RoMa v2: Harder Better Faster Denser Feature Matching
Abstract: Dense feature matching aims to estimate all correspondences between two images of a 3D scene and has recently been established as the gold-standard due to its high accuracy and robustness. However, existing dense matchers still fail or perform poorly for many hard real-world scenarios, and high-precision models are often slow, limiting their applicability. In this paper, we attack these weaknesses on a wide front through a series of systematic improvements that together yield a significantly better model. In particular, we construct a novel matching architecture and loss, which, combined with a curated diverse training distribution, enables our model to solve many complex matching tasks. We further make training faster through a decoupled two-stage matching-then-refinement pipeline, and at the same time, significantly reduce refinement memory usage through a custom CUDA kernel. Finally, we leverage the recent DINOv3 foundation model along with multiple other insights to make the model more robust and unbiased. In our extensive set of experiments we show that the resulting novel matcher sets a new state-of-the-art, being significantly more accurate than its predecessors. Code is available at https://github.com/Parskatt/romav2







































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces RoMa v2, a computer program that can “match” every pixel in one photo to the same spot in another photo of the same place. Think of two pictures taken from different angles or at different times: RoMa v2 figures out which tiny dots (pixels) in one image correspond to the same real-world points in the other image. It does this more accurately, more quickly, and in more difficult situations than previous methods.
Objectives
The researchers wanted to solve three main problems:
- Make pixel matching more accurate, even at very fine detail (sub-pixel precision means accuracy smaller than a pixel).
- Make it work in tough real-world cases, like big viewpoint changes, different lighting, motion, and even different camera types.
- Make it faster and use less computer memory so it can be used in practical systems.
They also asked: Can we predict how “uncertain” each match is, so later steps (like building 3D models) can use that information to get better results?
Methods and Approach
What is “dense feature matching”?
Imagine two photos of the same scene. Dense matching tries to draw a tiny arrow (called a “warp”) for every pixel in photo A that points to where the same object appears in photo B. It also outputs a confidence score for each pixel, which tells how sure it is that the match is correct (like a trust meter from 0 to 1).
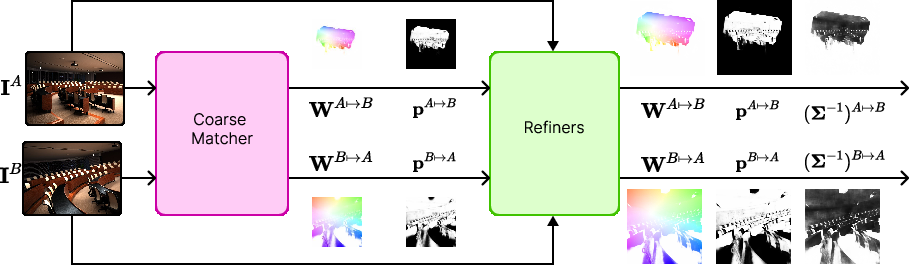
How RoMa v2 works (two stages)
RoMa v2 uses a two-step pipeline:
- Matching (coarse step): It finds a good approximate match for each pixel.
- Refinement (fine step): It polishes those matches to be extremely precise (down to sub-pixel accuracy).
To understand the images, RoMa v2 uses features from a powerful pre-trained vision model called DINOv3. Think of DINOv3 as a “super eye” trained on tons of images; RoMa v2 uses its vision but doesn’t change it (the DINOv3 part is “frozen”), which helps generalize to unusual situations.
Inside the matcher, RoMa v2 uses a Transformer (a type of neural network that looks at many parts of both images at the same time and learns patterns) to compare patches (small tiles) across images. It then predicts a rough warp and confidence. The refiners are like careful editors that adjust the warp to be as precise as possible.
Key improvements in RoMa v2
Here are the main upgrades, explained in everyday terms:
- New matching objective: The model learns both “where” pixels should go (warp regression) and “which patch is best” (a similarity-based loss). This helps it understand multi-view context—basically, how two images relate.
