- The paper introduces a lightweight self-supervised framework that balances intra-video temporal consistency with inter-video semantic separability.
- The method leverages frozen image-pretrained encoders and a shallow projection layer enhanced with positional encoding augmentation to ensure robust temporal alignment.
- Empirical evaluations across diverse video tasks show improved accuracy and computational efficiency with only 0.59M trainable parameters.
Self-supervised Image-to-Video Representation Transfer: Balancing Intra-video Temporal Consistency and Inter-video Semantic Separability
Introduction
The paper "From Static to Dynamic: Exploring Self-supervised Image-to-Video Representation Transfer Learning" (2603.26597) investigates the transfer of pretrained image models to the video domain for efficient and effective representation learning. The central premise is the observed dichotomy between intra-video temporal consistency—requiring temporally coherent representations for objects within a video—and inter-video semantic separability, which demands representations remain discriminative across videos of different categories. The authors identify a trade-off between these properties, wherein heavy temporal adaptation or fine-tuning risks semantic collapse, while overly rigid parameter constraints impede temporal alignment.
To address this, the paper introduces a lightweight, self-supervised transfer framework incorporating a temporal cycle consistency loss and a semantic separability constraint. The framework operates atop frozen image-pretrained encoders, learning only a shallow projection layer. Theoretical analysis demonstrates that this architecture enables a quantifiable improvement in the balance between temporal consistency and semantic separability. Strong empirical results on a range of ViT-based image models and multiple video understanding tasks validate the efficacy and efficiency of the proposed approach, positioning the method as a paradigm for future image-to-video transfer learning research.
Framework and Methodology
The proposed method comprises two components: a frozen image-pretrained encoder and a learnable projection layer. The pipeline first encodes two randomly sampled frames from each video, generating patch-level representations. The lightweight projection layer—composed of a single linear layer and layer normalization—is trained to refine these features with two complementary objectives:
1. Temporal Cycle Consistency: Temporal alignment is enforced by constructing a cycle through two frames (forward: taf→tb, backward: tb→tab), maximizing the probability that patches return to their original spatial positions after the cycle. To avoid trivial positional shortcuts leveraged by ViT architectures, the authors introduce Positional Encoding Augmentation (PEA): backward frames are encoded with interpolated and cropped positional encodings, disrupting absolute position cues while preserving local structure.
2. Semantic Separability Constraint: To preserve cross-video discriminability and prevent feature collapse, the projection's output distribution is regularized using a Kullback-Leibler divergence constraint with respect to the frozen encoder's distribution, applied at the patch- and video-level. This regularization prevents catastrophic forgetting of the semantic structure inherited from the image pretraining stage.
The interplay between objectives is modulated by the regularization weight λ, which is theoretically shown to control the spectral attenuation of representation axes corresponding to high intra-video variance.
The overall architecture and the interaction between frames, encoders, and projection layer are depicted in Figure 1.
