- The paper introduces MVTracker, a multi-view 3D point tracker that fuses RGB video, depth cues, and CNN-extracted features using kNN correlation and transformer-based refinement.
- It achieves state-of-the-art results with high accuracy on Panoptic Studio, DexYCB, and MV-Kubric datasets, effectively addressing occlusions and depth ambiguities.
- The method scales with additional cameras and supports near-real-time inference, making it promising for applications in robotics and dynamic scene reconstruction.
Multi-View 3D Point Tracking: MVTracker
Introduction and Motivation
The paper presents MVTracker, a data-driven multi-view 3D point tracker designed to robustly track arbitrary points in dynamic scenes using a practical number of cameras (e.g., four). The method addresses the limitations of monocular trackers, which suffer from depth ambiguities and occlusion, and prior multi-camera approaches that require dense camera arrays and per-sequence optimization. MVTracker leverages synchronized multi-view RGB videos, known camera parameters, and either sensor-based or estimated depth to fuse multi-view features into a unified 3D point cloud. It then applies k-nearest-neighbors (kNN) correlation and a transformer-based update to estimate long-range 3D correspondences, handling occlusions and adapting to varying camera setups without per-sequence optimization.
MVTracker Pipeline and Architecture
MVTracker's pipeline consists of several key stages:
- Feature Extraction: Per-view feature maps are extracted using a CNN-based encoder at multiple scales for computational efficiency and multi-scale correlation.
- 3D Point Cloud Construction: Depth maps (sensor-based or estimated) are used to lift 2D pixels into 3D world coordinates, associating each point with its feature embedding. All views are fused into a single 3D point cloud.
- kNN-Based Correlation: For each tracked point, kNN search retrieves local neighbors in the fused point cloud, computing multi-scale correlations that encode both appearance similarity and 3D offset information.
- Transformer-Based Tracking: A spatiotemporal transformer refines point positions and appearance features over a sliding temporal window, using self-attention and cross-attention with virtual tracks.
- Windowed Inference: Sequences are processed in overlapping windows, merging outputs for globally consistent trajectories and occlusion-aware visibility predictions.
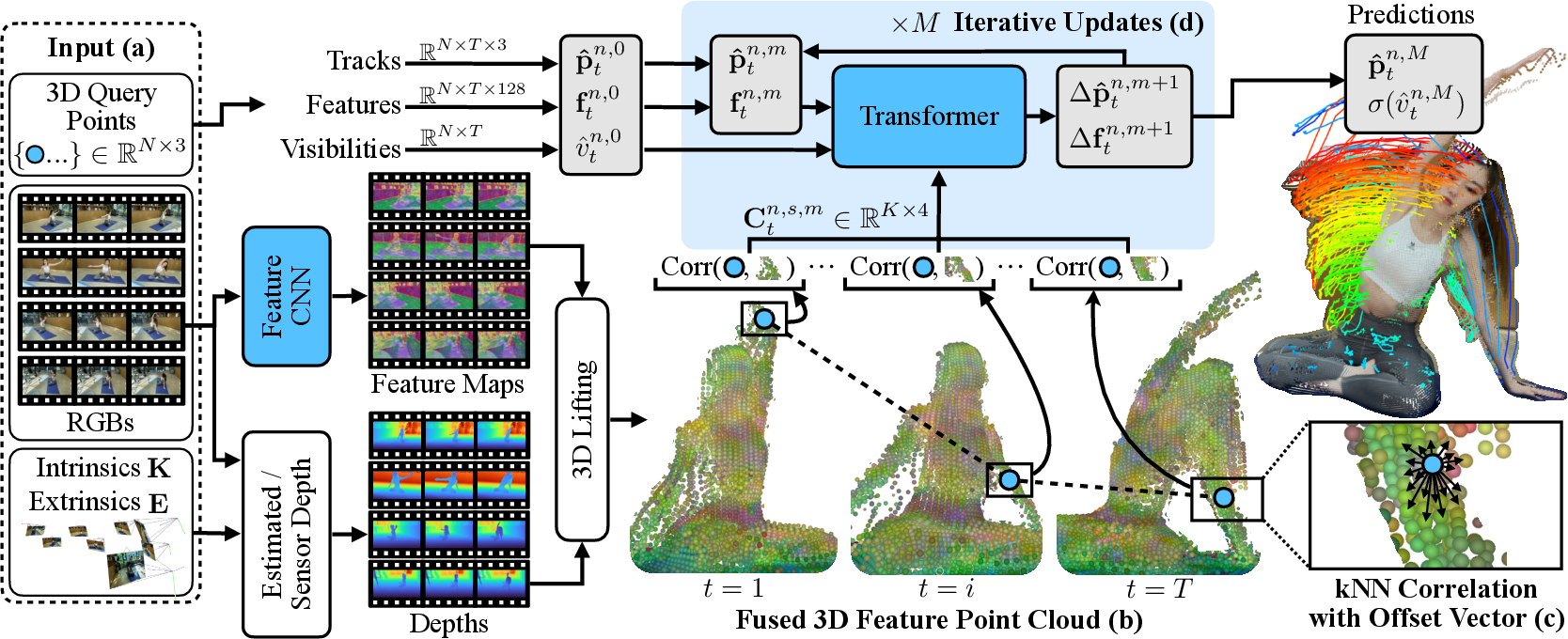
Figure 1: MVTracker pipeline: multi-view feature extraction, fused 3D point cloud construction, kNN-based correlation, transformer-based iterative tracking, and windowed inference for temporally consistent 3D trajectories.
