StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Abstract: Stereo cameras closely mimic human binocular vision, providing rich spatial cues critical for precise robotic manipulation. Despite their advantage, the adoption of stereo vision in vision-language-action models (VLAs) remains underexplored. In this work, we present StereoVLA, a VLA model that leverages rich geometric cues from stereo vision. We propose a novel Geometric-Semantic Feature Extraction module that utilizes vision foundation models to extract and fuse two key features: 1) geometric features from subtle stereo-view differences for spatial perception; 2) semantic-rich features from the monocular view for instruction following. Additionally, we propose an auxiliary Interaction-Region Depth Estimation task to further enhance spatial perception and accelerate model convergence. Extensive experiments show that our approach outperforms baselines by a large margin in diverse tasks under the stereo setting and demonstrates strong robustness to camera pose variations.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces StereoVLA, a robot control model that uses both images and text to decide what actions a robot should take. Its big idea is to use a stereo camera (two cameras side by side, like human eyes) so the robot can understand depth and 3D space much better. This helps the robot pick up and move objects more accurately, even in tricky situations.
Key Objectives
The researchers wanted to answer three simple questions:
- Can adding stereo vision (two cameras) make robot models that use vision and language better at doing tasks?
- Which camera setup (single camera, stereo, front + side, front + wrist) works best in real life?
- Which parts of their new design actually make the biggest difference?
How They Did It
The main idea, in everyday terms
Think of the model as having two kinds of “eyes”:
- One kind focuses on precise 3D shape and distance (geometry).
- The other recognizes what things are and what they mean (semantics), which helps follow written instructions like “Pick up the red pen.”
StereoVLA combines both kinds of vision so the robot knows both “what” and “where” very well.
The approach, step by step
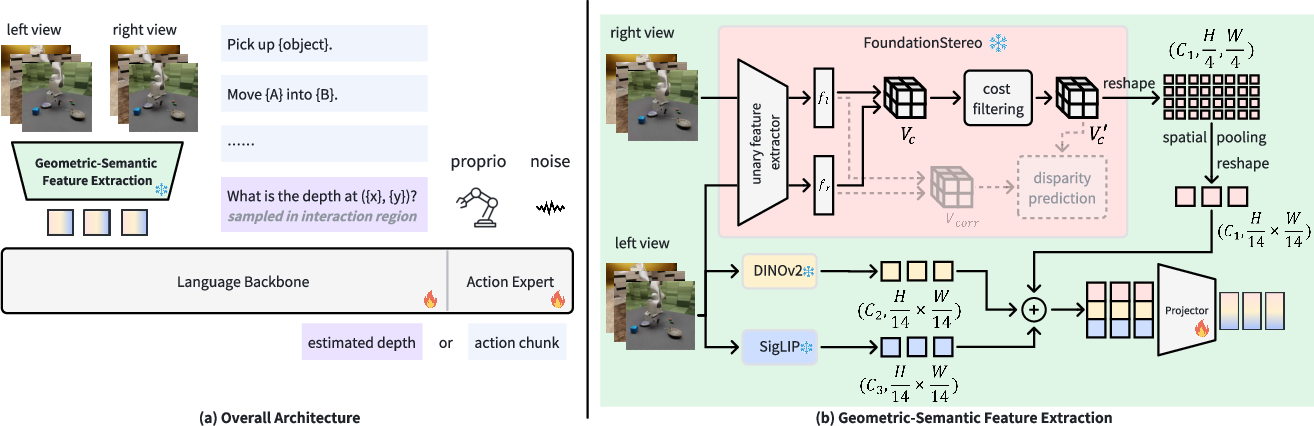
Here’s how StereoVLA works:
- It takes two images at the same time (left and right), like your two eyes do, to sense depth.
- It extracts geometry features (depth and 3D cues) from a stereo vision model called FoundationStereo. Think of this as building a detailed “distance map” across the scene.
- It extracts semantic features (what objects are and visual details) from strong image-LLMs (SigLIP and DINOv2) on just the left image to save time.
- It fuses the geometry and semantic features together so the robot gets “hybrid” visual tokens—compact information chunks that carry both depth and meaning.
- It uses a LLM backbone to combine the visual tokens with the instruction text (like “Place the bowl on the plate”).
- It trains an “action expert” that turns this combined information into smooth robot movements (how to move the gripper in small steps).
A smart training trick
They add an extra training task: predict the depth of points only in the “interaction region,” meaning the area around the robot gripper and the target object. This is like telling the robot, “Pay attention right where your hand meets the thing you need to grab,” so it learns the most useful 3D details faster.
Data and testing
- Because big public robot datasets don’t include stereo pairs, they generated 5 million synthetic (simulated) pick-and-place examples using MuJoCo and Isaac Sim.
