StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Abstract: The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation”
1. What is this paper about?
This paper shows a new way to turn regular videos (shot with one camera—what we call “monocular”) into 3D videos you can watch with 3D glasses or on XR headsets. The system is called StereoWorld. It teaches a smart video generator to create a right-eye view from a left-eye video so the two eyes together form a comfortable, realistic 3D experience.
Quick vocabulary:
- XR: “Extended Reality” devices like VR/AR headsets.
- Stereo video: Two matched videos (left eye and right eye) that your brain combines into 3D.
- IPD (interpupillary distance): The distance between your eyes (usually about 5.5–7.5 cm). Matching this matters for comfortable 3D viewing.
- Depth map: An image that tells how far each pixel is from the camera.
- Disparity: The small horizontal shift between left and right views that creates the 3D effect.
2. What questions were the researchers asking?
The authors set out to answer a few simple but important questions:
- Can we convert ordinary one-camera videos into high-quality, comfortable 3D videos automatically?
- Can we avoid the usual problems (wobbly geometry, flickering across frames, weird colors) that make 3D hard to watch?
- Can we make the result match the natural distance between human eyes (IPD), so it feels realistic in XR headsets?
- Can we do all of this end-to-end in one model instead of using fragile multi-step pipelines?
3. How did they do it?
Think of their system like a very skilled video painter who looks at the left-eye video and paints what the right eye should see.
To make this work, they used a powerful video “diffusion” model (a kind of AI that learns to remove noise step-by-step to create realistic video). They then added smart training tricks so the model learns real 3D structure, not just pretty pictures.
Here are the main ideas, explained in everyday terms:
- Teaching the model to use the left view
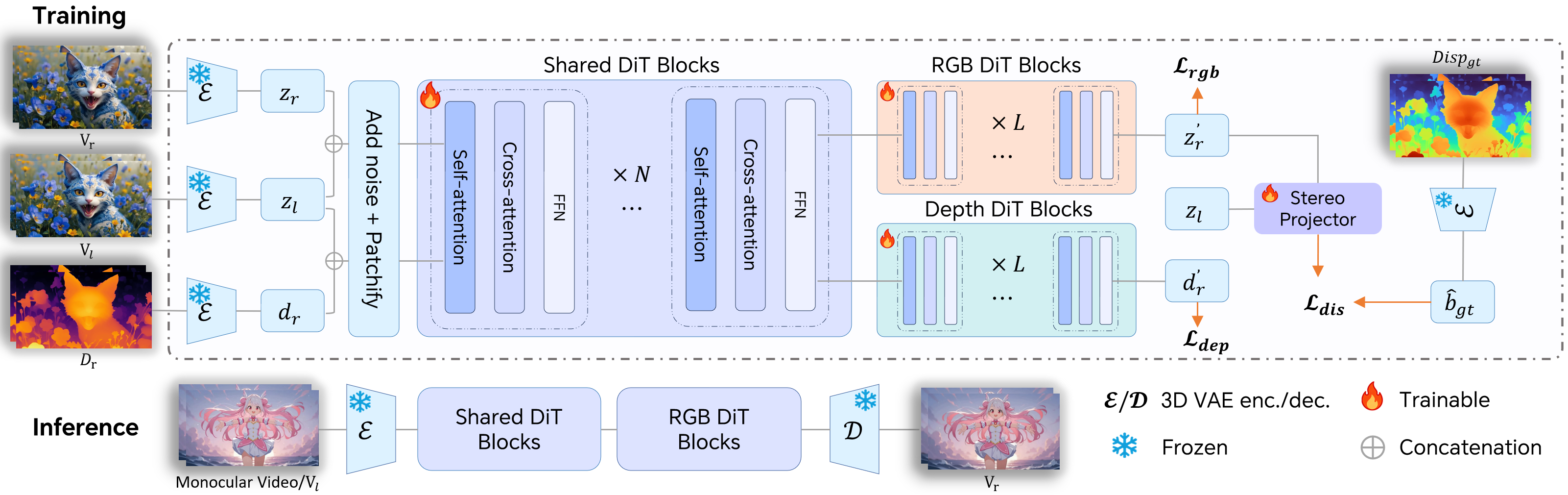
- During training, the model sees pairs of videos: the left view and the right view. It learns to take a left-eye video as input and produce the matching right-eye video.
- Instead of adding complicated new parts to the model, they give it the left and right information in a way that fits the model’s existing “attention” system, so it can connect what it sees across space, time, and the two eyes.
