- The paper introduces a novel QUAD framework that enables a single compiled quantized model to support multiple LoRA adapters through runtime injection.
- It demonstrates up to 6× reduction in memory footprint and 4× faster inference latency while preserving image quality.
- The approach refines quantization with adaptive distillation to harmonize disparate LoRA weight distributions for dynamic, efficient edge deployments.
Quantization with Unified Adaptive Distillation: Multi-LoRA One-for-All Generative Vision Models on Edge
Introduction and Problem Statement
This work addresses the deployment of multi-task generative vision models (LVMs) on edge devices, focusing on practical techniques to enable efficient, memory- and compute-constrained inference. The growth of GenAI-based features such as image inpainting and prompt-guided stylization on consumer hardware motivates research into model adaptation methods compatible with resource-limited platforms. While LoRA-based parameter-efficient fine-tuning is standard for task specialization, current edge deployment pipelines compile a separate binary for each LoRA, duplicating the foundation model and inflating both storage and runtime costs.
The primary technical barrier—quantization incompatibility across individually trained LoRA adapters—precludes runtime adapter switching under a unified compiled model, as each adapter typically yields unique quantization scales and offsets (see Figure 1).
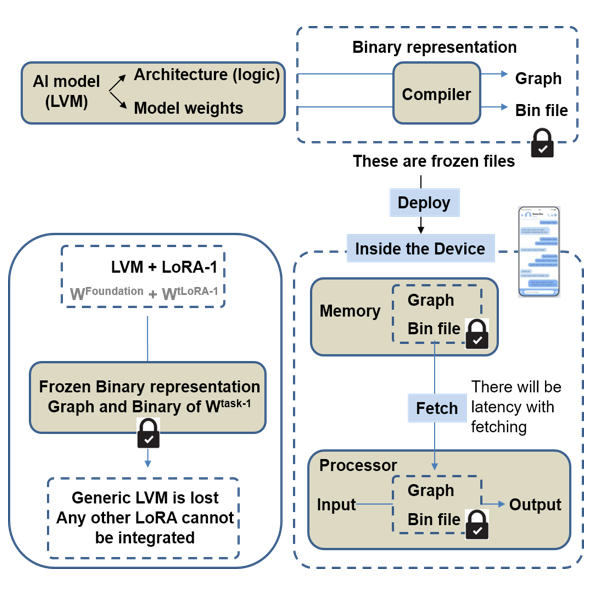
Figure 1: Schematic for a simplified version of compilation and deployment, illustrating per-LoRA binary duplication and quantization incompatibility.
The paper introduces a unified framework that enables a single compiled quantized LVM to serve multiple tasks dynamically by treating LoRA weights as runtime input tensors, rather than statically embedding them into the computation graph. This architectural shift (Figure 2) demands revising inference logic to expose LoRA weights as explicit model inputs, with graph modifications to accept A, B (the LoRA low-rank matrices) at runtime for all adapted linear layers.
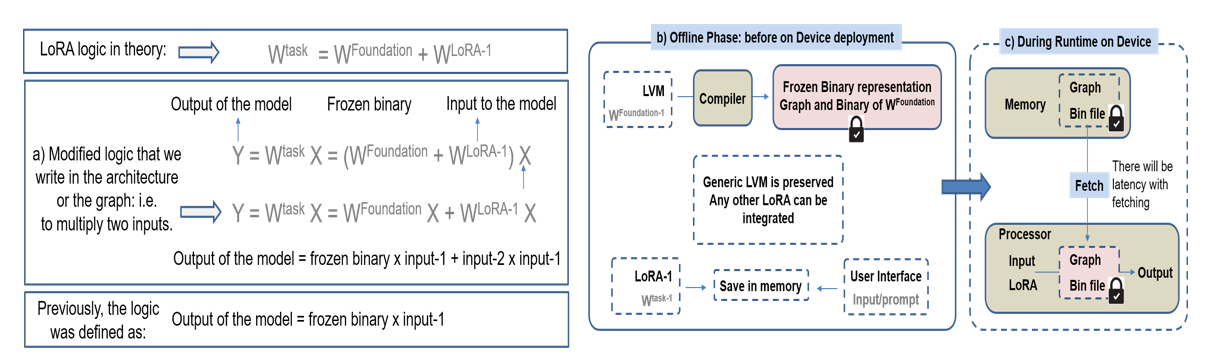
Figure 2: Unified deployment architecture—modification for LoRA as runtime input, single frozen graph construction, and on-device runtime logic.
