Stereo World Model: Camera-Guided Stereo Video Generation
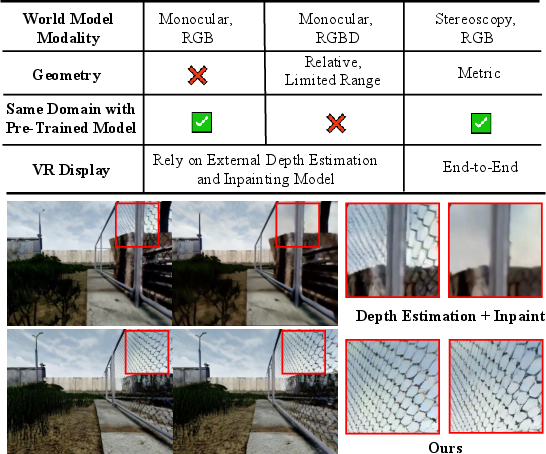
Abstract: We present StereoWorld, a camera-conditioned stereo world model that jointly learns appearance and binocular geometry for end-to-end stereo video generation.Unlike monocular RGB or RGBD approaches, StereoWorld operates exclusively within the RGB modality, while simultaneously grounding geometry directly from disparity. To efficiently achieve consistent stereo generation, our approach introduces two key designs: (1) a unified camera-frame RoPE that augments latent tokens with camera-aware rotary positional encoding, enabling relative, view- and time-consistent conditioning while preserving pretrained video priors via a stable attention initialization; and (2) a stereo-aware attention decomposition that factors full 4D attention into 3D intra-view attention plus horizontal row attention, leveraging the epipolar prior to capture disparity-aligned correspondences with substantially lower compute. Across benchmarks, StereoWorld improves stereo consistency, disparity accuracy, and camera-motion fidelity over strong monocular-then-convert pipelines, achieving more than 3x faster generation with an additional 5% gain in viewpoint consistency. Beyond benchmarks, StereoWorld enables end-to-end binocular VR rendering without depth estimation or inpainting, enhances embodied policy learning through metric-scale depth grounding, and is compatible with long-video distillation for extended interactive stereo synthesis.




































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Stereo World Model: Camera-Guided Stereo Video Generation”
1. What is this paper about?
This paper introduces StereoWorld, an AI system that can create stereo videos (videos for left and right eyes) that match a chosen camera path. It does this using only regular color images (RGB), like what a normal camera sees, and it learns real 3D structure from the differences between the two eyes (called “disparity”), similar to how our own eyes see depth.
2. What questions are they trying to answer?
The authors ask:
- Can we make an AI “world model” that understands both how things look and how they sit in 3D space using stereo vision, not just single-camera video?
- Can it follow camera movements accurately over time while keeping the left and right views consistent?
- Can we make this fast and reliable enough to be useful for VR/AR and for robots that need accurate depth?
3. How does their method work?
Think of a “world model” as a smart simulator: if you tell it where the camera moves, it predicts the next frames of the world. StereoWorld does this for two eyes at once.
To build it, the authors start from a powerful video-generation model and add two key ideas so it understands stereo 3D while staying efficient:
- Learning from stereo videos using a diffusion model
- Diffusion models create videos by starting with random noise and “cleaning” it step by step until a realistic video appears.
- A 3D VAE (a compressor for videos across time and space) shrinks videos into a compact form so generation is faster.
- A transformer (DiT) then learns to denoise and produce future frames in that compact space.
