- The paper proposes StereoVGGT, a training-free stereo backbone that fuses VGGT, DINOv2, and MDE to integrate strong camera geometric priors with high spatial fidelity.
- It introduces entropy-minimized weight merging and a dual-branch feature neck to balance global camera awareness with fine pixel-level details.
- Empirical results on KITTI and Inria 3D Movie benchmarks demonstrate state-of-the-art performance in disparity estimation and stereo conversion tasks.
Introduction and Motivation
Stereo vision systems are foundational to 3D perception, with applications spanning autonomous vehicles, robotics, and multimedia content creation. The accuracy of stereo tasks such as stereo matching (disparity estimation) and stereo conversion is fundamentally constrained by the model’s capacity to encode camera geometric priors—most critically, camera intrinsic parameters like focal length. Existing stereo vision backbones typically rely on Monocular Depth Estimation (MDE) models or Visual Foundation Models (VFMs) pretrained on generic objectives, which lack explicit supervision on camera pose or intrinsics. This deficiency creates a bottleneck in downstream stereo tasks, where precise metric depth and geometric calibration are indispensable.
To address this limitation, the paper “StereoVGGT: A Training-Free Visual Geometry Transformer for Stereo Vision” (2603.29368) directly targets the lack of geometric priors in backbone feature extractors. It leverages the Visual Geometry Grounded Transformer (VGGT), which is unique among foundation models for its pretraining on 3D geometry with camera pose supervision. However, direct application of VGGT in stereo tasks reveals a suboptimal tradeoff: VGGT encodes strong camera priors at the expense of severe feature-level spatial degradation, thus impairing pixel-level alignment required for high-precision stereo correspondence.
The work proposes StereoVGGT—a novel, training-free stereo backbone—which algorithmically fuses the strengths of VGGT, DINOv2 (a VFM), and a SOTA MDE model through entropy-minimized weight merging (EMWM). This fusion achieves both geometric camera awareness and fine spatial fidelity, resolving the antagonistic properties that hinder vanilla VGGT.
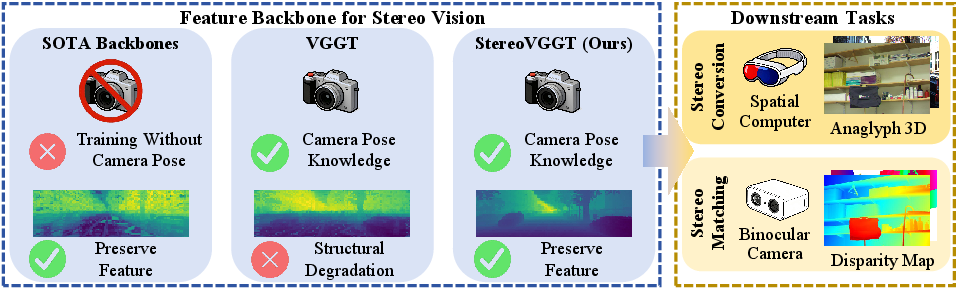
Figure 1: Camera focal length (an intrinsic parameter) is essential for accurate disparity estimation, but generic stereo backbones lack explicit geometry supervision, whereas VGGT encodes strong geometric priors but with structural degradation in the features. StereoVGGT overcomes this dichotomy.
Geometric Priors and Feature Degradation Analysis
The paper rigorously analyzes the camera parameter awareness of contemporary backbones. Using a Levenberg-Marquardt-based solver, it evaluates how accurately different model features allow for camera field-of-view (FOV) estimation from monocular images.
Empirical results show that DINOv2 and DAv2 (Depth Anything V2) have large FOV estimation errors, signaling their lack of geometric awareness. In contrast, VGGT features allow significantly more accurate camera FOV recovery—demonstrating that explicit pose pretraining imbues the encoder with relevant geometric priors.
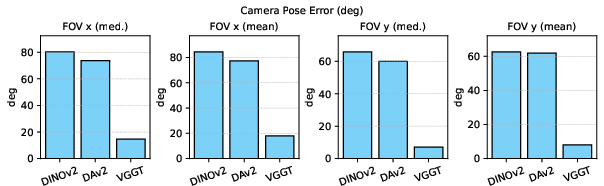
Figure 2: Median and mean FOV estimation errors across frameworks, confirming that only VGGT exhibits robust camera awareness on ETH3D.
