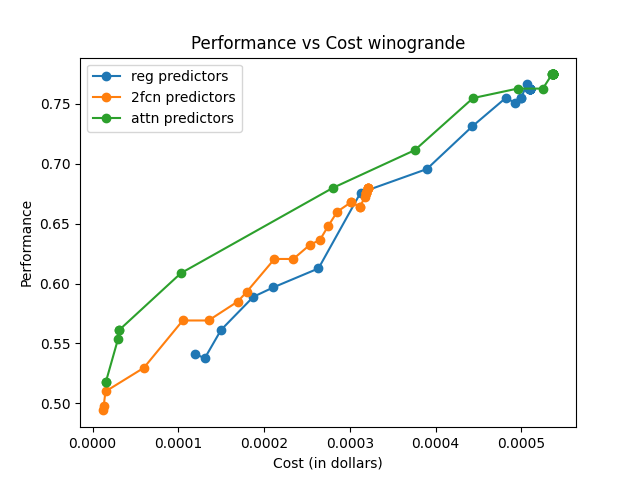
The effectiveness is measured using AIQ, reflecting the trade-off between performance and cost by computing the area under a cost–quality Pareto frontier. Across all pools, the attention-based router consistently achieves higher AIQ scores and better maximum performance compared to baseline methods.
The attention-based router demonstrated superior performance across various data sets and tasks, emphasizing its capability to generalize and efficiently manage trade-offs between model performance and execution cost.
Figure 3: Hellaswag
The framework's scalability is achieved without extensive retraining, as model representation construction is decoupled from predictors' training. This adaptability is crucial for dynamic environments where LLM pools evolve.
Conclusion
The paper presents a pioneering approach to LLM selection, balancing performance and computational cost using a cross-attention mechanism. With robust empirical performance across diverse tasks, the proposed method sets a new standard for cost-efficient, real-time LLM deployment, offering significant implications for scalable AI system designs. Future research could further explore dynamic dataset environments and refine model uncertainties.