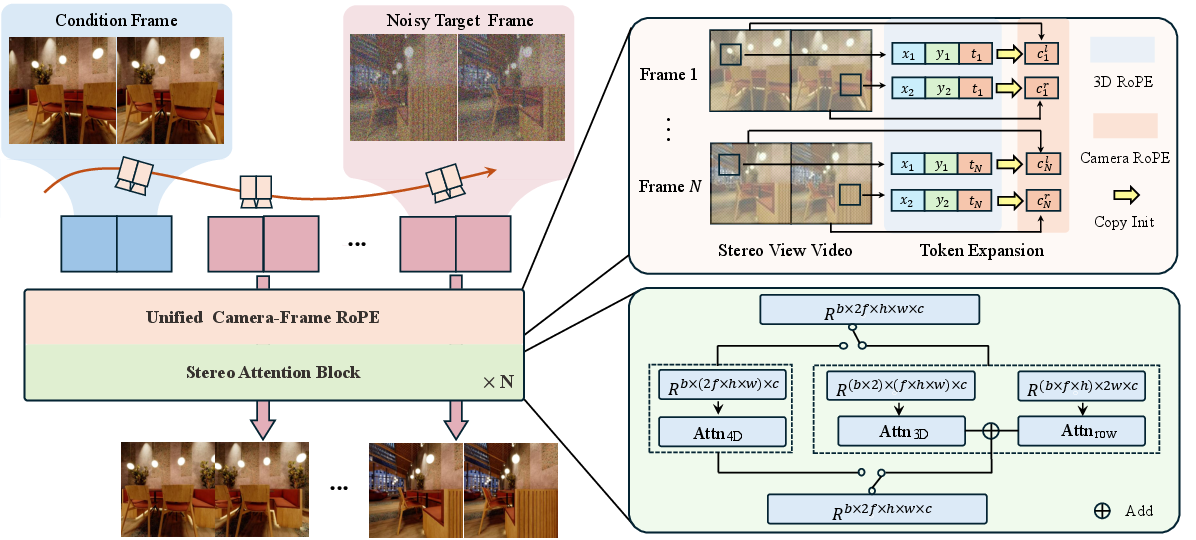
- Idea 1: Unified camera-frame RoPE (camera-aware positional encoding)
- Transformers need to know where and when each patch of video is (like labeling pieces with “this is frame 3, row 10, column 20”).
- RoPE is a way to give the model a sense of position by rotating features in a way that encodes relative positions.
- The authors add camera information (like lens settings and where the camera is pointing) into this positional system, but in a careful way:
- Instead of changing the original positions (which could disrupt what the pretrained model already learned), they add extra “channels” dedicated to camera info.
- This lets the model understand relationships across time and between the two eyes while keeping the old knowledge stable.
- Simple analogy: Imagine the model already knows how to read a map. The authors add a clear, separate compass and ruler on the side, instead of redrawing the whole map.
- Idea 2: Stereo-aware attention with epipolar geometry
- Transformers decide “who should pay attention to who.” That can be very expensive when you have many frames and two views.
- In stereo, matching points in the left and right images lie on the same horizontal line (after rectification). This is a classic stereo rule called the “epipolar constraint.”
- The authors split attention into two parts:
- Intra-view attention: each eye looks within its own video across space and time (normal 3D attention).
- Row-based cross-view attention: the left eye only compares with the right eye along the same rows, where true matches live.
- This keeps stereo consistency high but cuts computation a lot.
- Simple analogy: If you’re comparing two long spreadsheets (left and right) to find matches, you only compare the same rows, not every row with every other row. Much faster and just as accurate.
Key terms explained:
- Stereo: Two views of the same scene from slightly different positions (like your two eyes).
- Disparity: The small shift of an object’s position between left and right images; larger shift means the object is closer. From disparity, you can get real depth if you know the distance between the “eyes” (the baseline).
- Baseline: The distance between the left and right cameras.
- Intrinsics/Extrinsics: Camera “settings.” Intrinsics describe the lens and sensor; extrinsics describe where the camera is in space and how it’s oriented.
- Attention: How a transformer decides which parts of the input are most relevant to each other.
- Positional encoding (RoPE): A way to give the model a sense of where and when each piece of the video is, using clever rotations of features that encode relative positions.
4. What did they find, and why is it important?
The authors show that StereoWorld:
- Makes left and right views match better over time (higher stereo consistency).
- Follows the planned camera motion more accurately.
- Produces better depth geometry (cleaner, more reliable disparity).
- Runs over 3 times faster than doing “generate a single-view video first, then convert it to stereo with depth and inpainting,” which is the common alternative.
- Improves viewpoint consistency by about 5%.
Why this matters:
- For VR/AR: You need two eye views that match perfectly; otherwise, it looks wrong or feels uncomfortable. StereoWorld generates both views directly without messy extra steps like depth estimation and filling holes.
