- The paper introduces a novel framework that combines ontology-guided extraction with multi-dimensional clustering and dual-channel fusion to advance multi-hop reasoning.
- It achieves significant performance gains, including a 22.45% F1-score improvement over vector-based RAG and 2.23% over LightRAG, especially in complex inference tasks.
- The study highlights a modular approach for domain adaptation and outlines future directions such as semi-automated schema induction and cross-modal integration.
UniAI-GraphRAG: A Unified Approach to Ontology-Guided Extraction and Multi-Dimensional Graph Reasoning
Introduction
Retrieval-Augmented Generation (RAG) approaches have improved factual grounding and reduced hallucinations in LLMs for knowledge-intensive tasks. However, their extension to complex multi-hop reasoning, especially in vertical domains with rich ontological structures (e.g., healthcare, finance, legal), remains inadequate due to generic schema-free extraction and limited community detection strategies. The UniAI-GraphRAG framework directly addresses these bottlenecks by integrating ontology-guided knowledge extraction, multi-dimensional clustering, and a dual-channel graph/semantic retrieval architecture, surpassing the limitations of prior systems such as LightRAG.
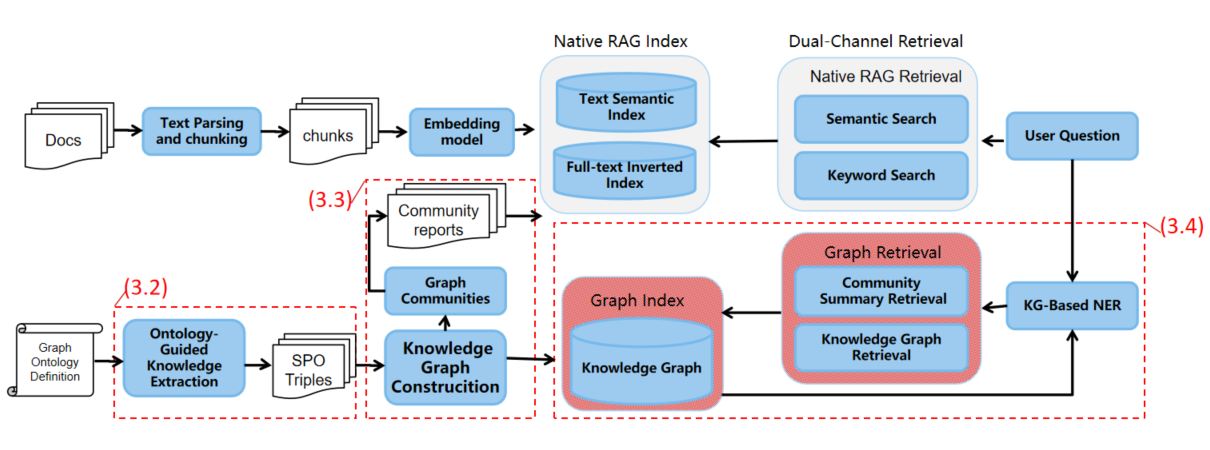
Figure 1: The UniAI-GraphRAG architecture: a pipeline integrating ontology-guided extraction, multi-dimensional clustering, and dual-channel fusion for robust multi-hop reasoning.
One of the central innovations is the ontology-guided extraction module, which explicitly conditions graph construction on expert-defined schemas encompassing entity types, relations, and constraint logic. Unlike schema-free open IE maximizing generic triple extraction probabilities, this approach enforces logical constraints via a triplet constraint space S=(E,R,Φ), where E and R denote allowed entity and relation types, and Φ imposes domain/range constraints over these relations.
The probability space of generated triples is constrained through:
P(t∣d,S)=∑t′∈Tallexp(SLM(t′,d))⋅I(t′∈VS)exp(SLM(t,d))⋅I(t∈VS)
This formulation restricts triple generation to those compliant with schema constraints, mitigating both hallucination and semantic noise. Evaluation demonstrates that this ontology-driven extraction not only limits spurious relations but also boosts entity-relation discovery rates in vertical knowledge discovery scenarios.