- Two-stage training: The matching part is trained first, and then the refinement part. This makes training faster and more stable.
- Frozen DINOv3 features: By reusing strong, pre-trained features without changing them, the model becomes more robust to strange lighting, different styles, and unusual scenes.
- Faster, lighter refiners: A custom GPU kernel reduces memory use during a heavy operation (local correlation), and smarter design choices speed things up.
- Better training data mix: They trained with both “wide-baseline” pairs (challenging viewpoint changes) and “small-baseline” pairs (tiny movements) to be strong in both tough angles and fine details.
- Predictive uncertainty (covariance): For each pixel, the model predicts not just the match but also how uncertain it is in two directions (left-right and up-down). This helps later steps trust good matches more and down-weight risky ones.
- Reduced sub-pixel bias: During training, tiny systematic errors can creep in. Using EMA (exponential moving average) reduces these small biases and sharpens precision.
- Resolution robustness: The model still works well if input images are different sizes, thanks to careful position encoding and scaling strategies.
Main Findings and Why They’re Important
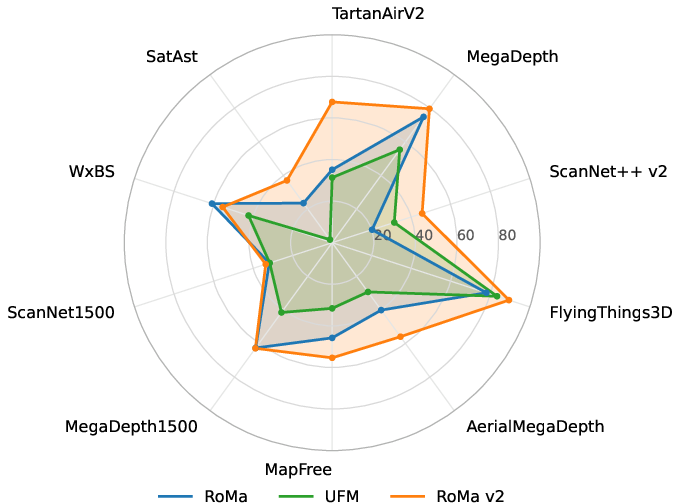
Across many tests, RoMa v2 is more accurate and more robust than previous dense matchers (including the earlier RoMa and the faster UFM), and it’s faster than RoMa:
- Pose estimation (figuring out camera angles between two photos): On popular benchmarks like MegaDepth-1500 and ScanNet-1500, RoMa v2 reaches or sets state-of-the-art performance among matchers, matching or surpassing feedforward 3D models in some cases.
- Dense matching quality: On six different datasets (including tough ones with big viewpoint changes and motion), RoMa v2 had lower error and higher accuracy at tight thresholds (1, 3, 5 pixels) than both RoMa and UFM.
- Speed and memory: RoMa v2 runs about 1.7× faster than RoMa with similar memory use, and uses much less memory than UFM while staying competitive in speed.
- Uncertainty helps downstream: Using the predicted per-pixel uncertainty to weight residuals in geometry estimation gives big improvements (for example, much higher AUC@1° in Hypersim), meaning better final 3D pose results.
- New hard test (SatAst): On astronaut-to-satellite image matching—a very tricky case with big rotations and scale changes—RoMa v2 outperforms previous dense matchers.
In simple terms: RoMa v2 can match pixels more precisely, in more situations, and more quickly. And it tells you which matches to trust, which boosts your results in later steps like building a 3D model.
Implications and Potential Impact
This kind of dense, reliable matching is a core building block for:
- Visual localization (helping phones, robots, or AR devices know where they are by looking around).
- 3D reconstruction (turning many photos into accurate 3D models of buildings, rooms, or landscapes).
- Mapping and navigation for drones and self-driving cars (especially with uncertain or low-texture surfaces like roads).
- Scientific and industrial imaging (matching across different sensors or viewpoints).
Because RoMa v2 is both accurate and faster, it’s more practical for real-world systems. The added uncertainty estimates make downstream algorithms smarter and safer—they can rely more on confident matches and be careful with uncertain ones.