- For robots and embodied AI: Accurate, metric-scale depth (depth with real units, thanks to stereo baseline) makes navigation and planning more reliable.
- For long videos: Their method can plug into long-video generation systems, making long, interactive stereo scenes possible.
5. What’s the impact and what could this lead to?
- Better VR/AR experiences: End-to-end stereo video generation with consistent details between eyes can make virtual worlds look more stable and realistic.
- Safer, smarter robots: A world model that “sees” in stereo can make better decisions using true 3D geometry.
- Faster, more reliable pipelines: Skipping separate depth-estimation and inpainting steps reduces errors and speeds things up.
- A step toward geometry-aware generative AI: This shows a practical way to blend visual quality with strong 3D understanding, which could influence future video, gaming, simulation, and robotics systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research:
- Rectification assumption and epipolar simplification:
- The stereo-aware attention relies on horizontal row attention (epipolar lines aligned with image rows), implicitly assuming rectified stereo. It is unclear how the method performs with unrectified pairs, vertical parallax, toed-in rigs, rolling-shutter distortions, or calibration errors. Extend attention to general epipolar geometries (e.g., fundamental-matrix–guided attention) and quantify robustness to miscalibration.
- Generalization to multi-view and non-binary camera setups:
- The method is limited to two views. It remains unknown how the architecture and the unified camera-frame RoPE scale to N-view video generation and to dynamically changing camera constellations. Investigate computational and performance trade-offs for 3+ synchronized views.
- Metric-scale claims lack direct depth evaluation:
- Although the paper claims metric-scale grounding via disparity and known baselines, there is no systematic evaluation against ground-truth depth/scale (e.g., EPE/bad-pixel on Middlebury/SceneFlow, absolute scale error on real datasets with GT). Add quantitative depth/scale metrics and ablate sensitivity to baseline/intrinsics noise.
- Geometry assessment depends on external disparity estimator:
- Disparity quality is analyzed using a third-party estimator on generated stereo, not against ground truth. This confounds model and estimator errors. Evaluate geometry using datasets with GT disparity/depth and report standard stereo metrics across time.
- Temporal stereo consistency is not measured:
- There is no quantitative assessment of disparity/geometry stability across frames (e.g., scene flow consistency, temporal flicker in disparity, cross-time reprojection error). Introduce temporal-geometry metrics and analyze long-horizon drift.
- Occlusions and disocclusions are not explicitly modeled:
- Cross-view fusion does not include occlusion-aware mechanisms or losses, and no occlusion-specific metrics are reported. Evaluate on scenes with heavy occlusion and introduce occlusion-aware attention or visibility modeling.
- Dynamic scene content beyond camera motion:
- The model is “action-/camera-conditioned,” but experiments focus on camera trajectories; handling of independently moving objects remains underexplored. Test on dynamic scenes with object motion and quantify performance on motion segmentation or tracking consistency.
- Long-horizon generation and drift:
- Experiments use 49-frame clips; the stability of geometry and camera conformity over minutes-long sequences is untested. Evaluate much longer trajectories, analyze drift, and assess compatibility with long-video distillation at scale.
- Robustness to photometric/heterochannel variations:
- VR/AR rigs often exhibit exposure, gain, and color mismatches between eyes. The method’s robustness to left–right photometric inconsistencies is not quantified. Add controlled tests with photometric perturbations and evaluate view-consistency under such conditions.
- Real-world generalization and domain bias:
- Training and evaluation are heavily synthetic, with limited real stereo data. Assess generalization on diverse real-world datasets (handheld stereo, vehicle rigs, head-mounted displays), and report domain gap analyses and adaptation strategies.
- FPS and VR-readiness:
- Despite a 3× speedup over multi-stage pipelines, reported FPS (≤0.49) is far from real-time VR needs (≥60–90 FPS per eye at high resolution). Profile bottlenecks, evaluate at VR resolutions (e.g., ≥2K per eye), and explore sampling/architecture speedups for interactive rates.
- Sensitivity to camera-RoPE design choices:
- The expanded camera subspace (dimension d_c), initialization choices (zero vs. copy), and frequency allocation are not systematically ablated. Provide controlled studies on d_c size, frequency bands, and alternative camera encodings to guide practitioners.