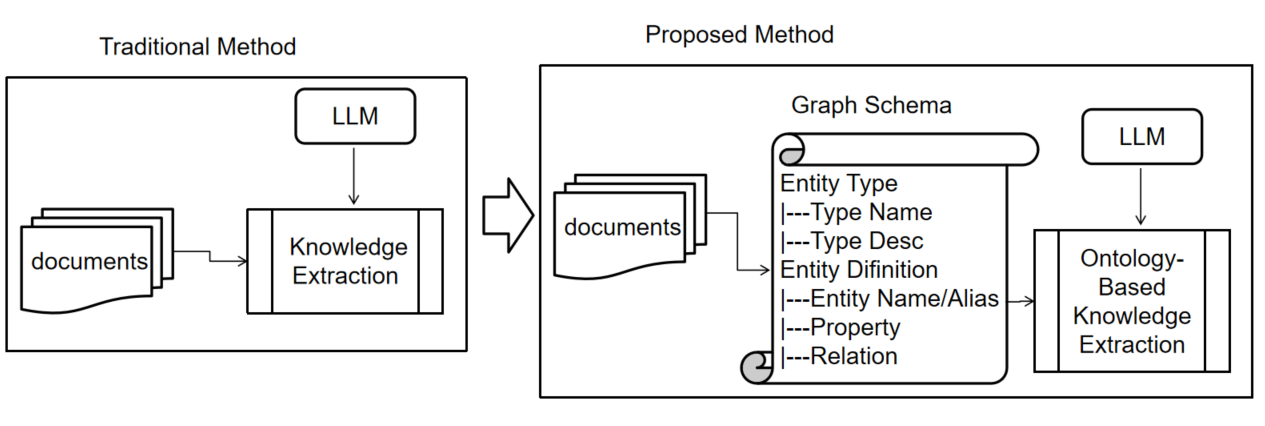
Figure 2: Knowledge extraction process leveraging schema-constrained prompts for high-precision entity and relation identification.
Standard graph-based RAG clustering (e.g., Leiden, Louvain) captures only topological neighborhoods, fragmenting business logic and overlooking semantically salient groupings (such as temporal, spatial, or causal). UniAI-GraphRAG introduces a multi-dimensional strategy with three core mechanisms:
- Alignment Completion: Edge and attribute backfilling for nodes severed by conventional clustering, preserving reasoning chains across community boundaries.
- Attribute-Based Clustering: Communities are formed not only by structure but also by semantically relevant attributes (e.g., "year", "location"), enhancing cluster completeness for queries like "Which products were released in Q2 2022?"
- Multi-Hop Relationship Clustering: Subgraphs are clustered by relational paths of configurable hop length, encapsulating the full context for multi-hop question answering.
A novel attribute-aware modularity function is defined as follows:
Qmulti=2m1i,j∑(Qijstruct+α⋅Sij)δ(ci,cj)
where Sij quantifies attribute similarity, and α balances structural versus semantic cohesion.
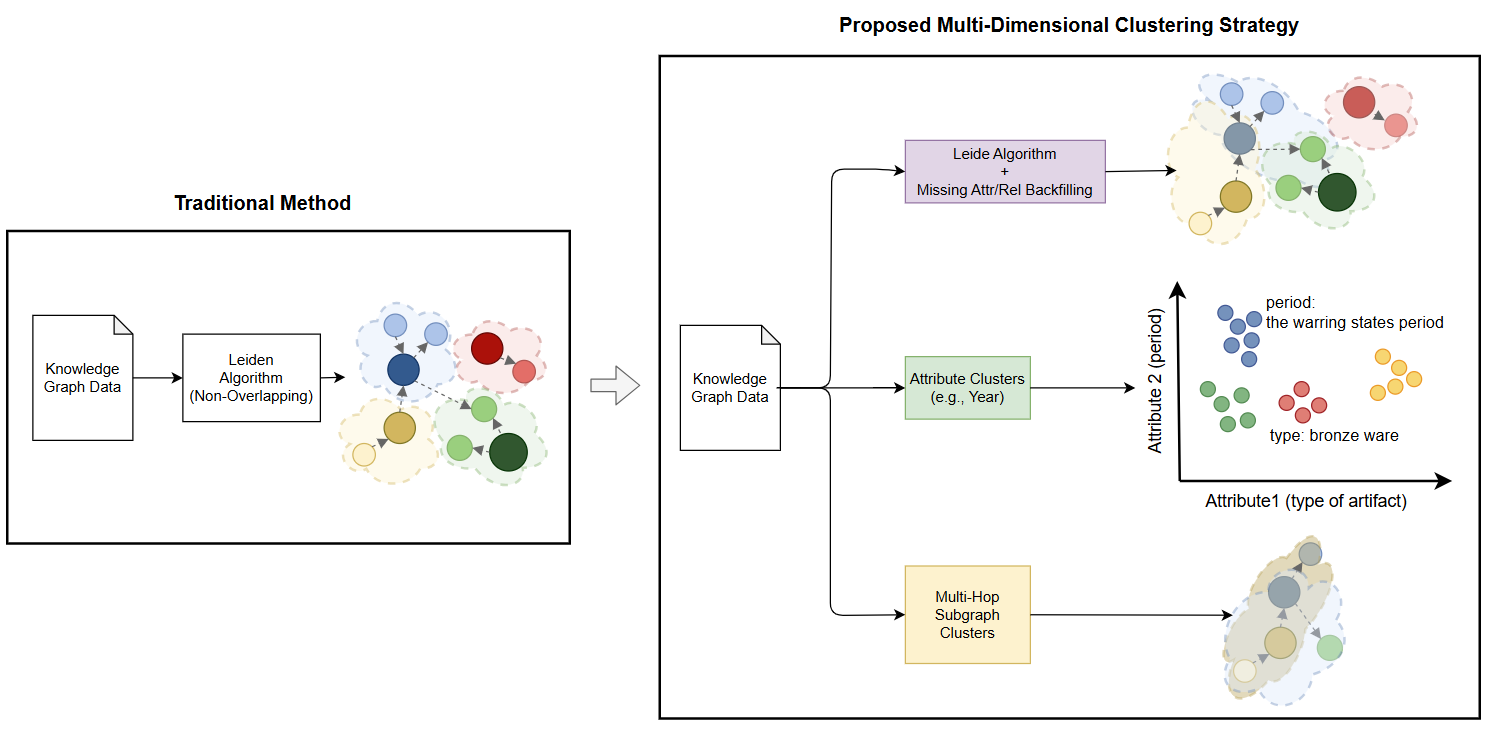
Figure 3: Multi-dimensional community detection: integrating structure, attribute, and relationship constraints to preserve reasoning chains across communities.
Boundary completion ensures, by an ϵ-neighbor mechanism, that critical adjacent nodes are included in summaries when sufficient cross-community connectivity is detected. Deep traversal enables pattern-based, N-hop clustering to provide maximal coverage for inference chains in multi-hop QA.
Dual-Channel Retrieval and Fusion
UniAI-GraphRAG introduces a dual-channel retrieval protocol, balancing fine-grained graph matching and coarse-grained community report recall. Channel 1 utilizes trie-based entity-attribute retrieval optimized for factoid queries, while Channel 2 matches semantic themes to multi-dimensional community summaries, optimal for summarization and relational queries. The overall retrieval score is combined with query-adaptive weighting:
Sfinal(di∣q)=β(q)⋅Sgraph(di∣q)+(1−β(q))⋅Ck:di∈CkmaxScomm(Ck∣q)
Here, β(q) is dynamically determined via entity density and semantic abstraction heuristics. The final reranking leverages a mutual information maximizing cross-encoder, increasing diversity and relevance by integrating micro- and macro-level retrieval signals.
