Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Abstract: Vision-LLMs (VLM) excel at general understanding yet remain weak at dynamic spatial reasoning (DSR), i.e., reasoning about the evolvement of object geometry and relationship in 3D space over time, largely due to the scarcity of scalable 4D-aware training resources. To bridge this gap across aspects of dataset, benchmark and model, we introduce DSR Suite. First, we propose an automated pipeline that generates multiple-choice question-answer pairs from in-the-wild videos for DSR. By leveraging modern vision foundation models, the pipeline extracts rich geometric and motion information, including camera poses, local point clouds, object masks, orientations, and 3D trajectories. These geometric cues enable the construction of DSR-Train for learning and further human-refined DSR-Bench for evaluation. Compared with previous works, our data emphasize (i) in-the-wild video sources, (ii) object- and scene-level 3D requirements, (iii) viewpoint transformations, (iv) multi-object interactions, and (v) fine-grained, procedural answers. Beyond data, we propose a lightweight Geometry Selection Module (GSM) to seamlessly integrate geometric priors into VLMs, which condenses question semantics and extracts question-relevant knowledge from pretrained 4D reconstruction priors into a compact set of geometry tokens. This targeted extraction avoids overwhelming the model with irrelevant knowledge. Experiments show that integrating DSR-Train and GSM into Qwen2.5-VL-7B significantly enhances its dynamic spatial reasoning capability, while maintaining accuracy on general video understanding benchmarks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI models to understand “4D” scenes—meaning 3D space changing over time. The authors call this dynamic spatial reasoning (DSR). For example, imagine a video of two bikes weaving through traffic while the camera is also moving. The AI needs to figure out where objects are, how they move, and how their positions change from different points of view. The paper introduces a full “suite” to make this possible: a way to build training data from real videos, a benchmark to test models fairly, and a small add-on module that helps AI focus on the right 3D information.
The main questions the paper asks
- How can we create lots of high-quality training data that teaches AI to reason about moving objects in 3D over time (4D), not just in still images?
- How can we test whether an AI truly understands dynamic scenes, including multiple moving things and different viewpoints?
- How can we add 3D knowledge to vision-LLMs (VLMs) in a smart way without hurting their general abilities?
How they did it
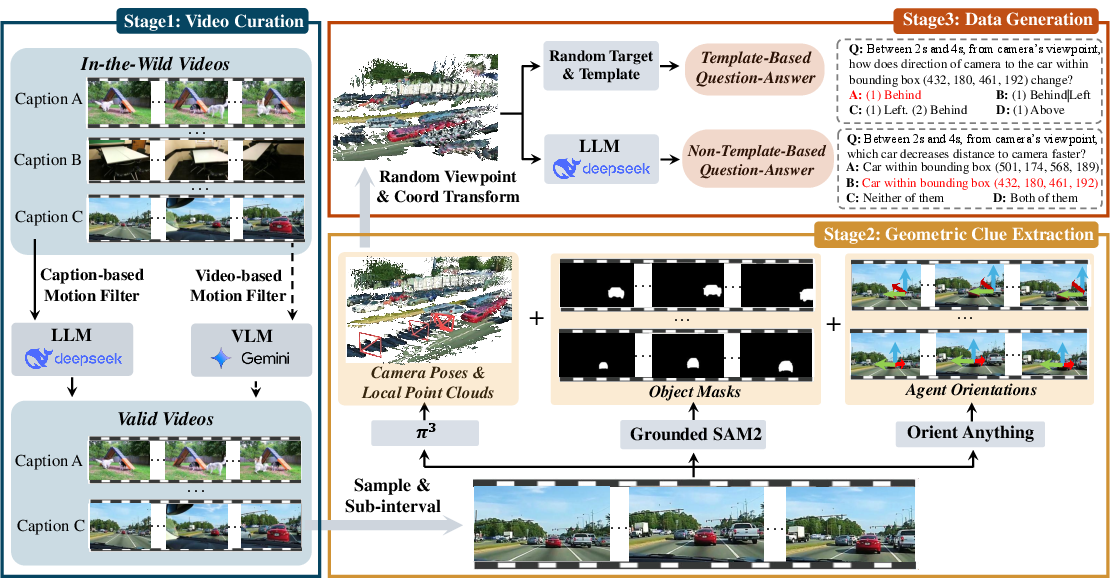
To answer these questions, the authors built “DSR Suite,” which has two big parts: a data pipeline (for training and testing) and a model add-on.
