- The paper introduces VRE, a framework that transforms latent visual introspection into a reliable, information-gain-driven self-reflection mechanism.
- It leverages iterative self-distillation and RL-based refinement to enhance visual attention during complex reasoning tasks and mitigate visual drift.
- Empirical results show notable performance gains on high-resolution perception, OCR, and mathematical reasoning benchmarks compared to baseline models.
Motivation and Problem Identification
The paper identifies a recurring deficiency in current Multimodal LLMs (MLLMs): visual drift during long-form generation. As decoding progresses, these models exhibit a consistent tendency to reduce their reliance on visual tokens, increasingly defaulting to their internal textual priors. This leads to ungrounded and often hallucinated outputs, particularly when late-stage visual verification is required or when intricate visual evidence must be extracted. Prior efforts to mitigate this drift predominantly employ explicit mechanisms, such as patch-injection, token interleaving, or visual prompt markers. However, these interventions invariably disrupt the standard autoregressive pipeline and entail significant computational overhead.
The critical insight advanced here is the empirical evidence of latent implicit visual re-examination capabilities in MLLMs. Attention analysis demonstrates sporadic, prompt-contingent re-allocation of visual attention during later decoding stages—an ability that is present but not reliably or robustly activated.
Visual Re-Examination (VRE) Framework
The proposed solution, Visual Re-Examination (VRE), leverages this latent capacity through self-iterative training to endow MLLMs with stable, actionable visual introspection during multi-step reasoning—without requiring modifications to the architecture, external teacher models, or post hoc visual interventions.
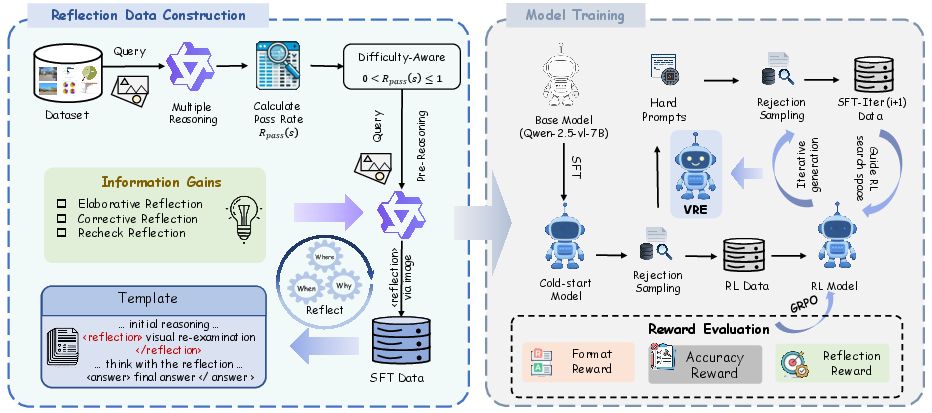
Figure 1: The Visual Reflection Enhancement (VRE) pipeline: difficulty-aware data filtering and information-gain-guided reflection synthesis yield high-quality SFT data, which is iteratively refined via reward-driven rejection sampling and RL.
The VRE pipeline initiates by generating stochastic rollouts from the base policy for each image-query pair. Samples are partitioned by the pass rate on their own distribution into three regimes: Stable, Intractable, and Unstable. The regime of primary interest is Unstable, reflecting cases at the model's cognitive-perceptual boundary.
For each trajectory, a two-stage reasoning format is enforced: an initial chain-of-thought followed by a <reflection> block. The reflection phase is synthesized by conditioning the model on its own prior reasoning and regenerating a response with a strict Information Gain criterion. Only traces that introduce additional or corrective visual evidence, rather than redundant paraphrasing, are retained via rejection sampling. This curation yields three reflection paradigms: Elaborative (broadening evidence), Corrective (rectifying errors), and Recheck (robustness verification).
