- The paper presents SR-CorrNet, an asymmetric encoder-decoder that leverages a correlation-to-filter paradigm for efficient and robust speech separation across varied acoustic scenarios.
- It integrates early speaker disentanglement with a dynamic attractor-based split to reduce information bottlenecks and enhance speaker discriminability even in noisy, reverberant conditions.
- Experiments on WSJ0-mix, WHAMR!, and LibriCSS datasets demonstrate state-of-the-art SI-SNR improvements and significant reductions in ASR word error rates.
Asymmetric Encoder-Decoder Based on Time-Frequency Correlation for Speech Separation: Technical Analysis
Introduction
The paper "Asymmetric Encoder-Decoder Based on Time-Frequency Correlation for Speech Separation" (2603.29097) introduces SR-CorrNet, a time–frequency (TF) domain architecture for single- and multi-channel speech separation robust to complex, realistic acoustic scenarios. Key innovations include (1) an asymmetric encoder–decoder based on the separation-reconstruction (SepRe) framework and (2) a correlation-to-filter paradigm for filter estimation using explicitly defined spatio-spectro-temporal correlations. The architecture integrates a dynamic attractor-based speaker stream splitting module for generalization across varying numbers of speakers. Comprehensive experiments show state-of-the-art separation and ASR performance on both simulated (WSJ0-mix, WHAMR!) and real-recorded (LibriCSS) datasets.
Limitations of Existing Architectures
Dominant TF-domain architectures (e.g., Conv-TasNet, DPRNN, Sepformer) typically employ a late-split strategy: mixture embeddings are disentangled in the last stage via direct spectral mapping, producing an information bottleneck and reducing speaker discriminability, especially for long, noisy, reverberant, and/or partially overlapped utterances. Furthermore, the direct mapping from raw spectra to target signals forces the model to learn complex physical dependencies implicitly, hindering robust generalization.
These deficiencies are illustrated by block diagram comparisons:


Figure 1: Late-split schemes defer separation to the final stage, while early-split (as used in SR-CorrNet) performs separation in the encoder for improved discriminability and reduced information bottlenecks.
SR-CorrNet Architecture
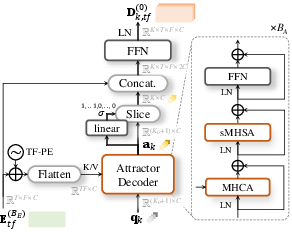
The SR-CorrNet architecture fundamentally restructures the TF-domain separation pipeline by implementing the SepRe framework for early speaker disentanglement in the encoder, with stage-wise feature refinement and reconstruction in the decoder via weight-sharing and cross-speaker interaction modules. The encoder processes correlation features instead of raw spectra, estimating deep filters applied to the input mixture. The output streams are dynamically split with an attractor-based mechanism that adapts the model to the actual speaker configuration.
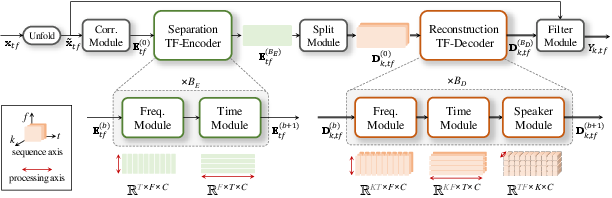
Figure 2: Full SR-CorrNet architecture, highlighting correlation-based feature extraction, TF dual-path encoder/decoder, speaker splitting, and filter estimation for direct signal reconstruction.
Correlation-to-Filter Paradigm
Rather than using spectral coefficients or masks as input, SR-CorrNet computes structured spatio-spectro-temporal correlations at the frame and channel levels, providing explicit cues for spatial, spectral, and temporal structure (including reverberation effects). The filter estimation module takes these correlation features and directly estimates complex-valued, multi-tap deep filters, establishing a one-to-one correspondence between input correlations and deep separation filters.
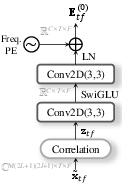
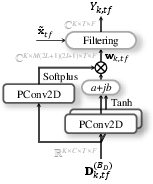
Figure 3: Correlation and filter modules – complex-valued correlations are embedded into real-valued features, forming the input for filter prediction networks.
This paradigm is invertible, generalizing the model to (i) single and multi-channel mixtures, (ii) anechoic, noisy, and reverberant conditions, and (iii) arbitrary TF context sizes. The explicit correlation computation stabilizes training and provides strong physical inductive bias, as verified in ablation studies.
