- The paper introduces an INT8-based FP64 emulation framework that adapts legacy BLAS routines for GPU acceleration in ab initio electronic structure calculations.
- It demonstrates high numerical fidelity with precision tunability achieving errors as low as 10^-10 and an average 1.7× speedup on performance benchmarks.
- The method enables seamless integration into existing DFT codes without modification, promoting adaptive precision management for future HPC hardware.
Precision Emulation for GPU-Accelerated Ab Initio Electronic Structure Calculations
Introduction
The proliferation of AI-oriented hardware architectures has driven an industry-wide shift toward low-precision arithmetic units in modern GPUs, such as INT8 and FP16 tensor/matrix cores. While these advancements have greatly accelerated machine learning workloads, they present challenges for traditional HPC applications—particularly those reliant on double-precision (FP64) computations, such as ab initio electronic structure calculations. The paper "A Precision Emulation Approach to the GPU Acceleration of Ab Initio Electronic Structure Calculations" (2603.29975) presents a framework for addressing this hardware-software mismatch via high-throughput tunable-precision emulation, specifically in the context of BLAS-intensive quantum chemistry codes.
Methodology: INT8-based FP64 Emulation and Automated BLAS Offload
The approach leverages two core technologies: SCILIB-Accel, an automatic BLAS offload tool designed for CPUs and GPUs with cache-coherent unified memory, and GEMMul8, which implements emulation of FP64 GEMM via INT8 matrix multiplication following the Ozaki-II scheme. SCILIB-Accel transparently intercepts BLAS calls in legacy CPU codes, rerouting compute-intensive matrix multiplications to the GPU. GEMMul8 redirects cuBLAS GEMM calls to its own INT8-based emulation, allowing fine-grained control over emulated precision by adjusting moduli counts, with no source code modification required.
Unlike canonical mixed-precision approaches, which often necessitate algorithmic changes and explicit error correction schemes in solvers, this emulation pipeline preserves the original program semantics. The system enables live tunability between performance and numerical accuracy—a critical capability as contemporary AI-specialized GPUs (e.g., NVIDIA Blackwell, Rubin) increasingly deprecate native FP64 throughput in favor of low-precision compute.
Application to LSMS in the MuST Suite
The authors apply this methodology to the LSMS (Locally Self-consistent Multiple Scattering) method as implemented in the MuST suite—a widely used O(N) electronic structure code. LSMS primarily solves the Kohn-Sham equation using the Green function formalism and is computationally dominated by BLAS calls (ZGEMM/ZTRSM), with matrix dimensions on the order of 33,750×33,750 in benchmarks.
GPU acceleration is traditionally hindered by the cost of adapting LSMS's legacy codebase. By deploying SCILIB-Accel and GEMMul8, the study demonstrates seamless migration of numerically intensive routines to INT8-optimized hardware, achieving tunable precision in the inversion of the multiple scattering matrix critical for self-consistent field (SCF) iterations.
A primary metric for emulation fidelity is the maximum percent error of the energy-dependent, atomic-volume-integrated Green function G(z). Across a range of emulation granularities—implemented as mantissa bit width gradations in cuda13 (Ozaki-I) and moduli counts in GEMMul8 (Ozaki-II)—the results indicate exponential improvement in accuracy with increased precision controls.
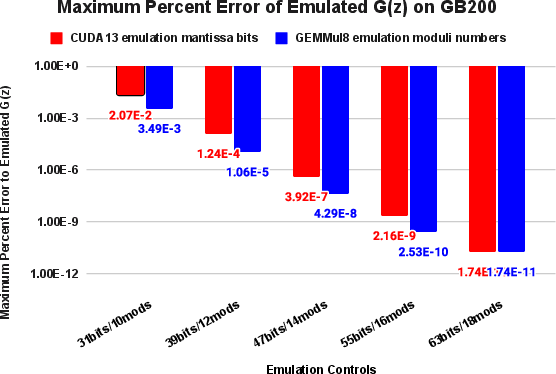
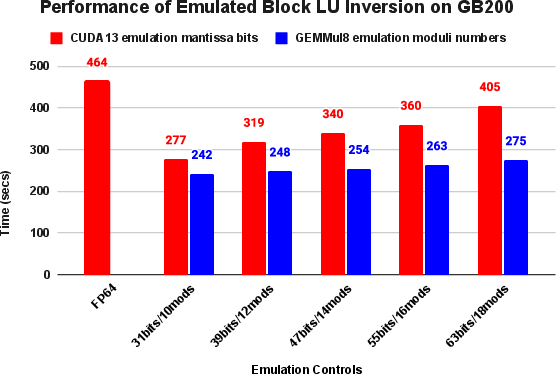
Figure 1: Maximum percent error of emulated G(z) demonstrates several orders of magnitude fidelity gain as emulation precision is increased via mantissa bit width or moduli count.
For example, low-precision emulation at 31 mantissa bits or 10 moduli yields percent errors up to 10−2, while higher-precision settings (55 bits/16 moduli) achieve errors ≤10−10—matching the variance typical of native FP64 computations across compilers and HPC environments. Most notably, these minuscule errors are well within the envelope of physical acceptability for DFT-based observables. Lower precision modes can result in SCF convergence failure, but precision modes ≥39 bits/12 moduli reliably reproduce total energies, local moments, and net charges to the last significant digit of the FP64 baseline.
This emulation framework also results in tangible computational acceleration—high-precision emulation mode attains an average 1.7× speedup relative to native FP64 pipelines on the NVIDIA GB200 platform. The critical observation is that errors in emulated Green functions are spectrally localized around the Fermi energy and further attenuated by quadrature integration and the variational stability inherent to total energy functionals in DFT.
Implications for HPC and Future Hardware Co-design
The results support a strong case for broad adoption of adaptive, emulation-based precision strategies in scientific codes. By decoupling required numerical fidelity from hardware data type limitations, the methodology accommodates future architectures with diminishing FP64 throughput. It also eliminates the extensive software engineering burdens traditionally associated with adapting legacy simulation codes for GPU acceleration.
Key theoretical implications include:
- Algorithmic resilience in LSMS/Ozaki schemes: The inherent stability of the LSMS approach, and similar DFT-based methods, against quantization and emulation errors, facilitates deep integration of tunable-precision paradigms without algorithmic redesign.
- Decisive advantage over traditional mixed-precision: By orthogonally addressing precision control and compute mapping, the method circumvents common limitations and error-propagation risks associated with in-place mixed-precision solvers.
Practically, such frameworks pave the way for maximal exploitation of upcoming AI-oriented supercomputing installations, ensuring that core scientific applications—climate modeling, quantum chemistry, materials science—remain performant and reliable after hardware transitions.
Outlook and Future Work
Anticipated future directions include refinement of emulation strategies (e.g., leveraging advanced error correction, lower-precision kernels, or new CRT-based compositions), extension to a broader suite of BLAS/LAPACK routines, and joint optimization of hardware-software stacks via collaborative design between domain experts and hardware architects. Systematic evaluation of the impact of emulation on more tightly coupled or ill-conditioned physical problems, as well as direct coupling with AI-driven surrogate models, presents additional research avenues.
Conclusion
This study establishes the feasibility and efficiency of INT8-based emulation for FP64 matrix-math workloads—demonstrating that carefully tuned emulation not only preserves scientific fidelity but recovers substantial performance headroom on current and next-generation GPU hardware. The approach offers a generic route to sustain ab initio simulations amid hardware trends prioritizing low-precision arithmetic, and underscores the need for future scientific software to embrace adaptive, hardware-aware precision management.