Finally, while RoMa v2 is slightly less robust than the original RoMa for some extreme modality changes (like infrared-to-RGB), it’s still much stronger than speed-focused methods, and the overall balance of accuracy, speed, and robustness makes it a powerful tool for many applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that future work could address to strengthen and generalize RoMa v2.
- Multi-modal robustness: The model is less robust than RoMa on extreme modality changes (e.g., IR↔RGB in WxBS). What training strategies (e.g., targeted multi-modal datasets, adapters/LoRA on frozen backbones, modality-specific heads) can recover or surpass RoMa’s cross-modal performance without sacrificing other gains?
- Satellite/astronaut matching: SatAst is small (39 pairs, augmented to 156 via rotations). How well does RoMa v2 generalize to broader satellite sources (multi-sensor, multi-resolution, multi-season, multi-angle), larger rotations, and scale changes? Is rotation invariance needed, and what architectural or training changes would best achieve it?
- Evaluation on extreme viewpoint benchmarks: The paper cites RUBIK as highlighting weaknesses of prior methods but does not evaluate on it. Does RoMa v2 improve on RUBIK (and similar large-baseline/viewpoint benchmarks) and what failure modes remain?
- Calibration of uncertainty: The per-pixel covariance predictions are shown to help RANSAC/pose refinement, but their calibration is not evaluated. Are the predicted covariances well-calibrated (e.g., NLL, ECE, coverage tests), and how do they behave under domain shift and large residual regimes?
- Covariance training constraints: Covariance is trained only on covisible regions with residuals < 8 px and residuals are detached. What is the impact of these constraints on uncertainty quality? Can stable end-to-end training (without detaching) or curriculum/robust losses improve uncertainty learning?
- Additivity of precision across scales: The hierarchical “precision additivity” assumption is not theoretically justified or empirically ablated. Does additive precision across refiners hold, and are there better fusion strategies (e.g., learned fusion, Bayesian updates with independence checks)?
- Confidence vs covariance: The interplay between overlap confidence p and covariance is unexplored. Can joint calibration/learning of p and Σ improve downstream geometric estimation (e.g., robust BA) or sampling strategies in RANSAC?
- Two-stage training vs end-to-end: Matchers and refiners are trained separately for speed. Does joint end-to-end fine-tuning yield further accuracy/robustness, and how can training be stabilized (e.g., loss design, gradient routing) to avoid past GP-related instability?
- Matching loss design: The auxiliary NLL (patch-level dense directional loss) may struggle under repetitive textures or ambiguous matches. How sensitive is performance to the NLL formulation (e.g., temperature, hard/soft positives, contrastive margins) and negative sampling choices?
- Attention and positional encoding choices: The coarse matcher uses alternating attention and does not use cross-frame RoPE. Would cross-frame relative positional encodings or other positional schemes yield stronger multi-view context, especially under extreme viewpoint changes?
- Resolution generalization: Refiners are trained only at 640×640. How does fine-resolution performance scale beyond this, across aspect ratios, and on very high-res inputs? Is multi-resolution training for refiners beneficial and affordable?
- Data mixture and sampling weights: The curated dataset mix (with specific weights) is not systematically ablated. What is the optimal composition/weighting, and can automated curriculum or sample reweighting (e.g., active learning, domain balancing) improve generalization across tasks (aerial, indoor, AD, dynamic scenes)?
- Dynamic scenes and non-rigid motion: The method handles small-baseline optical flow but is not explicitly evaluated on large non-rigid motion or multi-object dynamics. Can motion segmentation/rigidity priors or multi-hypothesis matching improve reliability in dynamic environments?
- Occlusions and cycle consistency: Overlap labels are derived from depth consistency or warp cycle consistency, but explicit cycle losses are not enforced. Would incorporating cycle-consistency losses and improved occlusion modeling enhance match reliability?
- DINOv3 freezing vs adaptation: Freezing the backbone improves robustness, but the trade-off with lightweight adaptation (e.g., adapters, partial fine-tuning) is not explored. Can modest adaptation recover cross-modal/OD generalization while preserving robustness?
