- The paper demonstrates that high-precision FFTs can be computed by decomposing the computation into lower-precision NTT-based convolutions using the Ozaki scheme for exact reconstruction.
- The methodology employs the Bluestein FFT to convert the DFT into a cyclic convolution, with CRT recombination from split 32-bit computations ensuring error-free results.
- Experimental results show stable relative error across FFT sizes and reduced computational cost via optimizations like NTT-domain accumulation, highlighting its practical applicability.
Efficient Target-Precision FFTs via Lower-Precision FFTs and the Ozaki Scheme
Introduction and Motivation
The paper "Computing FFTs at Target Precision Using Lower-Precision FFTs" (2603.29129) introduces an algorithmic framework for performing discrete Fourier transforms (DFTs) at a high (target) precision by decomposing the FFT computation into a series of lower-precision FFTs, specifically via the application of the Ozaki scheme to the cyclic convolution stage in the Bluestein FFT algorithm. This approach is motivated by the increasing disparity between hardware throughput for low-precision and high-precision arithmetic operations in modern processors. While the technique analogous to the Ozaki method has been leveraged to perform high-precision matrix-matrix multiplications with lower-precision BLAS calls, there has been no practical methodology to achieve similar effects for FFTs.
The paper's central contribution is adapting the Ozaki scheme to the cyclic convolution step within Bluestein's FFT and implementing the split convolutions using 32-bit number theoretic transforms (NTTs) with CRT-based recombination, circumventing floating-point roundoff error in the convolution stage. The work includes a concrete realization: a double-precision FFT computed using only 32-bit NTTs, showcasing significant accuracy benefit and controlled computational cost compared to direct emulation with higher precision.
Algorithmic Framework and Technical Underpinnings
Background: Bluestein FFT, NTT, and Ozaki Scheme
The Bluestein FFT (chirp-z transform) enables computing the DFT of arbitrary length by converting it to a cyclic convolution, which can be efficiently evaluated for power-of-two sizes. The Ozaki scheme, originally developed for matrix multiplication, splits high-precision inputs such that exact results are obtained from low-precision computations on split components, with the final result reconstructed by accumulation.
A direct extension of the Ozaki scheme to FFTs using floating-point arithmetic in the convolution stage is problematic. As split component convolutions are performed using floating-point FFTs, they can easily lose precision due to round-off; guaranteeing error-free computation would require prohibitively many splits, especially as the FFT size grows.
This motivates the use of the NTT, which implements the DFT over a finite field (modulo a prime). Since the NTT can be made exact for integer input as long as intermediate values stay within representable bounds, it becomes possible to use 32-bit NTT code paths to implement high-precision cyclic convolution on split vectors, with the CRT employed to handle dynamic range expansion.
Applying Ozaki to FFTs: Detailed Procedure
- Split inputs with Ozaki scheme: Input vectors are split into components representable in 32 bits, such that dot-product-like convolutions performed on each pair are exact.
- Cyclic convolution via NTT+CRT: Each split x(i)⊛y(j) is computed using two 32-bit NTTs with coprime moduli. CRT is used to reconstruct the exact integer result once the input dynamic range dictates more than a single modulus' width.
- Reconstruction: The output is formed as a sum (Ozaki accumulation) over the split component convolutions, each scaled correctly according to the split.
For double-precision FFTs (64-bit floats), the approach encodes each value as a triple-single (TS) number—three 32-bit floats representing the sum x0+x1+x2. All split, convolution, and elementwise product operations are performed in this format to guarantee sufficient significand bits.
Reduction of Computational Cost
To mitigate quadratic growth in computational cost with the number of splits K, the paper introduces two optimizations:
- An upper bound on the number of splits, K, is imposed, with negligible impact on overall accuracy for modest K.
- Split component convolutions with identical scaling can be accumulated in the NTT domain before applying the inverse NTT (NTT-domain accumulation, controlled by parameter L), reducing the number of NTT calls required.
These strategies allow for efficient leveraging of lower-precision NTT routines to achieve high-precision FFTs.
Accuracy
A double-precision FFT implementation using the presented method shows the following strong characteristics:
- Relative error remains stable across increasing FFT size (in contrast to standard double-precision Stockham or Bluestein FFTs, where error increases with size).
- The relative ℓ2 error is systematically lower than that of baseline double-precision FFTW and even TS-based Stockham and Bluestein FFTs for a wide range of input exponent distributions.
- Enforcing K=3 yields performance close to unlimited splits with only marginal loss of accuracy, and the minimum number of NTT calls can be reduced from 268 (for some parameter regimes) to 64 with NTT-domain accumulation.
The implemented prototype (C++/OpenMP, 48-core CPU) is dominated by NTT computation, which represents approximately 80% of the total execution time for n=210 to x(i)⊛y(j)0. The total number of 32-bit NTT and NTTx(i)⊛y(j)1 calls required is reduced substantially by bounding x(i)⊛y(j)2 and using NTT-domain accumulation.