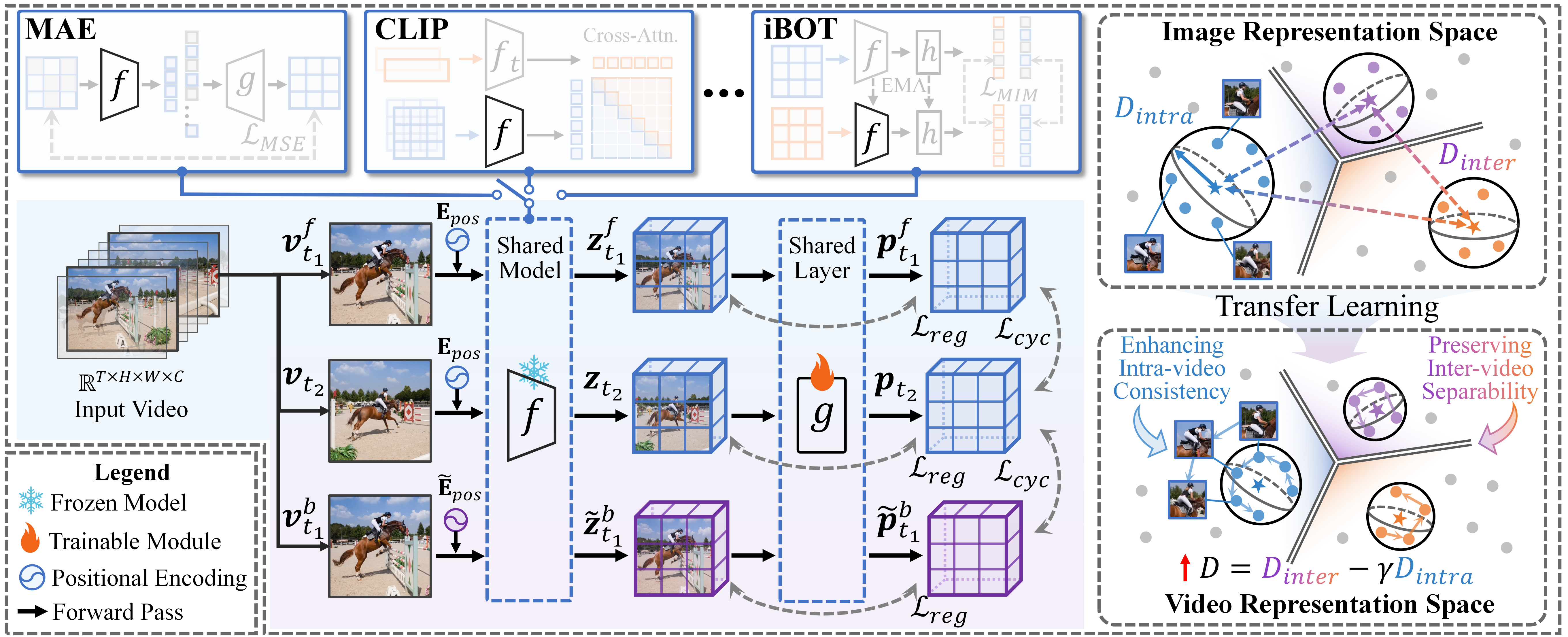
Figure 1: Image-to-video transfer learning pipeline combining frozen encoder features, a projection layer, temporal cycle-consistency loss, and semantic separability regularization.
Theoretical Analysis of the Trade-off
The authors provide a rigorous spectral analysis of the learned projection, treating both linear and shallow MLP settings. The core findings can be summarized as follows:
- Optimal Projection Spectral Behavior: The projection parameterizes a spectrum-wise soft-thresholding that selectively attenuates or amplifies feature directions based on intra-video covariance. Eigen-directions with variance above a threshold σi>2λ are suppressed, while those below are scaled, improving alignment without overly compressing discriminative axes.
- Trade-off Margin Improvement: By quantifying intra-video distance (Dintra) and inter-video distance (Dinter), the authors define the difference D=Dinter−γDintra as a trade-off margin. Theoretically, they prove that optimization of the projection layer under the proposed constraints guarantees a strict improvement in D, leading to better separation between dynamic invariance (temporal consistency) and semantic alignment.
- Linear vs. MLP Projectors: Analysis shows that the gain mostly arises from spectral scaling, and deeper projection networks offer little additional improvement over well-regularized linear layers.
The impact on the latent manifold is empirically confirmed in Figure 2.
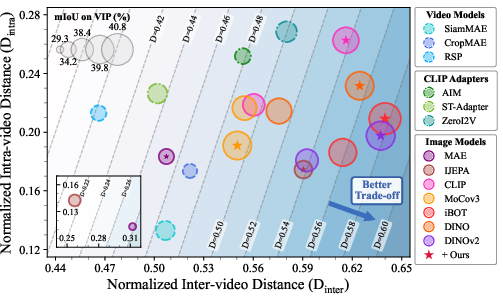
Figure 2: The proposed method consistently shifts representations toward simultaneously higher inter-video distance (semantic separability) and lower intra-video distance (temporal consistency), outperforming baseline models on Kinetics-400.