- Handling of non-horizontal epipolar lines over time:
- Row attention restricts cross-view fusion to same-timestep horizontal correspondences. This may be suboptimal for imperfect rectification or cases where epipoles shift (e.g., zoom, lens distortions). Explore learned epipolar kernels or dynamic row/column attention.
- Evaluation fairness vs. RGBD baselines:
- Comparisons rely on monocular models plus depth-estimation-and-inpainting conversion; no directly comparable end-to-end stereo baseline exists. Construct or fine-tune a strong stereo-capable backbone as a baseline to isolate gains from stereo conditioning vs. pipeline artifacts.
- Camera accuracy assessment via estimation on generated frames:
- Camera conformity is measured using an external pose estimator (VGGT), which introduces estimator biases. Validate with synthetic scenes where ground-truth camera poses and geometry are known, and report direct conformity metrics.
- Comfort and safety for VR:
- There is no evaluation of vergence–accommodation comfort zones, disparity bounds, or temporal disparity changes that affect visual comfort. Analyze disparity distributions vs. HMD guidelines and user studies on comfort/motion sickness.
- Embodied intelligence claims lack task-level validation:
- The paper asserts benefits for policy learning but provides no concrete embodied-task evaluations or benchmarks (e.g., navigation, manipulation). Conduct controlled RL/IL studies comparing monocular, RGBD, and stereo world models on standard embodied environments.
- Scalability to higher resolutions and memory constraints:
- Training is at 480×640; VR/AR typically requires much higher resolutions. Benchmark memory/compute at 1080p–4K per eye and propose memory-efficient attention (e.g., windowed/linear attention or token sparsification).
- Failure modes with low-texture/repetitive patterns:
- Stereo can fail with textureless surfaces or repetitive patterns; robustness is not analyzed. Curate stress-test sets (e.g., blank walls, periodic textures) and evaluate view consistency and depth plausibility.
- Extension to non-rigid camera models and lens effects:
- Real lenses introduce distortions, vignetting, and rolling-shutter artifacts. The method assumes pinhole + rectification. Assess how to incorporate non-linear camera models or learn distortion-aware RoPE.
- Inter-view latency and synchronization:
- The approach assumes synchronized frames across views; behavior under small temporal offsets (e.g., unsynced shutters) is untested. Experiment with induced inter-view latency and design temporal cross-view fusion to compensate.
- Lack of explicit geometry-consistency losses:
- Training relies on diffusion priors and positional encodings without explicit epipolar/photometric consistency or reprojection losses. Explore adding differentiable geometric constraints to further tighten binocular consistency.
- Limited analysis of failure cases:
- The paper highlights improvements but does not catalog failure modes (e.g., ghosting across views, stereo jitter, depth sign flips). Provide qualitative/quantitative error analysis to target model refinements.
Practical Applications
Immediate Applications
Below are deployable-now use cases that can leverage the paper’s methods and findings with today’s tools and compute (primarily offline or near–real-time), assuming access to a rectified stereo pair and camera metadata.