Part 1: A data pipeline that turns real videos into questions and answers
They created an automated three-step process to build two datasets: DSR-Train (for training) and DSR-Bench (for evaluation).
- Step 1: Pick the right videos
- They start from a huge set of real-world videos (called in-the-wild videos) and filter out boring ones where nothing really moves.
- For training, they keep 10,000 videos. For testing, they select 575 carefully chosen videos across topics like sports, driving, daily life, nature, and performances.
- Step 2: Pull out 3D clues from the videos
- Camera pose: where the camera is and which way it’s pointing.
- Point clouds: a “cloud” of 3D dots that shape the scene, like a 3D sketch.
- Object masks: outlines of objects in each frame, so the model knows which pixels belong to which thing.
- Object trajectories: the paths that objects follow through space over time.
- Orientations (for “agents” like people, cars, animals): which way they’re facing and rotating.
- These clues are extracted using strong vision models. Important note: the 3D they use is “relative” scale (good for comparisons like left/right, closer/farther), not exact measurements like meters.
- Step 3: Turn 3D clues into multiple-choice questions
- The pipeline creates questions that test skills like:
- Distance: Are two objects getting closer or farther?
- Direction: How does the direction of one object change relative to another?
- Orientation: How does an agent’s facing direction change?
- Speed: Is something speeding up, slowing down, or steady?
- Speed comparison: Who is faster?
- Direction prediction: Where will it move at the end?
- Viewpoints matter. A question can ask from:
- The camera’s view, or
- An agent’s view (for example, “from the runner’s point of view, is the bike moving left or right?”).
- Viewpoints can be:
- Absolute (fixed in place), or
- Relative (moving along with the observer), like how another car looks slower if you’re driving alongside it.
- Answers are qualitative and “procedural,” meaning they describe how things change over time (for example: “keeps steady, then becomes larger”) rather than giving a single number.
Beyond template-style questions, they also generate more natural, free-form questions to make sure language variety and real-world phrasing are covered.
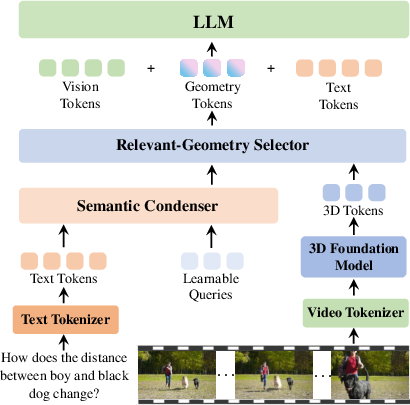
Part 2: A small, smart add-on to VLMs called GSM
The Geometry Selection Module (GSM) helps a vision-LLM use 3D info without getting overwhelmed. Think of it like a smart librarian:
- First, it reads the question and condenses its meaning to understand what is actually being asked.
- Then, it looks through all the 3D clues (camera pose, trajectories, etc.) and picks only the pieces relevant to the question.
- It packs this into a small set of “geometry tokens” (tiny bundles of information) and feeds them to the main model.
This prevents the model from being flooded with extra details and helps it focus, so it can improve at 4D reasoning while still staying good at general video understanding.
What they found
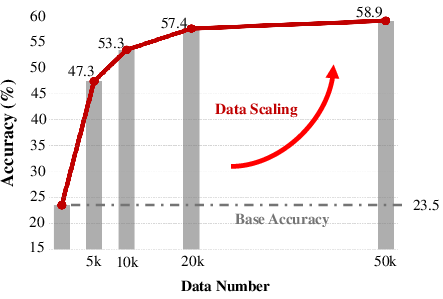
- Training a strong open model (Qwen2.5-VL-7B) on DSR-Train and adding GSM greatly improves the model’s ability to reason about moving objects in 3D over time.
- On their new test set (DSR-Bench), the improved model reaches state-of-the-art performance.
- Importantly, adding these 3D abilities does not ruin the model’s general skills on regular video understanding tasks, which can happen if you pour in too much unfiltered 3D data.