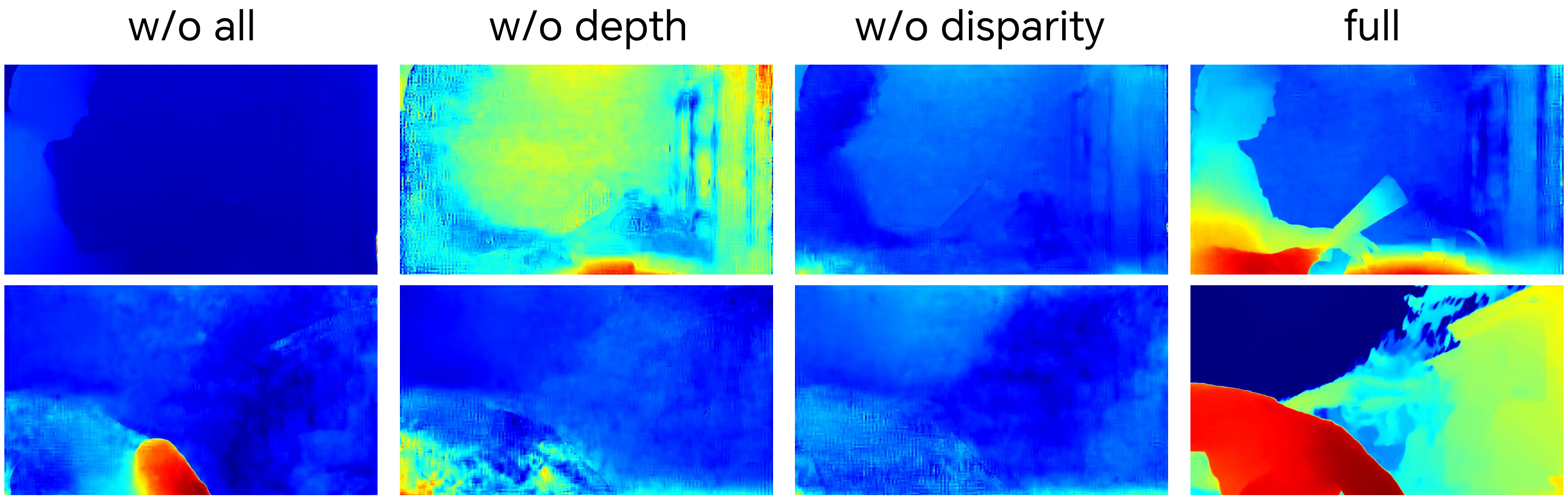
- Geometry-aware regularization (teaching the model real 3D)
- Disparity supervision: The model gets a “built-in stereo checker” that measures the difference between left and right views (disparity). The model is trained to match these differences to reliable targets. This helps keep the two views aligned and stable over time, which reduces eye strain.
- Depth supervision: The model also learns to predict depth (how far things are) alongside the video. Depth gives a full, per-pixel sense of the scene’s 3D shape—even in areas only one eye can see (newly revealed parts when shifting viewpoint). Learning both video and depth together makes the 3D feel solid and accurate.
- Two-branch learning for clarity and control
- Inside the model, early layers are shared, but the last layers split into two focused “branches”: one specializes in making the RGB video, the other in making depth. This avoids the two tasks fighting each other and speeds up learning.
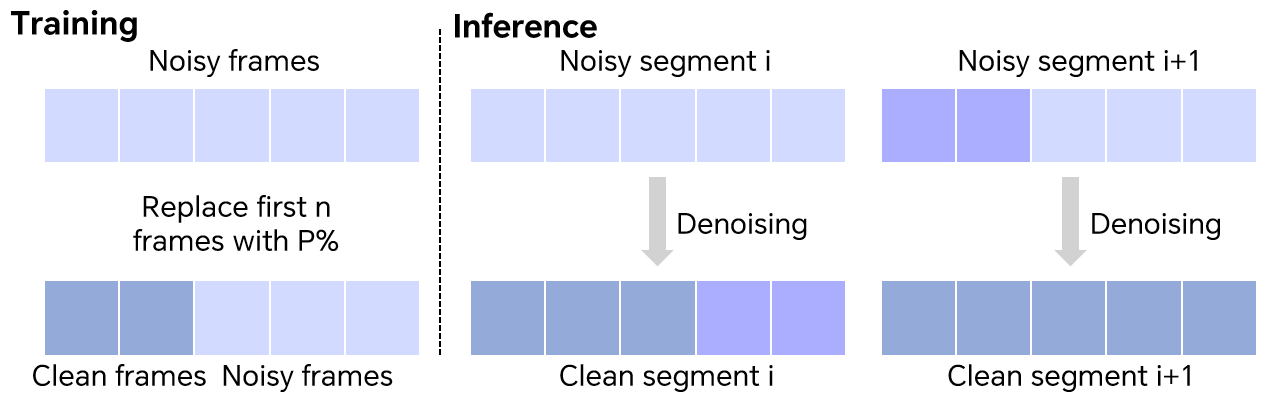
- Making long and high-resolution videos practical
- Temporal tiling: Long videos are processed in overlapping chunks, so the end of one chunk smoothly guides the start of the next. This reduces flicker over time.