- End-to-end stereo VR video rendering for content production
- Sectors: media/entertainment, VR/AR, gaming
- Tools/workflows: plug-ins for video editors or game engines (e.g., Adobe After Effects, Blender, Unity/Unreal) that take a stereo image pair and a specified camera trajectory to synthesize consistent left–right stereo videos without depth estimation or inpainting
- Assumptions/dependencies: calibrated/rectified stereo input; known or estimated intrinsics/extrinsics for camera control; offline GPU resources; VR output targets (e.g., VR180/side-by-side) rather than full 6DoF
- Faster, higher–fidelity stereo conversion pipelines for post-production
- Sectors: media/entertainment, advertising
- Tools/workflows: replace multi-stage depth-estimate/warp/inpaint chains with StereoWorld’s end-to-end stereo generation for sequence extension, reframing, or stylized camera moves
- Assumptions/dependencies: access to stereo stills or short stereo clips (or capture from stereo rigs); acceptable offline latency; color/tonal consistency benefits are maximized when inputs are well-exposed and rectified
- Pre-visualization and virtual cinematography with precise camera control
- Sectors: film, episodic TV, games
- Tools/workflows: storyboard and previz tools that preview stereo camera moves (dolly/track/orbit) over a captured stereo plate; directors and DP teams can iterate on camera paths and see stereo outcomes quickly
- Assumptions/dependencies: camera trajectories authored by users; not interactive head-tracked rendering; domain alignment to plate imagery
- Data augmentation and benchmarking for binocular vision research
- Sectors: academia (computer vision), R&D labs
- Tools/workflows: generate diverse, geometry-consistent stereo videos from stereo images to augment datasets for stereo matching, disparity estimation, or geometry-aware video tasks; use disparity-consistent outputs to probe algorithms
- Assumptions/dependencies: acknowledge generative data bias; maintain separation between training and evaluation content to avoid leakage
- Off-policy rollout generation for embodied AI training (stereo world model as a simulator)
- Sectors: robotics, embodied AI
- Tools/workflows: use camera-conditioned stereo predictions to create training rollouts for policy learning, especially where metric-scale depth is needed (e.g., navigation, grasping with stereo rigs)
- Assumptions/dependencies: offline training (not real-time inference); requires calibrated baselines for metric depth from disparity; sim-to-real gap must be managed
- VR/AR experience prototyping for HMDs and smart glasses
- Sectors: VR/AR product design
- Tools/workflows: rapidly prototype binocular visuals and motion cues for user studies (e.g., motion comfort assessment) from a stereo still and designed camera path
- Assumptions/dependencies: content displayed as pre-rendered stereo video; latency constraints for live XR do not apply
- Consumer “3D moving photos” from dual‑camera devices
- Sectors: consumer apps, social media
- Tools/workflows: mobile/cloud apps that turn a stereo photo (e.g., from dual-lens smartphones or VR180 cameras) into short 3D stereo clips with smooth camera motion
- Assumptions/dependencies: rectified/near-rectified input; likely cloud inference due to model size; guardrails for artifact detection
- Teleoperation/remote inspection training content
- Sectors: industrial robotics, energy, infrastructure inspection
- Tools/workflows: produce stereo prediction sequences simulating expected views for varying camera maneuvers to train operators or validate UI designs
- Assumptions/dependencies: non–real-time playback acceptable; requires matching the capture domain (e.g., indoor plants, outdoor substations)
Long-Term Applications
These applications require further research, optimization, domain adaptation, or ecosystem changes before widespread deployment.
- Real-time, interactive 6DoF stereo rendering for VR/AR
- Sectors: VR/AR, gaming
- Potential products: lightweight/distilled stereo world models integrated into game engines to render left/right views on-the-fly under head pose changes
- Assumptions/dependencies: substantial speedups (quantization, distillation, caching); low-latency pipelines; wider-baseline training data; safety/comfort validation
- On-robot model-predictive control and forecasting with stereo world models
- Sectors: robotics, drones, autonomous systems
- Potential products: onboard prediction modules that anticipate stereo observations for obstacle avoidance and planning under commanded motions
- Assumptions/dependencies: tight latency (<50 ms) and power budgets; robust generalization; integration with SLAM/IMU; fail-safes for prediction errors
- Generative stereo video compression and streaming
- Sectors: video codecs, streaming platforms
- Potential products: “decoder-side generation” where seeds, camera paths, and compact conditioning are transmitted and stereo frames are synthesized client-side
- Assumptions/dependencies: codec standardization, reliable client inference, perceptual quality guarantees, content authenticity labels
- Multi-sensor fusion world models (stereo + IMU/LiDAR)
- Sectors: robotics, automotive, AR navigation
- Potential products: fused models that jointly condition on stereo, inertial signals, and sparse depth for robust, long-horizon geometry-consistent predictions