Empirical Evaluation
Benchmarks and Experimental Protocol
The approach is validated on eight ViT-based image-pretrained encoders spanning masked modeling, contrastive, and self-distilled paradigms (MAE, I-JEPA, CLIP, BLIP, MoCo v3, DINO, iBOT, DINOv2). Testing spans dense-level (DAVIS-2017, VIP, JHMDB), frame-level (Breakfast), and video-level (UCF101, HMDB51, SSV2, Chiral SSV2) tasks. The layer g is trained for only five epochs on Kinetics-400 with no task-specific annotation, in a fully self-supervised regime.
Main Results
- Dense-level Video Understanding: The method consistently delivers 1.98% (VIP), 2.63% (J, DAVIS-2017), and 2.59% ([email protected], JHMDB) performance improvements across all base encoders. Transfer from image models yields parity or superiority versus video-pretrained models, with significant computational savings.
- Frame-/Video-level Tasks: Strong, consistent gains are realized in action localization, video retrieval, and action classification. Notably, improvements hold for both unimodal and multimodal (CLIP, BLIP) foundations.
- Distance-based Metrics: Post-transfer, models exhibit substantially increased trade-off margins tb→tab0, driven by expanded inter-video distances without elevated intra-video variation, corroborating the theoretical predictions.
- Efficiency: The method requires only 0.59M trainable parameters, achieving a tb→tab1 speedup over parameter-efficient fine-tuning baselines and orders of magnitude less overhead than full video pretraining or heavy adapter-based adaptation. See Figure 3 and Table analyses.
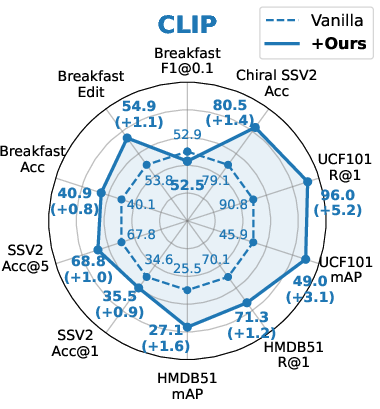
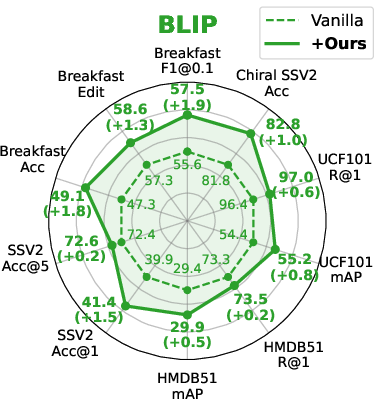
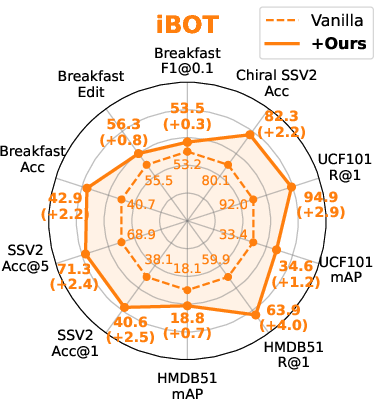
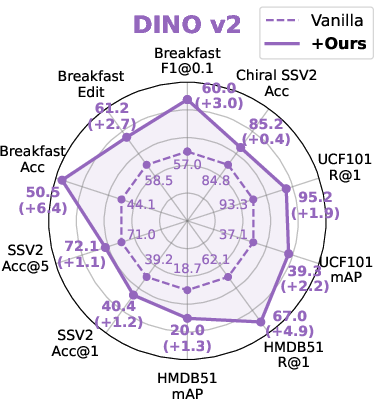
Figure 3: Performance assessment on representative downstream frame-/video-level tasks for CLIP, BLIP, iBOT, and DINOv2 backbones.