Why this matters:
- Most older benchmarks and methods focused on still scenes, single objects, short time spans, or one viewpoint. DSR-Bench includes multiple moving objects, longer videos, different viewpoints (including from moving agents), and fine-grained, step-by-step answers. This makes it much better for testing real-world spatial intelligence.
- The GSM approach shows you can add 4D understanding to general-purpose AI without breaking its other abilities.
Why this work is important
- For robots and self-driving systems: Understanding how things move around you—people, cars, balls, animals—from different viewpoints is essential for safe and smart behavior.
- For AR/VR and embodied AI: Systems need to reason about the 3D world as it changes, not just recognize objects.
- For AI assistants watching videos: They can answer deeper questions about motion, interactions, and “what happens next,” not just “what is in the frame.”
In short, this paper offers a practical recipe—better data and a focused model add-on—to help AI think in 4D. That brings AI a step closer to understanding the real, moving world the way people do.
Knowledge Gaps
Unresolved gaps and limitations
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper that future work could address:
- Absence of metric-scale 3D: The pipeline relies on relative-scale reconstruction, preventing quantitative reasoning (e.g., meters, degrees, acceleration). Evaluate and incorporate scale recovery via multi-view calibration, known-size priors, or sensor fusion (depth/IMU) to enable metric answers.
- Orientation limited to “agent” classes: Non-agent orientations are omitted to avoid spurious estimates. Develop robust orientation estimation for non-agents (e.g., vehicles, tools) and quantify how orientation errors affect DSR performance.
- Object localization via mask-mean centers: Using a mean of projected points as the 3D center ignores object extent and shape. Compare against 3D bounding boxes, robust centroiding, and instance-level point aggregation to reduce bias in large or thin objects.
- Procedural answer construction sensitivity: Answers are derived by merging adjacent qualitative states. Quantify sensitivity to sampling rate, sub-interval choice, and state-merging rules; explore adaptive segmentation tuned to motion dynamics.
- Limited question types: Current templates focus on distance, direction, speed, and orientation. Add interaction-rich tasks (e.g., collision/contact events, occlusion handling, containment, path crossing, following/avoidance, topological relations like inside/overlap) to broaden DSR coverage.
- Viewpoint scope: Viewpoints are restricted to camera or a single agent. Introduce global/world coordinates, third-person static anchors, and multi-agent viewpoints; assess invariance across viewpoint acceleration and rotations.
- Qualitative-only speed and distance: Transition from qualitative to quantitative (when metric is available) and evaluate hybrid settings (qualitative thresholds tied to metric estimates) to improve precision and calibration.
- LLM-based video filtering bias: Filtering via captions (train) and VLMs (bench) may exclude subtle or non-verbalized motion. Benchmark against motion analytics (optical flow, trajectory variance) and quantify selection bias and false negatives/positives.
- Noisy auto-labels in DSR-Train: The training set is not human-refined. Measure label noise rates, identify error modes (tracking, pose, orientation), and adopt noise-robust training (confidence weighting, bootstrapping, consistency checks).
- Frame sampling constraints: Training uses 32 frames per video and evaluation uses 1 FPS. Study sensitivity to temporal resolution, fast motion aliasing, and long-horizon memory; scale frame counts and test sliding-window vs. global-memory strategies.
- Benchmark scale and diversity: DSR-Bench has 575 videos and 1,484 questions. Expand the benchmark for statistical power, include edge cases (night, weather, motion blur, heavy occlusion, non-rigid motion), and add more domains beyond the six current categories.
- Reliance on specific priors (π3, SAM2, Orient Anything): Conduct controlled ablations across different 3D priors, quantify robustness to pose and segmentation noise, and evaluate cross-prior generalization of GSM.
- GSM generalization and portability: Validate GSM across multiple VLM backbones (beyond Qwen2.5-VL-7B), larger/smaller parameter scales, and alternative 3D priors; report compute cost, latency, and memory overhead for real-time applications.
- GSM interpretability: Provide visualizations of selected geometry tokens, measure selection precision/recall w.r.t. question-relevant 4D cues, and analyze failure cases where irrelevant geometry leaks or relevant cues are missed.
