- The paper introduces APEX-EM, a non-parametric online learning framework that uses structured procedural-episodic memory to significantly improve autonomous agents’ performance.
- It employs a novel Procedural Knowledge Graph (PKG) and a hybrid retrieval mechanism for iterative self-correction, achieving notable gains on benchmarks like KGQAGen-10k and BigCodeBench.
- The system enables robust cross-domain transfer and reduces iteration counts, facilitating both positive and negative learning without updating model parameters.
APEX-EM: Non-Parametric Online Learning for Autonomous Agents via Structured Procedural-Episodic Experience Replay
Motivation and Context
LLM-based autonomous agents, despite improvements in multi-step reasoning, code generation, and complex tool use, exhibit a fundamental deficiency in procedural memory. Unlike RL agents with experience replay buffers that enable knowledge accumulation and reinforcement through transitions, LLM agents re-derive solutions ab initio for each new task, regardless of prior structurally analogous experiences. Existing memory augmentations—narrative logs, code snippet repositories, entity graphs, and episodic buffers—are unstructured or domain-fragmented, limiting deep procedural reuse. Even recent works using value-based episodic memory (e.g., MemRL) rely on flat, text-based summaries and scalar Q-values, lacking dual-outcome learning and robust cross-domain procedural transfer.
APEX-EM directly addresses these limitations by instituting a non-parametric online learning framework centered on structured experience replay and hybrid retrieval, enabling genuine procedural-episodic memory for LLM-based agents. The system accumulates, retrieves, and reuses complete procedural plans, supporting both positive and negative transfer via layered, type-rich memory structures and compositional retrieval mechanisms.
System Architecture and Methodology
Structured Experience Representation
Central to APEX-EM is the Procedural Knowledge Graph (PKG). The PKG is a typed, relational ontology capturing entities, experiences, operations, sub-tasks, and task topics interconnected through semantically meaningful edges (e.g., FOLLOWED_BY, USES, structurally_similar_to, supersedes). Each experience encodes:
- Goal Reflection: Task definition, constraints, and verification contracts.
- Procedure Reflection: Parameterized, versioned procedural templates.
- Evidence Reflection: Provenance-tagged support artifacts.
- Execution Trace: Iterative attempts with results and feedback.
- Error Registry: Structured error types, root causes, and recovery protocols.
- Patch Reflection: Instrumented corrections and rationale.
Successful experiences serve as positive samples, whereas failed executions—with error decomposition—are retained for explicit negative guidance, directly analogous to hindsight experience replay in RL.
PRGII Workflow
Task processing is governed by the Plan-Retrieve-Generate-Iterate-Ingest (PRGII) workflow (Figure 1), which systematically decomposes each task as follows:
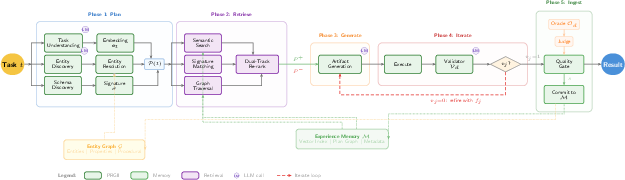
Figure 1: The PRGII workflow. A task t flows through Plan, Retrieve, Generate, Iterate, and Ingest phases, with PKG mediating both structured retrieval and entity resolution.
- Plan: Extracts intent, entity, and schema hypotheses, computes a structural signature (abstracted operation sequences).
- Retrieve: Hybrid retrieval queries memory by semantic similarity (embedding space), structural signature match (LCS-based), and plan graph traversal, yielding dual-tracks P+ (successes) and P− (failures).
- Generate: LLM prompts are conditioned on both the structured plan and contextually relevant retrieved experiences.
- Iterate: Multi-step self-correction using rigorous validators and feedback loops (including judge and oracle signals).
- Ingest: Evaluation and quality gating; integration of successful/failed traces into PKG, updating entity/procedure versions as required.