Integration and Qualitative Analysis
The method also enhances performance when dropped into complex video processing pipelines such as dense point tracking (on BADJA and TAP-DAVIS), with improved trajectory coherence and occlusion handling. Qualitative visualizations of cross-frame correspondences (Figure 4) and segmentation masks (Figures 9 and 10) highlight superior temporal feature alignment post-adaptation.

Figure 4: The learned cross-frame correspondence is robust, revealing meaningful patch-level relationships beyond simple positional matches.

Figure 5: Downstream segmentation masks obtained with MAE before and after transfer; improvements are pronounced for challenging, dynamic shots.

Figure 6: Downstream segmentation masks based on CLIP features, illustrating enhanced spatiotemporal structure via the proposed approach.
Ablation and Robustness
Comprehensive ablations demonstrate:
- PEA is essential to avoid shortcut solutions inherent in ViT architectures; omitting it collapses performance.
- The KL-based regularization is superior to stricter MSE or less constrained schemes for maintaining video-level semantic separability.
- The framework generalizes across patch sizes, cropping mechanisms, backbones (ViT-Base/Large/Huge), and is robust to moderate hyperparameter variations.
- Training for as few as five epochs is sufficient for convergence.
Cycle-consistency accuracy curves (Figure 7) further emphasize the effect of design choices on stable temporal alignment.
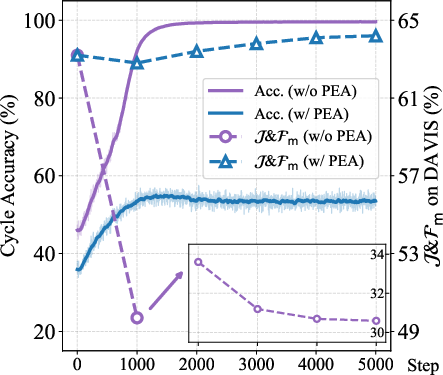

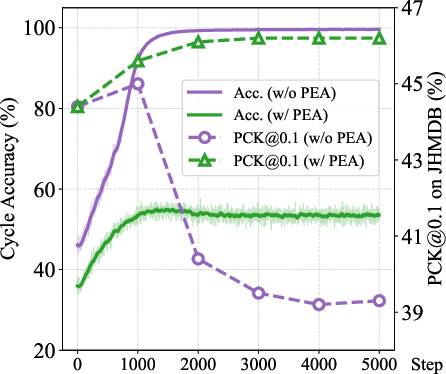
Figure 7: Training dynamics with/without PEA for MAE and DINO: proper regularization with PEA prevents collapse and fosters monotonic improvement in both cycle accuracy and downstream metrics.
Implications and Future Directions
This work demonstrates that judicious linear adaptation—guided by patch-level self-supervision and explicit semantic regularization—enables the deployment of frozen image-pretrained features for high-fidelity video understanding. The theoretical and empirical insights challenge the perceived necessity of heavy temporal modules and video pretraining. The findings suggest the viability of unifying visual representation learning across static and dynamic domains within lightweight, task-agnostic frameworks.
Future directions include extending this approach to alternative visual backbones (e.g., hybrid CNN/ViT, frozen large-scale foundation models), exploration of more expressive yet regularized projection mechanisms, and broader application in real-world spatiotemporal search, video-language alignment, and continual/lifelong learning regimes.
Conclusion
The presented framework efficiently and consistently advances the state of self-supervised image-to-video representation transfer by balancing the crucial trade-off between temporal consistency and semantic separability. The method's theoretical foundation, strong empirical performance, and high computational efficiency collectively mark it as a reference point for future research in efficient generic video representation learning (2603.26597).