- Negative transfer analysis breadth: The paper claims GSM mitigates degradation on general benchmarks, but a broader suite and detailed ablations are missing. Systematically quantify trade-offs across many non-spatial tasks and input regimes.
- Robustness testing: Add adversarial and stress tests (heavy occlusion, motion blur, rapid camera shake, rolling shutter, non-rigid deformation, crowded scenes) and perturb 3D priors to measure DSR robustness and graceful degradation.
- Coordinate conventions and invariance: Standardize and document coordinate frames (camera/agent/world), sign conventions, and rotation representations; test invariance across reparameterizations and pose-estimation errors.
- Non-template question generation quality: Non-template items are LLM-generated from extracted cues. Audit their factuality, consistency, and linguistic diversity; introduce human refinement or rule-based checks for this subset.
- Evaluation protocol comparability: Ensure fair, reproducible comparisons to proprietary baselines (token budgets, prompt templates, fps, video length, context windows). Release detailed protocols to enable consistent benchmarking.
- 3D-awareness quantification via LLMs: The paper uses LLM judgments to tag 3D demand levels. Validate these tags with human experts and propose objective metrics (e.g., ablation of 3D cues and performance drop) for 3D requirement labeling.
- Sampling rate effects in DSR-Bench: Using 1 FPS may miss fast dynamics. Perform sensitivity analysis across fps settings and define per-video recommended sampling based on motion statistics.
- Pipeline compute and reproducibility: Report end-to-end runtime, hardware, and energy costs; release full prompts and scripts; quantify which stages dominate cost and propose optimizations (batching, caching, model distillation).
- Downstream transfer: Demonstrate how improved DSR translates to robotics/navigation/AR tasks (e.g., egocentric planning, collision avoidance), including sim-to-real evaluations and closed-loop performance.
- Physics and causal reasoning: Extend beyond geometric trends to force/contact modeling, momentum, acceleration, and causal predictions (e.g., “will collide,” “will topple”). Integrate lightweight physics priors or learned causal simulators.
- Multi-agent social dynamics: Move beyond pairwise comparisons to group behaviors (formation, flocking, overtaking, merging), and evaluate reasoning about intent and interaction patterns.
- Error analysis granularity: Provide per-question-type and per-cue error breakdowns (distance vs. direction vs. orientation), diagnose common failure modes, and tie them to specific priors or GSM components.
- Ethical and licensing considerations: Clarify Koala-36M licensing, consent, and privacy handling for in-the-wild videos; provide dataset cards detailing potential risks and mitigation strategies.
Glossary
- 3D foundation models: Large pretrained models that infer or encode 3D geometric information across scenes. "knowledge extracted from 3D foundation models, such as CUT3R \cite{wang2025continuous} and VGGT \cite{wang2025vggt}, are directly fused with vision tokens."
- 3D trajectories: Time series of 3D positions capturing how an object moves in space. "orientations, and 3D trajectories."
- 4D grounding: Aligning model representations to entities in 3D space over time (space + time). "enabling precise 4D grounding without compromising general multimodal understanding performance."
- 4D reconstruction priors: Learned spatiotemporal geometric knowledge from pretrained 3D/temporal reconstruction models. "pretrained 4D reconstruction priors"
- 4D-aware training resources: Datasets that include both 3D spatial and temporal information for supervision. "4D-aware training resources."
- Absolute viewpoint: A fixed observer reference frame that does not move over the considered time span. "or fixed to its status at one specific timestamp (absolute viewpoint)."
- Allocentric: A world-centered coordinate frame independent of the observer’s position. "egocentric-allocentric transformation"
- Azimuth: The horizontal rotation angle of an object relative to the camera’s frame. "azimuth, elevation, roll w.r.t. the camera"
- Camera poses: The position and orientation parameters of the camera for each frame. "camera poses, local point clouds"
- Cross-attention: A transformer mechanism where one sequence attends to another to fuse information. "direct cross-attention or naïve fusion"
- Dynamic spatial reasoning (DSR): Reasoning about how object geometry and relationships change in 3D over time. "dynamic spatial reasoning (DSR)"
- Egocentric-allocentric transformation: Converting between observer-centered and world-centered coordinate frames. "egocentric-allocentric transformation is a crucial aspect of spatial reasoning"
- Geometry Selection Module (GSM): A lightweight module that selects question-relevant geometric knowledge for VLMs. "Geometry Selection Module (GSM)"
- Geometry tokens: Compact token embeddings containing selected geometric information relevant to the query. "into a compact set of geometry tokens."
