- The paper introduces GeoSR, a framework using geometry-unleashing masking and geometry-guided fusion to compel VLMs to use actionable geometry signals.
- The paper demonstrates that naive geometry token injection can hinder performance, while GeoSR achieves state-of-the-art results on both static and dynamic spatial benchmarks.
- The framework’s adaptive fusion and masking strategies offer practical insights for enhancing spatial reasoning without relying on expensive 3D reconstruction.
Geometry-Aware Spatial Reasoning in Vision-LLMs: An Expert Analysis of GeoSR
Motivation and Empirical Findings
Spatial reasoning in vision-LLMs (VLMs) is critical for applications demanding comprehension of spatial relationships, geometric layouts, and dynamic scene evolution. While recent paradigms inject geometry tokens—derived from pretrained 3D foundation models—into VLMs, standard token fusion and fine-tuning frequently yield marginal gains or even negative impact, particularly in dynamic settings. Empirical evaluation demonstrates that VLMs default to 2D appearance-driven shortcuts, relegating geometry to a dispensable auxiliary signal rather than actionable evidence.
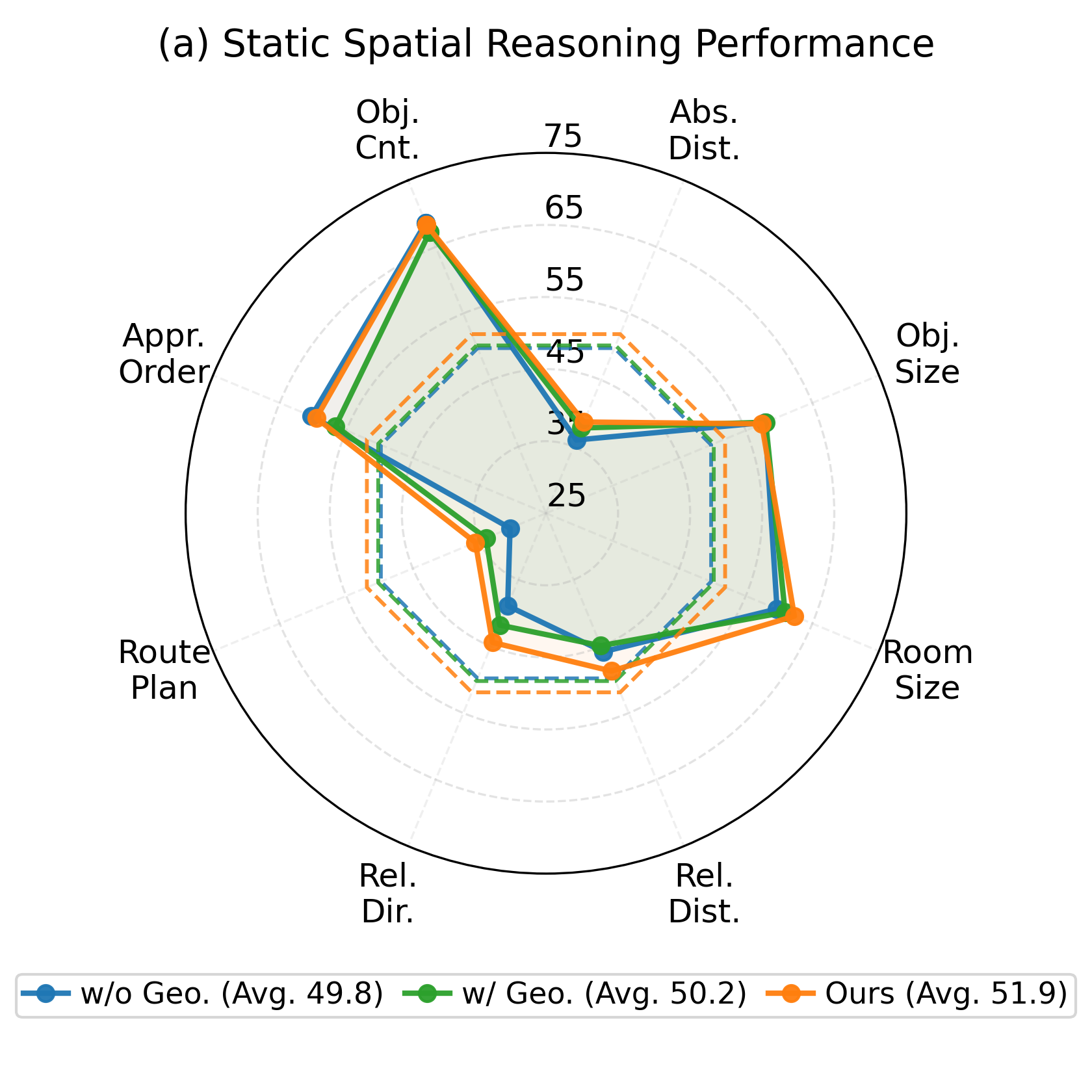
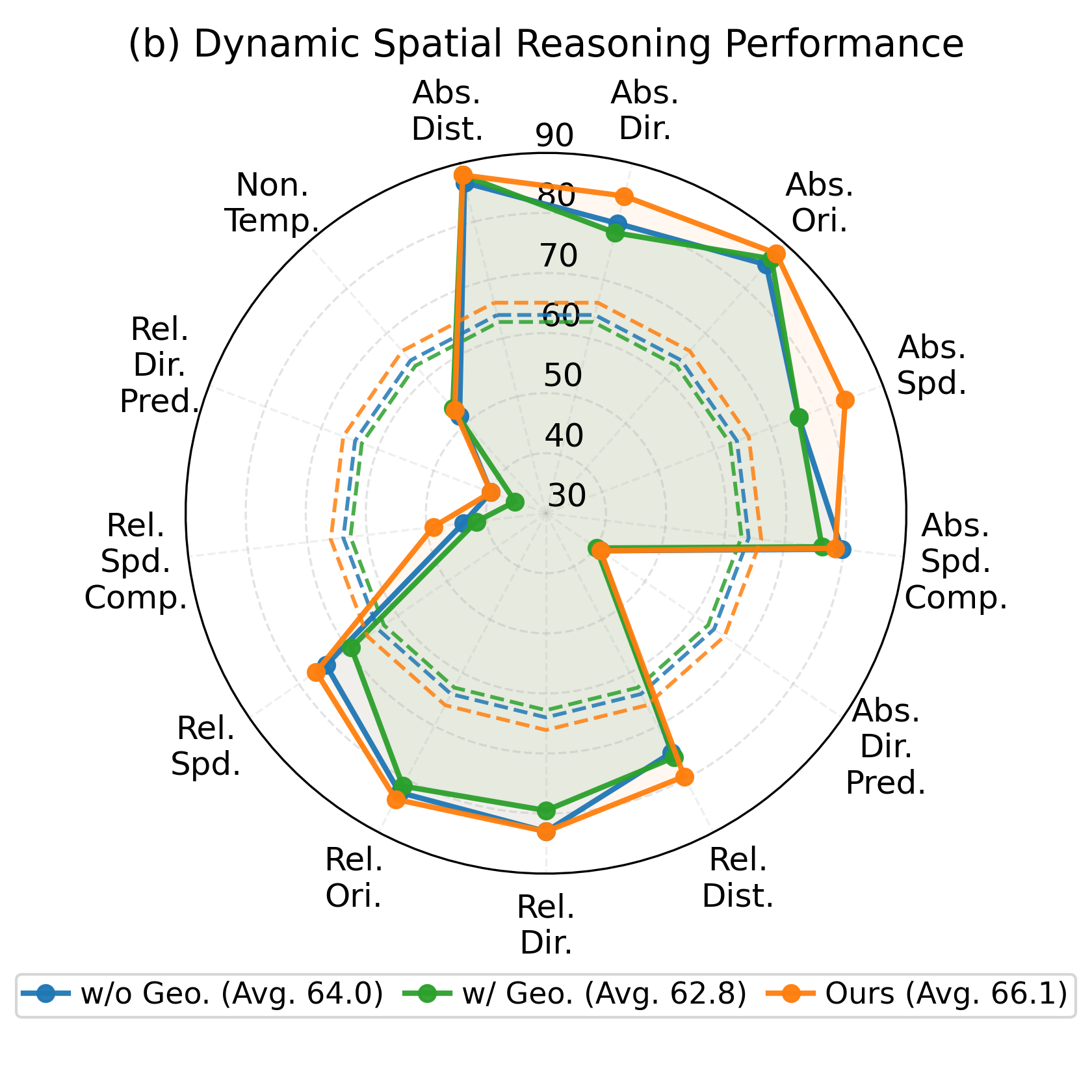
Figure 1: Marginal or negative impact of naive geometry token injection on spatial reasoning in static and dynamic benchmarks.
These results underscore the necessity for stronger architectural and training incentives to make geometric cues an integral part of spatial reasoning, avoiding the dilution inherent in indiscriminate fusion.
GeoSR Framework and Architectural Innovations
GeoSR (Geometry-aware Spatial Reasoning) addresses geometry utilization deficiencies in VLMs via two orthogonal strategies:
- Geometry-Unleashing Masking: This method strategically masks subsets of 2D vision tokens during training, suppressing appearance shortcuts and compelling models to leverage geometry tokens for spatial inference. For static scenes, visual tokens are randomly masked; for dynamic scenarios, masking is guided by query relevance, as calculated from attention weights on geometry tokens. This paradigm promotes geometry as the only salient evidence in masked regions.