- Patch size and stride impacts: Moving from DINOv2 (14) to DINOv3 (16) patch size with stride-4 matching refiner changes the spatial granularity. What is the effect of backbone patch size and stride choices on subpixel precision and runtime across datasets?
- EMA bias fix: The subpixel bias is mitigated via EMA, but the root cause is unclear. What induces the bias (loss curvature, optimizer dynamics, architectural asymmetries), and are alternative remedies (e.g., symmetric losses, debiasing layers) more principled?
- Runtime portability and hardware variability: Runtime/memory are reported on an H200; results on consumer GPUs, embedded hardware, and CPUs are missing. How do performance and memory scale across devices and resolutions, and what optimizations (quantization, pruning, kernels) improve portability?
- Custom CUDA kernel portability: The local-correlation CUDA kernel reduces memory, but cross-platform robustness and maintenance are untested. Are there fallback or vendor-agnostic implementations (e.g., Triton, XLA) that retain efficiency?
- Downstream integration: Relative pose improves, but full SfM/BA/SLAM integration is not evaluated. How much do covariance-weighted correspondences improve end-to-end reconstruction/localization pipelines at scale, and what interfaces (APIs, formats) facilitate adoption?
- Confidence calibration for correspondence sampling: The thresholding/sampling of p influences pose estimation. Is p calibrated (e.g., reliability diagrams), and can calibration or learned sampling policies improve robustness and reduce outliers?
- Domain shift breadth: While the mix covers many domains, key OOD areas (night, adverse weather, underwater, medical imaging) are not evaluated. How does RoMa v2 perform under these shifts, and what training data/augmentations are most effective?
- Robustness to repetitive/texture-poor regions: The model shows gains on roads and some texture-poor surfaces, but failure modes in repetitive patterns (facades, grids) are not analyzed. Can explicit priors or anti-ambiguity mechanisms (e.g., global context constraints) help?
- Fairness and geographic bias: Aerial datasets and MapFree may bias scene types and locations. Are there biases in geographic coverage or environment types that affect generalization? How can data curation mitigate this?
- Reproducibility details: Many training/GT generation details are relegated to supplementary material. A standardized protocol (data splits, GT generation, loss schedules) and public ablations would aid reproducibility and comparative research.
Practical Applications
Immediate Applications
The following applications can be deployed now using RoMa v2’s open-source implementation, improved accuracy/speed, and new predictive covariance outputs. Each item names a sector, a concrete use case, and specific tools/workflows, followed by key assumptions and dependencies that affect feasibility.
- Sector: software/photogrammetry
- Use case: replace or augment matchers in Structure-from-Motion (SfM) pipelines for more accurate and denser correspondence (e.g., for COLMAP variants, OpenSfM forks, custom reconstruction stacks).
- Tools/workflows: drop-in dense matching stage; bidirectional warps; covariance-weighted residuals in RANSAC and bundle adjustment; leverage the custom CUDA local-correlation kernel to reduce GPU memory.
- Assumptions/dependencies: two views must capture the same scene with sufficient co-visibility; quality depends on GPU availability; outputs follow a Gaussian residual model (for covariance weighting).
- Sector: robotics/autonomy
- Use case: improved visual odometry and pose estimation in texture-poor environments (roads, indoor corridors), especially under wide baselines or rotations.
- Tools/workflows: integrate RoMa v2 for real-time frame-to-frame matching; use predicted per-pixel covariances to downweight unreliable residuals; run decoupled matching-refinement for lower latency on embedded GPUs.
- Assumptions/dependencies: sufficient illumination and image quality; motion blur inflates predicted covariances; dynamic objects can break static-scene assumptions.
- Sector: AR/VR and mobile
- Use case: more robust feature alignment for camera tracking, relocalization, and scene reconstruction in AR headsets and smartphones.
- Tools/workflows: swap existing matcher (e.g., LoFTR/SuperGlue) with RoMa v2; leverage resolution robustness for varied device camera streams; use EMA-trained refiners to reduce subpixel bias.
- Assumptions/dependencies: access to GPU or performant mobile accelerators; consistent intrinsics for pose estimation; real-world IR-RGB matching still challenging in extreme modality gaps.
