- The paper presents a unified approach by leveraging deep spectrogram embeddings and alternating spectrogram blocks to integrate spectral and spatial cues for effective speech separation.
- It employs dual multi-head self-attention modules alongside MBConv layers to capture both temporal and local spectral features, achieving significant SI-SDR improvements in multi-channel setups.
- Robust experiments demonstrate scalability with varying microphone counts and superior performance in reverberant conditions compared to traditional models.
A Unified Approach to Multi/Single-Channel Speech Separation
Introduction
The paper "DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation" (2302.10657) presents a novel architecture aimed at unifying the approach to both multi-channel and single-channel speech separation tasks. Traditional speech separation techniques typically treat these scenarios separately, deploying specialized architectures for each. DasFormer innovates by proposing a unified model capable of handling both scenarios, demonstrating robustness particularly in reverberant environments.
Architectural Design
DasFormer is built on the premise of deep spectrogram embedding, representing each TF-bin with spectral and spatial information rather than merely modeling sequences frame by frame. The core architecture consists of multiple Alternating Spectrogram (AS) Blocks, each integrating multi-head self-attention (MHSA) for both temporal and spectral domains. This approach facilitates enhanced aggregation of spectral and spatial features, capitalizing on dependencies within the time-frequency domain.
The AS Block houses two MHSA modules processing frame-wise and spectral-wise inputs, along with MBConv layers to model local features on the spectrogram. This structure promotes effective speaker separation by handling spectral information and spatial cues, such as those introduced by reverberation and multi-channel inputs.
In rigorous evaluations, DasFormer significantly surpasses existing SOTA models in multi-channel separation tasks. Experiments on the spatialized WSJ0-2Mix dataset reveal a scale-invariant signal-to-distortion ratio improvement of 25.9 dB, exceeding previous benchmarks by substantial margins (Table 1). This marks a notable advancement compared to methods like Beam-TasNet, especially under randomized microphone array configurations where spatial inconsistency often poses challenges.
DasFormer also excels in single-channel separation on the WHAMR! dataset, demonstrating an SI-SDR improvement of 16.0 dB, which further enhances to 17.3 dB for its extended version (DasFormer Plus). This performance illustrates the architecture's robustness when dealing with reverberant environments—a continual challenge in real-world applications (Table 2).
Scalability and Robustness
The experiments highlight DasFormer’s scalability and robustness across varying microphone counts. While existing models like Sepformer and NBC show degradation or limited gains in multi-channel settings, DasFormer scales effectively. Its performance improves notably with an increasing number of microphones, making it a versatile solution across diverse configurations (Figure 1).
A series of ablation studies confirm the importance of deeper network layers and the MBConv module design. Removing these components results in a marked degradation of performance, reinforcing their critical role within the architecture (Table 3).
Visualization Insights
Attention map visualizations from various AS Block layers (Figure 2) provide insights into DasFormer's functionality. The attention patterns evolve across layers, with shallow layers focusing on local frame relationships, middle layers recognizing broader phonetic similarities, and deeper layers aligning more closely with speaker activity. This layered processing differentiation underscores DasFormer’s ability to integrate multi-level information effectively.
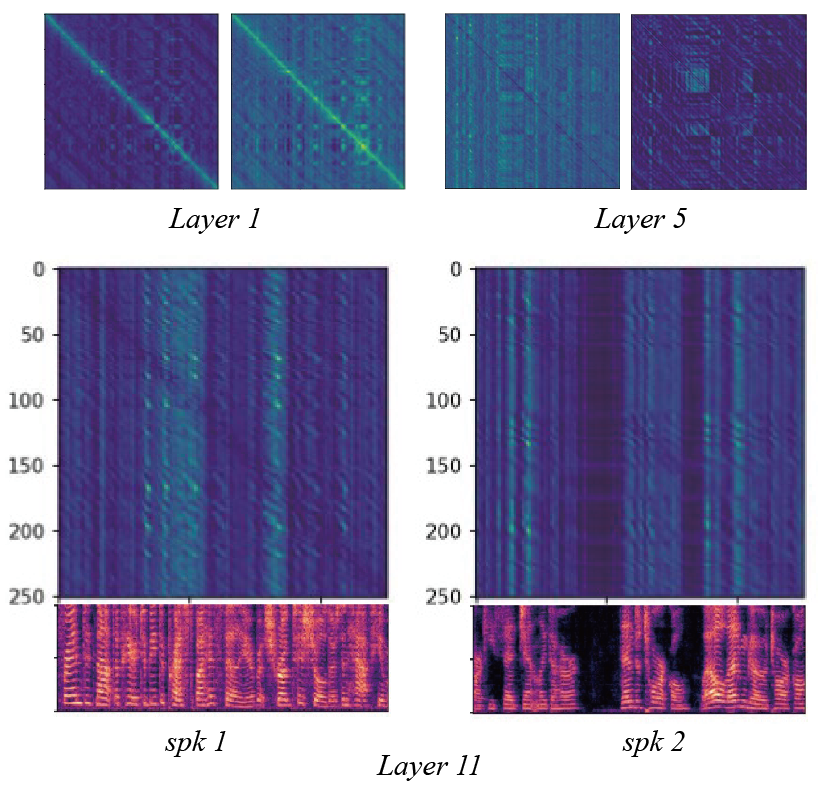
Figure 2: Results of attention scores from different layers in AS Block. They are two heads from the shallow (layer 1), middle (layer 5) and deep (layer 11) layer respectively.
Conclusion
DasFormer presents a transformative approach to speech separation, providing a unified solution for both multi-channel and single-channel scenarios. Its design leverages deep TF-bin embedding with spectral and spatial attention mechanisms, leading to robust performance across challenging environments. Such adaptability is promising for future applications, particularly in scenarios requiring adaptation across diverse microphone arrays or reverberant conditions.