Hybrid Retrieval and Cross-Domain Structural Transfer
APEX-EM's hybrid retrieval mechanism integrates:
- Semantic search (embeddings on Goal Reflection fields)
- Structural signature matching (LCS/Jaccard over operation sequences, yielding robust cross-domain transfer)
- PKG traversal (guided multi-hop graph walks)
Unlike prior works tied to surface-level text similarity, this architecture enables retrieval and adaptation of structurally analogous procedural traces across semantically distinct task domains.
Empirical Analysis and Results
Evaluation Benchmarks
Comprehensive evaluation spans three primary domains:
- BigCodeBench (code generation)—high-complexity API usage and code synthesis tasks.
- KGQAGen-10k (multi-hop structured query generation on Wikidata).
- Humanity's Last Exam (HLE) (multi-domain expert-level reasoning).
Comparisons are made under frozen-backbone conditions (Claude Sonnet/Opus 4.5) against MemRL and a spectrum of RAG/episodic baselines.
Main Results
Numerical Gains
- KGQAGen-10k: APEX-EM attains 89.6% accuracy (95.3% CSR), a +48.3 pp improvement over the baseline and exceeding the oracle retrieval upper bound (GPT-4o + SP at 84.9%).
- BigCodeBench: Achieves 83.3% SR/84.0% CSR from 53.9%, markedly surpassing MemRL's +11.0pp on comparable splits.
- HLE: Reaches 48% SR from 25.2%, with entity-graph retrieval, outperforming all baseline strategies.
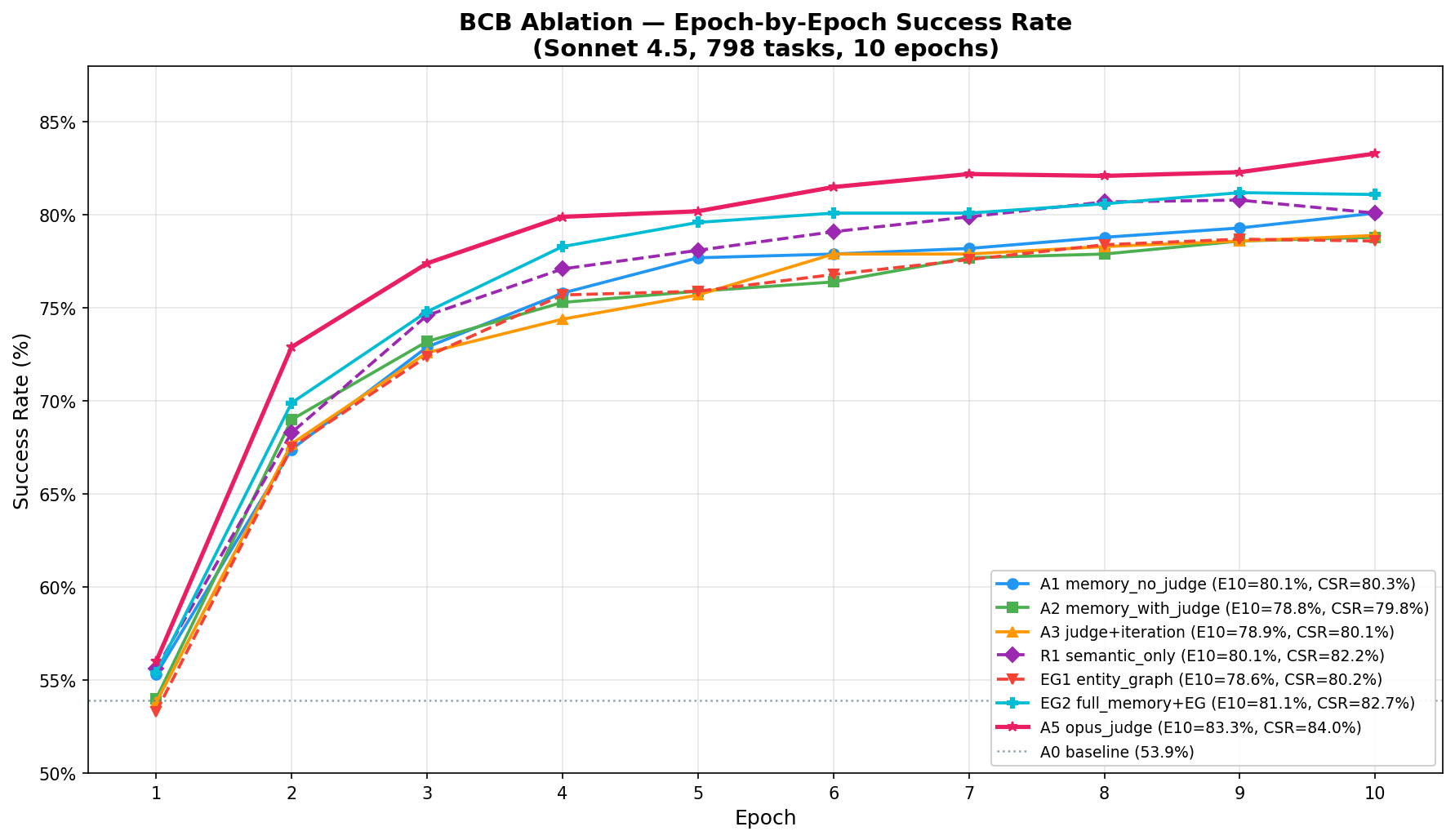
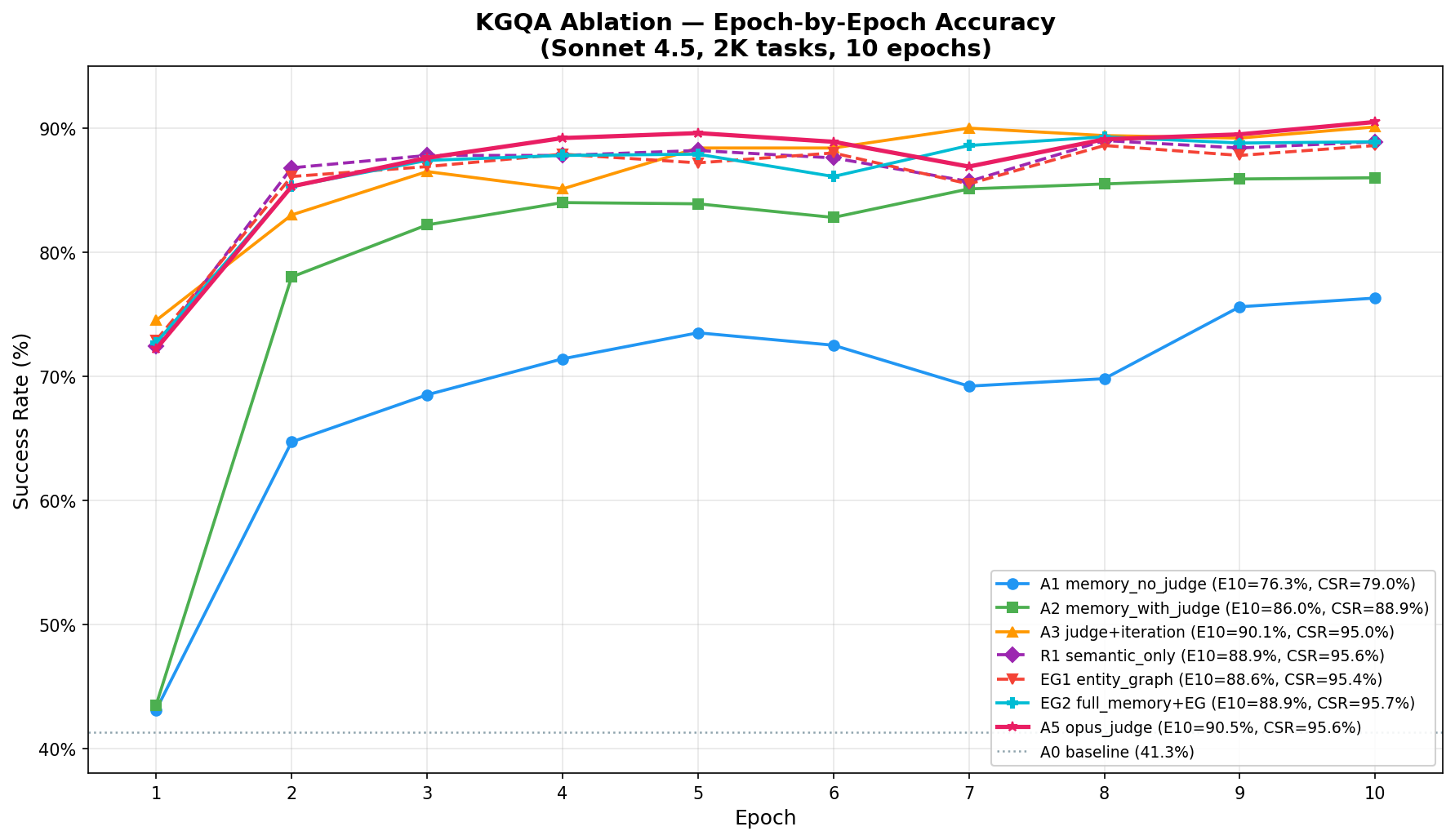
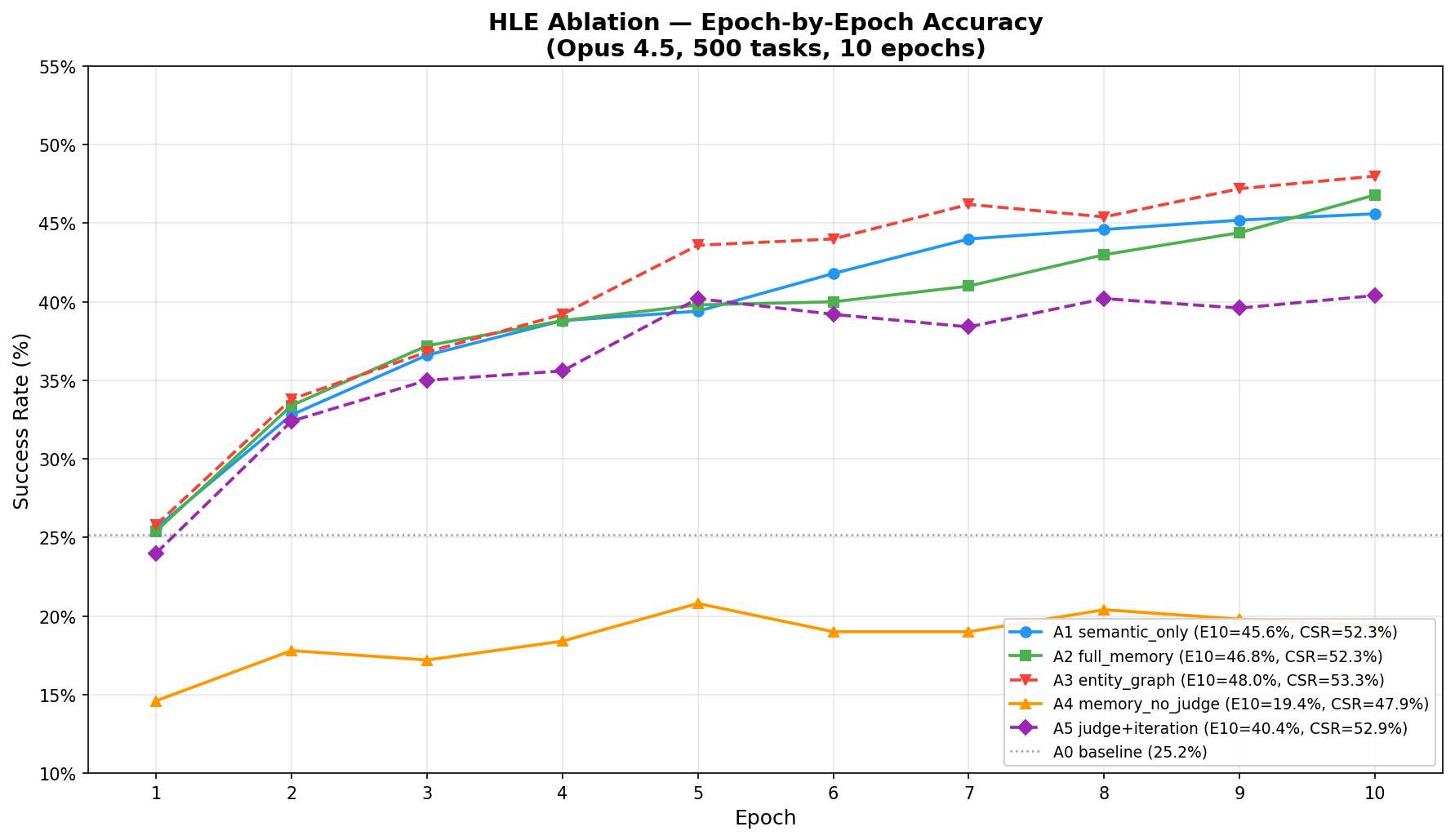
Figure 2: Epoch-by-epoch success rates for ablation configurations across benchmarks, demonstrating strong early-phase improvements and eventual plateauing characteristic of non-parametric online updates.