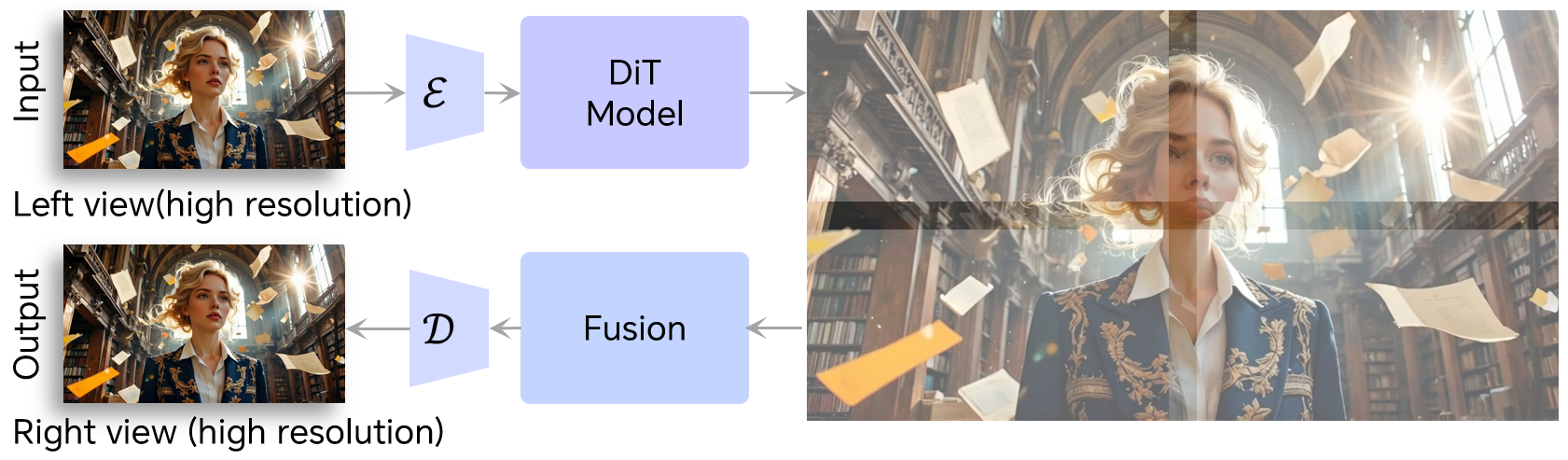
- Spatial tiling: Big frames are split into overlapping tiles, processed, then stitched back together. It’s like cleaning a window pane by pane to handle very large windows.
- Building the right training data
- The team created a huge stereo dataset (StereoWorld-11M) with more than 11 million frames, aligned to human IPD. This matters: if the left/right cameras are too far apart, the 3D effect feels exaggerated and uncomfortable. Their dataset is designed for comfort and realism on XR devices.
4. What did they find, and why is it important?
The authors compared StereoWorld to other methods and found it did better in several key ways:
- Visual quality: Sharper details, fewer weird colors or “made-up” textures, better text readability.
- Geometric accuracy: The left and right views match more precisely, which makes the 3D effect feel correct and reduces eye strain.
- Temporal stability: Less flickering and fewer jumps across frames; motion looks smoother over time.
In tests with both automatic scores and human raters:
- StereoWorld beat other methods on clarity, comfort (binocular consistency), depth feel (stereo effect), and smoothness over time.
- It handled challenging cases like on-screen text especially well, keeping it sharp and aligned in 3D.
Why this matters: High-quality, comfortable 3D is crucial for XR headsets. Bad stereo can make people tired or dizzy. StereoWorld’s improvements help make 3D video more enjoyable and believable.
5. What’s the impact, and what could come next?
This research could make it much easier to create 3D content:
- Anyone with a regular video can convert it to 3D for XR headsets, without special dual-camera rigs.
- It could help filmmakers, educators, game streamers, sports broadcasters, and everyday creators bring more immersive content to people.
Current limits and future ideas:
- Speed: Generating a clip still takes minutes; they want to make it faster.
- Control: The model learns stereo end-to-end, so you can’t yet easily adjust how strong the 3D effect is (the “baseline”). Future versions may allow precise control.
In short, StereoWorld shows a practical, accurate, and comfortable way to turn ordinary videos into high-quality 3D, opening the door to more immersive experiences across many areas.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored, with concrete items that future work can act on:
- Dataset/IPD calibration: The paper claims “IPD-aligned” stereo movies but does not describe how baseline/IPD were measured, normalized, or standardized per shot. Quantify and release per-clip metadata (baseline, disparity range, vertical disparity, window violations) and the method used to align to human IPD.