- Sector: aerial mapping and surveying
- Use case: robust alignment of aerial imagery (air-to-ground) with large rotations and viewpoint changes for photogrammetry and change detection.
- Tools/workflows: use RoMa v2’s robustness to AerialMegaDepth-style baselines; batch pipelines for orthomosaic creation; covariance-based weighting to improve downstream geo-registration accuracy.
- Assumptions/dependencies: requires overlap between views; radiometric differences and extreme seasonal changes can degrade correspondence; camera metadata/intrinsics help downstream geo-referencing.
- Sector: remote sensing/GIS
- Use case: astronaut-to-satellite and satellite-to-satellite alignment for annotation transfer, ground-truth curation, and mosaic creation (SatAst benchmark).
- Tools/workflows: dense homography estimation via RoMa v2; AUC@10px reprojection metrics; incorporate covariance to identify uncertain regions for manual QA.
- Assumptions/dependencies: large scale differences and rotations; multi-sensor domain shift (e.g., IR-optical, SAR-optical) may require retraining or domain adaptation.
- Sector: construction/architecture/cultural heritage
- Use case: more accurate multi-view alignment for building scans, heritage digitization, and progress monitoring.
- Tools/workflows: dense matcher in multi-view photogrammetry; use per-pixel confidences to mask occlusions; use covariance for uncertainty-aware measurements.
- Assumptions/dependencies: sufficient texture or structural detail; occlusions handled via overlap masks; downstream reconstruction stack must accept dense correspondences and uncertainty.
- Sector: media/VFX
- Use case: camera tracking and match-moving with improved correspondence density and subpixel accuracy.
- Tools/workflows: integrate RoMa v2 in tracking pipelines for difficult shots (blur, rotations); use refiners at stride {4,2,1} for high-res accuracy; exploit resolution robustness to reduce retakes.
- Assumptions/dependencies: consistent lens calibration; motion blur increases covariance (usable for adaptive weighting rather than failure).
- Sector: education/research
- Use case: baseline for teaching dense matching; plug-and-play matcher for benchmarking new SfM/VO algorithms; dataset curation strategies.
- Tools/workflows: adopt two-stage training for rapid iteration; use the NLL auxiliary loss and multi-view transformer; employ EMA to suppress subpixel training noise; replicate dataset mixing to balance wide/small baseline generalization.
- Assumptions/dependencies: reproducibility depends on dataset availability (MegaDepth, Hypersim, AerialMD, etc.) and compute resources.
- Sector: policy/public-sector (mapping and disaster response)
- Use case: rapid aerial image alignment for damage assessment and situational awareness.
- Tools/workflows: batch processing with RoMa v2 for dense mosaics; uncertainty maps via covariance to prioritize human review.
- Assumptions/dependencies: timely access to aerial imagery; domain shifts (smoke, debris) may need fine-tuning; legal/privacy constraints on data.
Long-Term Applications
The following directions require additional research, scaling, domain adaptation, or productization. Each item notes the sector, potential product/workflow, and key feasibility constraints.
- Sector: autonomous driving
- Application: end-to-end, uncertainty-aware visual localization and map alignment at fleet scale.
- Emerging tools/workflows: integrate predictive covariance into real-time SLAM/BA; cross-sensor fusion (camera–LiDAR–radar) with covariance propagation; city-scale batch mapping.
- Assumptions/dependencies: extensive multi-domain retraining for nighttime/weather; rigorous system-level validation; compute-efficient inference on automotive-grade hardware.
- Sector: healthcare/medical imaging
- Application: dense registration across modalities (e.g., endoscopy sequences, cross-device optical imaging, thermal-to-visible in clinical settings).
- Emerging tools/workflows: adapt RoMa v2’s multi-view transformer to medical foundations; incorporate domain-specific losses; uncertainty maps for clinical decision support.
- Assumptions/dependencies: strong multi-modal generalization needed; regulatory approval; curated medical datasets; explainability and reliability requirements.
- Sector: remote sensing/Earth observation
- Application: cross-sensor dense alignment (optical–IR–SAR), multi-temporal change detection with uncertainty quantification.
