Double-Precision Matrix Multiplication Emulation via Ozaki-II Scheme with FP8 Quantization
Abstract: In high-performance computing (HPC) applications, FP64 arithmetic remains indispensable for ensuring numerical accuracy and stability. However, in recent hardware generations, improvements in FP64 arithmetic performance have been relatively modest. Consequently, achieving sustained performance gains for FP64 computations necessitates the effective utilization of high-throughput low-precision arithmetic, such as INT8 and FP8. In several recent architectures, such as NVIDIA Blackwell Ultra and NVIDIA Rubin, INT8 performance has been significantly reduced, making reliance on INT8 alone insufficient. The use of FP8 arithmetic is thus increasingly important. In this paper, we propose a method for emulating double-precision (FP64) general matrix--matrix multiplication (DGEMM), a fundamental and performance-critical kernel in many HPC applications, using FP8 matrix multiply-accumulate (MMA) units. The Ozaki-I and Ozaki-II schemes are well established as foundational approaches for emulating DGEMM via low-precision arithmetic. For DGEMM emulation via the Ozaki-I scheme, implementations using INT8, FP8, and FP16 MMA units have been proposed, all of which can be realized based on the same underlying algorithmic structure. In contrast, although implementations of DGEMM emulation via the Ozaki-II scheme using INT8 MMA units have been reported, the original algorithm cannot be directly adapted to exploit FP8 MMA units. In this work, we introduce a novel technique to overcome this limitation and demonstrate FP64 matrix multiplication emulation based on the Ozaki-II scheme that operates on FP8 MMA units. Compared to FP8-based emulation via the Ozaki-I scheme, our method significantly reduces the number of required FP8 matrix multiplications and enables efficient FP64 emulation on emerging GPU architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a clever way to do very accurate matrix multiplication (the kind scientists use, called “double precision” or FP64) using much faster, low-precision hardware (FP8) found on new AI-focused chips. The authors adapt a method called the “Ozaki-II scheme” so it works well with FP8 units, letting computers get FP64‑like answers while mostly doing FP8‑speed work.
What questions are the authors trying to answer?
The authors focus on simple, practical questions:
- Can we use very fast FP8 hardware to mimic the accuracy of slow, very precise FP64 math for matrix multiplication (GEMM), a core operation in science and engineering?
- Can we adapt the Ozaki-II method—originally built for integer math (INT8)—so it works reliably with FP8?
- Can we do this while using fewer FP8 multiplications than other FP8 methods (like Ozaki‑I), so it’s fast on new GPUs?
- How does this approach compare in speed, accuracy, and memory use to existing INT8 and FP8 methods?
- Which low-precision format (FP8, FP16/BF16, FP4) is the best match for this idea?
How does their method work?
Here’s the idea using everyday language.
The challenge
- New chips are built to run AI fast, so they’re great at low-precision math (like FP8) and not as strong at FP64.
- Scientists still need FP64‑level accuracy to keep results stable and trustworthy.
- The goal: get FP64‑quality answers while mostly using FP8‑speed hardware.
The Ozaki idea, in short
- Ozaki schemes (I and II) turn a hard, high-precision multiplication into several easier, low-precision multiplications and then combine the results to recover a very accurate answer.
- Ozaki‑II uses a “remainders” trick (the Chinese Remainder Theorem, or CRT). Think of finding a big secret number by knowing its remainders when you divide by several smaller numbers (like “the secret leaves remainder 2 mod 5, remainder 1 mod 7,” etc.). If you gather enough of these, you can reconstruct the big number exactly.
Why Ozaki‑II doesn’t directly fit FP8—and what they changed
- Ozaki‑II was designed for fixed-size integers (like INT8). FP8 is floating point, which behaves differently (it has exponents).
- The authors add two key ideas so FP8 works:
- Karatsuba splitting: When a number is too big for FP8, split it into two parts (like a high part and a low part). With a trick called Karatsuba, you can multiply two split numbers using 3 small multiplications instead of 4, then recombine them.
- A hybrid “modular reduction” trick: For certain special divisors (squares like 32², 25², etc.), they skip some Karatsuba steps and still get the right remainder. This reduces the total number of FP8 multiplications.
Putting it together:
Step 1: Scale the input matrices so their entries become integers that are safe to handle.
Step 2: For many carefully chosen small divisors (called “moduli”), compute products of the matrices modulo each divisor using FP8 matrix-multiply units.