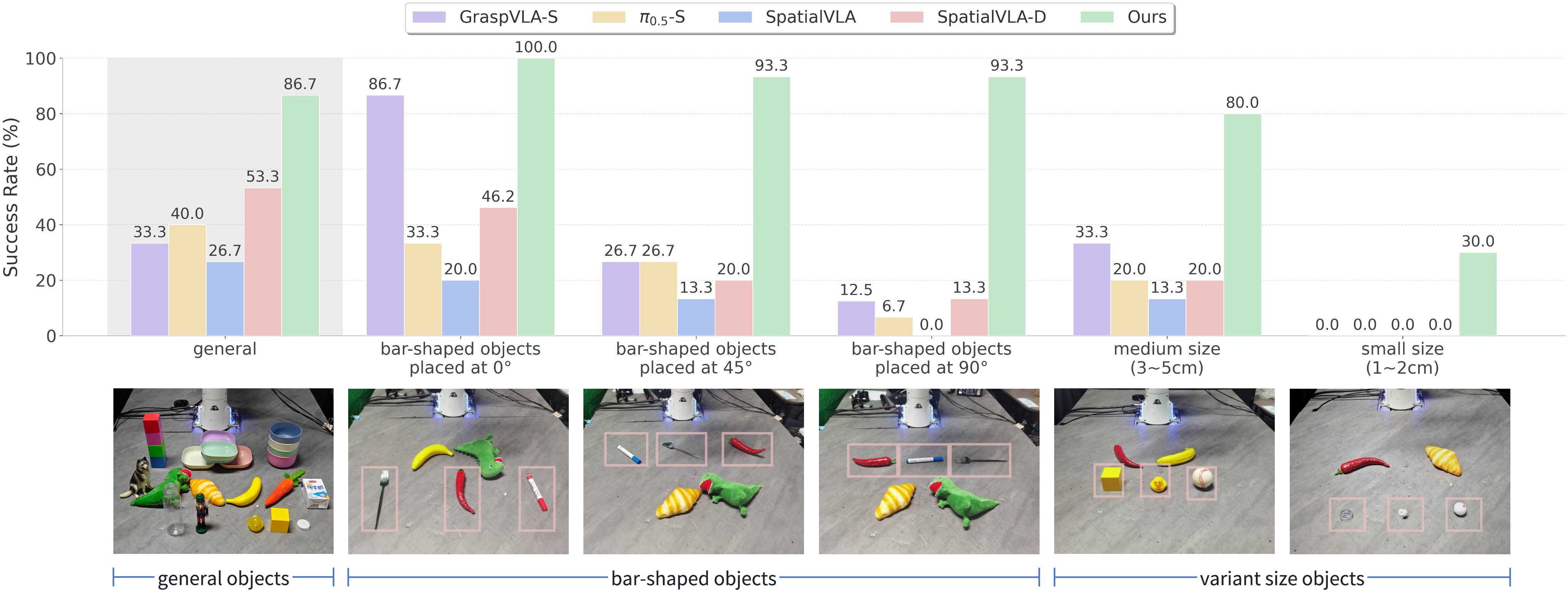
- They tested the model on real robots, trying tasks like grasping long bar-shaped objects (pens, forks) at different angles, picking small objects (1–2 cm), and general pick-and-place tasks.
Main Findings and Why They Matter
Here are the most important results:
- StereoVLA beat other strong baseline models across many tasks when using stereo cameras, with about 33% higher success rates in general tasks and big gains in precision tasks.
- It was much better at grasping long objects at different angles (0°, 45°, 90°) and succeeded even when objects visually overlapped with the gripper.
- It was the only model to get notable success on very small objects, even with only one try allowed (others failed completely).
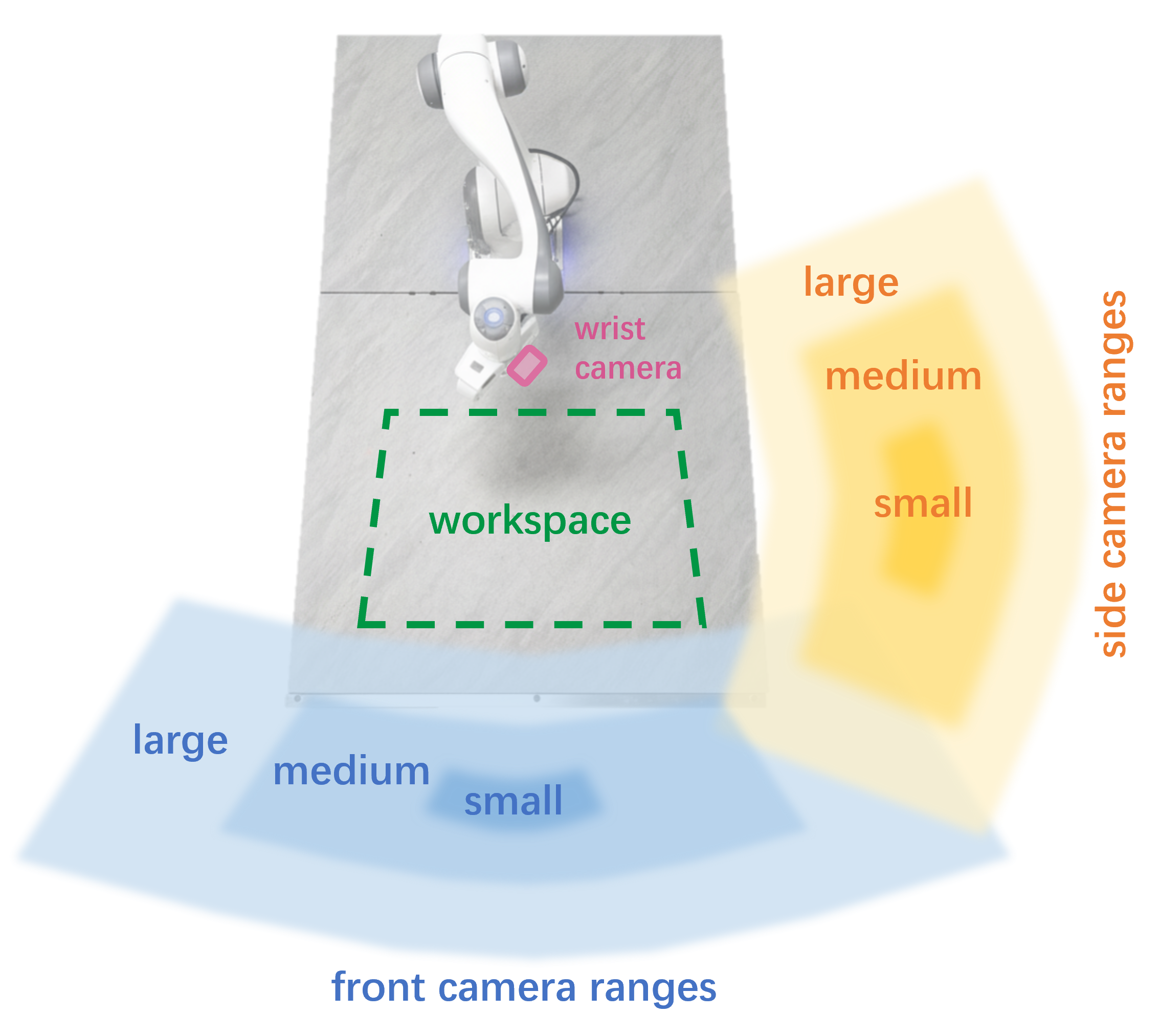
- It stayed robust when camera positions changed a lot, showing it can handle real-world set-ups where cameras won’t always be in the same spot.