- Assumptions/dependencies: new training corpora with synchronized sensors; architectures that preserve StereoWorld’s geometric priors while fusing complementary signals
- Domain-specific medical applications (e.g., stereo endoscopy guidance)
- Sectors: healthcare
- Potential products: predictive stereo visualization to stabilize views during camera maneuvers or to preview trajectories for training
- Assumptions/dependencies: domain-specific training, small baselines and challenging textures, regulatory approval, clinical validation
- Safety analysis and “what-if” scenario generation for autonomous vehicles
- Sectors: automotive, policy/safety
- Potential products: simulation tools that produce binocular sequences under alternate camera paths or maneuvers to evaluate perception robustness
- Assumptions/dependencies: high-fidelity domain alignment, scenario coverage, integration with ground-truth simulators, standardized evaluation protocols
- Standards and policy for camera-conditioned stereo content
- Sectors: policy/regulation, industry consortia
- Potential outputs: metadata standards (intrinsics/extrinsics/baselines) for interoperable stereo content; guidelines for synthetic content disclosure and VR comfort
- Assumptions/dependencies: cross-industry collaboration (hardware vendors, platforms), alignment with codec/container standards, user safety research
- Personalized spatial memories and explorable 3D capture
- Sectors: consumer hardware/software
- Potential products: capture apps that turn a quick stereo snapshot into an explorable short stereo “walkthrough” with user-driven camera paths
- Assumptions/dependencies: on-device acceleration or efficient cloud; robust handling of challenging scenes; privacy-preserving processing
- Training-time accelerators for stereo/multi-view foundation models
- Sectors: AI infrastructure, academia
- Potential outputs: adoption of stereo-aware row attention and unified camera-frame RoPE in broader multi-view models to reduce compute while improving geometric consistency
- Assumptions/dependencies: integration into popular backbones, reproducibility across domains, availability of multi-baseline datasets
- Long-horizon interactive stereo generation via distillation
- Sectors: media tech, VR platforms
- Potential products: stereo-capable “world engines” that enable extended, user-steered camera paths (e.g., minutes-long sequences) by distilling from long-video monocular models
- Assumptions/dependencies: scalable distillation pipelines, memory-efficient inference, drift mitigation, safeguards for content stability
Notes on feasibility dependencies across applications:
- Calibration and rectification: Achieving metric depth from disparity requires known baseline and focal length; cross-device variability must be handled.
- Compute and latency: Current diffusion backbones are heavy; most real-time or interactive uses require compression/distillation.
- Generalization and domain shift: Performance benefits are strongest when training and deployment domains align; specialized domains (medical, AV) require dedicated data.
- UX and safety: VR/AR uses must address comfort (e.g., vergence–accommodation conflicts, motion sickness); policy sectors need transparency and content labeling.
- Data rights and privacy: Generative pipelines for consumer and enterprise footage must respect licensing and privacy constraints.
Glossary
- 3D Variational Autoencoder (VAE): A variational autoencoder extended to encode and decode spatiotemporal video volumes into compact latent representations. "consisting of a 3D Variational Autoencoder (VAE) ~\cite{kingma2013auto} and a Transformer-based diffusion model (DiT)~\cite{peebles2023scalable}."
- 4D attention: Full spatiotemporal cross-view self-attention over tokens arranged across time, height, width, and view dimensions. "full 4D spatiotemporal cross-view attention quickly becomes infeasible."
- 6DoF extrinsics: Six-degree-of-freedom camera pose parameters (3D rotation and translation) used as extrinsic calibration. "injects 6DoF extrinsics into diffusion models"
- Baseline (stereo): The fixed distance between the left and right cameras in a stereo rig, which determines parallax/disparity. "with baseline "
- Binocular geometry: The geometric relationships derived from two synchronized camera views that enable depth perception. "jointly learns appearance and binocular geometry"
- Camera-aware rotary positional encoding: A positional encoding that incorporates camera parameters into RoPE to condition attention on viewpoint relations. "camera-aware rotary positional encoding"
- Camera extrinsics: External camera parameters (pose) mapping from world to camera coordinates. "where and are the intrinsic and extrinsic respectively"
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) defining the projection model. "where and are the intrinsic and extrinsic respectively"
- CLIP-V: A CLIP-based metric measuring cross-domain alignment between generated and target video frames over time. "denoted CLIP-V \citep{CVD}"
- DiT (Diffusion Transformer): A Transformer backbone used within diffusion models to iteratively denoise latent representations. "a Transformer-based diffusion model (DiT)~\cite{peebles2023scalable}"
- Disparity: The horizontal pixel shift between corresponding points in stereo images, inversely related to depth. "grounding geometry directly from disparity."