Step 3: Use the CRT to rebuild the accurate product from all those modular results.
Step 4: Undo the scaling to get the final FP64‑quality matrix product.
They carefully choose the splitting and the sizes so that the FP8 units accumulate exactly (no rounding errors in the sum), which is crucial for accuracy.
Why FP8, not FP16, BF16, or FP4?
FP8 hits a sweet spot: it’s fast and, with the right setup, the chip can add up all the tiny FP8 products exactly in FP32 accumulators (no rounding during accumulation) for very large inner dimensions.
FP16/BF16 would need much smaller chunks to stay exact or would require more complicated splitting, which slows things down.
FP4 is too small to hold the intermediate sums cleanly in this method (unless future chips make FP4 so fast that three FP4 steps beat one FP8 step).
What did they find?
Here are the main takeaways, stated simply:
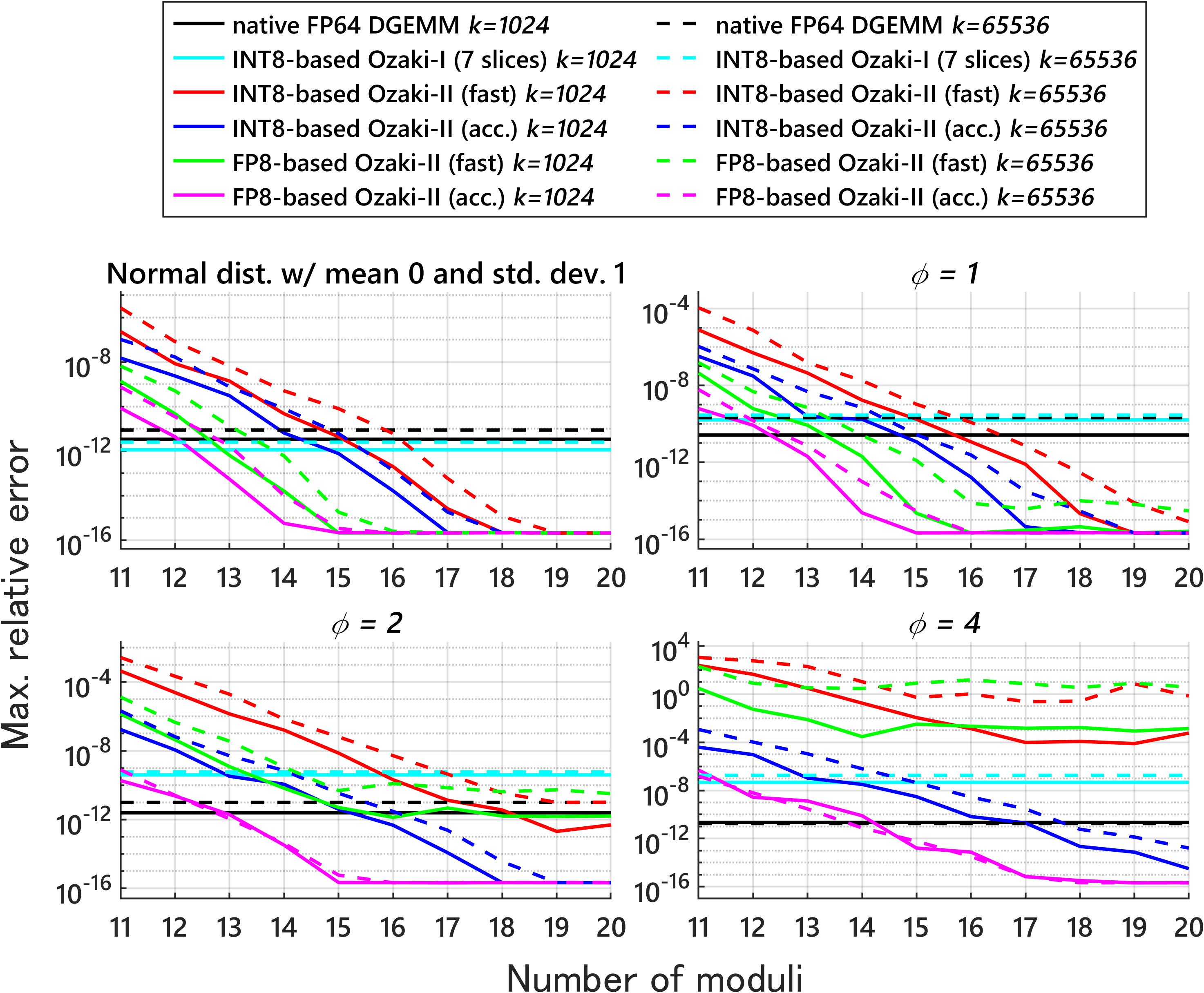
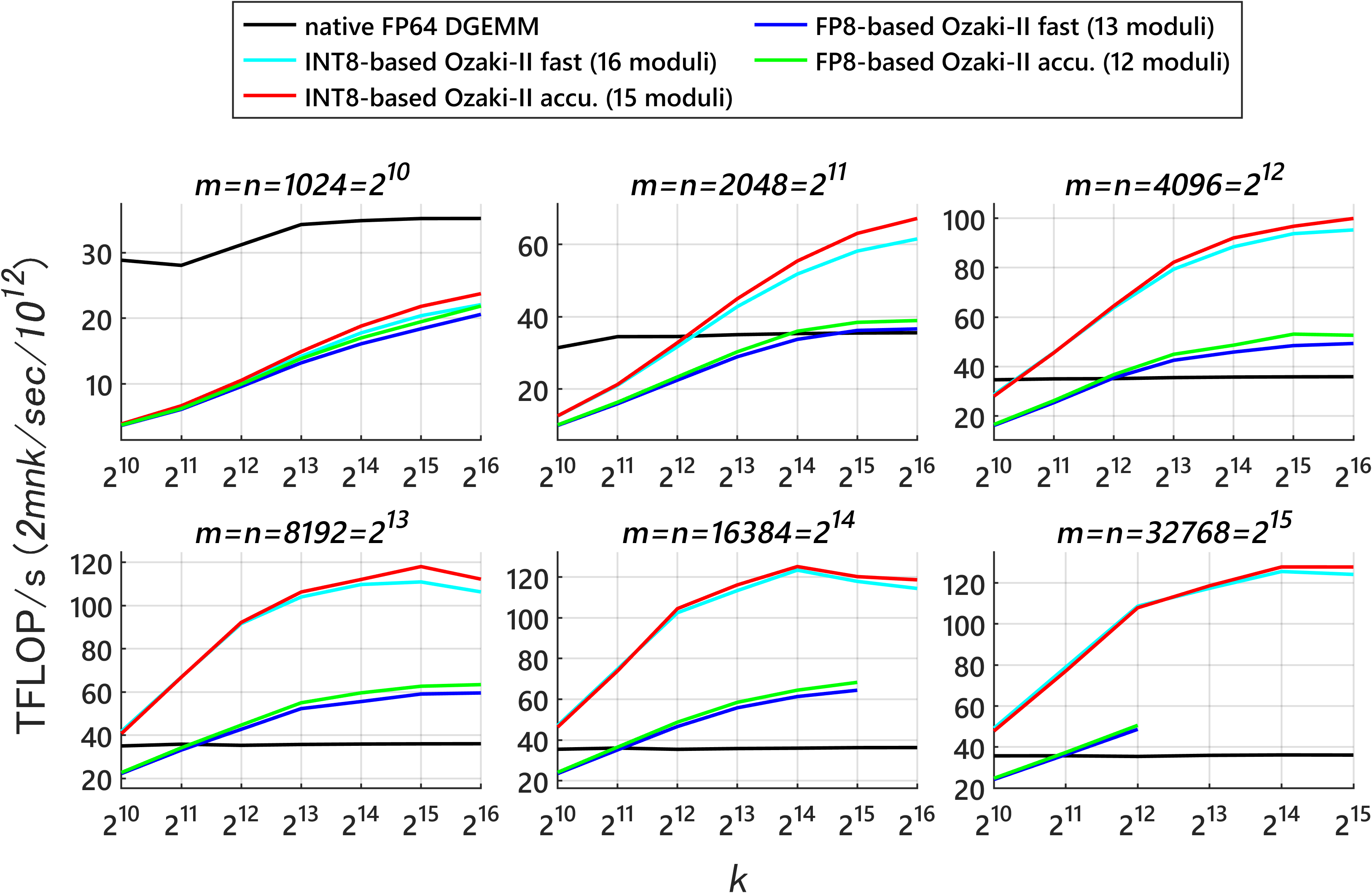
Fewer FP8 multiplications than FP8 Ozaki‑I: Their FP8 Ozaki‑II method needs far fewer FP8 matrix multiplications than the FP8 Ozaki‑I approach to reach FP64‑like accuracy. For example, to get roughly 53 bits of precision:
- FP8 Ozaki‑I needs at least 121 FP8 multiplications.
- Their FP8 Ozaki‑II needs about 36–40 FP8 multiplications (depending on mode).
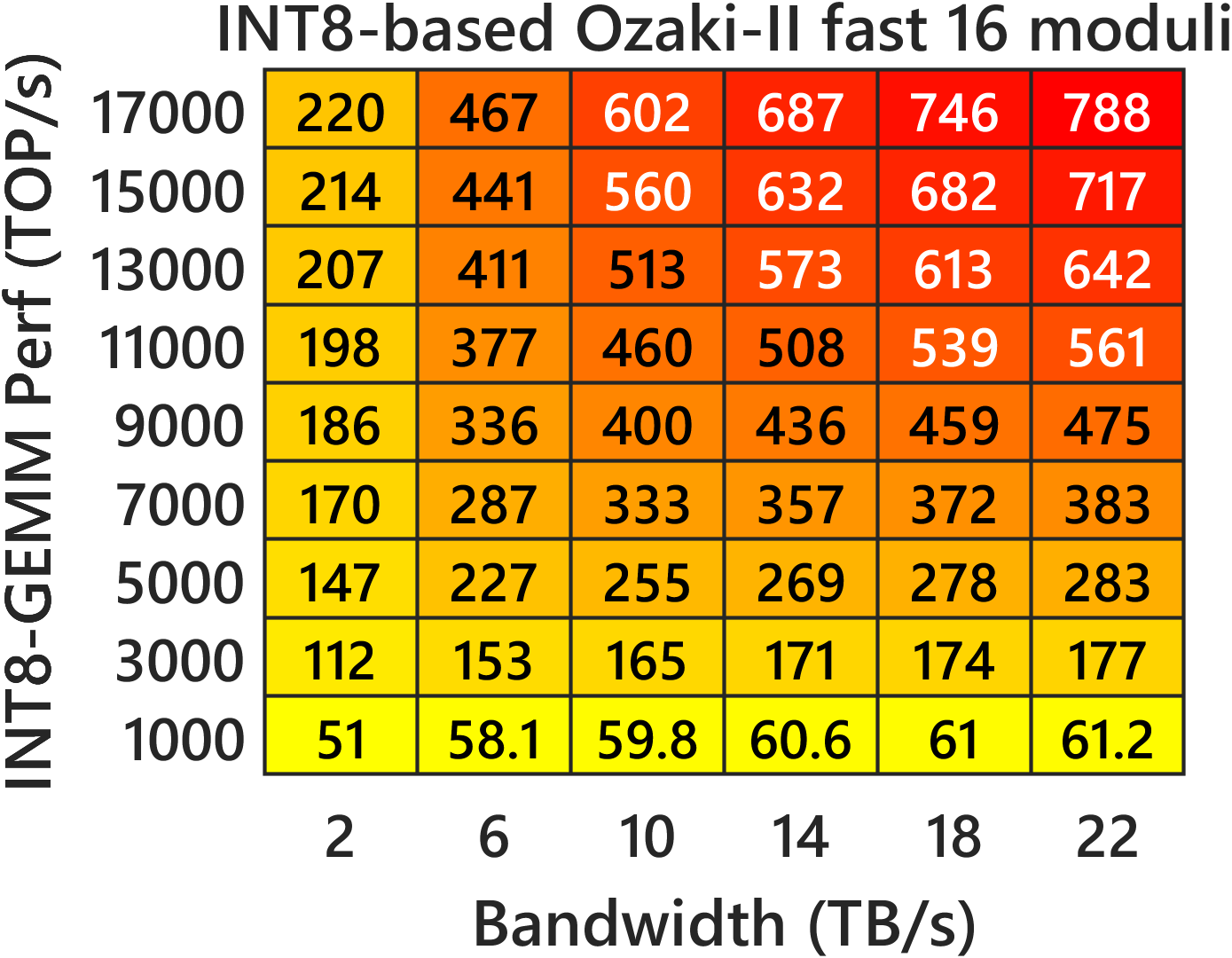
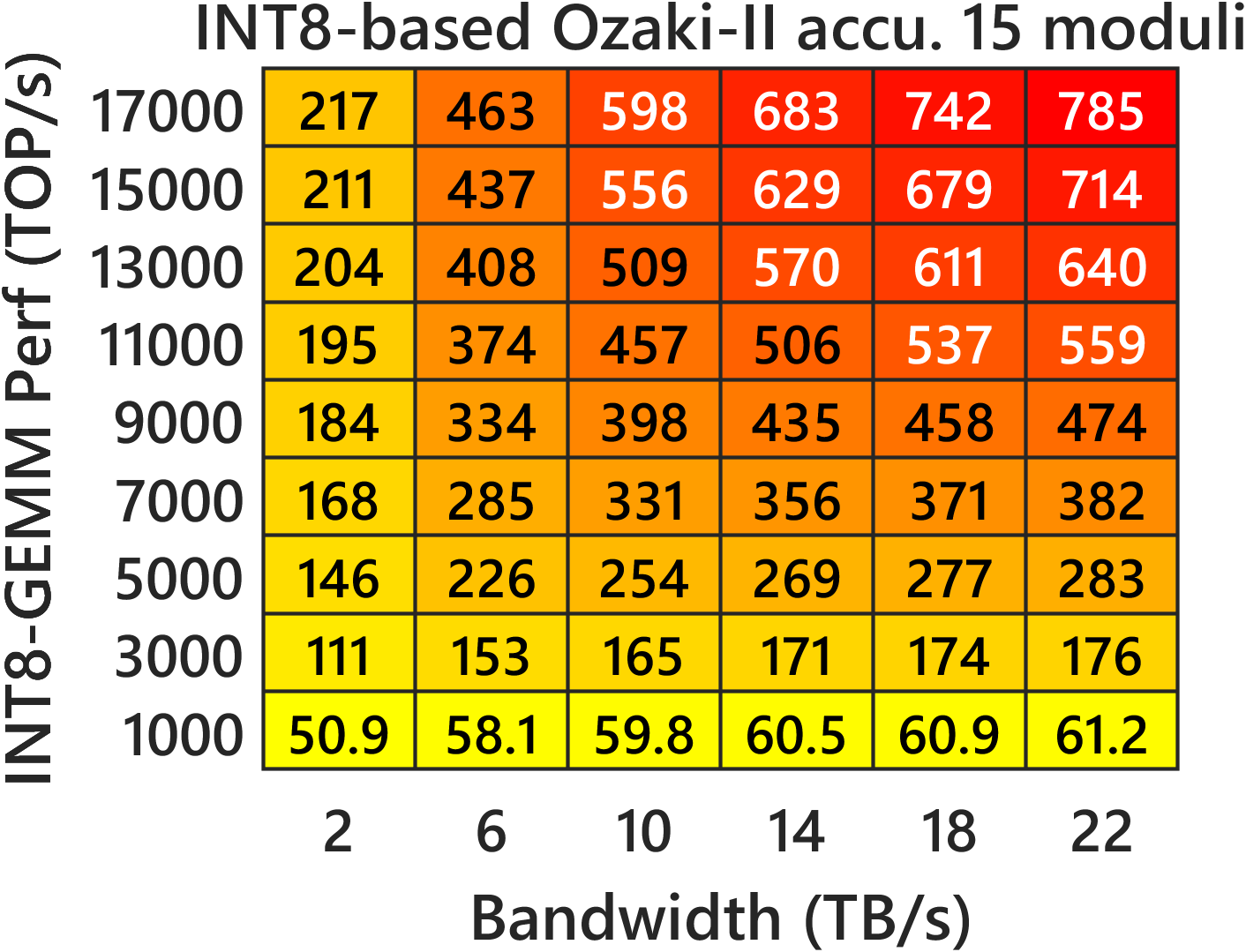
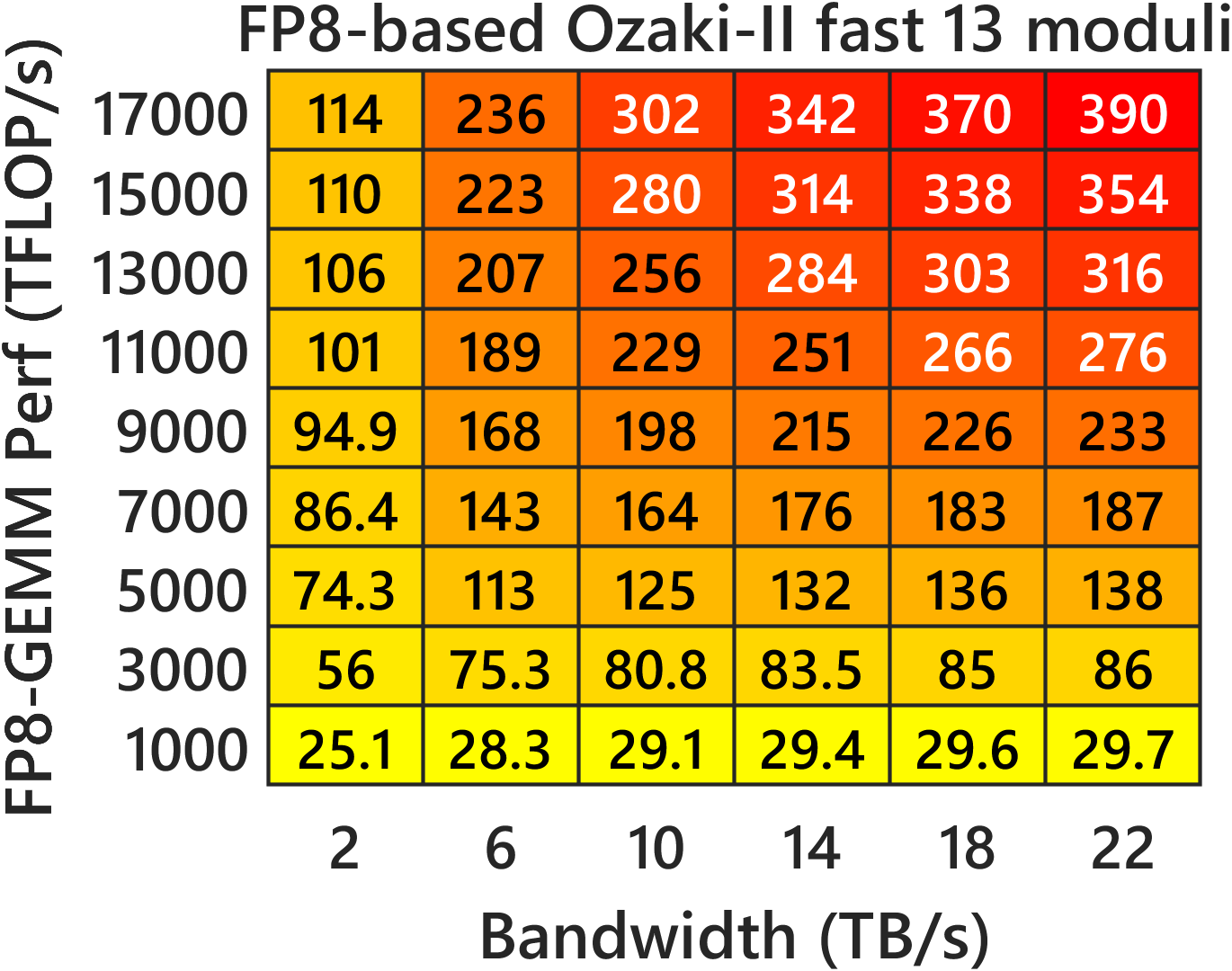
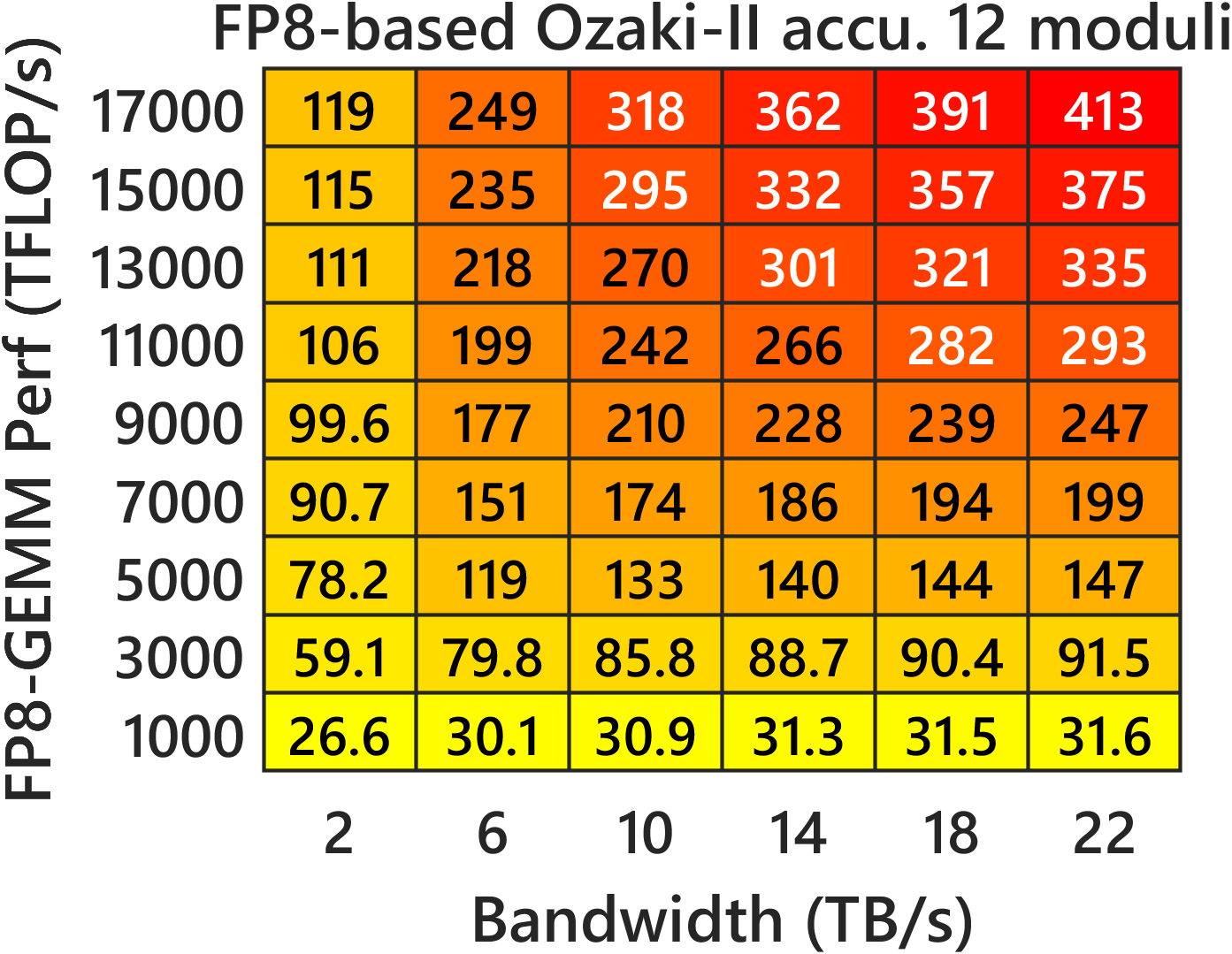
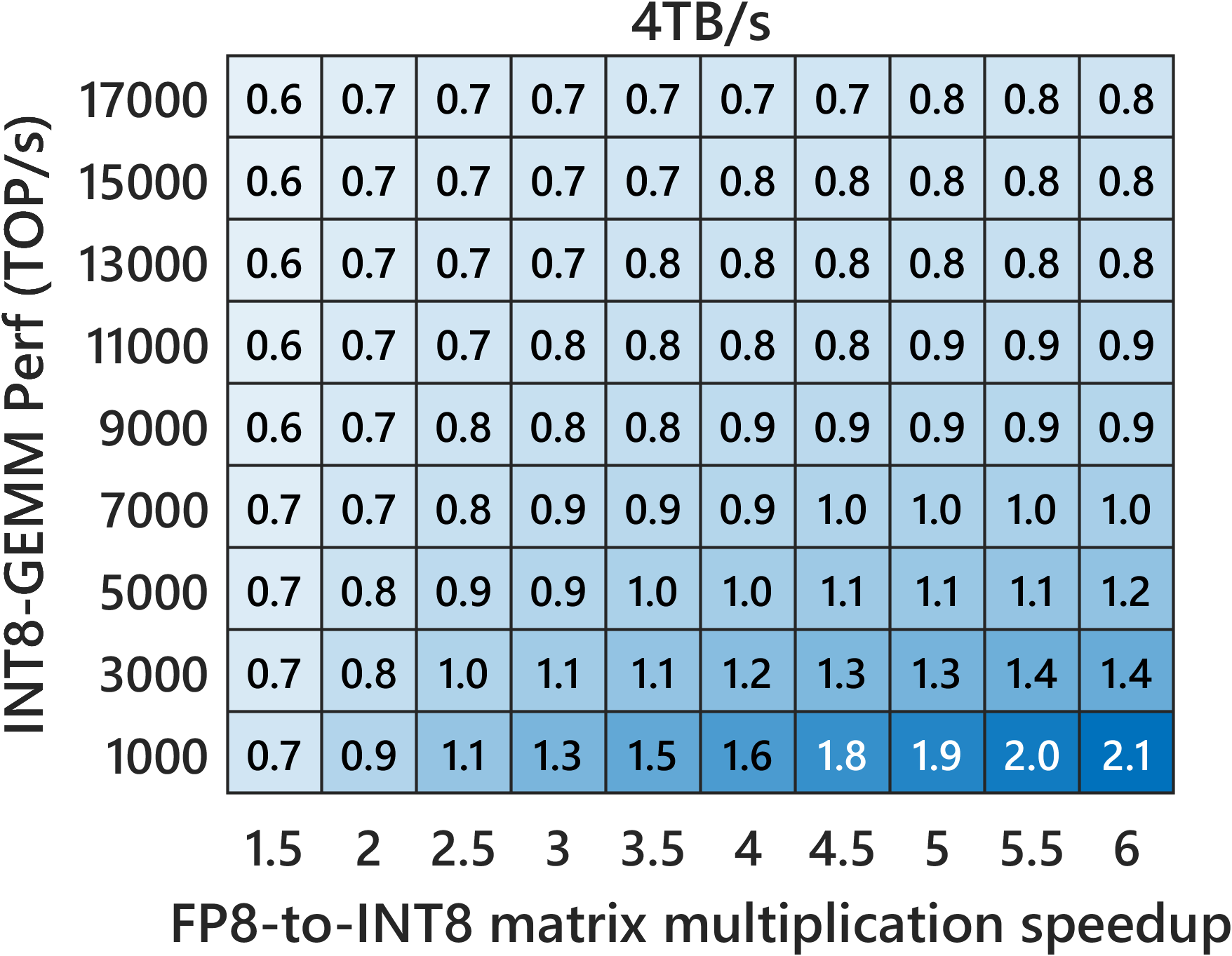
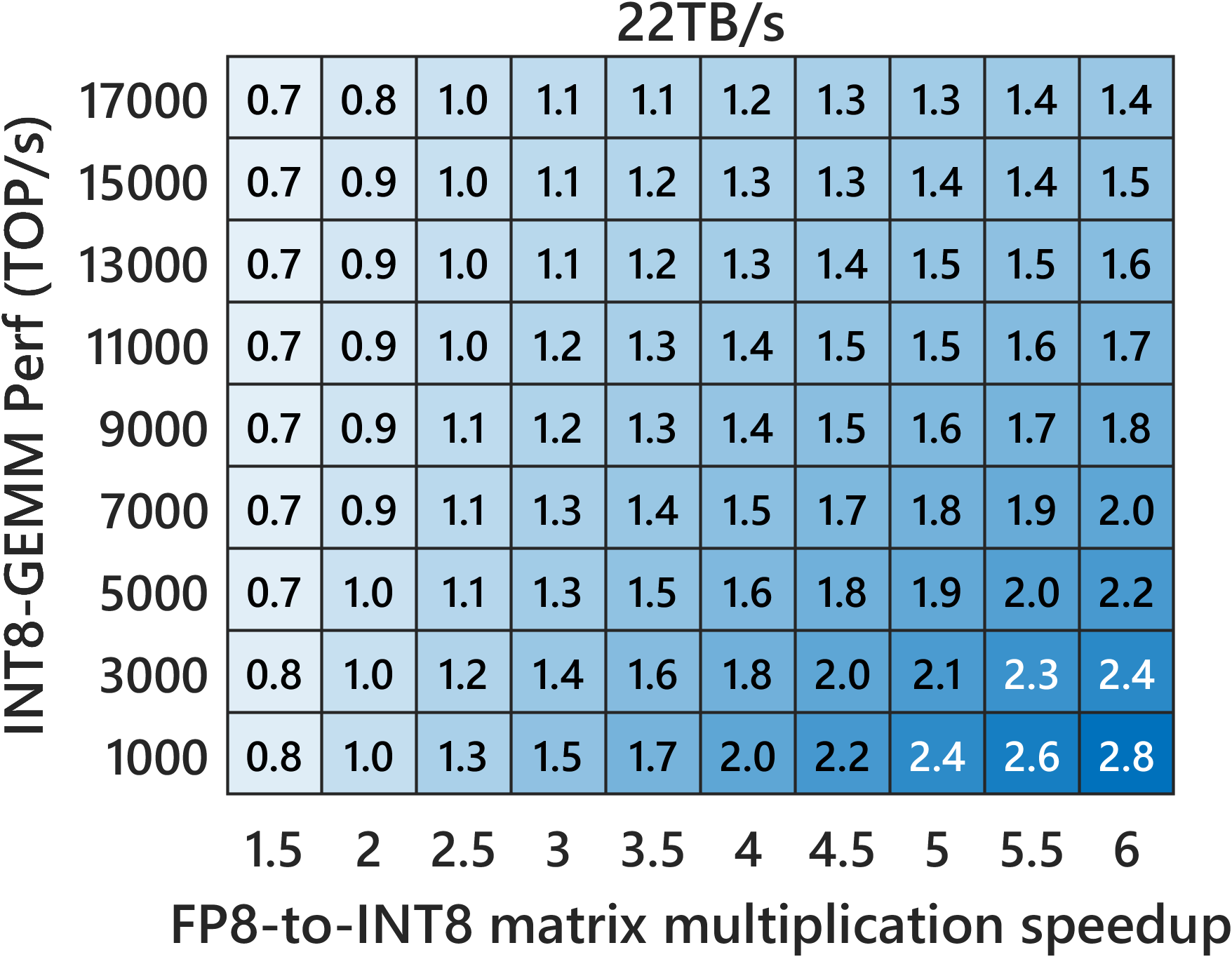
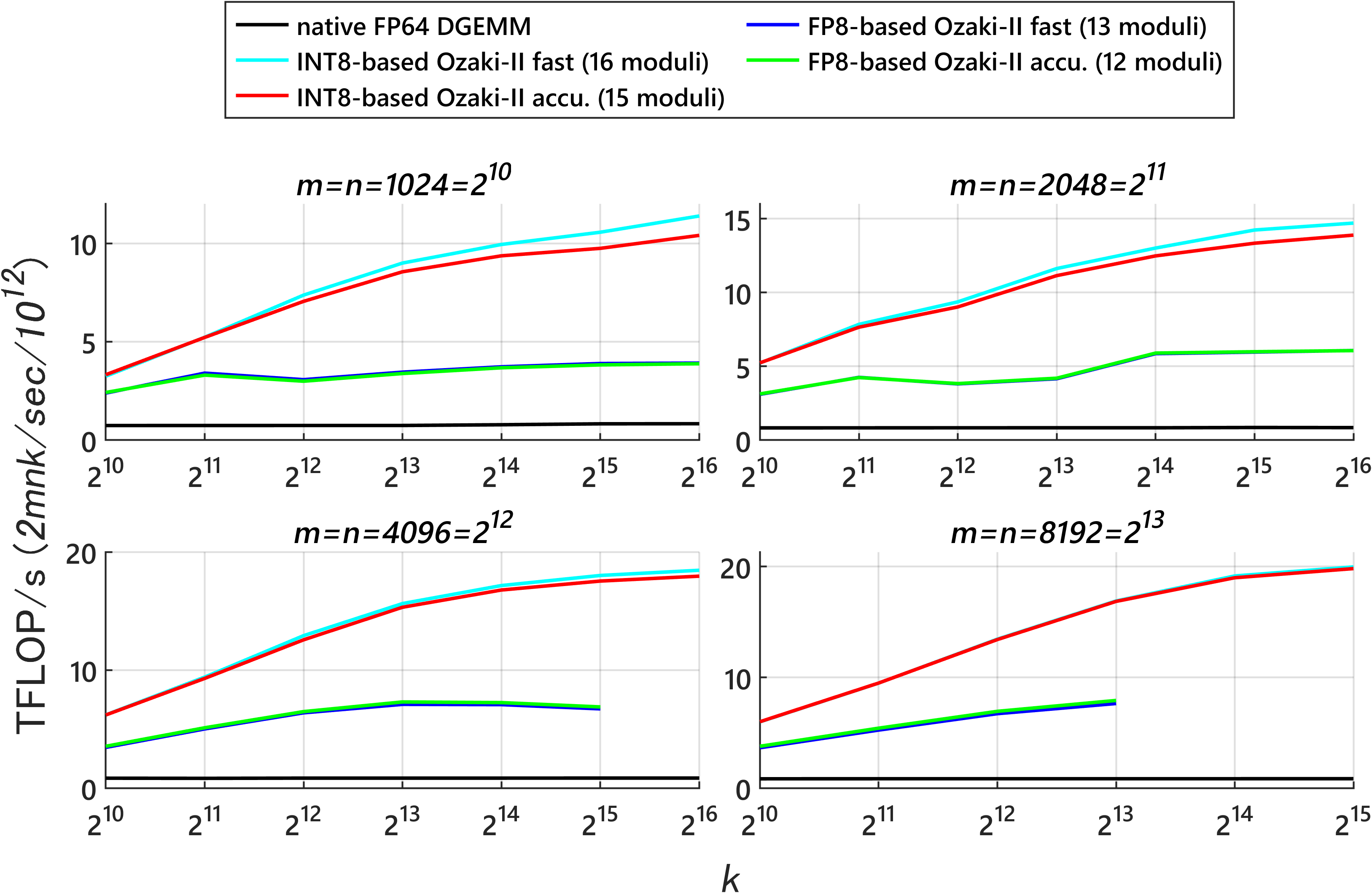
- Compared to INT8 Ozaki‑II: Their FP8 method needs about 2.5× more low-precision multiplications than INT8 Ozaki‑II. But on new GPUs where FP8 hardware is much faster and INT8 is de‑emphasized, the FP8 version can still be faster overall.
- Predicted speed on new GPUs: Their performance models suggest that on FP8‑heavy GPUs (like NVIDIA Rubin), this FP8 Ozaki‑II can beat a 200‑TFLOP/s FP64‑emulation target and run very fast.
- Accuracy: With about 12–14 carefully chosen moduli, the method matches or exceeds the precision needed to mimic FP64 in many cases.
- Memory trade‑off: The FP8 method uses more temporary memory than the INT8 version (because each piece is stored in multiple FP8 chunks and some buffers use larger types). You can reduce this by breaking the problem into tiles (especially along the “rows” and “columns,” not the inner dimension) to save memory with little speed loss.