- Monocular footage: Video captured from a single camera without metric depth information. "we primarily process the monocular footage"
- Multi-object interactions: Situations where multiple objects move and influence spatial relationships. "multi-object interactions"
- Non-metric 3D structure: 3D geometry expressed without an absolute scale (only relative sizes/distances). "relative (non-metric) 3D structure"
- Point cloud: A set of 3D points representing scene surfaces, often produced by reconstruction models. "local point clouds"
- Procedural answers: Answers that describe the step-by-step evolution of a state over time. "fine-grained, procedural answers"
- Q-Former: A query transformer that condenses inputs or extracts targeted features via learned queries. "GSM adopts a dual Q-Former design"
- Relative-scale reconstructions: Reconstructions whose scale is not absolute but consistent up to an unknown factor. "relative-scale reconstructions"
- Relative viewpoint: A moving reference frame that follows an observer/agent over time. "viewpoint can follow the motion of its corresponding agent and evolve across time sub-interval (relative viewpoint)"
- Short-horizon motion: Motion observed over a brief temporal span, limiting long-term reasoning. "short-horizon motion"
- Viewpoint transformations: Changes of the coordinate frame used to describe spatial relations. "viewpoint transformations"
- Vision foundation models: Broad, pretrained vision models used to extract general-purpose visual and geometric cues. "leverages modern vision foundation models to extract camera poses, local point clouds, object masks, orientations, and 3D trajectories."
Practical Applications
Immediate Applications
The following items can be deployed now with the paper’s datasets (DSR-Train, DSR-Bench), pipeline, and the GSM module, leveraging relative-scale 4D geometric cues and multiple-choice QA generation.
- Dynamic spatial reasoning evaluation for VLMs
- Sector: software/AI, academia
- Potential tool/product/workflow: Integrate DSR-Bench into model evaluation pipelines (CI/CD) to track a model’s competence on multi-object motion, viewpoint transformations, and procedural answers; publish internal or public leaderboards for release gating.
- Assumptions/Dependencies: Availability of the benchmark videos and QA pairs; models capable of multi-frame/video comprehension; acceptance that evaluation focuses on relative (non-metric) spatial judgments.
- Fine-tuning general-purpose VLMs for dynamic spatial reasoning
- Sector: robotics, video analytics, media, software/AI
- Potential tool/product/workflow: Use DSR-Train to fine-tune existing VLMs (e.g., Qwen2.5-VL-7B) to improve “changing distance/direction/speed” understanding in moving, in-the-wild scenes; apply to internal analytics tools and prototypes.
- Assumptions/Dependencies: Compute budgets for video fine-tuning, licensing for DSR-Train data; willingness to accept qualitative, procedural labels over metric values; careful validation against non-spatial tasks to avoid regression.
- GSM module integration (“Geometry Selection Module”) to add targeted 4D priors without hurting general performance
- Sector: software/AI
- Potential tool/product/workflow: Add GSM’s dual Q-Former design to production VLMs to selectively filter question-relevant geometry tokens from pretrained 4D reconstruction priors; deploy as a plugin layer in inference stacks for spatial questions.
- Assumptions/Dependencies: Access to pretrained 3D/4D priors (e.g., pi3, VGGT); engineering capacity to integrate Q-Formers and geometry tokens; compatibility with model architectures and inference latency budgets.
- Automated domain-specific QA dataset creation from in-house videos
- Sector: security/surveillance, sports analytics, logistics/operations, education
- Potential tool/product/workflow: Run the paper’s pipeline on proprietary video collections to auto-generate multiple-choice QAs targeting dynamic motion (e.g., forklift-pedestrian interactions, athlete speed/direction changes, package flows). Use outputs for model training or internal auditing.
- Assumptions/Dependencies: Legal rights to process videos, privacy controls; robust segmentation and tracking (Grounded SAM2) in domain videos; sufficient object visibility across time; tolerance for relative-scale geometry.