- Emerging tools/workflows: domain-adapted backbones (frozen or fine-tuned) for multi-spectral inputs; covariance-aware geo-registration standards; GIS plugins that consume per-pixel uncertainty layers.
- Assumptions/dependencies: substantial domain gaps and speckle noise (SAR); standardized data formats and metadata; collaboration with geospatial standards bodies.
- Sector: AR/VR and consumer devices
- Application: real-time SLAM using dense matches on low-power hardware.
- Emerging tools/workflows: lightweight variants of RoMa v2 (quantized/refactored kernels); streaming multi-view transformer with temporal memory; on-device EMA stabilization.
- Assumptions/dependencies: accelerator-specific optimization; thermal and power limits; privacy-preserving on-device computation.
- Sector: robotics/industrial inspection
- Application: automated inspection of textureless surfaces with dense alignment under challenging lighting and motion.
- Emerging tools/workflows: active-light augmentation plus RoMa v2 matching; adaptive covariance thresholds to trigger re-capture; integration with robotic path planning.
- Assumptions/dependencies: safety-certified pipelines; domain-specific retraining for reflective/featureless materials; integration with PLC/industrial systems.
- Sector: software/vision infrastructure
- Application: uncertainty-aware SfM and VO standards; tooling for covariance propagation across pipelines.
- Emerging tools/workflows: define APIs for passing per-pixel covariance/precision; standardize residual weighting in RANSAC/BA; extend to multi-view sequence-level covariance fusion.
- Assumptions/dependencies: community adoption; interoperability with existing libraries; empirical validation across diverse datasets.
- Sector: education/research
- Application: general methods design guidance from paper insights.
- Emerging tools/workflows: design of multi-view transformers using frozen foundation features; dataset-mixing strategies to achieve both wide-baseline robustness and subpixel precision; resolution-normalized positional encodings; CUDA primitives for local correlation in dense matchers.
- Assumptions/dependencies: continued availability of foundation models; reproducible training rigs; sustained maintenance of open-source codebases.
- Sector: policy/public-sector
- Application: standards for uncertainty reporting in automated mapping/assessment pipelines.
- Emerging tools/workflows: guidelines to incorporate per-pixel covariance in damage assessments; protocols for human-in-the-loop review based on uncertainty maps; procurement requirements mandating uncertainty-aware outputs.
- Assumptions/dependencies: stakeholder training; auditability and traceability; transparent model documentation and governance.
Cross-cutting assumptions and dependencies
- Co-visibility and static-scene assumptions: dense matching presumes overlapping views of the same 3D scene; dynamic objects and occlusions require careful handling via confidence masks and downstream filtering.
- Domain gaps and modality changes: while robust to many conditions, extreme cross-modality (e.g., IR-to-RGB, SAR-to-optical) may need domain adaptation or fine-tuning.
- Hardware constraints: throughput and memory depend on GPU class; the custom CUDA kernel reduces memory for local correlation but requires compatible environments.
- Uncertainty modeling: covariance predictions assume approximately Gaussian residuals; heavy-tailed noise or systematic biases may require robust loss functions downstream.
- Data and licensing: training mixes influence generalization; adoption may be constrained by data access, licensing, and privacy regulations.
Glossary
- AUC: Area Under the Curve; a metric summarizing accuracy across pose or error thresholds. "Measured in AUC (higher is better)."
- bidirectional dense image warps: Two 2D displacement fields mapping pixels in both directions between two images. "We estimate bidirectional dense image warps "
- Charbonnier loss: A robust regression loss used to penalize residuals smoothly. "Following RoMa we use a generalized Charbonnier loss~\cite{barron2019general} which for each refiner reads"
- Cholesky factors: Lower-triangular factors used to parameterize positive-definite matrices. "mapping these to Cholesky factors as $l_{11} = \softplus(z_{11})+10^{-6}$, , $l_{22} = \softplus(z_{22})+10^{-6}$"
- confidence mask: Per-pixel probability indicating match validity or overlap. "and a confidence mask "
- co-visible: 3D points that are visible from both camera viewpoints. "i.e., that are co-visible, and $0$ for occluded pixels."