- Ready to use: They provide an open-source library for NVIDIA and AMD GPUs to reproduce results and run the method in practice.
Why does this matter?
- Faster science on AI‑era chips: Many future chips will be optimized for FP8, not FP64. This method lets scientific codes get FP64‑like answers while running at FP8‑like speeds.
- Broad applicability: Matrix multiplication sits at the heart of countless tasks—simulations, physics, chemistry, finance, and more—so speeding it up benefits many fields.
- Practical and portable: The method works across different GPUs and comes with a library, making it easier to adopt.
- Looking ahead: As hardware evolves (for example, if FP4 gets extremely fast), similar ideas could be adapted again. For now, FP8 is the right balance of speed and exactness for this approach.
In short, the paper delivers a practical recipe to “have your cake and eat it too”: get the accuracy scientists trust, but at the speeds today’s AI‑first chips are built to deliver.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, and suggests concrete directions for future research.
- Missing empirical comparison against FP8-based Ozaki-I: no optimized, reproducible FP8 Ozaki-I implementation was available, preventing a direct runtime, accuracy, and energy comparison; building and benchmarking such an implementation is needed.
- Limited hardware validation: results are shown on RTX 5080 and B200; there is no validation on FP8-prioritized architectures (e.g., Blackwell Ultra B300, Rubin) or AMD/ROCm platforms despite claiming portability; cross-vendor accuracy/performance studies are needed.
- FP8 format variants: the method targets FP8_E4M3 with FP32 accumulation; adaptation to FP8_E5M2 and mixed FP8 pairs, and the impact on exactness and the k-bound, are not analyzed.
- k-dimension limit: correctness relies on error-free FP32 accumulation for k ≤ 216; strategies to handle larger k (e.g., tiled pairwise accumulation, compensated summation, hierarchical reductions) without large throughput loss remain open.
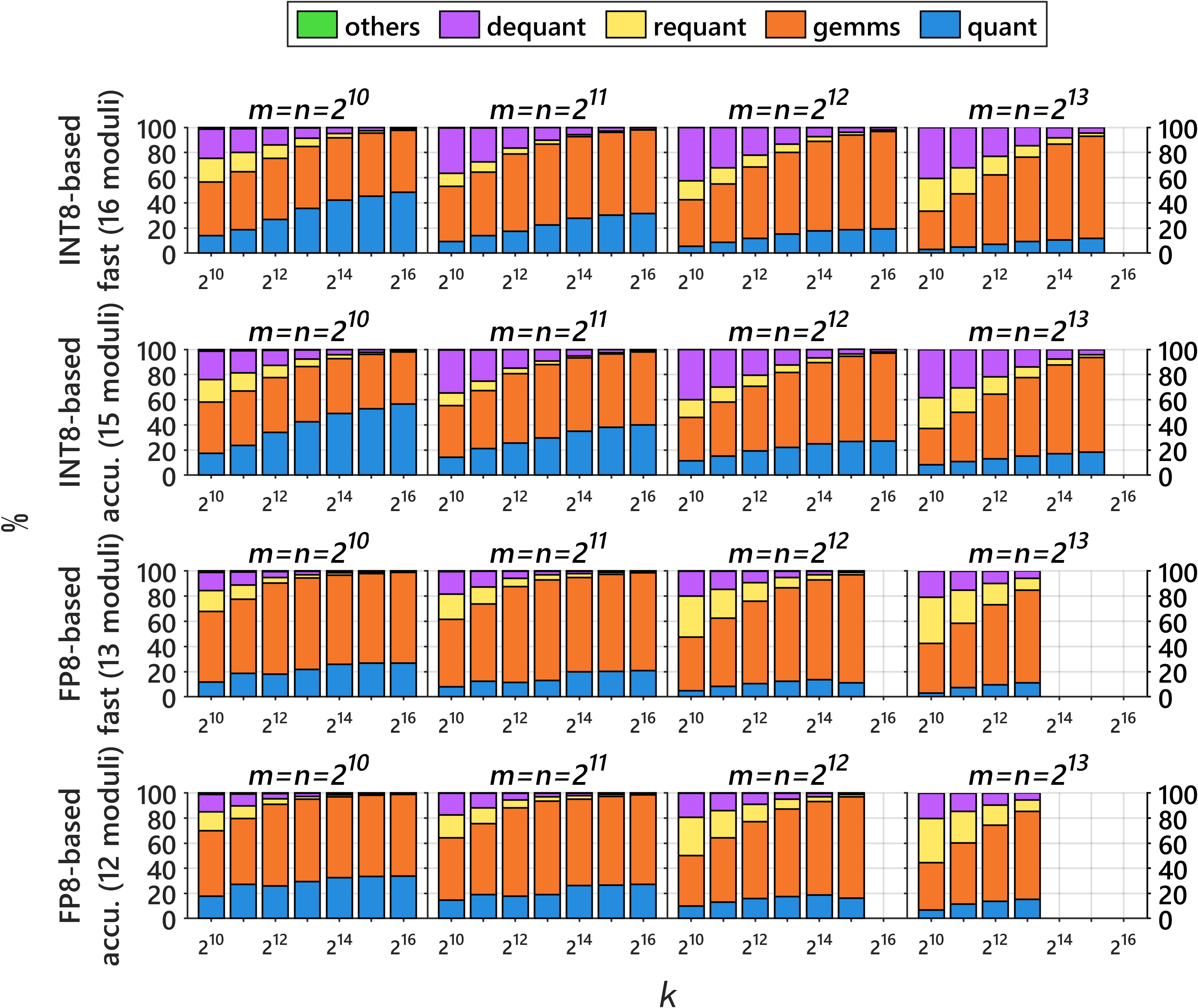
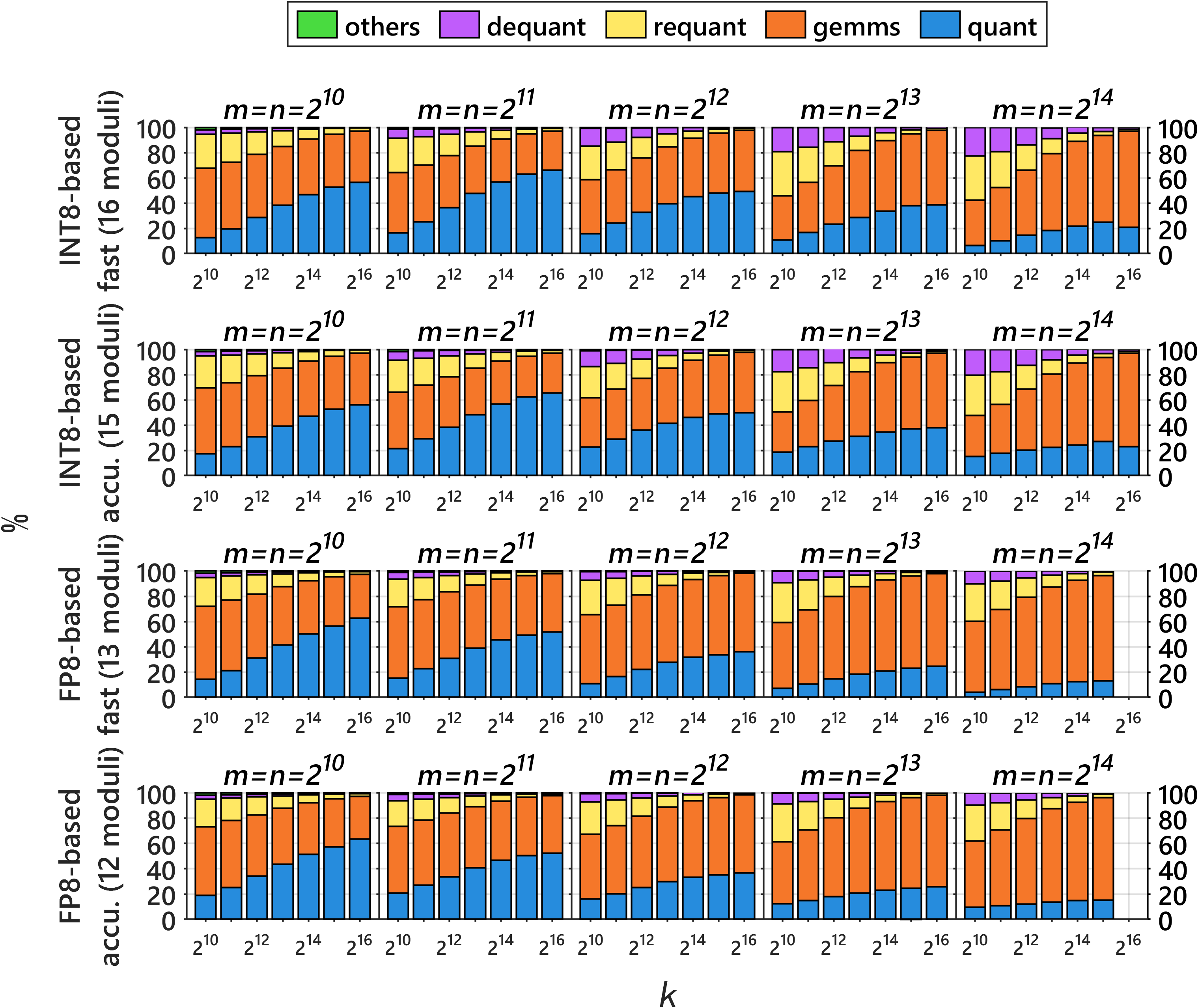
- Large workspace footprint: for 163843, FP8-based Ozaki-II requires ~55 GB workspace; investigate streaming CRT reconstruction, on-the-fly modulo/reduction to avoid storing all residues, residue compression/packing, fused kernels that reduce intermediate buffers, and rigorous performance–memory trade-offs.