- Design ablations (experiments that remove or swap parts) showed:
- Using the “filtered cost volume” from FoundationStereo (a dense 3D feature representation) worked best for geometry.
- Adding semantic features (SigLIP + DINOv2) reduced mistakes like grabbing the wrong object.
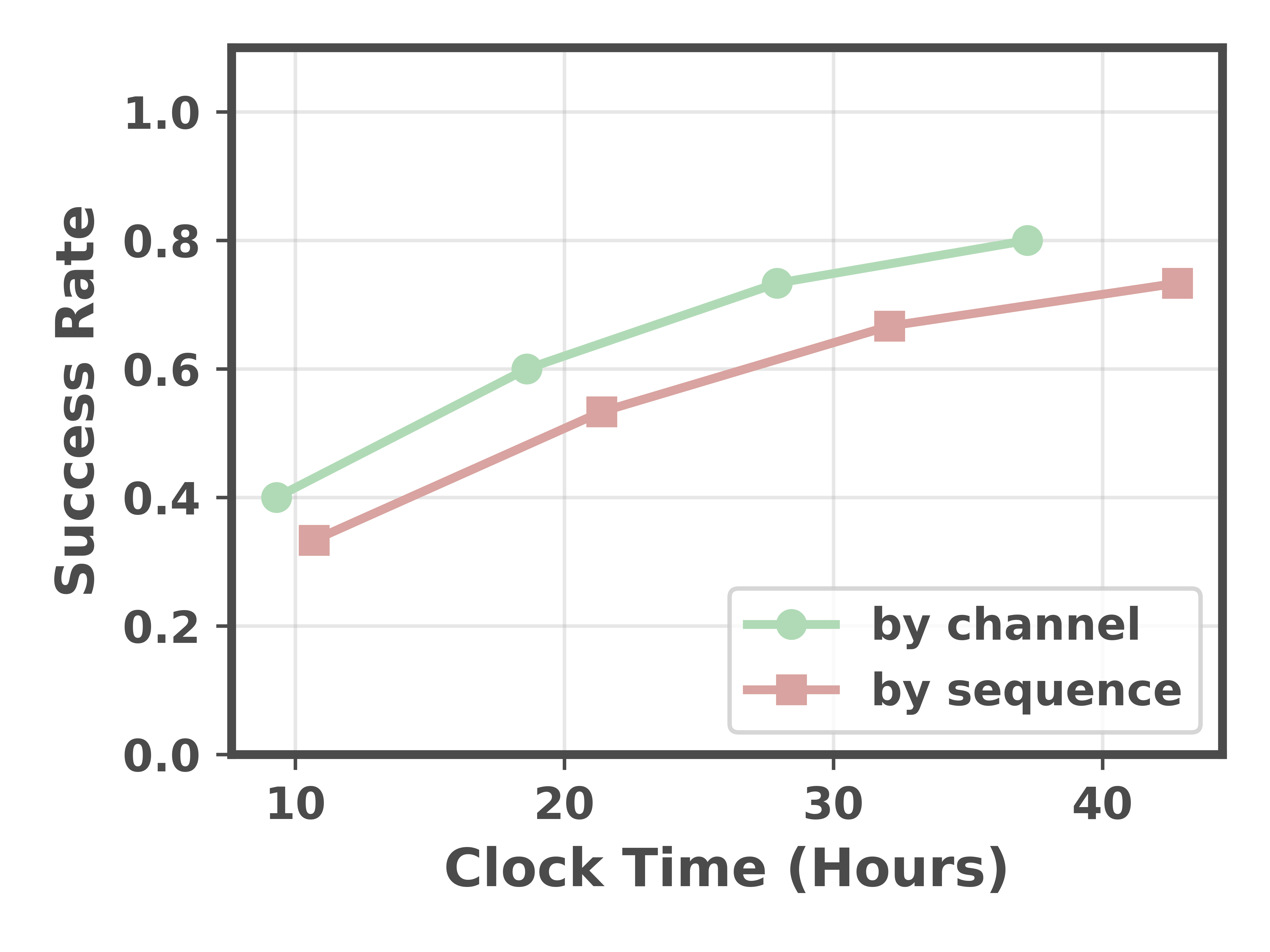
- Fusing features by channel (not by doubling token sequences) was both faster and more accurate.