Ablation Analysis
Component contribution is task-dependent:
- Rich judge feedback (qualitative reward decomposition) is critical for structured query generation (+10.3pp on KGQA) but marginal for code generation, where pass/fail is sufficient.
- Iterative self-correction can partially substitute for finer feedback quality, particularly in domains where pattern adaptation is easier.
Iteration Efficiency
Memory accumulation reduces average iteration count per task (key for computational cost):
Cross-Domain Transfer
APEX-EM's structural signatures enable robust transfer even when task embeddings are disjoint. Unlike MemRL, which relies on semantic retrieval, APEX-EM maintains effectiveness on benchmarks (such as HLE) where intra-set embedding similarity is intentionally low.
Qualitative Dynamics
- Cold-start is mitigated via curated seed plans and offline-to-online bootstrapping.
- PKG maintenance (compaction, entity swaps, patching) prevents memory bloat and guarantees up-to-date procedural generalization.
Theoretical and Practical Implications
The APEX-EM framework firmly establishes non-parametric online learning as a tractable, model-agnostic pathway for agent knowledge accumulation without model weight updates. By promoting structured, type-rich procedural traces and dual-outcome learning, it closes the procedural memory gap for LLM agents and offers full auditability and modular repair that flat/episodic memories cannot.
Practically, APEX-EM provides increased sample efficiency (fewer inferences per solved task), robust negative transfer avoidance, and directly supports continuous deployment in dynamic environments (e.g., evolving APIs or KBs via PKG entity versioning).