- CRT and modular arithmetic overhead on weak-FP64 GPUs: FP64-heavy reconstruction may dominate on devices like B300; explore integer-based or mixed-precision CRT (e.g., Garner/Montgomery in 32/64-bit integers), GPU-parallel CRT kernels, and CPU–GPU co-design to reduce this bottleneck.
- Moduli selection optimality: the greedy selection (including six squares ≤1089) is heuristic; formulate and solve an optimization to choose moduli (and square/non-square mix) that maximize log2(P) per FP8 matmul and minimize N and workspace under FP8 representability constraints.
- Beyond squares with s2 ≡ 0 (mod p): the modular-reduction trick is limited to square moduli up to 332; investigate other modulus classes (e.g., p with chosen s where s2 ≡ 0 mod p but s remains FP8-friendly) to expand the effective modulus set and reduce N further.
- End-to-end error bounds: provide formal worst-case and probabilistic error analyses (in ULPs) that include all sources—truncation in A′, B′, scaling, FP8 casting (round-up), Karatsuba/hybrid reconstruction, and CRT rounding—beyond the effective-bit estimates.
- Assumptions about FP8 matmul exactness: verify and document across toolchains that FP8 MMAs truly accumulate in FP32 with IEEE semantics (no hidden rescaling or post-ops that break the error-free guarantee), including ROCm and future vendor libraries.
- Improved fast-mode bounds: Cauchy–Schwarz is conservative; develop tighter yet cheap bounds (e.g., blockwise norms, sampled maxima, hybrid norm/sampling estimators) to increase fast-mode accuracy without the extra FP8 pre-matmul.
- Scheduling and overlap: design pipelines that overlap per-modulus FP8 matmuls with CRT and scaling, fuse kernels to reduce global memory traffic, and exploit parallelism across moduli; quantify the gains and refine the performance model accordingly.
- GEMM epilogue support: integrate alpha/beta epilogues (C := αAB + βC) into the emulation without adding passes or violating exactness assumptions; analyze the impact on scaling bounds and workspace.
- Shape and batch sensitivity: thoroughly characterize performance and accuracy for tall–skinny/wide matrices and batched small GEMMs; derive thresholds and specialized kernels where the current approach underperforms.