Implementation Details
Point Cloud Encoding
- Depth Lifting: For each pixel (ux,uy) in view v and frame t, the 3D position is computed as:
x=Etv−1(Ktv−1(ux,uy,1)⊤⋅Dtv[uy,ux])
- Feature Association: Each 3D point is associated with its corresponding feature vector from the CNN encoder.
- Fused Point Cloud: All points from all views are merged into a single set, preserving geometric and appearance information.
kNN-Based Multi-Scale Correlation
- For each tracked point, kNN search retrieves K neighbors at multiple scales.
- Correlation features are computed as the dot product between the track feature and neighbor features, concatenated with the 3D offset vector.
- Ablation studies show that encoding only the offset vector yields the best performance.
- Track tokens include positional encoding, appearance features, multi-scale correlations, and visibility.
- The transformer iteratively refines positions and features, recomputing correlations after each iteration.
- Visibility is predicted via a sigmoid projection of the final feature vector.
Training and Supervision
- Supervised on synthetic multi-view Kubric sequences (5K videos).
- Loss function combines weighted ℓ1 position error and balanced binary cross-entropy for visibility.
- Extensive augmentations (photometric, spatial, depth perturbations, scene-level transforms) improve generalization.
Experimental Results
MVTracker is evaluated on Panoptic Studio, DexYCB, and Multi-View Kubric datasets. Key metrics include Median Trajectory Error (MTE), Average Jaccard (AJ), Occlusion Accuracy (OA), and location accuracy at multiple thresholds.
- Panoptic Studio: AJ = 86.0, OA = 94.7, MTE = 3.1 cm
- DexYCB: AJ = 71.6, OA = 80.6, MTE = 2.0 cm
- MV-Kubric: AJ = 81.4, OA = 90.0, MTE = 0.7 cm
MVTracker outperforms single-view, multi-view, and optimization-based baselines in both accuracy and occlusion handling. The kNN-based correlation mechanism is critical; replacing it with triplane-based correlation leads to significant performance degradation due to feature collisions and loss of geometric fidelity.

Figure 2: Qualitative comparison of multi-view 3D point tracking. MVTracker maintains correspondences and handles occlusions more accurately than baselines.
Scalability and Robustness
- Performance improves with more input views, reaching AJ = 79.2 with eight views on DexYCB.
- Robust to varying camera setups and depth sources (sensor, DUSt3R, VGGT).
- Inference speed: 7.2 FPS with sensor depth, suitable for near-real-time applications.
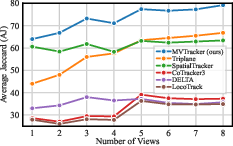
Figure 3: Effect of the number of input views on DexYCB. MVTracker scales efficiently with additional views.
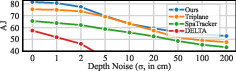
Figure 4: Robustness to depth noise N(0,σ2) on MV-Kubric. MVTracker maintains stable performance under moderate depth perturbations.

Figure 5: Visualization of predicted tracks under different depth sources, demonstrating adaptability to depth estimation quality.
Limitations and Future Directions
MVTracker's reliance on depth quality is a key limitation; sparse-view depth estimation can be unreliable, especially in unbounded or outdoor scenes. Joint depth and tracking estimation, or foundation models for 4D reconstruction, are promising future directions. Scene normalization and generalization to arbitrary environments require further research, as does the acquisition of large-scale real-world training data. Self-supervised learning and integration with foundation models for geometry may enhance robustness and applicability.
Conclusion
MVTracker introduces a practical, feed-forward approach to multi-view 3D point tracking, leveraging kNN-based correlation in a fused 3D point cloud and transformer-based refinement. It achieves state-of-the-art performance across diverse datasets and camera configurations, with strong scalability and robustness to occlusion and depth noise. The method provides a foundation for real-world applications in robotics, dynamic scene reconstruction, and scalable 4D tracking, and sets a new standard for multi-view 3D tracking research.