RL with Structured Rewards and Iterative Self-Distillation
Subsequent to cold-start SFT, the model is optimized using Group Relative Policy Optimization (GRPO). The reward signal is a weighted sum of three components: format compliance, answer accuracy, and explicit reflection quality (as determined by LLM-based scoring of the reflection block's information gain). After RL, a post-training distillation phase exploits the improved model to recover and internalize correct strategies on hard prompts previously considered intractable.
Empirical Instantiation
All experiments are conducted with Qwen2.5-VL-7B as the backbone. Evaluation benchmarks are selected across four axes: visual mathematical reasoning, high-resolution perception, visual document extraction, and multi-disciplinary QA.
Mechanistic Analysis and Validation
Visual Attention Dynamics
Direct visualization of attention weights over visual tokens is employed to delineate the mechanism. The base model exhibits a monotonic visual decay as textual context accumulates, substantiating the onset of visual drift. In contrast, VRE induces a pronounced and synchronized resurgence of visual attention precisely within the <reflection> phase.
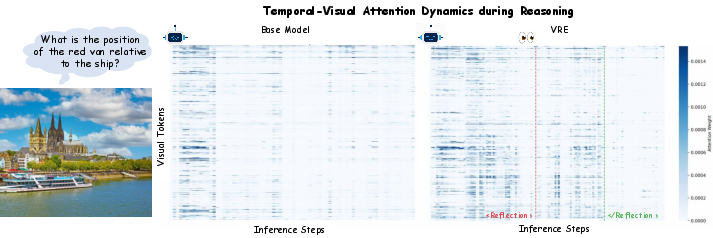
Figure 2: Attention weights: Whereas the base model's attention to visual cues collapses over time, VRE spikes visual attention during the reflection, explicitly triggering re-examination and evidence extraction.
Ablative analyses further illustrate that prior to RL, the reflection phase is frequently degenerate (no gain over initial reasoning). The introduction of the explicit reflection reward is necessary to consolidate an actionable visual re-examination policy.
Spatial Attention and Error Correction
Spatial attention heatmaps substantiate that during <reflection>, attention is not randomly reallocated but instead performs targeted visual searches to acquire missing or misperceived evidence.

Figure 3: Transition from visual blindness to precise re-grounding during reflection: the model correctly localizes previously missed image regions upon retriggered visual search.
Evolution of Introspection
Detailed introspection paradigm tracking reveals that RL and self-distillation systematically suppress degenerate, no-gain reflections in favor of meaningful corrective, elaborative, or verification-focused introspections. Task-specific trends emerge: corrective reflections dominate in fine-grained perception and complex reasoning, while elaborations are prevalent in dense-visual or OCR-centric datasets.
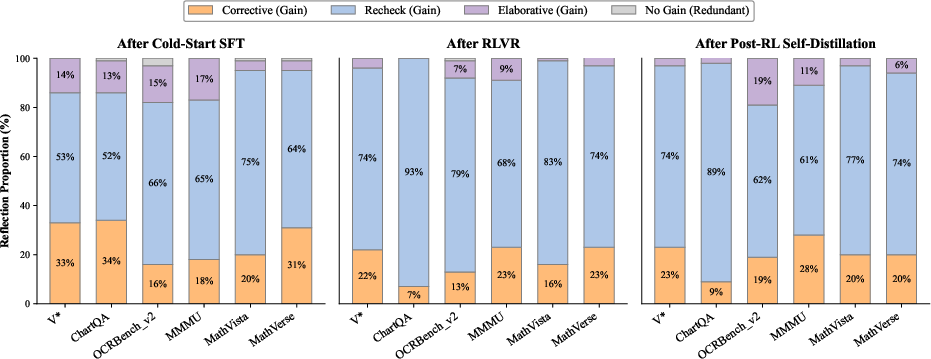
Figure 4: Distribution of reflection types evidences a shift toward high-utility visual introspection across training stages.