- Complex arithmetic: extend the FP8-based Ozaki-II scheme to complex GEMM (as done for INT8), and compare workspace, performance, and accuracy.
- Multi-GPU/distributed scaling: extend to multi-GPU and distributed settings; study residue partitioning, communication-avoiding CRT, overlap of communication with compute, and strong/weak scaling.
- Portability and reproducibility guarantees: beyond “fixed toolchain,” establish bitwise reproducibility across vendors, driver/library versions, and compilers; specify required rounding-mode controls and fallback paths when controls are unavailable.
- Dynamic-range adaptivity: systematically study accuracy vs input dynamic range and implement runtime selection of N (and modulus sets) based on measured bounds to minimize work while meeting a target error.
- Energy efficiency: quantify power/performance vs native FP64 DGEMM and INT8-based Ozaki-II, especially on FP8-dominant GPUs; report energy–delay product improvements or regressions.
- Theoretical limits: derive lower bounds on the number of FP8 matmuls necessary to emulate t-bit precision under FP32 accumulation; assess how close the hybrid Ozaki-II method is to optimal vs Ozaki-I variants.
- FP4 pathway: prototype and analyze the FP4-based construction (e.g., realizing each FP8 matmul by three FP4 matmuls), determine break-even points given hardware ratios, and address representational challenges for intermediate sums in FP4.
- Padding overheads: performance modeling assumes padding to multiples of 256; develop kernels that maintain high throughput with arbitrary sizes/strides or quantify the real-world overhead of padding for typical HPC workloads.
- Parameter tuning for s and decomposition: investigate alternative s choices, multi-s decompositions, or adaptive s per modulus/tile to either widen admissible moduli (p > 1089) or reduce |A′(x)|, |B′(y)| further for robustness.
- Performance-model calibration: fit the correction parameter c and bandwidth/throughput terms across sizes and platforms; incorporate cache/tile reuse, launch overheads, and read/write amplification; release a calibration methodology and open datasets.
- Comparison with alternative FP64 emulations: benchmark against other mixed-precision FP64 approaches (e.g., double-double, quad, Kulisch-style accumulators, production Ozaki-I INT8/FP8 once available) on identical hardware with matched epilogues and problem shapes.