- Dataset availability and licensing: The StereoWorld-11M dataset is sourced from Blu-ray movies; licensing, redistribution rights, and actual release status are unclear. Provide legal/ethical documentation and a reproducible acquisition pipeline or a licensed alternative dataset.
- Domain coverage and generalization: Training and testing are limited to cinematic SBS movies. Assess generalization to in-the-wild monocular videos (handheld phone footage, egocentric/first-person scenes, sports, documentary, user-generated content) and other domains (driving, robotics).
- Training–inference conditioning mismatch: Training concatenates left and right latents; inference uses only the left view. Study leakage risks and the impact of removing the right-view latent at training time, and compare alternative conditioning (cross-attention to left-only features, scheduled right-view masking).
- Differentiable stereo projector specification: The architecture, training, occlusion handling, and calibration of the projector κ are not described. Provide details and ablations vs. alternative stereo estimators or correlation volumes; incorporate occlusion masks.
- Disparity supervision without occlusion modeling: The disparity loss seems applied uniformly, which can penalize non-overlapping regions. Introduce occlusion-aware losses (left–right consistency checks, visibility masks from depth/disparity) and evaluate their effect.
- Reliance on third-party estimators for supervision: Ground-truth disparity and depth come from Stereo Any Video and Video Depth Anything, which may be noisy or biased across genres (animation vs. live-action). Quantify sensitivity to label noise and domain shift; explore uncertainty-weighted losses, teacher ensembles, and self-training.
- Evaluator bias in geometry metrics: EPE and D1-all are computed using the same or similar disparity estimators, not true ground-truth. Validate with synthetic datasets that provide exact disparity, or triangulate across multiple independent evaluators to reduce metric bias.
- Depth latent encoding via RGB-trained VAE: Encoding depth maps with a VAE trained on RGB videos may be suboptimal. Compare a depth-specific encoder, multi-modal VAE, or joint latent spaces designed for geometry.
- Dual-branch DiT design choices: The number of shared vs. specialized transformer blocks and their placement are not ablated. Study the trade-off between shared representation and task-specific specialization for RGB and depth branches.
- Loss design and hyperparameters: The rationale for the log-disparity loss and weightings (e.g., λl1, λdis) is not analyzed; probabilities in temporal tiling (p) are unspecified. Provide systematic ablations of loss forms (Charbonnier/Huber, scale-invariant depth), weights, and p.
- Parallax/baseline control: The method learns disparity end-to-end but cannot explicitly control stereo baseline or parallax strength. Introduce a controllable knob to scale disparity (e.g., conditioning tokens, adaptive camera baseline) for comfort or device-specific IPD.
- XR comfort metrics: No measurement of viewer comfort (vergence–accommodation conflict, disparity safety ranges, vertical disparity, window violations). Integrate comfort metrics and device-specific evaluations on HMDs (Apple Vision Pro, Quest) under different content and playback settings.
- Text rendering evaluation: Claims improved text fidelity are supported only qualitatively. Add quantitative tests (cross-view OCR accuracy, stereo alignment error, temporal stability of text regions).
- Challenging materials and scenes: Performance is not evaluated on specular, transparent, reflective surfaces, thin structures, extreme near–far compositions, and low-light/high-ISO noise. Create stress tests for these conditions.
- Motion robustness: Robustness to fast camera motion, high motion blur, rolling shutter artifacts, and non-rigid motion is not analyzed. Evaluate on motion-rich datasets and measure temporal disparity drift.
- Shot boundary effects: The dataset samples fixed-length clips that may include hard cuts. Analyze how shot transitions affect training and inference; adopt shot-aware sampling and conditioning.
- Long-duration generation: Temporal tiling is described but assessed only qualitatively for short clips. Evaluate minute-scale or longer sequences with metrics for drift, flicker, and cross-segment geometry consistency.
- Spatial tiling artifacts: Overlap stitching may introduce seams or global inconsistency at high resolutions. Quantify seam artifacts and compare to alternatives (global attention windows, multi-scale diffusion, sliding-window denoising with global context).
- Resolution scaling limits: The method is trained at 480p; high-res (1080p/4K) behavior is evaluated only qualitatively. Provide quantitative metrics and memory/performance profiles for 2K/4K and ultra-wide formats.
- Frame rate constraints: Output frame rates (12–16 FPS) are below XR needs (60–90 FPS). Assess stereo-consistent frame interpolation/in-betweening and its comfort implications.
- Efficiency and deployment: Inference takes ~6 minutes per clip; training requires 11 days on 8×A800 GPUs. Explore acceleration (distillation, consistency models, fewer sampling steps, progressive denoising, caching of conditioning features) and report throughput vs. quality trade-offs.
- Failure case analysis: The paper lacks a systematic catalog of failure modes (ghosting, vertical disparity, inconsistent occlusions, color shifts). Release a failure set with annotations and targeted remedies.