The result is a single deployment artifact for multiple LoRAs, supporting dynamic task switching, over-the-air LoRA updates, and significant reductions in memory and storage footprint. However, the runtime injection of different LoRA adapters challenges quantization uniformity, as independently-trained LoRAs may possess disparate weight distributions, leading to distinct quantization encodings.
To solve this, the authors propose the QUAD (Quantization with Unified Adaptive Distillation) framework. The method consists of the following steps:
- Quantization sensitivity analysis selects the most sensitive LoRA adapter (highest divergence in quantized-vs-FP32 output) as the anchor for fixed quantization parameters.
- All LoRA adapters are then finetuned using knowledge distillation under this shared quantization configuration, enforcing compatibility at inference.
- If no LoRA shows higher sensitivity, a global quantization profile is established by merging weight distributions.
This process ensures all LoRAs and the base model share quantization parameters, rendering the runtime graph invariant to adapter choice and compatible with fixed-parameter hardware accelerators. The QUAD flowsheet is formalized in Figure 3.
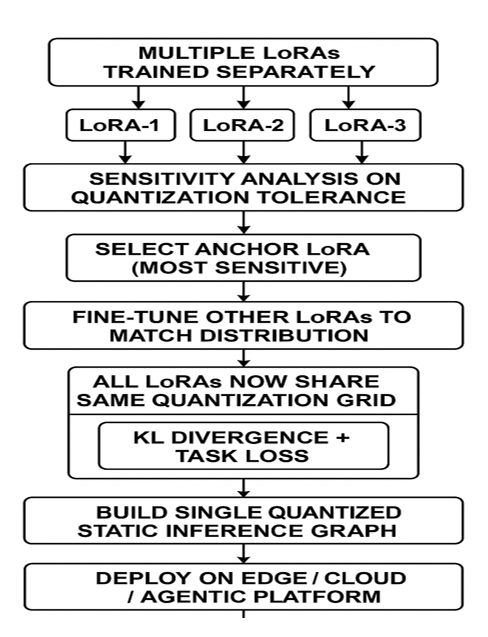
Figure 3: QUAD framework—adapter selection, quantization parameter sharing, and distillation for deployment.
System Architecture and Deployment
Deploying the unified quantized LVM+LoRA stack requires a specialized software infrastructure. Model export via ONNX and further vendor toolchains enables graph-level optimizations, including operator fusion, dead code elimination, parallelization, and static allocation of buffer placeholders for LoRA weights. The complete stack for on-device execution is depicted in Figure 4, constituting the compiled IR, lightweight runtime, LoRA loaders, and a task scheduler.