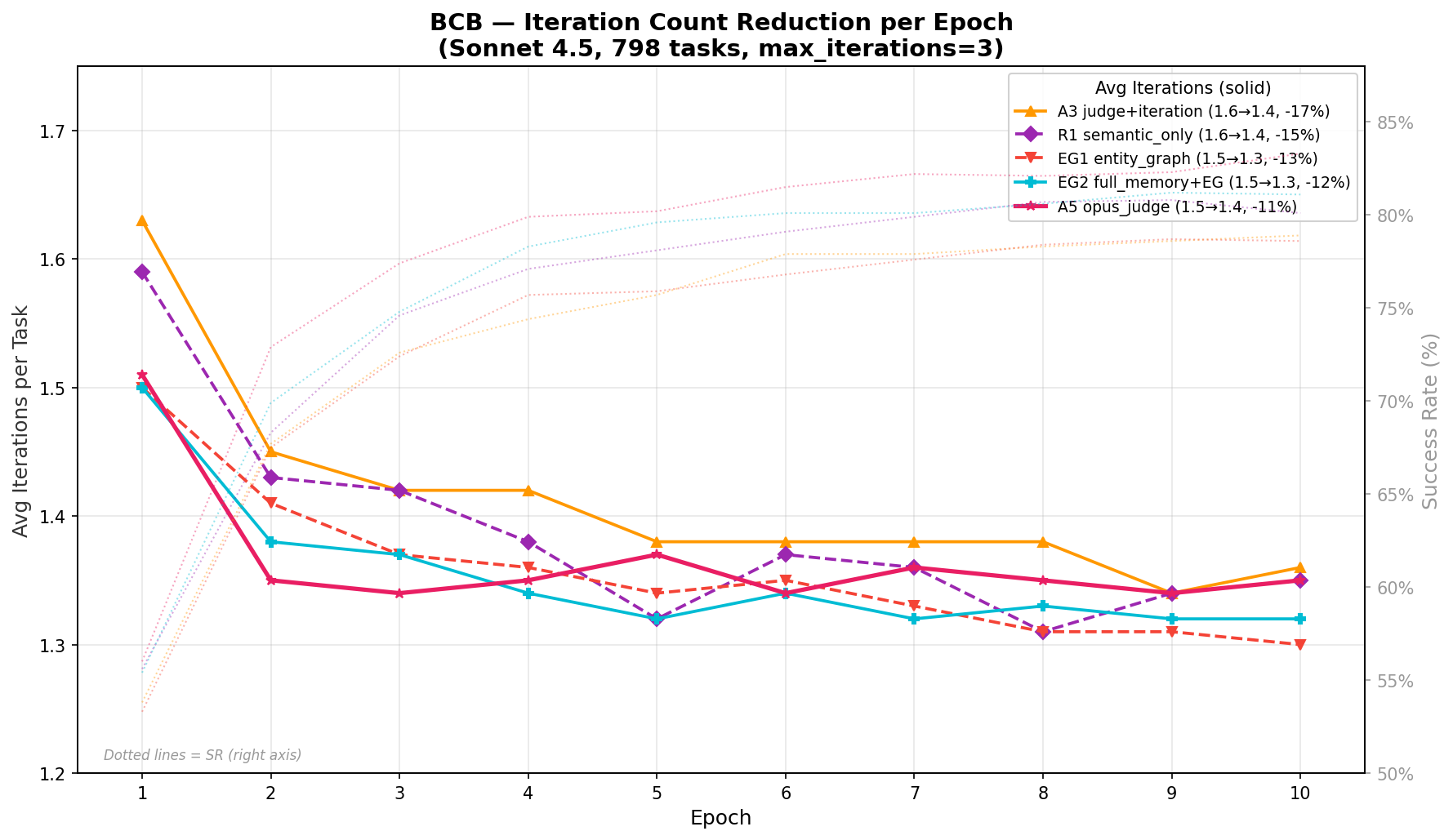
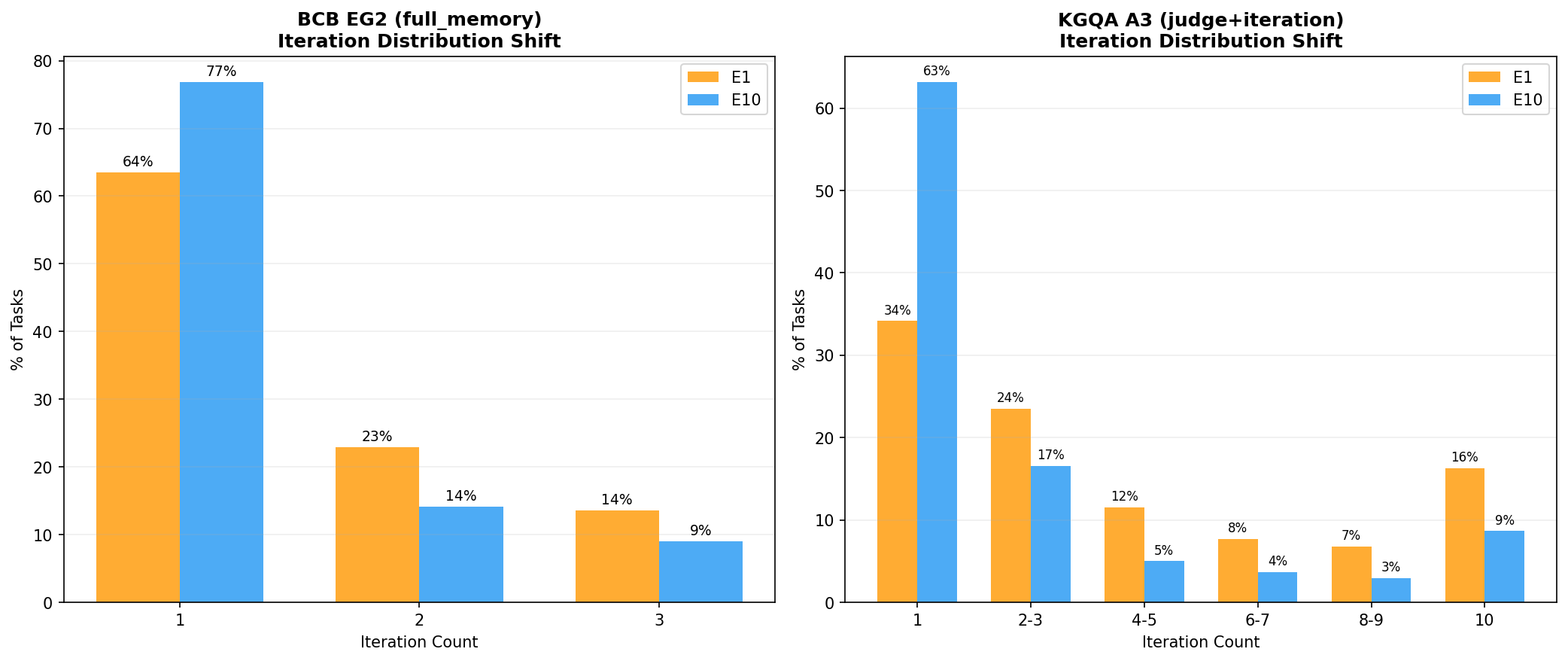
Figure 4: BCB iteration reduction across epochs, demonstrating consolidation toward first-attempt correctness due to memory adaptation.