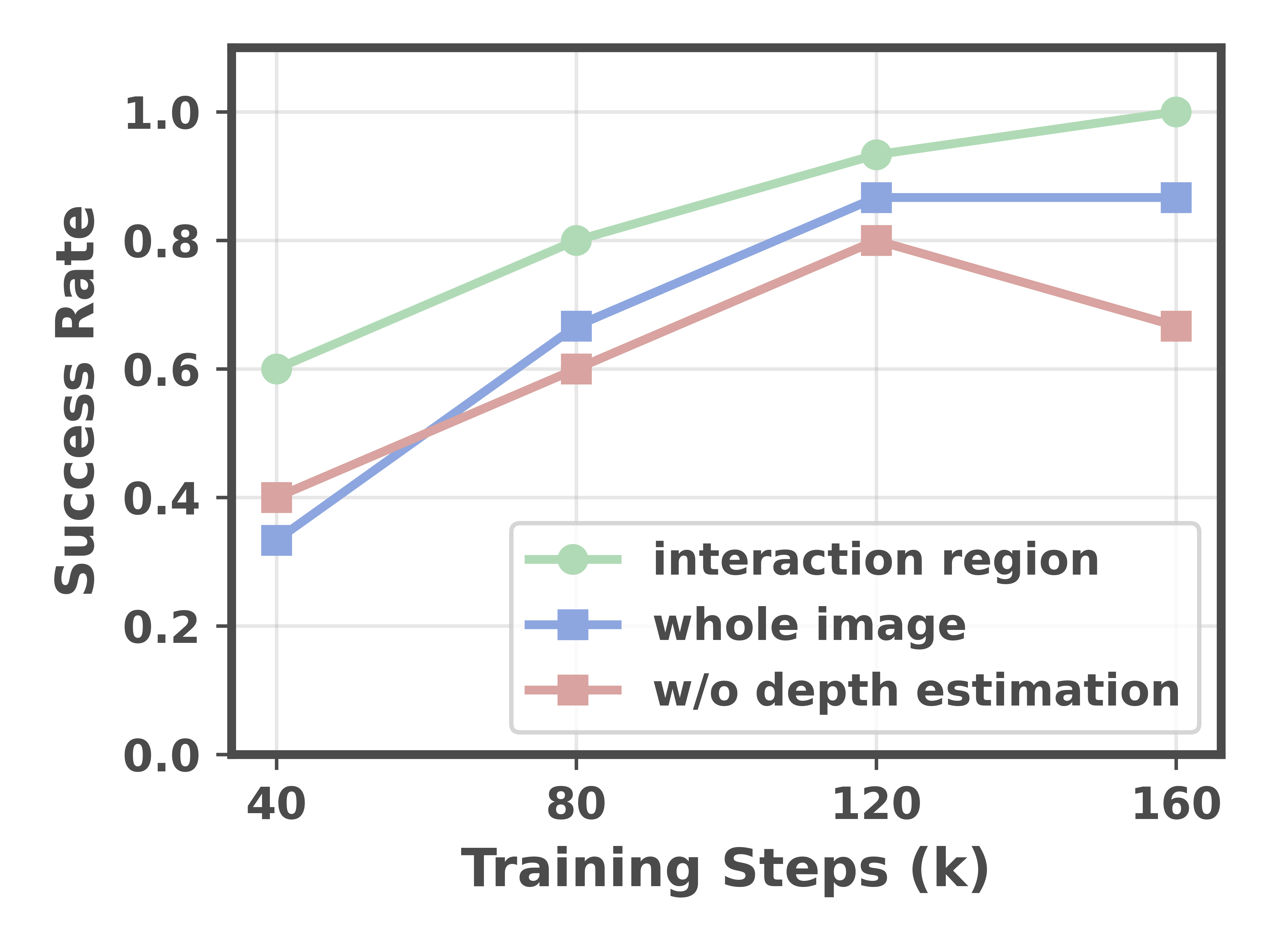
- Predicting depth in the interaction region improved learning speed and final performance compared to predicting depth anywhere in the image.
Why this matters: Robots need both “what” and “where.” StereoVLA proves that mixing stereo-based depth (where) with strong semantic understanding (what) makes manipulation more reliable, especially for tight, precise tasks.
Implications and Potential Impact
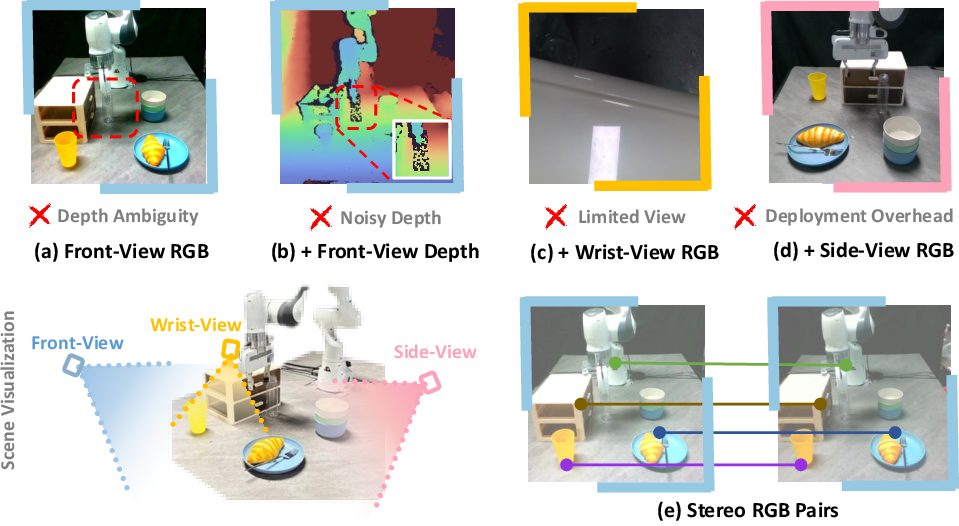
- Practical setups: A single stereo camera can give great 3D understanding without needing extra cameras or bulky wrist-mounted gear. That means simpler hardware and fewer problems with occlusion or collisions.
- Better precision: Tasks that demand fine control—like picking up small or thin objects—become much more doable.
- More robust robots: Since StereoVLA handles camera changes well, it’s easier to deploy in different places, robots, or rooms without carefully re-aligning cameras.
- Future directions: The authors note that higher image resolution could help even more with tiny objects, and learning longer action sequences could enable more complex tasks. The approach isn’t tied to a single robot, so it can be applied widely.
Overall, StereoVLA shows that bringing human-like stereo vision into vision-language-action models gives robots stronger spatial understanding and better performance in the real world.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of what the paper leaves missing, uncertain, or unexplored, framed as concrete and actionable directions for future research.
- Small-object manipulation is underperforming due to 224×224 input resolution; the benefits, compute costs, and latency impacts of higher-resolution backbones (e.g., ViT-L/ViT-H, SigLIP large variants) and multi-scale feature pyramids remain unquantified.