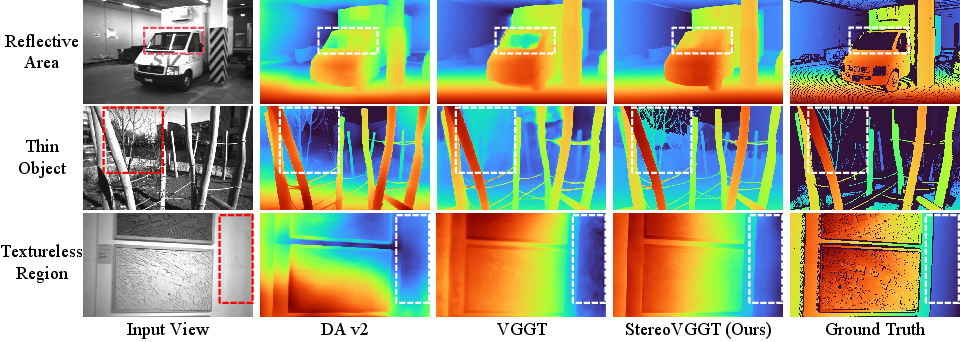
Despite this, VGGT’s internal representation suffers severe spatial-structural degradation, quantified by a lower SSIM (structural similarity) between feature maps and original input images compared to VFMs and MDE models. This loss is visually apparent—VGGT erases fine geometric contours crucial to stereo alignment, a direct result of its architecture and optimization for multi-view 3D reconstruction, where semantic abstraction is prioritized over local spatial consistency.
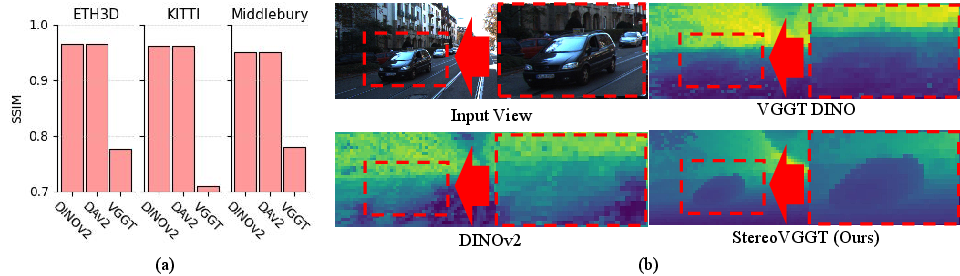
Figure 3: SSIM histogram and feature map visualizations highlight pronounced spatial blurring in VGGT compared to DINOv2 and MDE backbones.
StereoVGGT Architecture
To preserve both camera geometry knowledge and local structure, StereoVGGT introduces a novel, training-free model merging and feature manipulation pipeline:
- Entropy-Minimized Weight Merging (EMWM): The DINO subnetwork weight tensors from VGGT, DINOv2, and an MDE model are merged linearly, with merge coefficients per-layer dynamically optimized in a data-free fashion to minimize parameter entropy. This operation injects concrete geometric priors without requiring downstream supervision or finetuning.
- Dual-Branch Feature Neck: The re-weighted DINO patch tokens are processed in parallel by the frozen VGGT Frame Attention (FA) blocks (for geometric priors) and an MDE-derived neck (for fine spatial features). The FA features modulate the MDE pathway via feature-wise subtraction, balancing global geometry with local detail.
- Disparity Prior Head: A frozen DPT head predicts disparity priors, which, together with latent features, are fed to stereo matching or synthesis decoders.
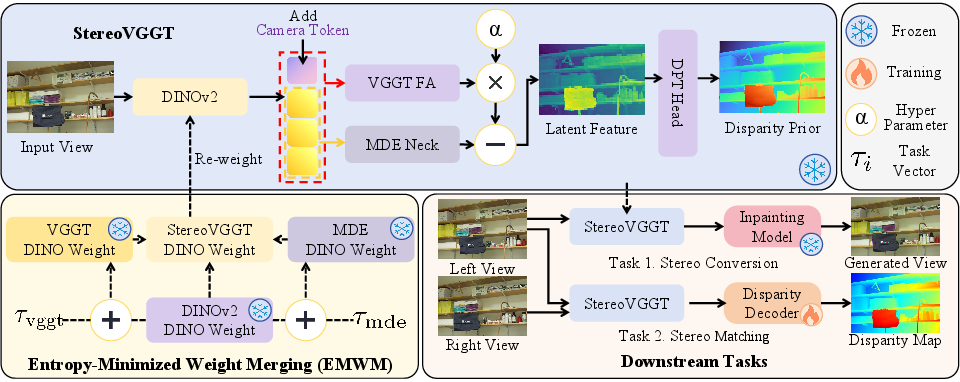
Figure 4: StereoVGGT architecture fuses weights (EMWM), produces parallel geometric and feature branches, and outputs robust representations for all stereo tasks.