- Video QA features in analytics dashboards (procedural motion descriptions)
- Sector: sports analytics, traffic monitoring, industrial operations
- Potential tool/product/workflow: Embed dynamic QA capabilities (“Did object A move left then speed up?”; “Did vehicle approach then pass behind the cyclist?”) into dashboards; export textual timelines of motion with qualitative states.
- Assumptions/Dependencies: Near-real-time inference may require frame subsampling and model distillation; handling occlusions and object entry/exit; calibration of confidence thresholds for alerts.
- AR egocentric assistance for viewpoint-transformed queries
- Sector: AR/consumer devices
- Potential tool/product/workflow: Provide AR users with relative-to-user motion answers (“Is the drone moving left relative to me, then rising?”) by transforming trajectories into egocentric coordinates using camera pose and agent orientation.
- Assumptions/Dependencies: Reliable pose estimation from monocular video; stable orientation for agent observers; acceptable latency on edge devices.
- Education content generation for motion and spatial reasoning
- Sector: education/EdTech
- Potential tool/product/workflow: Generate real-world, fine-grained motion QAs for physics or robotics courses from public videos (procedural answers emphasize state evolution); support assignments or auto-graded quizzes.
- Assumptions/Dependencies: Teacher review for correctness; proper selection of videos with clear motion and minimal occlusion; qualitative labels used for pedagogy rather than precise measurements.
- Smart home camera assistant for motion-related questions
- Sector: consumer/daily life
- Potential tool/product/workflow: Enable users to ask video questions like “Did the dog move closer to the baby?” or “Did the delivery person approach then leave?” with multi-object, viewpoint-aware reasoning.
- Assumptions/Dependencies: Privacy-preserving local processing; device compute constraints; household scenes with sufficient lighting and visibility.
- Video editing and media enrichment (motion tags and timelines)
- Sector: media/software tools
- Potential tool/product/workflow: Auto-tag segments where objects change speed/direction; generate motion timelines for highlights (e.g., “ball moves right → slows → reverses”); assist editors with search and annotations.
- Assumptions/Dependencies: Accurate multi-object tracking and segmentation; quality thresholds for consumer-facing outputs; domain adaptation for varied content (sports, vlogs, industrial footage).
- Research benchmarking and dataset curation for 4D reasoning
- Sector: academia
- Potential tool/product/workflow: Use DSR-Bench to study multi-viewpoint, multi-object dynamic reasoning; extend the pipeline to new domains (e.g., animal behavior); publish comparative studies on GSM vs. naïve fusion strategies.
- Assumptions/Dependencies: Community acceptance of qualitative, procedural answer format; reproducibility of pipeline outputs; consistent prompt protocols where LLMs are used in filtering/generation.
Long-Term Applications
These items require additional research, scaling (e.g., metric-accurate geometry, robust multi-sensor fusion), real-time performance, or broader validation and standardization.
- Embodied AI and robotics planning with 4D reasoning
- Sector: robotics, manufacturing, service robots
- Potential tool/product/workflow: Integrate GSM-enhanced VLMs as perception-reasoning modules that predict multi-object interactions and plan safe trajectories in dynamic environments (human–robot collaboration, warehouse robots).
- Assumptions/Dependencies: Real-time inference; metric-scale accuracy via sensor fusion (RGB+D/LiDAR/IMU); closed-loop control integration; safety certification and rigorous reliability testing.
- Autonomous driving decision support
- Sector: transportation/automotive
- Potential tool/product/workflow: Use dynamic spatial reasoning to anticipate multi-agent interactions (merging, overtakes, right-of-way conflicts) with procedural understanding; feed qualitative reasoning into driver assistance or high-level planners.
- Assumptions/Dependencies: Multi-camera and radar/LiDAR fusion for metric accuracy; domain-specific datasets beyond in-the-wild videos; stringent robustness, adversarial testing, and regulatory compliance.
- AR/VR world-aware assistants and training simulators
- Sector: AR/VR, education, industrial training
- Potential tool/product/workflow: Persistent, world-locked overlays that describe evolving object relations from user-selected viewpoints; training modules that teach situational awareness (e.g., crane operations).
- Assumptions/Dependencies: High-fidelity camera/inside-out tracking, persistent mapping, and orientation estimation; real-time GSM; user experience and safety constraints.