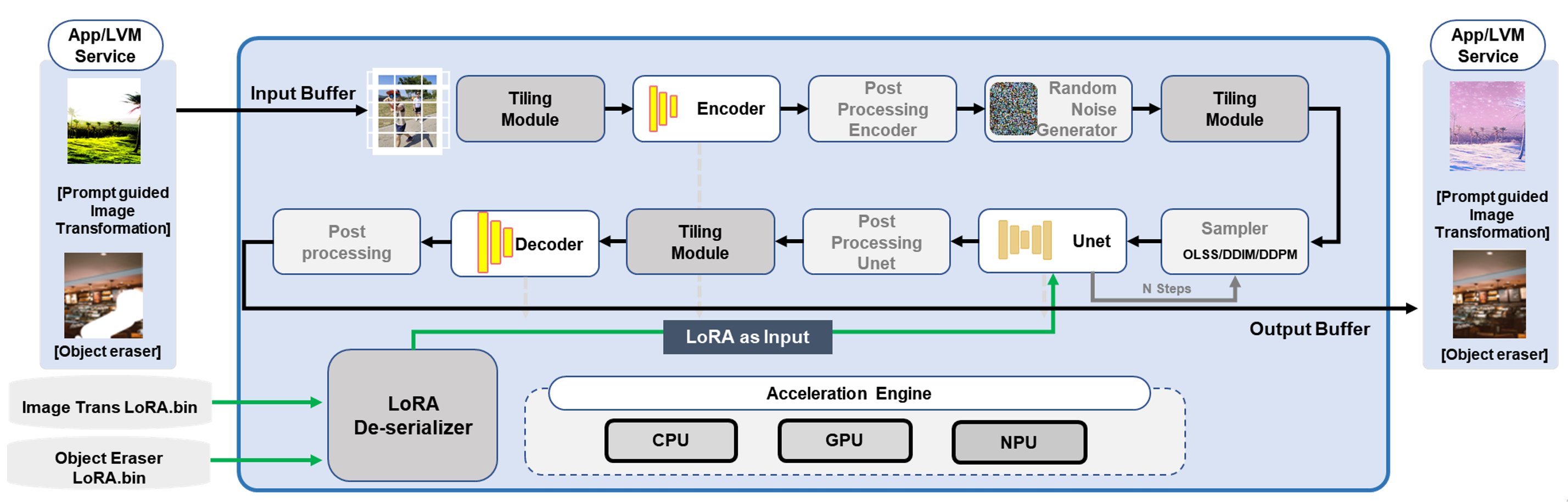
Figure 4: Software stack for "one-for-all" LVMs on mobile; a single foundation model with dynamic LoRA loading serves multiple use-cases.
This system is validated on multiple SoC platforms (Qualcomm, MediaTek, LSI), with dynamic task switching, LoRA caching, and compatibility with quantized operator sets, indicating generality across commercial hardware.
Experimental Results
The unified approach offers empirically validated improvements:
- Memory footprint is reduced by up to 6× compared to redundant per-LoRA binaries.
- End-to-end latency improves by up to 4× due to the elimination of runtime model reloading.
- Visual fidelity metrics (FID, LPIPS, SSIM, PSNR) are preserved, confirming the approach maintains generative quality post-INT8 quantization and distillation.
For prompt-guided image transformation, quantitative parity is observed between server-side FP32 and on-device INT8 execution (see Figure 5).

Figure 5: Prompt-guided image transformation—server FP32 vs. device INT8 output fidelity.
Object removal use-cases display negligible accuracy decrease post-quantization, as reflected across FID and SSIM metrics (Figure 6).

Figure 6: Object removal performance; on-device INT8 model preserves image quality.
Comprehensive profiling across multiple chipsets demonstrates consistent improvements in peak RAM, ROM requirements, and total inference time for both high- and medium-capacity LVM backbones.
Ablation Studies: Quantization Strategies
The paper further investigates the impact of mixed-precision quantization. Limiting quantization to W8A16 (weights INT8, activations INT16) optimally balances accuracy and memory reduction, whereas aggressive INT8 quantization (W8A8) for LoRA weights/activations increases memory savings but at measurable performance cost. Mixed-precision configurations provide knobbed trade-offs, allowing system designers fine-grained control over deployment accuracy vs. resource utilization.
Implications and Future Directions
This work advances practical deployment of modular, parameter-efficient generative vision models on edge hardware. By fully decoupling LoRA adapters from model binaries and resolving quantization compatibility at the deployment stage, this approach enables scalable, updatable, and memory-efficient on-device GenAI, significantly lowering total cost of ownership as the number of supported use-cases grows.
The approach generalizes to other foundation models and any scenario demanding runtime injection of trained adapters. Future developments may extend to real-time LoRA personalization, federated LoRA learning, or distributed edge-to-cloud multi-adapter orchestration. Research into more adaptive quantization/finetuning strategies could further expand the efficiency and fidelity achievable for on-device vision LLMs.
Conclusion
By reframing LoRA integration as a runtime operation and proposing the QUAD knowledge-distillation-anchored quantization strategy, this work enables robust, efficient, multi-task GenAI model deployment on resource-constrained edge devices. The unified stack circumvents the constraints of conventional per-task binaries, achieving substantial gains in adaptability, memory, and inference latency—all while sustaining competitive generative performance across diverse applications.