This pipeline is data-free, aligning with the “training-free” paradigm: all model parameters are fixed after pretraining, and only the downstream decoder is trained, if at all.
Experimental Results
StereoVGGT is empirically validated on flagship stereo benchmarks, with a focus on non-occluded pixel accuracy and real-world multimodal datasets.
Stereo Matching (KITTI)
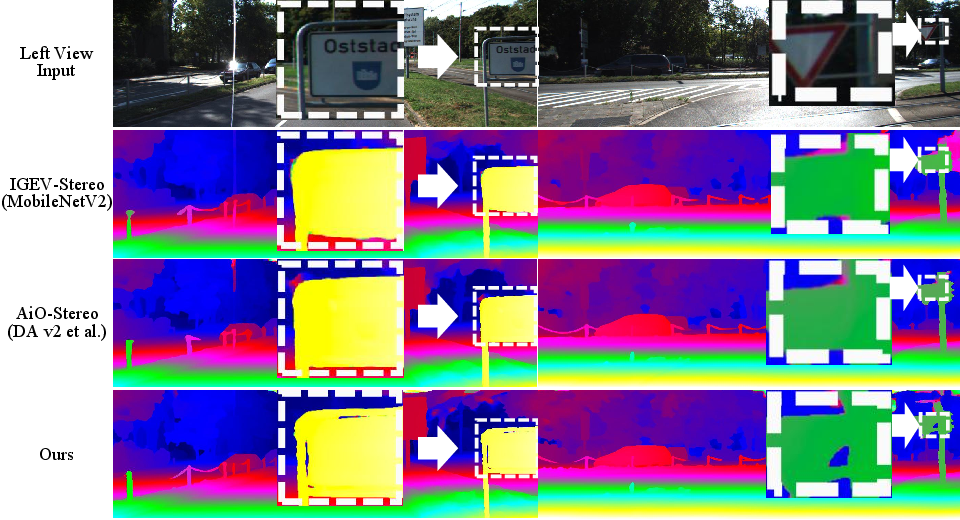
StereoVGGT, replacing the default backbone in IGEV-Stereo, achieves state-of-the-art performance and ranks first on the KITTI benchmark for non-occluded pixels—surpassing all published stereo backbones as of writing.
Noteworthy results:
Stereo Conversion (Inria 3D Movie, Mono2Stereo)
On the Inria 3D Movie dataset, StereoVGGT sets new SOTA across all standard metrics (RMSE, SSIM, SIoU, PSNR). Integrated into the Mono2Stereo pipeline, it demonstrates +90% win rate over 20 metrics, confirming robust generalization in both indoor and outdoor streams.

Figure 6: Anaglyph 3D results on the Inria dataset—StereoVGGT generates more accurate and spatially sound content than competing methods.
Monocular Disparity Estimation and Ablations
A monocular evaluation confirms that StereoVGGT, even without a downstream task-specific decoder, achieves the lowest EPE and best FOV recovery, indicating that geometric priors remain embedded and accessible.
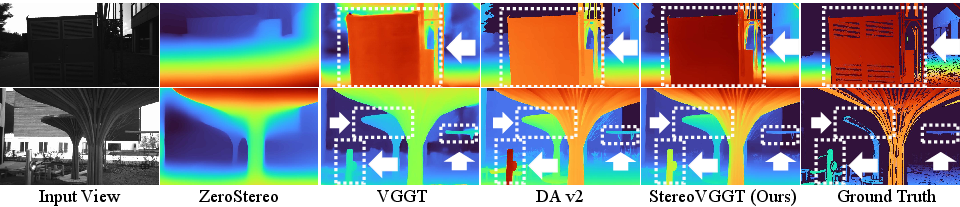
Figure 7: Monocular disparity estimation on ETH3D. StereoVGGT alone yields sharp contours and correct spatial ordering, unifying strengths of VGGT and MDE backbones.
Ablation studies validate:
StereoVGGT’s robust generalizability is further shown by backbone-swapping in BridgeDepth [bridgedepth], where it outperforms all other choices.