- Geometry-Guided Fusion: GeoSR introduces a token-level, channel-wise gating mechanism that adaptively routes geometry information into fused representations. The learned gates amplify geometry contributions where geometric evidence is critical for answering spatial queries, ensuring geometry is not uniformly injected but dynamically reweighted.
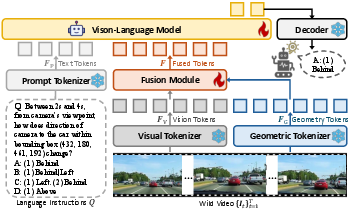
Figure 2: Geometry-aware framework: VLMs augmented with a geometry branch extracting 3D structural tokens fused into the main model.
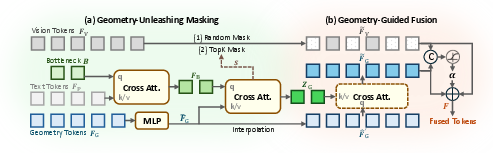
Figure 3: GeoSR architecture: masking suppresses appearance shortcuts, while adaptive fusion gates control geometry token impact.
The combined effect ensures both effective and context-sensitive integration of geometry, overcoming VLMs’ tendency to default to vision-centric reasoning.
Numerical Evaluation and Ablations
GeoSR achieves performance advances over prior spatial reasoning models and general-purpose VLMs on both static (VSI-Bench) and dynamic (DSR-Bench) datasets. Its superiority is observed across all spatial subtask types—numerical judgments, multiple-choice spatial queries, and dynamic relation inference—establishing new state-of-the-art scores.

Figure 4: Qualitative visualization of GeoSR’s static spatial reasoning accuracy on VSI-Bench.

Figure 5: Visualization of GeoSR’s dynamic spatial reasoning performance on DSR-Bench.
Ablation experiments reveal several critical insights:
- Naive geometry token fusion not only fails to exploit geometric evidence but may harm dynamic spatial reasoning performance—sometimes outperforming models with indiscriminate geometry injection.
- GeoSR’s masking mechanism (Geometry-Unleashing Masking) is required to suppress vision-driven shortcuts, compelling models to utilize geometry.
- Adaptive fusion (Geometry-Guided Fusion) is necessary for fine-grained, context-specific geometry utilization; neither masking nor fusion alone can deliver peak performance.
Sensitivity analysis confirms that the effectiveness of masking is robust to hyperparameters controlling mask ratio and masking probability, with only minor computational overhead relative to baseline models.
Benchmark Limitations and Qualitative Analysis
Evaluation benchmarks present ambiguities and annotation inconsistencies that affect absolute performance metrics. Certain spatial questions are fundamentally ambiguous from a geometric perspective, causing ground-truth answers to be disputable even for geometry-aware models.

Figure 6: Example ambiguity in speed comparison; video evidence is geometrically inconclusive for a definitive answer.

Figure 7: Example of spatial relation ambiguity due to occlusion and unclear geometric evidence.
GeoSR’s explicit geometry utilization makes the model’s reasoning more transparent in such cases, but further improvement in dataset construction and annotation is required to facilitate progress in this area.
Theoretical and Practical Implications
GeoSR demonstrates that geometry tokens—when made actionable—yield significant improvements in spatial reasoning for both static and dynamic visual scenes. The framework validates the hypothesis that geometry priors must be not just injected but actively promoted through architectural and training constraints to overcome shortcut learning. This suggests broader implications for multimodal model design: mere augmentation with rich modalities does not guarantee utilization, and tailored incentive structures are needed to activate non-visual cues.
Practically, GeoSR enables robust spatial reasoning in scenarios with only monocular visual input, obviating the need for costly multi-stage 3D reconstruction or additional sensors. Theoretically, the paradigm highlights the necessity for adaptive fusion and shortcut suppression, pointing toward future architectures with more nuanced, context-sensitive modality routing.
Future Directions
Opportunities for further research include:
- Advancing dataset quality with reduced ambiguity and improved geometric ground-truth alignment.
- Extending geometry-aware architectures to other complex spatial-temporal inference tasks beyond Q&A.
- Investigating cross-modal gating and adaptive fusion methods in broader multimodal settings, including agentic reasoning and spatial navigation.
- Exploring gradient-based geometry utilization incentives and explicit regularization terms during training.
Conclusion
GeoSR establishes that geometry tokens are underutilized or harmful under naive fusion in spatial reasoning tasks. Through strategic masking and adaptive fusion, the framework compels VLMs to treat geometry as actionable evidence, delivering consistent and substantial improvements in spatial reasoning benchmarks. These findings offer actionable guidance for future multimodal model design, emphasizing the importance of modality-specialized incentives and fusion mechanisms for robust spatial-temporal reasoning (2603.26639).