Speaker Stream Splitting and Interaction
To robustly adapt to arbitrary numbers of speakers, SR-CorrNet incorporates either:
Additionally, the decoder employs a cross-speaker interaction module (a self-attention-based unit) to enable refinement via direct interaction among separated streams, supporting enhanced separation of mixed or ambiguous segments.
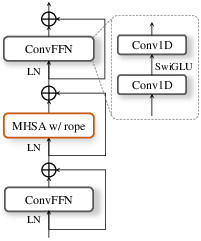
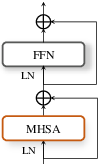
Figure 5: Common TF block and speaker interaction module for joint refinement of temporal, spectral, and speaker-dependent representations.
Early Supervision and Multi-Stage Objective
The decoder produces auxiliary outputs at each stage, with stage-dependent losses ("early supervision") encouraging progressive disentanglement and combating vanishing gradients. The total objective is a weighted sum across stages and, for dynamic split, includes a BCE term for speaker activity prediction.
Experimental Evaluation
Anechoic Mixtures (WSJ0-2/3/4/5Mix)
SR-CorrNet attains SI-SNRi of up to 25.5 dB on WSJ0-2Mix with dynamic mixing and outperforms all relevant prior architectures in the same MACs and parameter regime. It supports both fixed and dynamic splits; negligible performance gap is noted between known and unknown speaker count settings, with high accuracy up to five concurrent speakers.
Noisy-Reverberant Mixtures (WHAMR!)
SR-CorrNet surpasses previous state-of-the-art for single- and two-channel conditions, achieving 19.7 dB and 21.8 dB SI-SNRi, respectively—substantially outperforming time-domain and previous TF-domain models, notably SepReformer and TF-GridNet. The advantage is especially pronounced for multi-channel and reverberant conditions due to the correlation-based feature design.
Real Multi-Speaker Recordings (LibriCSS)
In both single-channel and seven-channel configurations, SR-CorrNet surpasses prior single- and two-stage pipelines, with up to 50% reduction in WER on the hardest overlapping conditions and improved RTF. The single-stage design eliminates reliance on explicit beamforming, speaker counting, or stream merging, unlike many competitors.
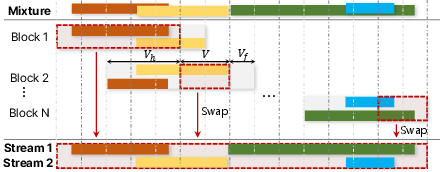
Figure 6: Illustration of the chunk-wise continuous speech separation (CSS) scheme used for evaluation on LibriCSS.
Ablation and Architectural Insights
Ablation studies confirm:
- The SepRe (encoder–decoder) architecture consistently yields higher SI-SNRi compared to encoder-only designs.
- Utilizing extended spatio-spectro-temporal correlation features is essential for robust filter estimation; reducing correlation context (temporal or spectral) degrades accuracy.
- Correlation-to-filter outperforms direct raw-input mapping, masking, or filtering, even in single-channel settings.
- The absence of cross-speaker interaction or removal of the dynamic split module leads to increased speaker confusion and spectral leakage, especially on long-form real recordings.
Practical and Theoretical Implications
SR-CorrNet introduces a unified framework for speech separation, robust across domains (anechoic, noisy, reverberant), channels, and dynamic speaker counts. The explicit correlation-to-filter paradigm offers structural interpretability and strong inductive bias without the architectural complexity of two-stage pipelines or extensive auxiliary modules.
In practical terms, this architecture enables efficient, chunk-based online separation (as in continuous speech separation), obviates the need for oracle speaker counts or beamformer pre-processing, and is well-suited as a front-end for far-field ASR and meeting transcription, as well as robust enhancement for hearing assistance and embedded systems.
Architecturally, SR-CorrNet establishes a foundation for expanding the scope of "unified" separation pipelines, supporting arbitrary array geometries and long-context speaker identity modeling, thereby paving the way toward integrating diarization and separation in future work.
Conclusion
SR-CorrNet merges an early-split, stage-wise refinement architecture with a structured correlation-to-filter paradigm, setting a new standard for single- and multi-channel TF-domain speech separation. The dynamic attractor-based split module generalizes separation to mixtures with varying speaker counts under adverse acoustic conditions. The design scales efficiently in computational requirements and outperforms prior approaches across benchmark datasets on both separation and ASR metrics, validating the merits of structured correlation modeling and progressive reconstruction.
Future directions include extension to arbitrary microphone array geometries and joint diarization-separation models, with the potential to deliver a unified, end-to-end solution for robust conversational AI front-ends.