- Exceptional values: specify and validate behavior for NaN/Inf in inputs through scaling, modulo, and CRT steps; provide correctness guarantees and recommended handling.
Practical Applications
Overview
The paper introduces a practical, FP8-based Ozaki-II scheme to emulate FP64 general matrix–matrix multiplication (DGEMM) using FP8 Tensor Cores while preserving FP64-level accuracy. It combines a Karatsuba-based decomposition with a modular-reduction trick to reduce the number of FP8 matrix multiplications relative to FP8-based Ozaki-I, and provides an open-source, portable GPU library (NVIDIA/AMD). It also offers performance models and a workspace analysis to guide deployment.
Below are actionable, real-world applications derived from these findings, methods, and tools.
Immediate Applications
These are deployable now with the provided methods and open-source implementation, assuming FP8-capable GPUs and sufficient memory.
- High-throughput FP64 DGEMM on AI-optimized GPUs
- Sectors: HPC, energy, cloud computing, software
- Use case: Replace native FP64 DGEMM in dense linear algebra pipelines with FP8-Ozaki-II emulation to recover FP64-like accuracy on GPUs with weak FP64 throughput (e.g., NVIDIA Blackwell Ultra B300, Rubin).
- Tools/workflow: Use the open-source GEMMul8 library as a DGEMM backend; link via BLAS/LAPACK wrappers or interceptors; select fast vs accurate mode per accuracy/time budget; apply m,n blocking to fit workspace constraints.
- Assumptions/dependencies: FP8 MMA with FP32 accumulation; k ≤ 216 for error-free accumulation; tens of GB workspace (block if needed); deterministic results require fixed toolchain; N ≥ 12 moduli for FP64-equivalent precision.
- Accelerating DGEMM-dominated factorizations and solvers
- Sectors: scientific computing, engineering (CAE), geoscience, CFD, quantum chemistry, materials science
- Use case: Speed up panel-update phases in blocked LU/QR/Cholesky that are DGEMM-bound, while keeping panel factorizations in true FP64; use accurate mode to maintain stability.
- Tools/workflow: Integrate GEMMul8 as the GEMM kernel in MAGMA, SLATE, PLASMA, cuSOLVER/rocSOLVER-based workflows; retain FP64 where stability-critical.
- Assumptions/dependencies: Standard blocked algorithms; numerical stability analysis for each code path; extra workspace; tuned N and blocking per problem/hardware.
- Cost-effective FP64-class workloads on cloud AI instances
- Sectors: cloud platforms, finance, pharma, energy, research labs
- Use case: Run FP64-heavy analytics (risk, Monte Carlo, portfolio optimization), quantum chemistry, or simulation workloads on AI-optimized instances using FP8 emulation instead of FP64-rich instances.
- Tools/workflow: Prebuilt AMIs/containers with GEMMul8; job launchers that choose INT8- vs FP8-based emulation based on instance capabilities; use provided performance models for instance selection and cost/performance planning.
- Assumptions/dependencies: Availability of FP8 Tensor Cores; accurate model calibration to sustained throughput/bandwidth; sufficient GPU memory.
- Mixed-precision iterative refinement (IR) with FP64-correctness
- Sectors: software libraries (PETSc, Trilinos), simulation codes, optimization
- Use case: Use FP8 Ozaki-II DGEMM for the bulk of linear algebra in IR loops while computing residuals/corrections in FP64; meet tight residual tolerances at higher throughput.
- Tools/workflow: Patch GEMM hot spots in IR implementations; choose accurate mode for residual-sensitive steps; auto-tune N (moduli) from performance/accuracy targets.
- Assumptions/dependencies: IR convergence properties of the target problem; careful separation of sensitive kernels; adequate workspace.
- Hardware-aware path selection between INT8- and FP8-based emulation
- Sectors: HPC centers, system software, performance engineering
- Use case: On platforms with limited INT8 throughput (e.g., Blackwell Ultra, Rubin), prefer FP8-based Ozaki-II; otherwise select INT8-based Ozaki-II. Use the paper’s performance models to decide break-even points.
- Tools/workflow: Integrate model-based heuristics into runtime dispatch; expose user flags for “fast/accurate” and N; capture sustained GEMM/bandwidth once per node for calibration.
- Assumptions/dependencies: Accurate sustained performance measurements; problem shapes with large k; model parameter c tuned per system.
- Reproducible testing and CI for scientific codes
- Sectors: software engineering for HPC, academia
- Use case: Bitwise reproducible DGEMM (under fixed toolchain) for regression tests across heterogeneous GPU fleets.
- Tools/workflow: Pin compiler/driver/container; use accurate mode; incorporate deterministic seeds and padding guidelines.
- Assumptions/dependencies: Fixed toolchain; consistent BLAS kernels; padding to multiples of 256.
- Teaching and prototyping in mixed-precision/HPC courses
- Sectors: academia, training
- Use case: Demonstrate CRT-based emulation, Karatsuba, and performance modeling; student labs on gaming-class GPUs with FP8 Tensor Cores.
- Tools/workflow: Classroom-ready notebooks/containers using GEMMul8; side-by-side comparisons vs native FP64 and INT8-based Ozaki-II.
- Assumptions/dependencies: Availability of FP8-capable GPUs in labs or cloud credits; simplified build scripts.
Long-Term Applications
These require further research, engineering, or ecosystem changes (standardization, hardware support, wider software integration).
- Full emulated-FP64 dense linear algebra stacks
- Sectors: software, HPC
- Use case: Extend FP8 Ozaki-II to GEMM-based BLAS-3 (SYRK, HERK, TRMM), and to LAPACK routines (SVD, eigen, least squares) where GEMM dominates; offer an “emulated-FP64” backend in MAGMA, SLATE, oneMKL, and rocSOLVER.
- Tools/workflow: Systematic replacement of GEMM kernels; stability audits; mode switching (fast/accurate) by routine sensitivity.
- Assumptions/dependencies: Error propagation analysis for each routine; additional workspace management; broad testing suites.
- Sparse and block-sparse extensions
- Sectors: CFD, structural mechanics, graph analytics, GNNs
- Use case: Use emulated FP64 DGEMM for dense sub-blocks (block-sparse SpMM/SpGEMM, ILU/AMG smoothers) where accuracy is critical.
- Tools/workflow: Mixed sparse–dense kernels; auto-tune block sizes for arithmetic intensity vs memory constraints; k-tiling to respect error-free accumulation if needed.
- Assumptions/dependencies: Data layout and blocking to amortize workspace; careful handling of irregular sparsity; throughput of small/batched GEMMs.
- Domain adoption in flagship simulation codes
- Sectors: weather/climate (NWP), seismic imaging, quantum chemistry (DFT, CC), LQCD, plasma physics, digital twins
- Use case: Port large production codes to AI-focused accelerators while retaining FP64 scientific fidelity by swapping DGEMM backends and refactoring GEMM-heavy loops.
- Tools/workflow: Validation campaigns against baseline FP64; accuracy/performance knobs (N, fast vs accurate); workflow orchestration in HPC centers.
- Assumptions/dependencies: Community acceptance; regression suites; regulatory/scientific verification standards.
- Automatic precision and kernel selection at runtime
- Sectors: performance portability, autotuning tools
- Use case: Autotuners select among FP8-Ozaki-II, INT8-Ozaki-II, FP8-Ozaki-I, or native FP64 based on hardware telemetry, problem size/shape, and accuracy constraints.
- Tools/workflow: Integrate the paper’s performance/accuracy models; learn calibration once per node; expose SLA-style accuracy budgets.
- Assumptions/dependencies: Robust model fitting; lightweight profiling; API for user tolerances.
- Standardization of “emulated precisions” in math libraries and compilers
- Sectors: standards bodies, compiler vendors, library maintainers
- Use case: Define a standardized “emulated FP64” type/flag in BLAS/oneAPI/ROCm APIs and compilers so that applications can request FP64 accuracy independent of hardware FP64 strength.
- Tools/workflow: Reference implementations; conformance tests; ABI/API design for mode selection and reproducibility.
- Assumptions/dependencies: Community consensus; long-tail maintenance; IP concerns.
- Hardware–software co-design and future FP4 paths
- Sectors: semiconductor, hardware architecture, policy
- Use case: Influence future Tensor Core designs toward FP8-friendly exact accumulation (larger k without loss) and native support for modular arithmetic; explore multi-level Karatsuba using FP4 if FP4 throughput vastly exceeds 3× FP8.
- Tools/workflow: Co-design studies using this method as a benchmark; metrics for energy/time-to-solution and memory footprint.
- Assumptions/dependencies: Vendor roadmaps; exposure of rounding modes; FP4 maturity.
- Energy- and cost-aware procurement and operations
- Sectors: national labs, supercomputing centers, cloud economics
- Use case: Adopt AI-optimized GPUs plus emulation software to meet FP64 workloads’ needs at lower TCO and power; set policy for reproducibility and verification when emulation is used.
- Tools/workflow: Use the performance and workspace models to size clusters; run acceptance tests comparing emulated vs native FP64; publish energy/performance baselines.
- Assumptions/dependencies: Accurate sustained throughput/bandwidth measurements; organizational risk tolerance; audit trails.