- Reproducibility details: Some hyperparameters and components (e.g., projector κ, tiling p) are under-specified; there are typos in loss weights in the text. Provide exact configs, seeds, training schedules, and code.
- Multi-view extension: The approach targets stereo only; generalization to N-view (light fields or panoramic stereoscopy) is not explored. Investigate scalability to multiple viewpoints and varying baselines.
- Hybridization with NVS/3D reconstruction: The method eschews explicit geometry. Explore hybrid pipelines that combine learned stereo priors with 3D reconstruction for controllable parallax and occlusion reasoning.
- Robustness to left-view degradations: Assess performance under compression artifacts, noise, deinterlacing errors, stabilization-induced warping, lens distortions, and rolling shutter; consider pre-processing or robust training.
- Device-specific rendering: Adaptation to different displays (interlaced, anaglyph, lenticular, dual-panel HMDs) and their color/geometry pipelines is not discussed. Provide device-calibrated rendering strategies and evaluations.
Practical Applications
Below is a structured synthesis of practical applications enabled by the paper’s findings and techniques—most notably, an end-to-end, geometry-aware diffusion framework that converts monocular videos into high-fidelity, IPD-aligned stereo videos, plus a scalable spatio-temporal tiling workflow and a large IPD-aligned stereo dataset.
Immediate Applications
- Bold: Stereo upconversion for streaming catalogs (Media/Entertainment, XR)
- Use: Batch-convert existing 2D libraries (films, series, documentaries, short-form content) into SBS/VR180-compatible stereo deliverables for XR headsets and stereoscopic displays.
- Tools/workflows: Cloud or on-prem transcode service integrated into existing pipelines (FFmpeg + StereoWorld API), packaging to MV-HEVC/DASH/HLS with XR metadata.
- Assumptions/dependencies: Content rights and licensing; compute throughput (current ~6 min/clip implies offline/batch processing); quality control for motion-heavy scenes; baseline is not user-controllable.
- Bold: Post-production stereo plug-ins (Film, Advertising, Creative Software)
- Use: Editor effects for Adobe Premiere/After Effects and DaVinci Resolve to produce right-eye views directly on the timeline with IPD-aligned comfort.
- Tools/workflows: Plug-ins leveraging spatio-temporal tiling for long/high-res sequences; render queue integration; stereo QC overlays (disparity drift flags).
- Assumptions/dependencies: GPU availability; render times; lack of explicit baseline/depth-budget control may limit creative intent; color management alignment.
- Bold: XR content expansion for headsets (XR, Education, Museums)
- Use: Convert 2D assets to stereo for Apple Vision Pro, Meta Quest, and 3D TVs; enhance immersion in exhibits, museum installations, and classroom XR content.
- Tools/workflows: In-headset converter app or web service with SBS/Top–Bottom export; device-specific packaging and player support.
- Assumptions/dependencies: Device format support and playback; per-title comfort validation; bandwidth/storage for stereo deliverables.
- Bold: Social media 3D creation (Marketing, Creator Economy)
- Use: Filters or mobile apps to convert short-form vertical videos into stereo for XR-friendly viewing and novel “3D post” formats.
- Tools/workflows: CapCut/TikTok/Snap camera integrations; cloud-based API for short clips; automated comfort presets.
- Assumptions/dependencies: Cost per clip; quality at smartphone aspect ratios; user privacy controls; network latency for mobile uploads.
- Bold: 3D product videos for e-commerce (Retail, Marketing)
- Use: Stereo product demos, unboxing, and fittings to improve depth perception in WebXR storefronts and virtual try-on experiences.
- Tools/workflows: Batch conversion for product libraries; stereo-optimized web player with fallback to 2D.
- Assumptions/dependencies: Device/browser compatibility; A/B testing for conversion lift; careful handling of fine textures and brand colors.
- Bold: Training and education content (Education, Healthcare training)
- Use: Enhance depth perception in lab demos, engineering walkthroughs, anatomy lessons, and surgical training videos for XR viewing.
- Tools/workflows: LMS/LTI integration; pre-set comfort profiles; export to classroom headsets.
- Assumptions/dependencies: Pedagogical validation; clinical content restricted to non-diagnostic training; comfort checks for long sessions.
- Bold: Archival and cultural exhibitions (Culture/Heritage)
- Use: Immersive re-releases of classic films and archival footage within museum experiences or remastered editions.
- Tools/workflows: Curated conversion with human-in-the-loop QC; metadata pipelines for preservation and cataloging.
- Assumptions/dependencies: Rights clearances; ethical curation; preservation-grade storage.
- Bold: Stereo QC and benchmarking (Media Tech, QA)
- Use: Automated QC to detect stereo artifacts (e.g., disparity drift, EPE thresholds) in converted content before release.