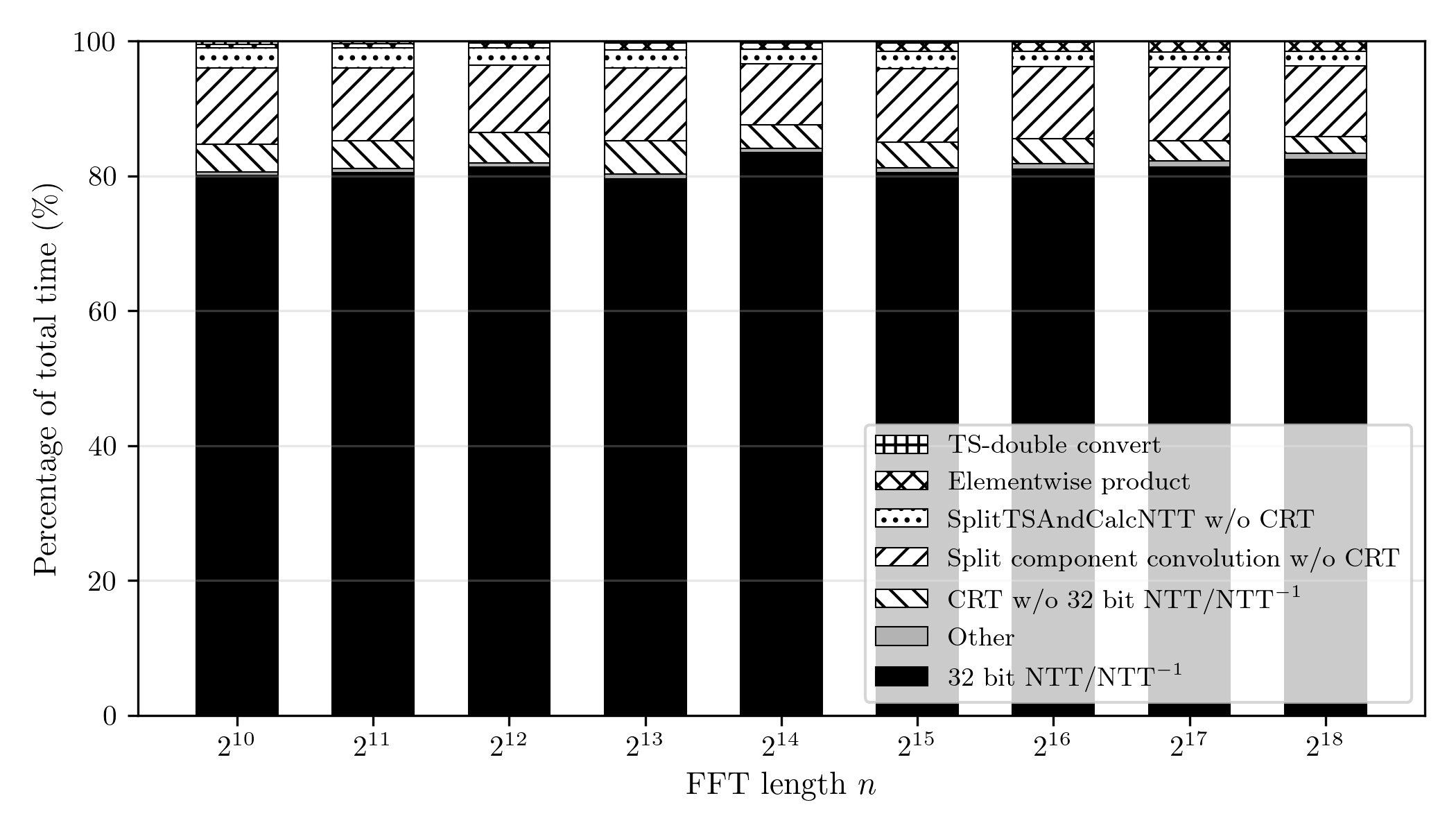 *Figure 2: Execution time breakdown of the proposed double-precision Bluestein FFT for x(i)⊛y(j)3, highlighting the 80% share occupied by 32-bit NTT/NTTx(i)⊛y(j)4. *
*Figure 2: Execution time breakdown of the proposed double-precision Bluestein FFT for x(i)⊛y(j)3, highlighting the 80% share occupied by 32-bit NTT/NTTx(i)⊛y(j)4. *
Raw runtimes (on single-precision optimized FFTW as baseline) suggest a slowdown of x(i)⊛y(j)5 to x(i)⊛y(j)6 compared to highly optimized double-precision FFTW on CPU. However, this ratio will decrease substantially for architectures with higher lower-precision throughput and/or GPU NTT optimization. The theoretical analysis quantifies the throughput win required for such a method to be competitive in wallclock time.
Theoretical and Practical Implications
The main theoretical implication is that it is algorithmically possible to decouple high-precision FFT computation from the availability of high-precision arithmetic hardware, provided modular integer computation is available at lower precision. This architecture-agnostic reduction to NTTs positions the FFT as the second major primitive (after GEMM) for which efficient Ozaki-style emulation of high-precision operations is achievable by composition—crucially, without writing new high-precision kernels.
Practically, if highly tuned low-precision (especially NTT) libraries become standard and available on accelerators, this technique would generalize high-precision FFTs to arbitrary target precision. Moreover, as the performance gap between single/low-precision and double/quad-precision continues to widen (especially on consumer GPUs), such approaches enable efficient exploitation of existing hardware. This is especially true for arbitrary-length FFTs, where the extra cost of Bluestein's mapping is proportionally smaller.
A limiting practical factor is the current lack of vendor-optimized, low-level, platform-specific NTT libraries, analogous to BLAS and FFTW; this is, however, changing rapidly due to cryptography and FHE demand, especially on GPUs.
The framework is extensible: integrating multi-modulus NTTs, exploiting emerging hardware with native 16- or 8-bit integer units (subject to transform length restrictions), and improved CRT-based splitting (see recent work on modular Ozaki splitting) may all further reduce overheads.
Conclusion
The paper establishes a mathematically principled method for translating high-precision FFT computation into a sequence of lower-precision, exact NTT-based convolutions orchestrated by the Ozaki scheme. The methodology achieves robust accuracy, with relative error that does not increase with problem size, and algorithmic cost controlled by the number of splits and accumulation depth. Its practical competitiveness depends on the existence of fast platform NTT implementations and hardware with pronounced low- vs. high-precision performance gaps, but as such conditions are increasingly common, this paradigm is well poised for scalable, portable high-precision FFT deployment in scientific and cryptographic computing.