- Democratized access to high-precision computing
- Sectors: education, citizen science, startups
- Use case: Enable FP64-class experiments on gaming-class GPUs with FP8 Tensor Cores; reduce costs for coursework and small labs.
- Tools/workflow: Easy installers/containers; documentation and tutorials; limited-memory presets (blocking strategies).
- Assumptions/dependencies: Memory footprint management; simplified UX; availability of FP8-capable devices.
Cross-cutting assumptions and dependencies
- Hardware/software
- FP8_E4M3 MMA with FP32 accumulation; stable and deterministic BLAS kernels; support for rounding-up/down modes in conversions; sufficient GPU memory bandwidth.
- Large k preferred (k ≤ 216 ensures error-free accumulation); small k reduces efficiency.
- Significant workspace (often tens of GB) unless blocked; padding to multiples of 256 may be required for performance/robustness.
- Algorithmic parameters
- Choice of N (number of CRT moduli) trades accuracy and performance; N ≥ 12 typically targets FP64-like accuracy in the proposed FP8 Ozaki-II method.
- Fast vs accurate mode: accurate uses one extra matmul and tighter scaling; fast reduces time at some accuracy cost.
- Performance break-even
- FP8-based emulation outperforms INT8-based Ozaki-II when FP8 GEMM sustained throughput sufficiently exceeds INT8 (platform-dependent; use provided models to decide).
- Memory bandwidth can dominate; tune blocking and data movement carefully.
Glossary
- Accurate mode: A configuration that computes tighter bounds or results by performing additional precise steps, often using low-precision GEMM to set scaling. Example: "In accurate mode, the upper bound is estimated using a direct low-precision matrix multiplication (INT8 or FP8), enabling the scaling vectors to be chosen such that the estimated bound is closer to ."
- Arithmetic intensity: The ratio of computation to memory access; low intensity can make kernels memory-bound. Example: "reducing arithmetic intensity and making the kernel memory-bound."
- Basic Linear Algebra Subprograms (BLAS): A standardized library interface for high-performance linear algebra routines such as GEMM. Example: "using the BLAS (Basic Linear Algebra Subprograms) implementation"
- BF16: Brain Floating Point 16-bit format (8-bit exponent, 7-bit fraction); a low-precision floating-point format used in ML/HPC. Example: "BF16 (TFLOP/s)"
- Bitwise reproducible: Producing identical binary outputs across runs under fixed toolchains. Example: "It produces bitwise reproducible results under a fixed toolchain."
- Blackwell Ultra: An NVIDIA GPU architecture variant prioritizing low-precision throughput. Example: "such as NVIDIA Blackwell Ultra and NVIDIA Rubin"
- Cauchy–Schwarz inequality: A mathematical inequality used here to bound dot products when estimating scaling in fast mode. Example: "In fast mode, the upper bound of is obtained based on the Cauchy--Schwarz inequality"
- Chinese Remainder Theorem (CRT): A number-theoretic method to reconstruct integers from residues modulo coprime moduli; used to combine modular matrix products. Example: "via the Chinese Remainder Theorem (CRT)."
- cuBLAS: NVIDIA’s GPU-accelerated BLAS library for dense linear algebra. Example: "Native FP64 DGEMM was computed using cublasDgemm implemented in cuBLAS."
- cuBLASLt: NVIDIA’s lightweight, flexible BLAS library optimized for modern Tensor Core operations (e.g., INT8/FP8 GEMM). Example: "The underlying INT8/FP8 matrix multiplications inside the emulation were executed using cuBLASLt."
- DGEMM: Double-precision general matrix–matrix multiplication; the FP64 GEMM routine. Example: "double-precision (FP64) general matrix--matrix multiplication (DGEMM)"
- Fast mode: A configuration that reduces work (e.g., fewer GEMMs) by using looser bounds or approximations, trading some accuracy for speed. Example: "In fast mode, the upper bound of is obtained based on the Cauchy--Schwarz inequality"
- Fixed-point: A numeric representation without explicit exponent; here used for decomposed matrices to align with integer MMAs. Example: "represented in a fixed-point form that does not involve exponent components"
- FP4: 4-bit floating-point format; extremely low precision, with variants like E2M1. Example: "Some hardware expose support for FP4 matrix multiplication with FP4_E2M1 inputs and FP32 accumulation."
- FP6: 6-bit floating-point format; an emerging ultra-low-precision format. Example: "FP6 (TFLOP/s)"
- FP8: 8-bit floating-point format; emphasized in modern accelerators for high throughput. Example: "The use of FP8 arithmetic is thus increasingly important."
- FP8_E4M3: An FP8 format with 4 exponent bits and 3 mantissa bits. Example: "The FP8_E4M3 format can exactly represent consecutive integers in the range of to $16$."
- FP32 accumulation: Accumulating products into 32-bit floating-point to control rounding; here, often enforced to be error-free. Example: "we require that no rounding error occurs in FP32 accumulation"
- FP64: 64-bit floating-point precision; essential for high-accuracy HPC workloads. Example: "FP64 arithmetic remains indispensable for ensuring numerical accuracy and stability."
- GEMM: General matrix–matrix multiplication; a fundamental dense linear algebra kernel. Example: "real-valued general matrix--matrix multiplication (GEMM) emulation."
- Karatsuba method: A divide-and-conquer algorithm to reduce the number of multiplications; adapted here for matrix products under precision constraints. Example: "we adopt the Karatsuba method."
- Matrix multiply-accumulate (MMA): Specialized hardware units that perform fused matrix multiplications and accumulations (e.g., Tensor Cores). Example: "low-precision matrix multiply-accumulate (MMA) units"
- Memory-bound: A regime where performance is limited by memory bandwidth rather than compute throughput. Example: "reducing arithmetic intensity and making the kernel memory-bound."
- Modular reduction: Reducing values modulo a number to keep intermediate results bounded; key in CRT-based reconstruction. Example: "a modular reduction formulation that avoids Karatsuba reconstruction"
- Moduli: The set of pairwise coprime integers used as mod bases in CRT. Example: "the moduli are selected in descending order from the following set"
- NVIDIA Rubin: An NVIDIA GPU architecture emphasizing FP8 throughput relative to INT8. Example: "such as NVIDIA Blackwell Ultra and NVIDIA Rubin"
- Ozaki-I scheme: A decomposition-based DGEMM emulation framework using low-precision slices, combinable with INT8/FP8/FP16 MMAs. Example: "The Ozaki-I and Ozaki-II schemes are well established as foundational approaches for emulating DGEMM via low-precision arithmetic."
- Ozaki-II scheme: A CRT-based DGEMM emulation framework mapping FP64 products to modular integer products. Example: "In contrast, although implementations of DGEMM emulation via the Ozaki-II scheme using INT8 MMA units have been reported"
- Pairwise coprime: A property where every pair of integers shares no common factors; required by CRT. Example: "let be pairwise coprime integers."
- Peak dense throughput: The maximum theoretical matrix-multiplication rate of hardware in dense mode. Example: "the peak dense throughput of recent NVIDIA GPUs"
- Performance model: An analytic estimate of runtime/throughput accounting for compute, bandwidth, and overheads. Example: "analytic performance models (including a new model for INT8-based Ozaki-II)"
- Residue: The remainder of integers or matrices modulo a modulus; used to store modular components. Example: "stores INT8 residue matrices"
- Round-down mode: Rounding toward negative infinity; used to conservatively bound computations. Example: "computed using FP32 arithmetic in round-down mode."
- Round-up mode: Rounding toward positive infinity; used to safely over-approximate bounds. Example: "in round-up mode."
- Scaling vectors: Per-row/column powers-of-two factors used to map floats to bounded integers before modular arithmetic. Example: "These scaling vectors are determined to satisfy"
- Symmetric modulo operation: A modulo mapping to a symmetric range around zero rather than [0, p). Example: "denotes the symmetric modulo operation"
- Tensor Cores: NVIDIA’s MMA units specialized for low-precision matrix ops with high throughput. Example: "the Tensor Core dense specification is 17.5 PFLOP/s for FP8 versus 4.0 PFLOP/s for FP16/BF16"
- TF32: TensorFloat-32; a reduced-precision FP32 format optimized for Tensor Cores. Example: "TF32 (TFLOP/s)"
- TFLOP/s: Tera floating-point operations per second; a throughput metric for floating-point compute. Example: "FP8 (TFLOP/s)"
- TOP/s: Tera operations per second; a throughput metric often used for integer compute. Example: "INT8 (TOP/s)"
- Toom–Cook: A family of fast multiplication algorithms generalizing Karatsuba. Example: "Recursive Karatsuba and Toom--Cook require products of sums of low-precision matrices"
- Unit in the first place (ufp): The largest power of two not exceeding the magnitude of a value; used in scaling analysis. Example: "where is the unit in the first place"
- Unit roundoff: The maximum relative rounding error in floating-point arithmetic for a given format. Example: "where is the computed result and is the unit roundoff"
- Working memory footprint: The total temporary memory required by an algorithm beyond inputs/outputs. Example: "working memory footprint to refer to the total size of this workspace."
Collections
Sign up for free to add this paper to one or more collections.