- Dense Prediction Transformer (DPT): A transformer head for dense prediction tasks (e.g., warps, confidence). "Dense Prediction Transformer (DPT)~\cite{ranftl2021vision} heads output coarse warps between the images and confidences "
- DINOv3: A foundation Vision Transformer feature encoder used as frozen features. "We upgrade the DINOv2~\cite{oquab2023dinov2} encoder used in RoMa to the newer DINOv3~\cite{siméoni2025dinov3}."
- EPE: Endpoint Error; average Euclidean distance between predicted and ground-truth displacements. "EPE~"
- Exponential Moving Average (EMA): A moving average over parameters to reduce bias or variance. "a simple way to fix it is to simply use an Exponential Moving Average (EMA)\footnote{See~\citet{izmailov2018averaging} for discussion regarding different variants.}."
- Gaussian Process (GP): A non-parametric probabilistic regression model. "relies solely on Gaussian Process (GP)~\cite{rasmussen2003gaussian} regression"
- homography: A planar projective transformation mapping points between two images. "we use RANSAC to obtain a homography and compute AUC@10px of the reprojection error"
- kernel density estimate: A non-parametric density estimator used for balanced sampling. "we also sample a balanced subset of matches using their kernel density estimate approach."
- kernel nearest neighbor matcher: Matching by kernelized similarity and nearest-neighbor selection. "training a single linear layer on the features followed by a kernel nearest neighbor matcher."
- Multi-view Transformer: A transformer that attends across multiple images/views. "input to a Multi-view Transformer utilizing alternating Attention."
- negative log-likelihood: Loss corresponding to maximizing probability under a model. "add an auxiliary target, $\mathcal{L}_{\text{NLL}$, to minimize the negative log-likelihood of the best matching patch in image B for each patch in image A."
- optical flow: A per-pixel motion field between images or frames. "the training of wide-baseline dense matching is unified with the related task of optical flow."
- overlap loss: A loss function for predicting matchability/covisibility masks. "We use the same overlap loss $\mathcal{L}_{\text{overlap}$, and weighting factor, as in RoMa."
- PCK: Percentage of Correct Keypoints within a pixel threshold. "Measured in PCK (higher is better)."
- precision matrix: The inverse covariance matrix encoding per-pixel uncertainty. "we additionally predict a precision matrix ."
- RANSAC: Random Sample Consensus; robust model fitting under outliers. "Given estimated correspondences from a model, we use RANSAC to obtain a homography"
- RoPE: Rotary Position Embeddings used in transformers to encode positions. "Following DINOv3~\cite{siméoni2025dinov3} we use RoPE~\cite{rope} on a normalized grid, rather than a pixel grid."
- robust regression loss: A regression loss designed to be less sensitive to outliers. "minimize the robust regression loss between its predicted warp and the ground truth warp."
- Softplus: A smooth function ensuring positivity, often used in parameterizations. "$l_{11} = \softplus(z_{11})+10^{-6}$"
- softmax: A normalized exponential function mapping scores to probabilities. "by first applying $\softmax$ over the second dimension of "
- Structure-from-Motion (SfM): Recovering camera poses and 3D structure from images. "Recovering 3D structure and camera parameters from images, or Structure-from-Motion (SfM)~\cite{hartley2003multiple},"
- sub-pixel precision: Accuracy finer than one pixel in the image grid. "while maintaining subpixel precision"
- UNet-like CNN: An encoder–decoder convolutional architecture with skip connections. "The refiners are fine-grained UNet-like CNN models"
- ViT (Vision Transformer): Transformer architecture for images using patch tokens. "DINOv3 ViT-L, and then applies a ViT-B Multi-view Transformer."
- warp: A 2D mapping (displacement field) that aligns pixels from one image to another. "in terms of a warp "
- warp confidence: Per-pixel confidence score for the predicted warp. "Brighter values mean lower warp confidence as output by the model."
- warp cycle consistency: Constraint that forward and backward warps compose to identity. "or from warp cycle consistency (for flow datasets)"
Collections
Sign up for free to add this paper to one or more collections.