- Tools/workflows: Stereo Any Video–based automated validators; integration with VBench metrics; per-shot reports for post teams.
- Assumptions/dependencies: Computational overhead; thresholds tuned to human comfort; potential false positives/negatives.
- Bold: Academic research enablement with IPD-aligned data (Academia, AI Research)
- Use: Train/evaluate stereo generation, depth estimation, and comfort metrics on human-IPD-aligned content at scale.
- Tools/workflows: Baselines built on StereoWorld’s training recipe; evaluations with PSNR/SSIM/LPIPS and geometry metrics (EPE, D1-all).
- Assumptions/dependencies: The 11M-frame dataset’s licensing status (sourced from Blu-ray content) may limit public redistribution; reproducibility may require alternate datasets or synthetic data.
- Bold: Synthetic stereo data augmentation (Robotics, Autonomy R&D)
- Use: Generate stereo pairs from monocular robot/dashcam videos to pretrain or augment stereo matchers and depth networks.
- Tools/workflows: Domain-specific batching; augmentation schedules; mix with real stereo when available.
- Assumptions/dependencies: Domain gap (movies vs. robotics); depth is perceptual rather than metrically guaranteed; unsuitable for safety-critical perception without validation.
- Bold: 3D signage and autostereoscopic display assets (Advertising/DOOH)
- Use: Convert marketing videos for lenticular/autostereoscopic billboards and displays with controlled disparity for viewing comfort.
- Tools/workflows: Export to device-specific formats; calibration profiles per signage system.
- Assumptions/dependencies: Hardware constraints; brightness and viewing distance variability; QC across viewing zones.
- Bold: Internal comfort guidelines and policy adoption (Policy/UX Governance)
- Use: Adopt IPD-aligned conversion standards and stereo QA checklists to reduce user discomfort across services.
- Tools/workflows: Studio/post policies; automated comfort tiers; labeling content with stereo-intensity expectations.
- Assumptions/dependencies: Organizational buy-in; absence of baseline controls may limit policy compliance granularity.
Long-Term Applications
- Bold: Real-time monocular-to-stereo conversion (XR devices, Live broadcasts)
- Use: Live stereo for sports/events and real-time XR viewing from 2D camera feeds.
- Tools/workflows: Model distillation, quantization, and hardware acceleration (on-device NPUs/ASICs); OBS/SDI pipeline plugins.
- Assumptions/dependencies: Significant latency and compute reductions; thermal/power constraints; robust live QC.
- Bold: User-controllable stereo baseline and comfort profiles (Media Tech, Accessibility)
- Use: Interactive control over depth budget/baseline per scene, viewer preference, or device.
- Tools/workflows: Model architectures with explicit disparity control; scene-aware depth sliders; automatic comfort normalization.
- Assumptions/dependencies: New training objectives for baseline control; human-factors validation; UI/UX standardization.
- Bold: Telepresence and conferencing in VR from single cameras (Enterprise, Collaboration)
- Use: Convert monocular webcams to stereo streams for more immersive meetings and remote collaboration.
- Tools/workflows: Plugins for Zoom/Teams/Meet; VR client rendering with comfortable depth cues.
- Assumptions/dependencies: Low-latency inference; privacy and security; handling of compression artifacts.
- Bold: Consumer camera “3D Video” mode (Consumer Electronics, Mobile)
- Use: Smartphone or action camera modes that capture 2D but output stereo for XR playback.
- Tools/workflows: On-device or cloud postprocess; camera firmware integration; pairing with XR viewers.
- Assumptions/dependencies: Battery/compute budgets; upload bandwidth; consistent results across lighting and motion conditions.
- Bold: Immersive news/sports pipelines (Media/News)
- Use: Stereo channels for news, replays, and highlight reels from legacy monocular feeds.
- Tools/workflows: Real-time edge processing; editorial tools for depth comfort; automated event-based triggers.
- Assumptions/dependencies: Broadcast-grade latency; rights; production-grade reliability.
- Bold: Operator-assist stereo visualization in robotics (Robotics, Teleoperation)
- Use: Improved depth perception for human operators teleoperating robots or drones from monocular feeds.
- Tools/workflows: Stereo overlays in operator UIs; adaptive depth budget by task.
- Assumptions/dependencies: Latency tolerance; not for autonomy or metric sensing; robust behavior in low-texture/low-light scenes.
- Bold: Medical education and planning (Healthcare)
- Use: Stereo viewing of surgical/endoscopic videos for training or preoperative visualization to increase spatial understanding.
- Tools/workflows: Hospital PACS-adjacent viewers; XR rehearsal environments; secure processing.
- Assumptions/dependencies: Regulatory compliance; patient privacy; not diagnostically validated or metrically accurate; clinical studies required.
- Bold: Standards and policy for stereo comfort and labeling (Standards bodies, Platforms)
- Use: Establish IPD-aligned stereo production standards, comfort metrics (e.g., disparity drift thresholds), and content labeling norms.