Sample-level KL divergence and conditional entropy analyses rigorously demonstrate the necessity of self-aligned reflection learning. Cross-model distillation—using an external teacher—incurs elevated KL divergence between the student's output distribution and its native manifold, indicating sub-optimal and distribution-shifting imitation. Conditional entropy of the VRE model's reflections is systematically higher than backbone baselines, confirming empirical information gain and the absence of degenerative redundancy.
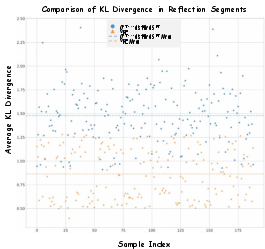
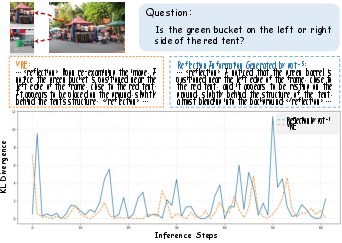
Figure 5: Sample-level KL divergence: self-evolving SFT with VRE produces trajectories more consistent with the model's intrinsic distribution than external distillation.
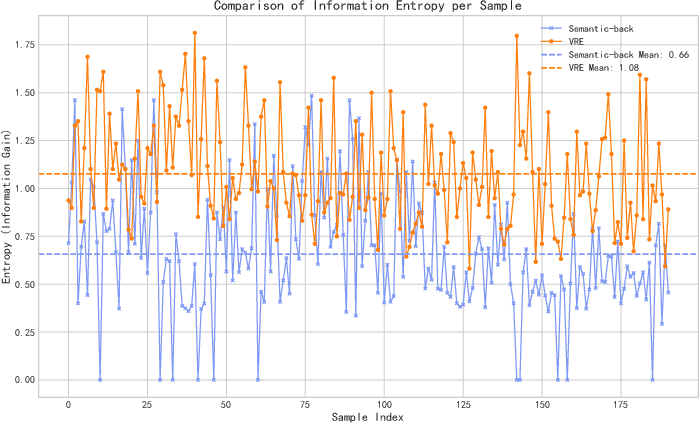
Figure 6: Information entropy in reflections: VRE maintains higher entropy, denoting introduction of novel evidence.
Empirical Results
VRE establishes strong performance on diverse benchmarks, outperforming explicitly augmented and tool-based models at comparable parameter scales. Absolute gains relative to the Qwen2.5-VL-7B baseline are substantial: +7.4% on the V∗-Bench high-resolution perception task, +5.1% on ChartQA, and up to +7.5% for OCRBench_v2. Mathematical and logical reasoning also see consistent advancement (MathVista: +3.0%, WeMath: +6.6%), with VRE approaching or surpassing several proprietary large-scale models.
Implications and Future Directions
Practically, VRE provides a resource- and architecture-efficient means to ameliorate visual drift, support information-dense reasoning, and reduce hallucination rates in MLLMs. Theoretically, the success of self-evolutionary, information-gain-driven introspection establishes a new paradigm for model improvement—moving away from teacher-driven distillation and explicit input intervention toward native policy alignment and continuous self-refinement.
Two immediate research trajectories emerge: (1) further controlling and formalizing the action space of introspective visual search within MLLMs, possibly with explicit spatial attention constraints or token masking; and (2) extending information-gain reflection to more complex, hierarchical, or real-world action and embodiment settings. Iterative, reflective RL with verifiable rewards is poised for continued impact in robust, generalizable multimodal reasoning.
Conclusion
This work demonstrates that VRE transforms latent, stochastic visual introspection in MLLMs into a learnable, policy-driven mechanism, rooted in information-theoretic regularization and continual RL-SFT cycles. The approach achieves high empirical performance, task-adaptive introspection strategies, and robust alignment with intrinsic model priors—without incurring computational or distributional liabilities associated with explicit interventions or teacher distillation. The findings lay a foundation for broader adoption of self-evolving, introspection-driven optimization in future multimodal AI systems (2603.26348).