- Healthcare and eldercare motion monitoring
- Sector: healthcare
- Potential tool/product/workflow: Procedural motion analytics for fall risk, gait changes, and patient mobility patterns (“slows → turns right → sits”); alerts based on motion trajectories rather than single-frame detections.
- Assumptions/Dependencies: Clinical validation; privacy and HIPAA compliance; robustness to occlusions, cluttered interiors, and variable lighting; potential need for depth sensors for metric reliability.
- Safety compliance and incident prevention in logistics/industrial sites
- Sector: logistics, energy, manufacturing
- Potential tool/product/workflow: Predict hazardous interactions (e.g., forklift vs. pedestrian, tool swing arcs) with multi-object, viewpoint-aware reasoning; generate procedural near-miss reports.
- Assumptions/Dependencies: Multi-sensor coverage; rigorous thresholding for false positives/negatives; union/worker privacy agreements; integration with EHS workflows.
- Regulatory benchmarks and certification for video AI
- Sector: policy/regulation
- Potential tool/product/workflow: Standardize dynamic spatial reasoning tests (e.g., DSR-Bench variants) as part of certification suites for video AI systems in safety-critical domains; define minimum performance bars on multi-object/viewpoint tasks.
- Assumptions/Dependencies: Multi-stakeholder consensus; domain-specific extensions; governance for dataset provenance and bias; auditing infrastructure.
- Insurance and legal video forensics
- Sector: finance/insurance, legal
- Potential tool/product/workflow: Use procedural motion reconstructions to support claim assessments (e.g., “vehicle A approached, slowed, then turned left behind cyclist”) and liability determination.
- Assumptions/Dependencies: Auditable models with chain-of-evidence; metric accuracy in contested cases; legal admissibility and standards; domain adaptation to dashcam/CCTV footage.
- Content moderation and safety classification informed by kinematics
- Sector: online platforms
- Potential tool/product/workflow: Detect risky or violent interactions based on dynamic spatial patterns instead of static cues; escalate ambiguous cases using procedural motion descriptors.
- Assumptions/Dependencies: Bias and fairness testing; handling adversarial edits; large-scale deployment efficiency; clear policy mappings from motion patterns to moderation actions.
- Scientific video analysis (e.g., animal behavior, sports science)
- Sector: academia, sports medicine
- Potential tool/product/workflow: Study interaction patterns (chasing, flocking, formation changes) or athlete kinematics using procedural 4D descriptors; enable hypothesis testing at scale without fully supervised labels.
- Assumptions/Dependencies: Domain calibration for orientations and class taxonomies; improved tracking in cluttered natural scenes; potential need for metric refinement.
- Generalized selective-prior integration beyond geometry
- Sector: software/AI
- Potential tool/product/workflow: Extend GSM’s “text-guided selection” to other priors (audio spatialization, tactile, RF signals), creating modular reasoning stacks that prevent overfitting while adding targeted capabilities.
- Assumptions/Dependencies: Availability of robust foundation priors; training curricula for multi-prior coordination; latency and memory optimization.
- EdTech interactive physics laboratories
- Sector: education
- Potential tool/product/workflow: Simulate and assess motion with fine-grained procedural reasoning in student-captured videos; adaptive feedback on errors in reasoning about direction, speed changes, and trajectories.
- Assumptions/Dependencies: Classroom-ready tools and privacy controls; improved reliability across diverse student devices and scenes; curriculum alignment.
Notes on cross-cutting assumptions and dependencies:
- The pipeline and datasets primarily operate on relative (non-metric) 3D reconstructions from monocular in-the-wild videos; metric-scale applications will require additional sensors or calibration.
- Performance depends on upstream foundation models (e.g., Grounded SAM2, pi3, Orient Anything) for camera pose, segmentation, tracking, and orientation; occlusion, motion blur, and crowded scenes can degrade outputs.
- GSM integration presumes access to pretrained 4D priors and architectural compatibility (Q-Formers); real-time constraints may necessitate model compression or frame sampling.
- Legal, privacy, and licensing considerations are essential when processing in-the-wild or proprietary videos; consent and on-device processing may be required for consumer deployments.
Collections
Sign up for free to add this paper to one or more collections.