- The paper presents MV-RoMa, a novel dense matching framework that shifts from pairwise to multi-view track reconstruction using track tokens for geometric consistency.
- It employs a track-guided encoder and pixel-aligned multi-view attention, enabling efficient feature fusion and refined correspondence prediction.
- Experimental results demonstrate state-of-the-art performance in 2D homography, 3D triangulation, and camera pose estimation, affirming its practical impact.
MV-RoMa: A Multi-View Consistent Dense Matching Framework for Track Reconstruction
Introduction and Motivation
Traditional dense feature matching models for 3D vision, most notably within the Structure-from-Motion (SfM) paradigm, fundamentally rely on composing pairwise correspondences between images. This heuristic, while simple, induces fragmentation and geometric inconsistency in recovered multi-view tracks, directly impacting the accuracy and density of reconstructed 3D points. Recent research has attempted to overcome these limitations using post-hoc refinement of SfM tracks, either via cycle consistency regularization or per-track geometric optimization; however, these methods are restricted by their reliance on the quality and validity of underlying pairwise matches and are computationally prohibitive in fully dense regimes.
To address these core deficiencies, "MV-RoMa: From Pairwise Matching into Multi-View Track Reconstruction" (2603.27542) defines a new class of dense matching model: one which explicitly operates on sets of co-visible images, producing correspondences that are consistent and robust across all views. The principal insight is to use geometric priors derived from initial pairwise matches as "track tokens," which index and orchestrate information exchange in a computationally efficient multi-view feature encoder. The approach presents a hybrid attention/refinement architecture that supports direct multi-view reasoning and yields state-of-the-art quantitative and qualitative performance across 2D, 3D, and camera pose estimation benchmarks.