- The model does not model long-horizon temporal dependencies; it is unclear how adding temporal stereo sequences (video) or recurrent/transformer temporal modules would affect planning, regrasping, and multi-step tasks.
- Generalization beyond a single embodiment (Franka) is untested; performance across different arms, grippers (parallel-jaw vs. multi-finger), and mobile/humanoid platforms is unknown.
- Real training relies on synthetic stereo data for auxiliary depth supervision; the sim-to-real transfer mechanisms (domain randomization coverage, photorealism, material/lighting variability) and their impact on geometry and semantic grounding are not analyzed.
- Stereo performance on transparent, specular, textureless, and low-light objects—where stereo and classical matching often fail—was not evaluated, despite being a stated motivation for stereo over commodity depth sensors.
- Robustness to stereo-specific failure modes (calibration drift, lens distortion, rolling-shutter mismatch, inter-camera desynchronization, baseline changes, and occlusions of one lens) is not characterized.
- The sensitivity of performance to stereo baseline length and intrinsic calibration (beyond the ±5% randomization used in sim) is unknown; optimal baselines for different workspace sizes and depth ranges are not studied.
- Semantic features are extracted only from the left view; the utility of binocular semantic encoding (both views), viewpoint-conditioned semantics, or cross-view semantic consistency is unexplored.
- Feature fusion is limited to channel-wise concatenation; alternatives such as cross-attention between semantic and geometric tokens, learned alignment with deformable attention, late fusion, or 3D-aware tokenization (e.g., cost-volume-to-token transformers) are not examined.
- FoundationStereo features appear to be used without end-to-end fine-tuning within the policy; the trade-offs between freezing vs. fine-tuning (or adapter-based tuning) on robot data, in terms of accuracy, convergence speed, and compute, are not reported.
- The interplay between stereo-derived geometry and different policy heads (diffusion vs. flow matching vs. autoregressive) is not investigated; it is unknown whether geometry helps one class of policy architectures more than others.
- The auxiliary depth estimation uses discretized depth with cross-entropy loss; the effects of regression losses, uncertainty-aware losses, ordinal/relative depth objectives, or self-supervised photometric consistency in real data are not studied.
- Interaction-Region Depth Estimation depends on accurate 2D bounding boxes; error propagation from mislocalized boxes to depth supervision and subsequent action prediction is not quantified.
- No explicit 3D scene representation (point clouds, voxel grids, NeRFs) is constructed; whether explicit 3D reconstruction or hybrid 2D–3D policies would improve small-object or cluttered-scene manipulation remains open.
- Real-time constraints (inference latency, throughput on edge hardware, memory footprint), especially when adding stereo geometric encoders, are not reported; deployment feasibility on onboard compute is unclear.
- Task diversity is limited (pick-and-place, grasping bars, small/medium objects); performance on deformable objects, articulated parts, dynamic targets, heavy clutter, and occlusion-heavy scenes is unknown.
- Closed-loop servoing vs. chunked open-loop control is not compared; potential gains from integrating continuous perception-action feedback using stereo cues are untested.
- Camera-setting comparison focuses on fixed, passive cameras; active perception (moving cameras, eye-in-hand stereo) or hybrid configurations (stereo + wrist monocular) could improve occlusion handling but are not explored.
- The effect of multi-task sampling ratios (5:2:2:1 for action/depth/bbox/pose) on convergence, stability, and final performance is not ablated; adaptive weighting or curriculum strategies remain unexplored.
- Robustness to extreme camera pose variations is only evaluated for three ranges; distributions beyond cuboid shells, sudden viewpoint shifts, and significant height changes (e.g., mobile robots) are not assessed.
- The claim that stereo reduces deployment overhead relative to multi-camera setups is not supported by a cost-benefit analysis (hardware complexity, calibration effort, wiring, maintenance, failure modes).
- Failure mode analysis is limited; systematic categorization of errors (early gripper closing, mislocalization, wrong-object grasps) and their correlation with geometry/semantic token qualities is missing.
- The contribution of GRIT-based bounding-box pretraining to real manipulation performance (vs. domain-specific detection training or segmentation) is not isolated.
- Safety and contact dynamics (gripper force control, compliance, slip detection) are not integrated into the policy; whether stereo improves contact-rich manipulation or reduces failure rates under force constraints is unknown.
- Generalization across language instructions (compositional commands, distractors in language, ambiguous references) with stereo grounding is not benchmarked beyond simple pick-and-place cues.
- Comparative fairness in camera-setting experiments could be improved by testing multi-view models explicitly designed for unaligned views (e.g., learned multi-view alignment modules), to isolate stereo-vs.-multi-view effects more cleanly.
- The benefit of incorporating right-view semantics may become critical under left-view occlusion; occlusion-aware semantic extraction and fusion policies are not tested.
- The effect of larger language backbones or stronger VLMs (e.g., Qwen2.5-VL, Florence-2) on geometry–language integration is unreported.
- The method’s applicability to outdoor, variable lighting, and high-dynamic-range environments is not examined; stereo performance under these conditions is uncertain.
Practical Applications
Below is an overview of practical applications that follow directly from the paper’s findings and methods. The items are grouped by deployment horizon, annotated with sectors, and include concrete tools/products/workflows plus key assumptions or dependencies that may affect feasibility.
Immediate Applications
The following use cases can be built now by adapting the StereoVLA recipe (single stereo camera, Geometric–Semantic Feature Extraction, and interaction-region depth co-training), fine-tuning on task-specific data, and integrating into standard robot stacks.
- Precision pick-and-place with a single stereo camera (manufacturing, logistics)
- What: Replace wrist or multi-camera rigs with one calibrated stereo pair for kitting, bin-picking of medium-sized parts, and grasping bar-shaped items (e.g., pens, brushes, screwdrivers) on benches or in totes.
- Why: Demonstrated gains in precision and robustness to camera pose; fewer occlusions vs wrist cams; more reliable than commodity RGB-D on reflective/transparent packaging.