Computational Cost
Despite the large parameter count inherited from foundation models, inference latency is close to or better than SOTA MDEs, owing to efficient architecture design.
Implications and Future Directions
The StereoVGGT framework demonstrates that explicit camera geometry supervision—absent from generic VFMs and MDEs—directly translates to improved stereo accuracy, especially in metric-critical domains. The architecture’s training-free property eliminates the need for computationally expensive end-to-end finetuning and allows plug-and-play replacement within existing pipelines. The entropy-based, data-free model merging represents a theoretically principled and empirically robust alternative to naive weight ensembling.
Practically, the approach advances deployable stereo perception for robotics, AR/VR, and multimedia content creation, particularly where camera intrinsics vary or explicit calibration is infeasible. Theoretically, the findings stress the need for future foundational models to encode geometric priors at scale, and not just semantic or texture-based representations.
A limitation is model footprint—StereoVGGT’s size, inherited from both VGGT and MDEs, may be prohibitive for low-memory scenarios. The paper highlights model distillation and sparsification as next steps for bringing geometry-aware vision models to edge devices.
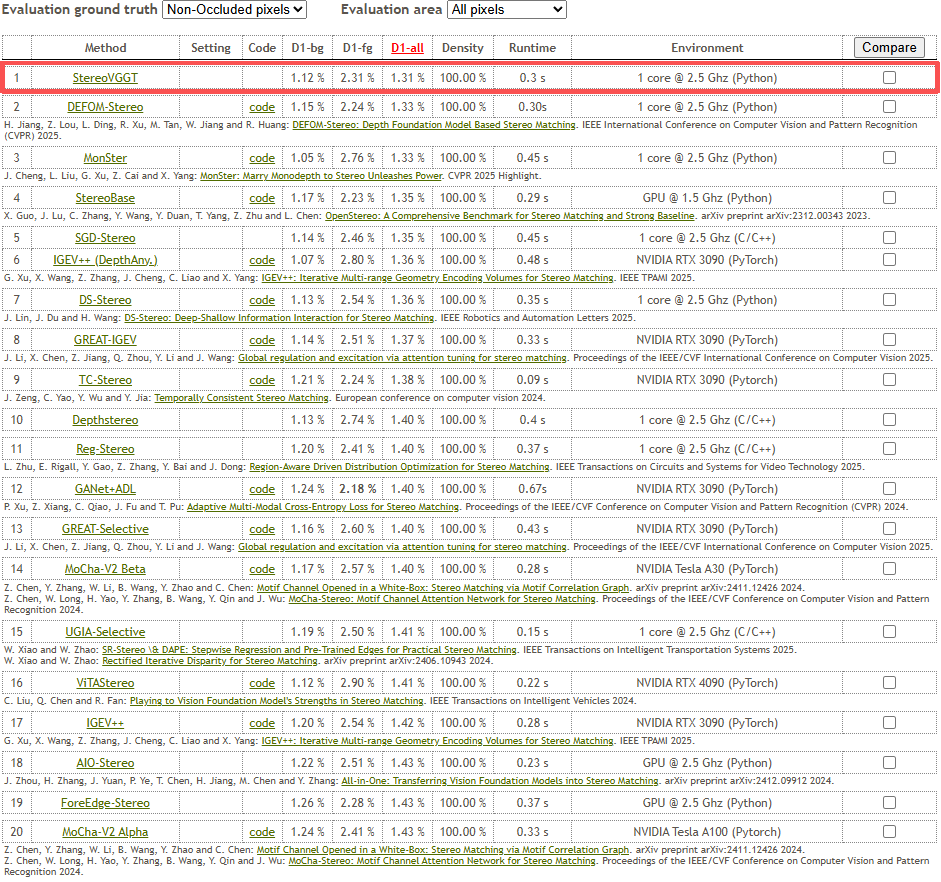
Figure 9: StereoVGGT achieves top rank on the KITTI online benchmark among all submissions, substantiating the method’s robustness and superiority in unconstrained stereo vision.
Conclusion
StereoVGGT sets a new baseline for geometry-aware, training-free stereo vision backbones. It proves that explicit camera supervision, when combined with spatially faithful feature representations through entropy-based model merging, yields consistent SOTA performance without the need for further training. The approach paves the way for future research in model compression, general-purpose geometry foundation models, and training-free adaptation for other geometric vision tasks.