- Tools/workflows: Open benchmarks; cross-industry task forces; platform-level QA tools.
- Assumptions/dependencies: Multi-stakeholder coordination; agreement on metrics and thresholds; alignment with device makers.
- Bold: Multimodal 3D foundation model training (AI Research)
- Use: Use stereo pairs with depth supervision to train video–language–3D models, improving 3D reasoning and perception in generative systems.
- Tools/workflows: Large-scale curated datasets; joint RGB–depth objectives; evaluation suites for geometry-aware generation.
- Assumptions/dependencies: Dataset licensing; large compute; robust generalization across domains.
- Bold: Embedded monocular-to-stereo cameras (Hardware, Drones, Sports cams)
- Use: Cameras that output stereo streams from a single lens for XR displays and specialized uses (e.g., FPV).
- Tools/workflows: Dedicated inference chips; thermal management; firmware updates.
- Assumptions/dependencies: ASIC development; power/latency constraints; price sensitivity.
- Bold: Cinema-grade 4K/8K HDR stereo remastering (Film, Post-production)
- Use: High-resolution, color-managed stereo conversion for theatrical and premium streaming releases.
- Tools/workflows: Training/fine-tuning at higher resolutions; integration into IMF and ACES pipelines; robust artifact suppression.
- Assumptions/dependencies: Substantial compute budgets; new training for high-res/HDR; longer render times; deeper creative controls.
Notes on feasibility and cross-cutting dependencies:
- The current system is optimized for offline processing (minutes per clip) and trained at 480p with tiling for high-res—near-term deployments should target batch conversion and editing workflows, not live or on-device use.
- IPD alignment and geometry-aware regularization improve comfort but do not guarantee metric accuracy; applications requiring ground-truth geometry (e.g., autonomy, diagnostics) need additional validation and are not recommended to rely solely on this method.
- Dataset provenance and licensing may limit public redistribution; replication may require alternative data sources or synthetic datasets.
- Lack of explicit baseline control can limit creative and accessibility-focused workflows; future model variants with disparity control will broaden applicability.
Glossary
- 3D Gaussian Splatting (3DGS): A neural rendering technique that uses Gaussian primitives to explicitly represent scene geometry for efficient, high-quality view synthesis. "3D Gaussian Splatting (3DGS) \cite{kerbl20233d} attempt to recover scene geometry and camera parameters before rendering a new perspective for the right eye."
- 3D Variational Auto-Encoder (3D VAE): A variational auto-encoder that encodes and decodes spatio-temporal video data into latent representations using 3D operations. "This model first uses a 3D Variational Auto-Encoder (3D VAE) to encode videos into a latent representation."
- Baseline (stereo vision): The physical distance between the optical centers of two cameras, determining stereo parallax; misaligned baselines can cause discomfort in XR. "In stereo vision, the baseline is the precise physical distance between the optical centers of the two camera lenses."
- Binocular Consistency (BC): A human evaluation metric assessing alignment and consistency between left and right views in stereo content. "participants scored each scene on four aspects using a 1–5 scale: Stereo Effect (SE), Visual Quality (VQ), Binocular Consistency (BC), and Temporal Consistency (TC)."
- Block-wise latent diffusion: An inference technique that splits high-resolution latent representations into overlapping tiles for independent denoising and stitching. "To handle high-resolution videos beyond the 480p training resolution, we adopt block-wise latent diffusion \cite{zhao2024stereocrafter}."
- Conditional Flow Matching (CFM): A training objective for Rectified Flow models that regresses a target velocity field to define a valid probability path between data and noise. "During training, we minimize the Conditional Flow Matching (CFM) loss \cite{esser2024scaling} by regressing the target vector field that generates a valid probability path between and ."
- Cross-attention: An attention mechanism in transformers that fuses conditioning signals (e.g., text or reference frames) with video tokens to capture aligned dependencies. "Then DiT blocks integrate self-attention and cross-attention modules to jointly capture spatio–temporal dependencies and text–video interactions."
- Depth supervision: A training constraint that jointly predicts and enforces consistency of per-pixel depth maps with generated RGB frames to improve geometric fidelity. "To compensate for the missing geometric cues in non-overlapping regions, we introduce a depth-based supervision."
- Differentiable stereo projector: A lightweight module that estimates disparity from left and generated right-view latents, enabling gradient-based supervision of geometric correspondence. "we employ a lightweight, differentiable stereo projector to estimate the predicted disparity "
- Diffusion Transformer (DiT): A transformer-based diffusion architecture that models spatio-temporal dependencies for video generation in latent space. "We build our framework on a pretrained text-to-video diffusion model based on the Diffusion Transformer(DiT) architecture~\cite{peebles2023scalable}."