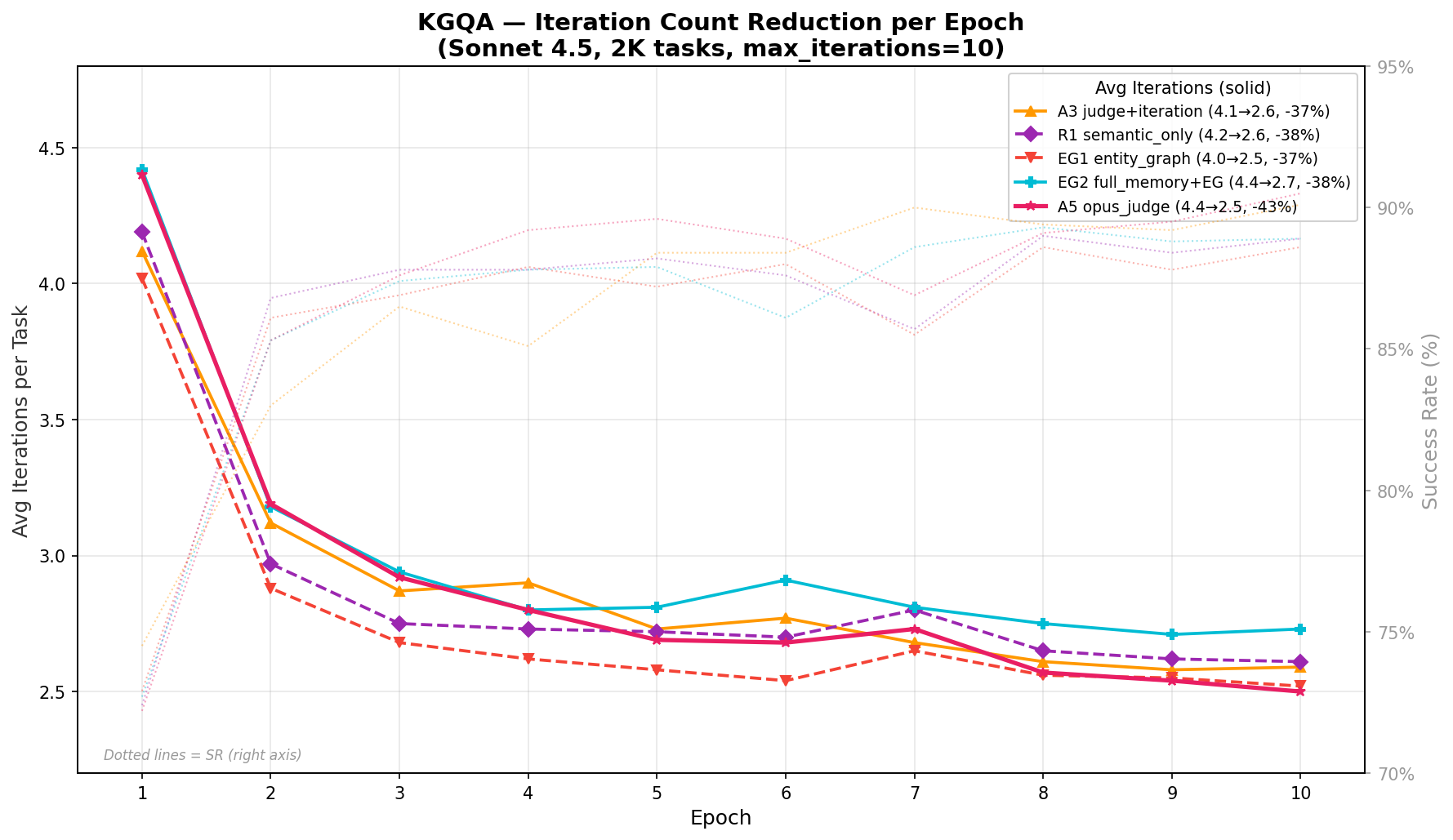
Figure 5: KGQA iteration reduction, with a pronounced reduction in multi-attempt solutions over online experience accumulation.
Future Directions
- Evaluating on additional embodied and tool-use agent benchmarks (e.g., ALFWorld, Lifelong Agent Bench).
- Automated extraction and optimization of structural signatures for finer-grained procedural induction.
- Integrating Q-value estimation (MemRL-style) with PKG-based structure for composite utility-aware retrieval.
- Plan/prompt compression for improved context usage without degradations in procedural fidelity.
Conclusion
APEX-EM advances the state of the art in agentic memory by unifying non-parametric online learning, structured procedural-episodic replay, and hybrid compositional retrieval. The paradigm shift from unstructured episodic memory to layered, type-rich, and negative-indexed experience enables LLM-based agents to realize persistent, generalizable learning at deploy time, without parameter updates. This positions APEX-EM as a foundational methodology for future research in memory-augmented and self-evolving autonomous systems (2603.29093).