- Tools/workflows: ROS 2 nodes for camera drivers and
StereoVLAinference; CAD-free cell setup using a calibrated stereo bar; plant-specific fine-tuning with a synthetic-to-real bootstrapping pipeline (Isaac Sim) plus short real calibration runs; PLC integration via action servers. - Assumptions/dependencies: Good stereo calibration and synchronized capture; sufficient texture for disparity; GPU for VLM+policy inference; safety interlocks; 224×224 input limits tiny-object accuracy—use task-tuned crops or higher-res encoders if needed.
- Tote-based e-commerce picking and returns processing (logistics, retail)
- What: Language-conditioned picking (e.g., “pick the blue toothbrush and place into slot B”) from cluttered totes or returns bins.
- Why: Hybrid geometric–semantic tokens reduce false grasps of distractors; stereo setup simplifies rigging on mobile manipulators.
- Tools/workflows: SKU-specific prompt templates; light domain adaptation on warehouse objects; shelf/tote coordinate registration; error logging with single-attempt success KPIs as in the paper’s evaluation protocol.
- Assumptions/dependencies: Adequate lighting and texture for stereo; periodic re-calibration; on-prem inference to minimize latency.
- Shelf restocking and front-facing tasks (retail, facilities)
- What: Restock, face, or reorganize products on shelves and pegboards using one stereo camera mounted on the robot mast.
- Why: Stereo reduces depth ambiguity on narrow items and mitigates occlusion vs wrist cams.
- Tools/workflows: “Front+stereo” rig retrofit kit; geometric-semantic tokenizer module as a drop-in for existing VLA stacks; store planogram prompts.
- Assumptions/dependencies: Variable shelf geometry and lighting; updated prompts for new planograms.
- Lab bench assistants for routine handling (R&D labs, biotech)
- What: Grasp and place common lab items (tubes, bottles, pipette boxes) on benchtops; language-directed rearrangement.
- Why: Single stereo camera simplifies containment-friendly setups and avoids active depth failures on clear plastics.
- Tools/workflows: Bench coordinate frames; dataset bootstrapping with digital twins (Isaac Sim) of benches and racks; task scripts that chain bounding-box → keyframe → action chunks, as in the training flow.
- Assumptions/dependencies: Transparent, low-texture objects may still challenge stereo—use fiducial labels, patterned trays, or polarized lighting to improve disparity when needed.
- Field maintenance of panels, switches, and meters (energy, utilities)
- What: Manipulate toggles/knobs and handle slender tools in substation rooms or plants using one stereo pair.
- Why: Better depth near metallic/specular surfaces than many RGB-D sensors; simpler deployment than multi-view rigs.
- Tools/workflows: Pre-visit photos to seed synthetic domain randomization; safety-rated motion constraints; language prompts tied to maintenance SOPs.
- Assumptions/dependencies: EMI-hardening for cameras; compute budget on edge (Jetson AGX Orin or similar) or via tether.
- Robot integrator kit: “Geometric–Semantic Tokenizer” and co-training head (software)
- What: Package the proposed feature extractor (FoundationStereo cost-volume features + SigLIP/DINOv2) and interaction-region depth auxiliary loss as a reusable library.
- Why: Immediate lift-and-shift for any VLA stack (OpenVLA, π0.5-style, GraspVLA) to exploit stereo without rewriting policies.
- Tools/workflows: PyTorch modules for channel-wise feature fusion; training recipe with multi-task sampling ratios (5:2:2:1) and interaction-region sampling; camera-pose randomization harness from the paper.
- Assumptions/dependencies: Access to FoundationStereo, SigLIP, DINOv2 checkpoints and licenses; GPU memory sized for the fused token dimensionality.
- Camera configuration benchmarking and selection (academia, robotics teams)
- What: Use the paper’s protocol to compare single-view, front+side, front+wrist, and stereo rigs for a given task budget.
- Why: Quantified robustness to pose randomization; helps pick the simplest rig that meets KPIs.
- Tools/workflows: Pose-randomized data capture; success-rate tracking with single-attempt criteria; ablation of fusion strategies (sequence vs channel).
- Assumptions/dependencies: Comparable dataset sizes per rig; matched training schedules.
- Training pipeline for stereo robotic data at scale (academia, software)
- What: Replicate the 5M-trajectory synthetic pipeline (MuJoCo control + Isaac Sim stereo rendering) to pretrain internal models.
- Why: Lack of public stereo datasets; pipeline closes the data gap quickly.
- Tools/workflows: Domain randomization of stereo intrinsics/extrinsics; automatic interaction-region labeling; co-training with GRIT-like grounding data.
- Assumptions/dependencies: Synthetic-to-real gap management; rendering throughput and storage; curation for long-horizon variants if needed.
- Assistive mobile manipulation in structured homes (daily life, healthcare)
- What: Pick up and place everyday objects on tables/counters in relatively uncluttered settings using one stereo camera.
- Why: Lower hardware complexity for home robots; language-directed commands for accessibility.
- Tools/workflows: Household object vocabularies; safety zones and velocity limits; user confirmation prompts for critical actions.
- Assumptions/dependencies: Performance on very small objects remains limited at 224×224; careful user-in-the-loop designs for safety.
- Curriculum and coursework modules on geometric-semantic fusion (academia, education)
- What: Course labs demonstrating stereo cost-volume features fused with language-grounded tokens for embodied tasks.
- Why: Clear, reproducible ablations (Vcorr vs Vc vs Vc′; fusion strategies) make strong teaching examples.
- Tools/workflows: Colabs with subset datasets and pretrained feature extractors; evaluation under pose randomization.
- Assumptions/dependencies: Compute quotas for students; simplified action spaces for classroom settings.
Long-Term Applications
These require additional research, scaling (e.g., higher image resolution, multi-embodiment training), productization, or regulatory clearance.
- Micro-assembly and small-object manipulation at scale (manufacturing, electronics)
- What: Pick/place sub-centimeter components, cable routing, and connector insertion with high reliability.