- Embodied intelligence: AI systems that perceive and act within environments using sensorimotor feedback. "as well as action planning in embodied intelligence."
- Epipolar lines: Lines in stereo image pairs along which corresponding points must lie, typically horizontal in rectified pairs. "in rectified stereo pairs the epipolar lines align horizontally"
- Epipolar prior: The prior knowledge that stereo correspondences lie along epipolar lines, used to constrain attention/computation. "leveraging the epipolar prior to capture disparity-aligned correspondences with substantially lower compute."
- Fréchet Image Distance (FID): A distributional metric comparing generated and real images via feature statistics. "Fréchet Image Distance (FID) \citep{fid}"
- Fréchet Video Distance (FVD): A distributional metric comparing generated and real videos via spatiotemporal feature statistics. "Fréchet Video Distance (FVD) \citep{fvd}"
- Kronecker product: A matrix operation producing a block matrix, used here to combine camera and positional encodings. "Here , is the Kronecker product"
- Latent diffusion model: A diffusion generative model operating in a learned latent space rather than pixel space for efficiency. "we adopt a latent diffusion model ~\cite{blattmann2023align}"
- Long-video distillation: Transferring knowledge from long-horizon monocular generation models into the stereo model to support extended synthesis. "compatible with long-video distillation for extended interactive stereo synthesis."
- M-RoPE: A multi-axis variant of RoPE that factorizes rotations along temporal and spatial axes for video. "recent RoPE variants (e.g., M-RoPE in Qwen2-VL~\cite{wang2024qwen2})"
- Metric-scale geometry: Depth/geometry that is grounded to real-world scale (not just up-to-scale). "StereoWorld incorporates metric-scale geometry,"
- Pl{\"u}kcer Ray encodings: A camera-ray representation (Plücker coordinates) concatenated to features to encode viewing geometry. "concatenates Pl{\"u}kcer Ray encodings~\cite{zhang2024cameras}"
- PRoPE: A camera-conditioned RoPE variant that injects relative camera information into rotational positional encoding. "Specifically, PRoPE replaces"
- Ray-map concatenation: Conditioning by concatenating per-pixel camera ray features to the input channels. "Ray-map concatenation~\cite{gao2024cat3d, Team2025AetherGU} encodes absolute coordinates"
- Rectified flow formulation: A training objective for diffusion that reformulates the denoising process to improve efficiency/stability. "following the rectified flow formulation~\cite{esser2024scaling}"
- Rectified stereo pair: A stereo image pair pre-warped so corresponding epipolar lines are aligned (typically horizontal). "Given a rectified stereo pair"
- RoPE (Rotary Positional Encoding): A positional encoding that rotates query/key vectors to encode relative positions directly in attention. "Vanilla RoPE~\cite{su2024roformer} encodes relative positions"
- Row attention: Attention restricted to horizontally aligned tokens (scanlines) to enforce epipolar constraints efficiently. "horizontal row attention"
- Stereo-aware attention: An attention mechanism tailored to stereo geometry, decomposing spatiotemporal and cross-view interactions. "a stereo-aware attention mechanism (Sec. \ref{sec:stereo_attention})"
- Stereo world model: A generative model that jointly predicts future stereo observations conditioned on actions/camera motion. "a stereo world model capable of performing exploration based on given binocular images"
- Unified camera-frame RoPE: A RoPE design that augments the latent token space with a separate camera-conditioned subspace while preserving pretrained priors. "a unified camera-frame RoPE that augments latent tokens with camera-aware rotary positional encoding"
- VBench: A benchmark suite of automatic metrics for evaluating video generation quality and consistency. "standard VBench metrics \cite{vbench}"
- Viewpoint consistency: The degree to which generated views remain geometrically coherent across viewpoints. "with an additional gain in viewpoint consistency."
- VR/AR visualization: Rendering outputs suitable for virtual/augmented reality display, often requiring binocular consistency. "VR/AR visualization"
- Warping and inpainting: A two-stage process that reprojects content using depth (warping) and fills missing regions (inpainting). "followed by warping and inpainting operations in the latent space."
Collections
Sign up for free to add this paper to one or more collections.