Figure 1: Overview of MV-RoMa: the system jointly predicts multi-view consistent correspondences, which are then processed by an SfM pipeline to yield dense, accurate 3D reconstructions.
Architectural Components
Track-Guided Multi-View Encoder
The representation bottleneck for multi-view consistency is addressed via a track-guided encoder, inspired by Tracktention, operating over the DINOv2 feature backbone. Given initial pairwise matches (from, e.g., UFM or keypoint-based pipelines), the system constructs a set of "track tokens" via k-means clustering, ensuring good spatial coverage and reducing sensitivity to noisy or redundant matches. Each token contains a vector of 2D image positions across views, as well as a binary visibility mask to handle occlusions and partial co-visibility. Sampling is controlled to balance spatial distribution and computational tractability.
These tokens are used in-between transformer layers to mediate cross-view information flow. For each token, features are sampled via cross-attention (with explicit locality bias) from each image grid, aggregated into a multi-view-aware track representation via masked self-attention over the view dimension, and then splatted back onto the image grids. This tightly couples per-pixel features with the geometric structure inferred from the joint matches, enabling the encoder to produce view-consistent dense descriptors.
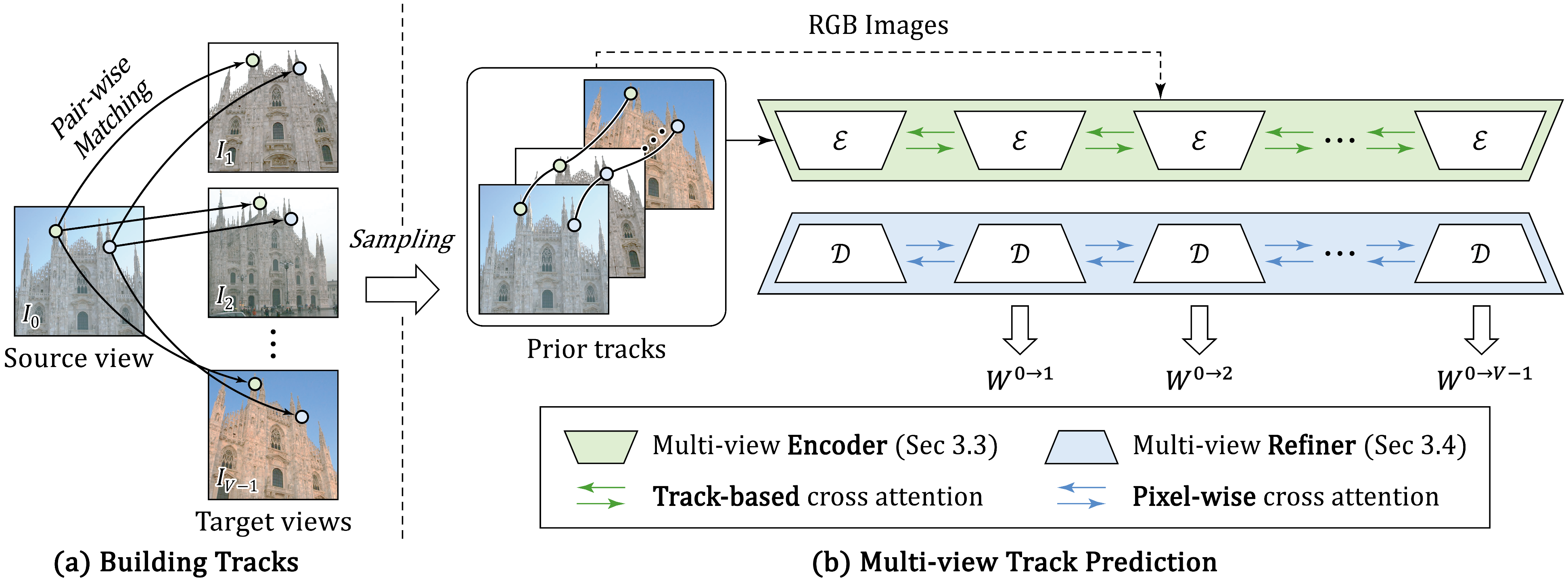
Figure 2: Pipeline of MV-RoMa showing track construction, multi-view encoding, and coarse-to-fine multi-view dense correspondence prediction.
Multi-View Matching Refinement
MV-RoMa leverages a two-stage correspondence prediction pipeline: initial coarse coordinate regression (modifying RoMa's technique to use multi-view features), followed by progressive refinement at multiple scales using a VGG-based feature pyramid. Novel to this approach is the pixel-aligned multi-view attention: for each stride, target features are warped into the source view’s grid using current correspondences, and attention is executed among the spatially-aligned tokens across the group. This enables feature fusion with linear complexity in the number of views and grid positions, avoiding quadratic cross-attention bottlenecks.