- Why: The paper notes current limits on small objects at 224×224; moving to higher-res backbones and optics plus refined interaction-region supervision can unlock micro-precision.
- Dependencies: High-resolution stereo sensors and encoders; efficient inference (quantization/distillation) to meet cycle times; robust ESD-safe grippers.
- Pharmacy and hospital automation of small/clear items (healthcare)
- What: Handling blister packs, ampoules, vials, and syringes with safety and traceability.
- Why: Stereo may outperform time-of-flight sensors around clear/reflective containers; language-conditioned workflows simplify SKU proliferation.
- Dependencies: Regulatory validation; improved disparity on low-texture transparent objects (e.g., patterns, polarization, active IR texture); strict audit logs.
- Minimally invasive surgical manipulation with stereo endoscopes (healthcare, surgical robotics)
- What: Language- and vision-guided suturing/grasps using laparoscopic stereo feeds.
- Why: Natural fit for stereo inputs; interaction-region depth objective aligns with instrument–tissue focus.
- Dependencies: Real-time, fail-safe control; clinical validation; dataset curation with stringent privacy/ethics; explainability and shared autonomy.
- Mobile manipulation in homes and offices with broad generalization (daily life, service robotics)
- What: Generalist household robots that tidy, set tables, and operate appliances from diverse viewpoints.
- Why: Paper shows strong robustness to camera pose variation; scaling to many embodiments and long-horizon tasks remains to be done.
- Dependencies: Long-horizon temporal reasoning; memory; navigation–manipulation coupling; safety and reliability standards for consumer deployment.
- Autonomous field harvesting and sorting (agriculture)
- What: Fruit/vegetable picking and packhouse sorting where surfaces are glossy or wet.
- Why: Passive stereo may be safer around sunlight than some active depth modalities; interaction-focused depth helps precise detachment cuts and gentle grasps.
- Dependencies: Outdoor lighting variability; domain-adapted stereo features; ruggedized hardware; efficient high-res inference.
- Shared autonomy teleoperation with stereo intent assistance (software, robotics)
- What: Operator issues high-level language commands and provides occasional corrections while the policy executes geometric-precise substeps.
- Why: StereoVLA’s precise grasping of elongated objects is a good substrate for assistive autonomy.
- Dependencies: Low-latency bidirectional comms; human factors and UI; continuous learning with safety guards.
- Standardized stereo-VLA benchmarks and certification protocols (policy, standards)
- What: Test suites that require camera pose randomization, single-attempt success, and reporting under clutter/occlusion and material diversity.
- Why: Paper’s methodology provides a blueprint for more realistic, manipulation-centric metrics.
- Dependencies: Multi-institution datasets; NIST/ISO coordination; seed funding for community curation.
- Environment- and cost-optimized sensing policies (policy, sustainability)
- What: Procurement guidelines favoring passive stereo where it meets task KPIs, reducing reliance on active depth emitters in sensitive environments.
- Why: One stereo rig can replace multiple cameras/sensors; simpler BOM and potentially lower energy/safety overheads.
- Dependencies: Comparative lifecycle and safety studies; facility-specific lighting constraints; occupational safety reviews.
- Edge deployment via model compression and distillation (software, hardware)
- What: Distill the InternLM-1.8B + 300M action head and fused tokens into compact controllers (e.g., 200–500M total) for embedded GPUs.
- Why: Brings precise stereo VLA to cost-sensitive cells and mobile platforms.
- Dependencies: Retaining geometric fidelity under quantization; on-device calibration routines; toolchains for mixed-precision kernels.
- Cross-embodiment foundation control with stereo priors (robotics, academia)
- What: A unified policy that transfers across arms and grippers (industrial, collaborative, humanoid), using stereo to stabilize geometry perception.
- Why: Paper’s robustness to pose suggests stereo as a strong inductive bias for generalization.
- Dependencies: Open X-Embodiment-style datasets augmented with stereo; consistent action abstractions; embodiment adapters.
- Safety-proofed, explainable geometric-language controllers (software, policy)
- What: Policies that output confidence and localized depth rationales (e.g., visualizing interaction-region depth maps) for certification and debugging.
- Why: The auxiliary depth head can be extended to generate human-interpretable spatial justifications.
- Dependencies: UI for introspection; formal methods for runtime monitors; standards for explainability in safety-critical manipulation.
Notes on cross-cutting assumptions and dependencies
- Stereo rig quality: Accurate extrinsics/intrinsics, synchronized shutters, sufficient baseline for the working distance, and periodic auto-check calibration are critical.
- Scene/content limits: Textureless, transparent, or highly specular targets can still challenge passive stereo; mitigation includes textured fixtures, polarization, projected patterning (if allowed), or learned priors with targeted fine-tuning.
- Compute and latency: Real-time inference with fused tokens requires capable GPUs; compression or streaming inference strategies may be needed in production.
- Data and domain adaptation: The paper uses large synthetic datasets; practical deployments benefit from short real-world fine-tunes, pose randomization, and interaction-region supervision tailored to the objects of interest.
- Safety and compliance: One-shot success criteria are informative for evaluation; production systems need retries, fail-safes, and certification processes aligned with sector standards.
Glossary
- AbsRel: Absolute Relative error; a standard metric for evaluating depth estimation accuracy. "VGGT obtains an AbsRel~\cite{absrel} error of 0.4121, whereas FoundationStereo achieves a substantially lower error of 0.0275."
- Action chunks: Short segments of actions output by the policy in blocks rather than single timesteps. "a 300M-parameter action expert predicts action chunks via flow-matching~\cite{flowmatching, pi_0} with a delta end-effector pose representation."
- Attention-based hybrid cost filtering module: An attention-driven module that filters a cost volume to capture long-range stereo correspondences. "the cost volume undergoes an attention-based hybrid cost filtering module, yielding a filtered cost volume with the same dimensions."