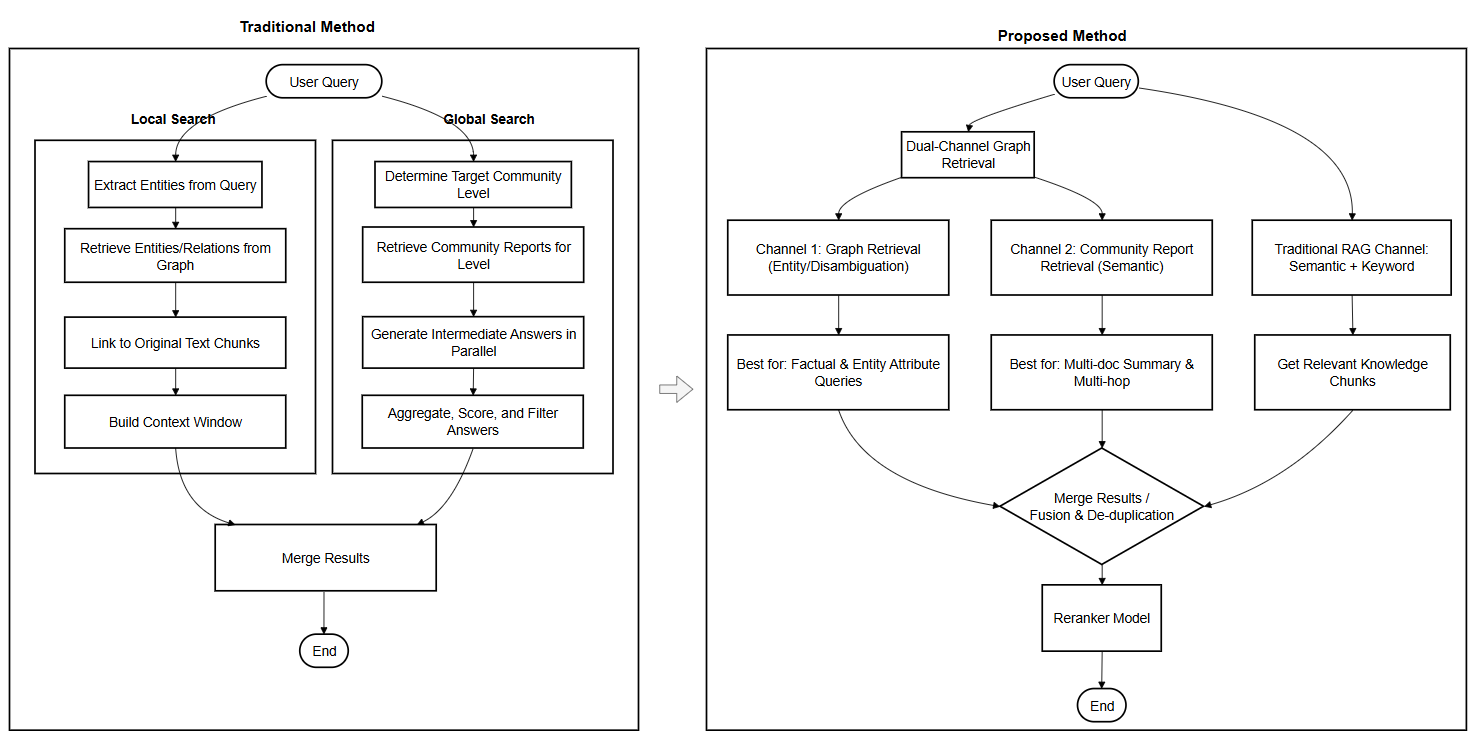
Figure 4: Dual-channel retrieval architecture: fusing entity-attribute graph retrieval with cluster-level community summarization for flexible query handling.
Experimental Results
Evaluation on the MultiHopRAG benchmark demonstrates consistent superiority of UniAI-GraphRAG over both classic and state-of-the-art GraphRAG baselines. Notably, the system achieves an F1-score improvement of 22.45% over naive vector-based RAG (Dify-RAG) and 2.23% over LightRAG, particularly excelling in inference and temporal queries due to its multi-hop clustering and adaptive retrieval fusion. Ablation studies attribute approximately 3.2–3.4% F1-score gains to each core component—ontology-guided extraction, multi-dimensional clustering, and dual-channel retrieval—underscoring their non-redundant contributions.
Implications and Future Directions
UniAI-GraphRAG demonstrates that precise schema-driven extraction, when coupled with semantically enriched clustering and adaptive retrieval fusion, eliminates key obstacles for complex, domain-specific multi-hop reasoning in RAG systems. The framework’s modularity enables sector-specific adaptation without retraining core LLMs, facilitating deployment in vertical domains.
Limitations include dependence on expert-crafted ontologies (limiting scalability) and lack of multimodal document integration. The extension to semi-automated schema induction and robust cross-modal entity/relation extraction represents an immediate direction. Adaptive windowing for chunked extraction is also identified as a crucial factor for future improvement.
Conclusion
UniAI-GraphRAG establishes a robust framework for domain-adaptable, multi-hop retrieval-augmented reasoning by synergistically integrating ontology-constrained extraction, multi-dimensional clustering, and adaptive dual-channel retrieval. This holistic approach not only achieves state-of-the-art performance but also exposes new pathways for generalizing schema-guided and community-aware graph reasoning in future AI systems.