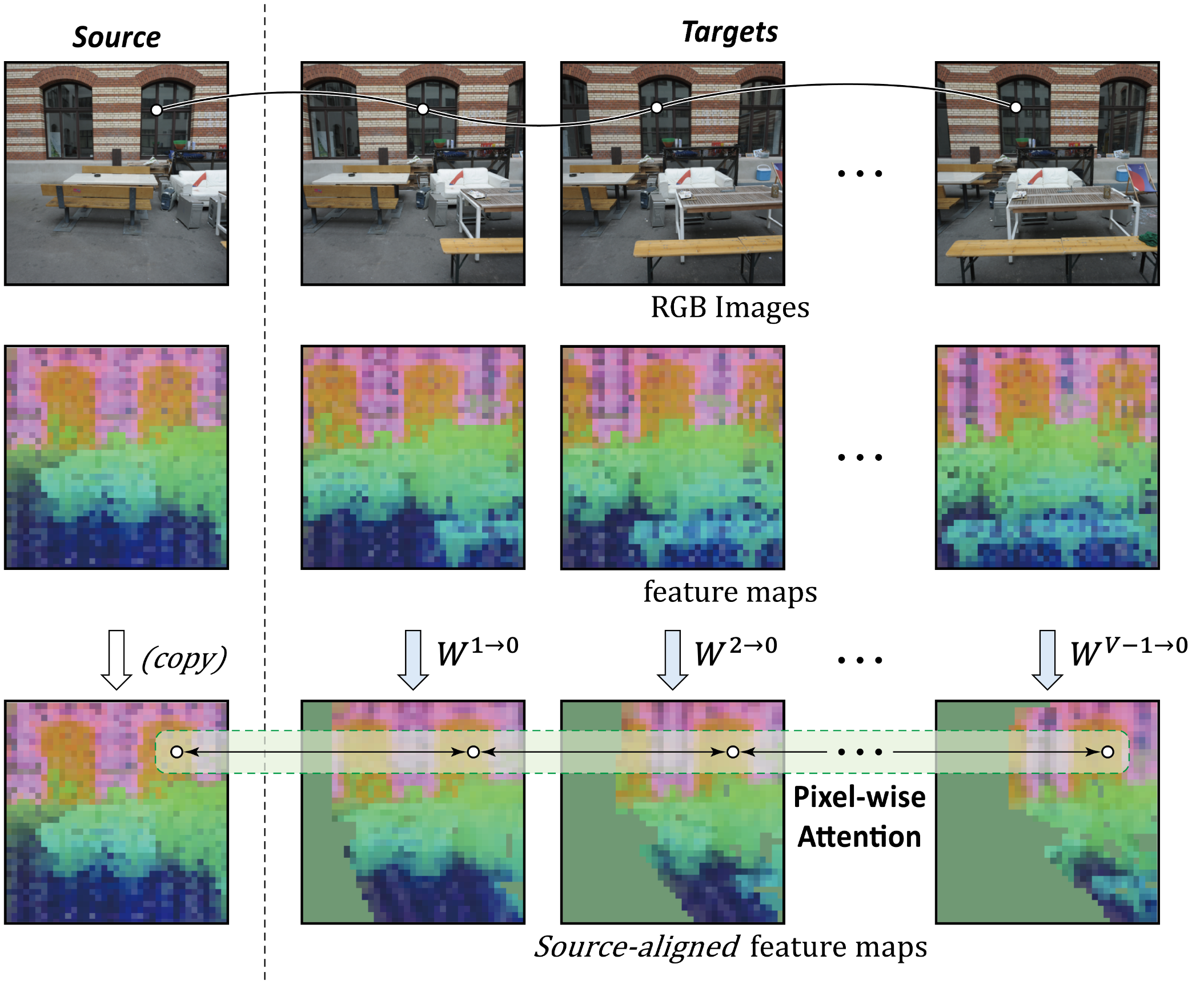
Figure 3: Pixel-aligned multi-view attention: target view features are warped to source coordinates, then multi-view attention is applied for each pixel.
SfM Integration and Post-processing
Rather than chaining pairwise match outputs, MV-RoMa natively predicts multi-view tracks over grouped sets. The post-processing recipe includes confidence pooling, bidirectional forward–backward consistency filtering, and keypoint sampling using non-maximum suppression over a confidence/track-length score map. This framework ensures tracks are both geometrically reliable and computationally efficient for downstream bundle adjustment and 3D triangulation.
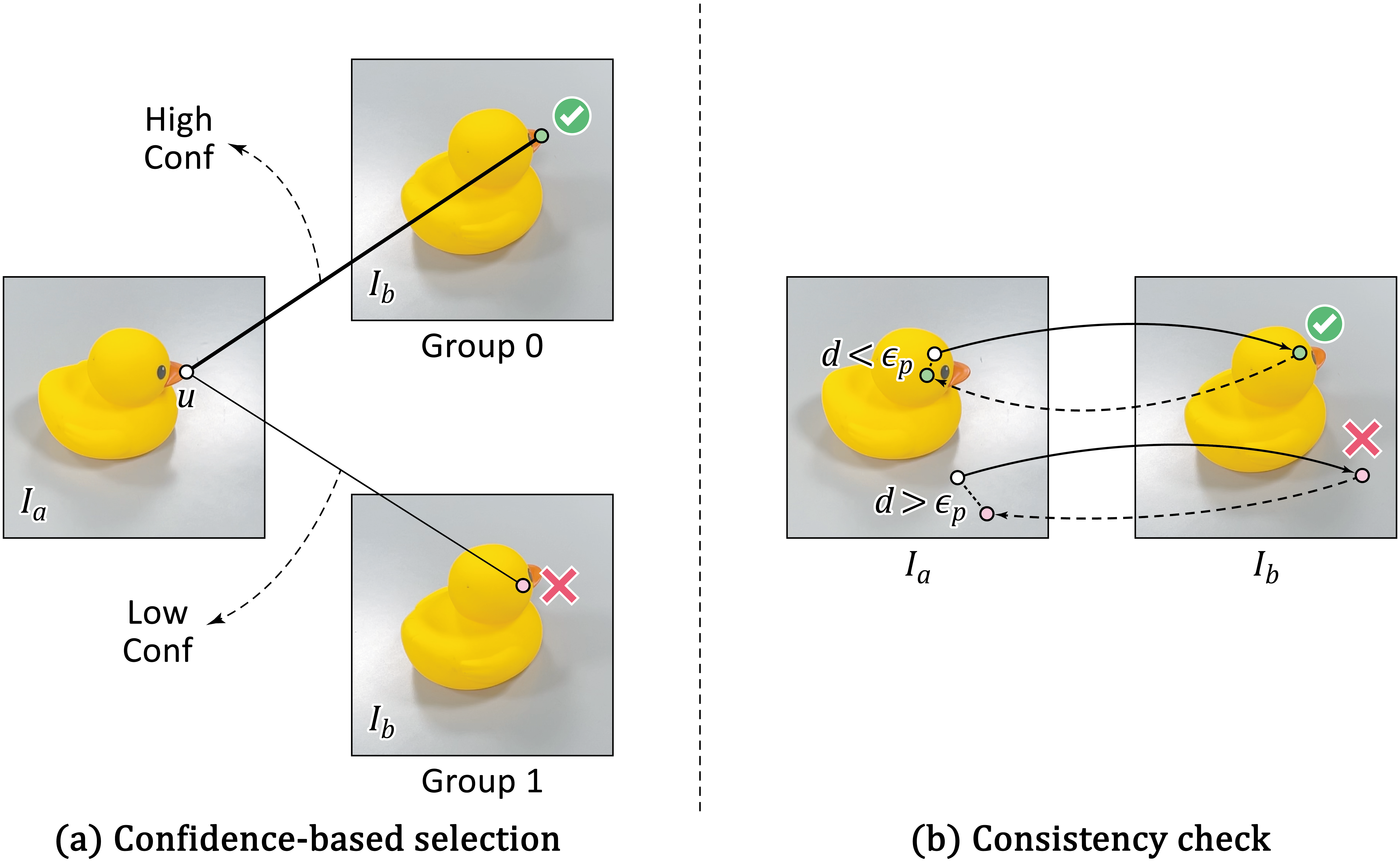
Figure 4: Confidence selection and reciprocity-based filtering for final SfM track construction, enforcing bi-directional correctness and match uniqueness.
Experimental Analysis
2D Homography Estimation
MV-RoMa achieves the strongest AUC at all error thresholds on HPatches for both DLT and RANSAC solvers, particularly excelling at the strictest 1 px criterion, indicating high precision and inlier rate in dense correspondence prediction. Importantly, paired baselines are decisively surpassed, validating the claim that joint multi-view processing can address error accumulation in sequential matching.
3D Triangulation and Camera Pose Estimation
On the ETH3D dataset, MV-RoMa sets a new upper bound for dense triangulation accuracy (>81.9% at 1 cm), and achieves leading completeness (>41% at 5 cm). Compared against recent advances in detector-free and cycle-consistency–based frameworks (including Dense-SfM and RoMa+DF-SfM pipelines), MV-RoMa exhibits both state-of-the-art accuracy and competitive completeness, even without extra costly iterative refinement.
Camera pose estimation results on Texture-Poor SfM and IMC PhotoTourism scenes further demonstrate the robustness of MV-RoMa in sparsely textured scenarios and under large viewpoint baselines, outperforming keypoint-based, dense pairwise, and even recent non-local attention-based deep 3D pipelines across all pose error thresholds.
Ablations