- Autoregressive prediction: Generating the next output conditioned on previous outputs in sequence (here, actions token-by-token). "Early systems~\cite{RT2,openvla} generated actions by discretizing continuous control for autoregressive prediction"
- Binocular disparity: Pixel shift between left and right stereo images that encodes scene depth. "stereo vision offers robust spatial cues via binocular disparity"
- Channel-wise concatenation: Fusing feature maps by concatenating along the channel dimension. "Channel-wise concatenation provides both efficiency and performance advantages."
- Correlation volume: A tensor of matching scores between left and right features across disparities. "to generate a correlation volume ."
- Cost volume (4D): A four-dimensional tensor encoding matching costs across disparity hypotheses and spatial locations. "to form a 4D cost volume $V_c \in \mathbb{R}^{C \times \frac{D}{4} \times \frac{H}{4} \times \frac{W}{4}$"
- Delta end-effector pose representation: Representing actions as changes (deltas) in the robot gripper’s pose. "with a delta end-effector pose representation."
- Disparity map: A per-pixel map of disparities between stereo images used to infer depth. "resulting in a final disparity map."
- Egocentric frame: A coordinate frame centered on the robot, used to reduce sensitivity to environment changes. "adopting a robot-centered egocentric frame"
- Flow-based policies: Controllers that generate trajectories by sampling from learned flow models. "adopted diffusion- or flow-based policies to directly sample smooth trajectories."
- Flow matching: A generative modeling technique that learns continuous flows to map noise to data (used here for action prediction). "a 300M-parameter action expert predicts action chunks via flow-matching~\cite{flowmatching, pi_0}"
- Flow-matching loss: The training objective used to learn the flow that generates actions. "where is the flow-matching loss for action chunk prediction"
- FoundationStereo: A stereo depth foundation model providing dense geometric features with strong generalization. "FoundationStereo is tailored for depth estimation with several specialized modules, making feature adaptation to our task non-trivial."
- Geometric-Semantic Feature Extraction: A module that fuses stereo geometric features with semantic features into unified tokens. "we introduce a novel Geometric-Semantic Feature Extraction module."
- Gripper-sticking heuristic: A manual rule that delays or alters gripper actions to mask decision errors. "we disable the ``gripper sticking'' heuristic used in OpenVLA, SpatialVLA, and , since it artificially delays gripper actions and can conceal inaccurate decisions."
- Interaction-Region Depth Estimation: An auxiliary task predicting depth at points within the gripper–object interaction area to sharpen spatial reasoning. "we introduce an auxiliary co-training task, Interaction-Region Depth Estimation, which improves fine-grained geometric understanding while preserving training and inference efficiency."
- Intrinsic matrix: Camera calibration matrix describing focal lengths and principal point used for projection. "the baseline and intrinsic matrix of the stereo camera is configured to randomize within a 5\% range of those of our real Zed Mini camera."
- Key-value cache: Transformer memory of past key/value states used for efficient multimodal processing. "Leveraging the intermediate vision-language features (i.e., the key-value cache), a 300M-parameter action expert predicts action chunks via flow-matching"
- Metric depth: Depth measured in absolute physical units (e.g., meters), not relative or normalized. "predicts the metric depth of given points."
- MLP projector: A multi-layer perceptron used to map fused features into the model’s token space. "then fuses them into a unified visual representation with an MLP projector."
- Point-cloud observations: 3D point sets sensed or reconstructed from depth used for geometry-aware policies. "DP3~\cite{3d-dp} show that leveraging point-cloud observations enhances robustness to lighting and object variations"
- PrismaticVLM: A visually-conditioned LLM providing semantically rich visual tokens. "we further integrate semantically rich visual tokens from PrismaticVLM~\cite{prismatic}."
- RAFT-style iterative refinement: An iterative update paradigm (inspired by RAFT) that refines correspondences without explicit 4D volumes. "to RAFT-style~\cite{raft} iterative refinement~\cite{iterative,li2022practical,jing2023uncertainty,gong2024learning,ral_stereo_depth_raft_style} that avoids explicit 4D volumes while preserving precision."
- Semantic grounding: Linking language references to specific visual entities or regions. "and add 2D bounding box prediction as an auxiliary task to enhance the model's semantic grounding capability."
- SigLIP: A vision-language pretraining method using a sigmoid loss to learn high-level semantic features. "we extract these features using SigLIP and DINOv2 following PrismaticVLM~\cite{prismatic}."
- Spatial pooling: Reducing spatial resolution by aggregating features over neighborhoods to match backbone strides. "We therefore spatially pool the FoundationStereo features to match the 14-pixel stride of the other two."
- Stereo matching: Estimating pixel correspondences (and disparity) between stereo image pairs to recover depth. "Deep stereo matching has evolved from cost-volume aggregation with 3D CNNs~\cite{chen2023learning,cfnet,pcw,aanet,ral_stereo_depth_cost_volume,ral_stereo_depth_cost_volume_2}"
- Unary feature extractor: A per-image feature encoder (as opposed to pairwise or cross-image processing) used before stereo matching. "FoundationStereo first computes monocular features for each image with a unary feature extractor."
- Visual servoing: Controlling robot motion directly from visual feedback signals. "Stereo visual-servoing~\cite{stereo-visual-servoing} maps 2D stereo features to joint commands for depth-aware grasping without explicit 3D reconstruction."
- Visual tokens: Discrete embeddings representing visual patches fed into a LLM. "to generate visual tokens with geometric precision and semantic richness."
- Vision-Language-Action (VLA) models: Architectures that map visual inputs and language instructions to robot actions end-to-end. "Vision-Language-Action (VLA) models offer an end-to-end framework that maps visual inputs and language instructions to actions"
- Vision-LLMs (VLMs): Models jointly trained on images and text to learn aligned representations for multimodal understanding. "Leveraging pretrained Vision-LLMs (VLMs)~\cite{paligemma, qwen2.5-vl}, they exhibit strong generalization and semantic understanding capabilities."
Collections
Sign up for free to add this paper to one or more collections.