- Disparity drift: Temporal fluctuations in estimated stereo disparities across frames that cause instability and visual discomfort. "Disparity supervision enforces accurate stereo correspondence, mitigating cross-view misalignment and temporal disparity drift to improve stability and visual comfort."
- Disparity supervision: A loss that enforces accurate stereo correspondence by comparing predicted disparities with ground-truth maps derived from stereo matching. "Disparity supervision enforces accurate stereo correspondence, mitigating cross-view misalignment and temporal disparity drift to improve stability and visual comfort."
- D1-all: A stereo accuracy metric quantifying the percentage of pixels whose disparity error exceeds a threshold (e.g., 3 pixels or 5% of true disparity). "D1-all~\cite{geiger2012we}, which denotes the percentage of pixels whose disparity error exceeds a given threshold (typically 3 pixels or 5\% of the true disparity)."
- End-Point-Error (EPE): The average per-pixel disparity error between predicted and ground-truth disparities in stereo evaluation. "We then compute EPE (End-Point-Error)âthe average pixel-wise disparity errorâand D1-all~\cite{geiger2012we}"
- Interpupillary Distance (IPD): The distance between human pupils; aligning stereo baselines to IPD improves comfort and realism on XR devices. "aligned to natural human interpupillary distance (IPD)."
- IQ-Score: An objective metric from VBench that evaluates the visual quality of generated video frames. "IQ-Score and TF-Score refer to image quality and temporal flickering scores from VBench~\cite{huang2024vbench}."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank updates into pretrained weights to adapt large models. "During fine-tuning, we adopt the LoRA \cite{hu2022lora} framework with a rank of 128"
- Monocular-conditioning: A conditioning strategy that feeds the left-view video to guide generation of the right view without architectural changes. "Monocular-conditioning."
- Monocular-to-stereo video generation: The task of synthesizing a right-eye view from a single input video to produce stereoscopic content. "we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation."
- Novel View Synthesis (NVS): Generating new camera viewpoints by reconstructing scene geometry and rendering from desired perspectives. "The first treats the task as novel-view synthesis (NVS) via 3D scene reconstruction."
- Occluded regions: Areas not visible from the target viewpoint after warping, requiring hallucination or inpainting to complete the view. "Depth is first estimated from the input video and used to warp frames into the target viewpoint; occluded regions are then hallucinated by an inpainting model."
- Parallax: Apparent positional shifts between two views due to baseline separation; excessive parallax can cause discomfort. "This wide baseline is unsuitable for XR devices as it leads to exaggerated parallax, which can easily cause visual discomfort for the viewer."
- Rectified Flow framework: A diffusion training paradigm that learns a velocity field along a linear path from data to noise via an ODE transform. "The model is trained under the Rectified Flow framework \cite{lipman2022flow}, where the forward process defines a linear trajectory between the data distribution and a standard normal distribution:"
- Side-by-side (SBS): A stereo video format storing left and right views horizontally adjacent within a single frame. "We collected and cleaned over a hundred high-definition Blu-ray side-by-side (SBS) stereo movies from the Internet"
- Spatial tiling strategy: An inference scheme that splits high-resolution latents into overlapping spatial tiles for independent denoising and fusion. "Spatial tiling strategy. During inference, high-resolution videos are encoded into latents, which are split into overlapping tiles."
- Spatio-temporal tiling scheme: A combined approach to handle both long durations and high resolutions by tiling across space and time. "A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis."
- Stereo correspondence: The pixel-level matching between left and right views that encodes scene depth via disparity. "Disparity supervision enforces accurate stereo correspondence, mitigating cross-view misalignment and temporal disparity drift"
- Stereo matching network: A model that estimates disparities between left-right pairs to provide ground-truth supervision signals. "we pre-compute the ground-truth disparity map by applying a pre-trained stereo matching network~\cite{jing2025stereo}"
- Temporal tiling strategy: A method for generating long videos by overlapping segments and guiding subsequent segments with previous frames to maintain consistency. "Temporal tiling strategy. During training, the first few frames of noisy latents are replaced with ground-truth frames with a probability ."
- TF-Score (Temporal Flickering Score): A VBench metric quantifying frame-to-frame stability and flicker in generated videos. "IQ-Score and TF-Score refer to image quality and temporal flickering scores from VBench~\cite{huang2024vbench}."
- Variational Auto-Encoder (VAE) encoder: The encoder component of a VAE that maps video frames into latent space for diffusion. "we encode the left and right videos into latent space via the VAE encoder "
- Velocity field (in Rectified Flow): A learned vector field that transports noise to data along a continuous trajectory defined by an ODE. "The goal is to learn a velocity field parameterized by the network weights , which transforms random noise into data samples through an ordinary differential equation (ODE)"
Collections
Sign up for free to add this paper to one or more collections.