Ablation studies systematically quantify the impact of the track-guided encoder, the pixel-aligned multi-view refiner, number and spatial distribution of track tokens, and group size. Results establish the complementary effect of the encoder and refiner. Reducing the number or spatial coverage of track tokens noticeably harms performance, as does reverting to independent pairwise processing. MV-RoMa's flexibility is further validated by its modular ability to accept geometric priors from diverse off-the-shelf matchers.
Theoretical and Practical Implications
MV-RoMa is architecturally distinct in that it eschews both pairwise or sequential chain matching and fixed keypoint detectors, directly generalizing dense track construction to the multi-view case. The computational utility of "track tokens" as geometric priors opens avenues for further integration of geometric structure into attention-based models without incurring O(N2) cost—making the approach scalable beyond small image groups.
The framework's direct multi-view consistency, flexibility for plug-and-play priors, and amenability to modern transformer-scale training have immediate significance for reconstruction and localization systems, notably when high correspondence density is required and in texture/challenge-dominated scenes where keypoint repeatability and distinctiveness are limiting. The method's architectural ingredients—track-aware attention, efficient per-pixel multi-view fusion, and robust post-processing—serve as a template for subsequent research in dense vision pipelines and potentially beyond, such as SLAM and 3D scene understanding.
Conclusion
MV-RoMa (2603.27542) synthesizes geometric priors, transformer-based feature extraction, and efficient multi-view correspondence reasoning to create a highly performant dense matching architecture. It delivers consistent multi-view correspondences, directly enabling denser and more accurate 3D reconstructions. The approach establishes new quantitative standards and provides a flexible foundation for future 3D vision systems seeking robustness, scalability, and geometric fidelity within and beyond structure-from-motion.