- The paper presents DCBS as a deterministic algorithm for estimating near-verbatim extraction risk in language models.
- It integrates beam search with edit-distance constraints to efficiently capture risk beyond strict verbatim matches.
- Experimental results reveal that near-verbatim risk estimates significantly exceed traditional verbatim extraction, indicating heightened privacy and copyright concerns.
Introduction and Motivation
The assessment of memorization and data extraction risks in LLMs has become an essential area of study, particularly given the increasing deployment of open-weight and production-grade models across domains where privacy and copyright are significant. Prior approaches have focused primarily on verbatim extraction: determining the ability to reproduce training data exactly or with deterministic greedy decoding. However, these approaches can both underestimate the extent and risk profile of memorization. Notably, near-verbatim extraction—where small edits, insertions, or deletions separate model output from the training target—can be just as problematic for privacy or copyright, yet is missed by standard methods.
This paper systematically addresses the measurement of near-verbatim extraction risk. It presents a family of algorithms, collectively termed decoding-constrained beam search (DCBS), that yield efficient and deterministic lower bounds on the probability with which a model, given a prefix, can generate a continuation within a bounded edit distance (e.g., Levenshtein or Hamming) from the original training suffix. The approach leverages beam search with per-decoding-step constraints derived from the target decoding policy (e.g., top-k) and integrates editing-distance–based pruning to improve both efficiency and the tightness of risk estimates.
Standard verbatim extraction computes the likelihood pz of generating the exact target suffix z under a deterministic or stochastic decoding policy ϕ, typically by:
pz:=Prθ,ϕ(z∣x)
where x is the context prefix, θ the LLM parameters, and ϕ is a next-token sampling strategy (e.g., greedy, top-k).
This formulation does not capture the risk associated with high-probability variants of z that are only a small number of substitutions, insertions, or deletions away from the target—the “near-verbatim” risk domain. To address this, the paper generalizes the risk metric to the total probability mass assigned to an pz0-ball about pz1 for some token-level distance function (e.g., Levenshtein):
pz2
where pz3 is the set of continuations within edit distance pz4 of pz5. This re-scopes extraction measurement to align with practical privacy and legal risk—since non-verbatim copies can carry similar liability.
Computational Challenges and Probabilistic Extraction
A major obstacle is the combinatorial growth of pz6. Enumerative approaches are intractable even for moderate pz7 and sequence lengths due to the exponential candidate space. Monte Carlo (MC) sampling is statistically unbiased but becomes computationally prohibitive, as the probability of observing even a single near-verbatim match can require pz8–pz9 samples, especially for low-threshold risk detection (e.g., z0).
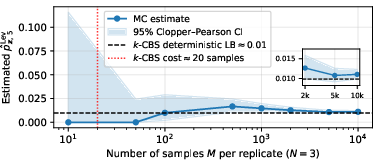
Figure 1: Monte Carlo estimation of near-verbatim extraction probability demonstrates that DCBS yields reliable lower bounds orders of magnitude faster.
To mitigate this, the paper introduces an algorithmic framework that enables efficient, deterministic lower bound estimation: decoding-constrained beam search.
Decoding-Constrained Beam Search (DCBS): Algorithmic Framework
The key observation is that high-probability continuations—especially those resulting from memorization—tend to be concentrated in a small region near the training target in the decoding tree. DCBS adapts beam search by restricting expansions to the top-z1 tokens at each step (matching the decoding scheme of interest, e.g., top-z2). The algorithm applies distance-based viability pruning, ensuring only candidate continuations that can potentially attain distance z3 are retained. Key properties include:
Experimental Results
The paper conducts extensive experiments with open LLMs: OLMo 2 (7B, 13B, 32B), Llama 2 (7B, 13B, 70B), and Pythia families, across Wikipedia, Books3 books, and Enron emails. Key findings are as follows:
DCBS reveals that the proportion of training sequences extractable with nontrivial near-verbatim risk is substantially higher than what is measured by verbatim methods. For OLMo 2 32B on held-in Wikipedia, verbatim probabilistic extraction finds 1.42% of sequences extractable; DCBS with ϕ1 finds 2.57%, a near doubling.
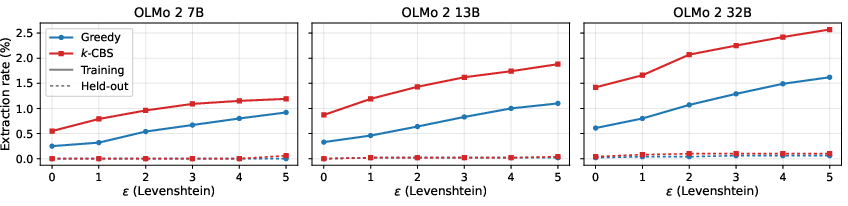
Figure 3: Extraction rates increase with both model scale and edit-tolerance; DCBS reveals significantly more risk compared to verbatim or greedy checks.
Per-Sequence Risk and Mass Gain
A large fraction of sequences have their extraction “unlocked” only in the near-verbatim regime—i.e., zero or sub-threshold verbatim risk but high near-verbatim probability. Per-sequence risk can increase from zero to ϕ2 or higher under near-verbatim matching in Llama~2-70B.
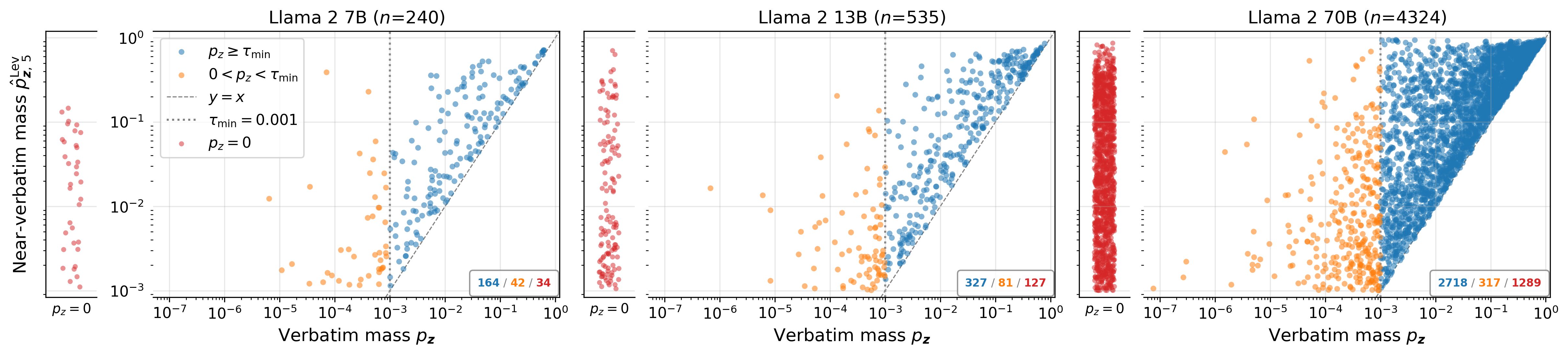
Figure 4: For Llama~2 on The Great Gatsby, many sequences have near-verbatim mass well above the verbatim; points above ϕ3 show substantial risk increase.
Empirical risk gain distributions (CCDF) show that for Llama~2-70B, 12.7% of all Gatsby sequences exhibit a mass gain ϕ4—a sharp increase unobservable to classic verbatim analysis.
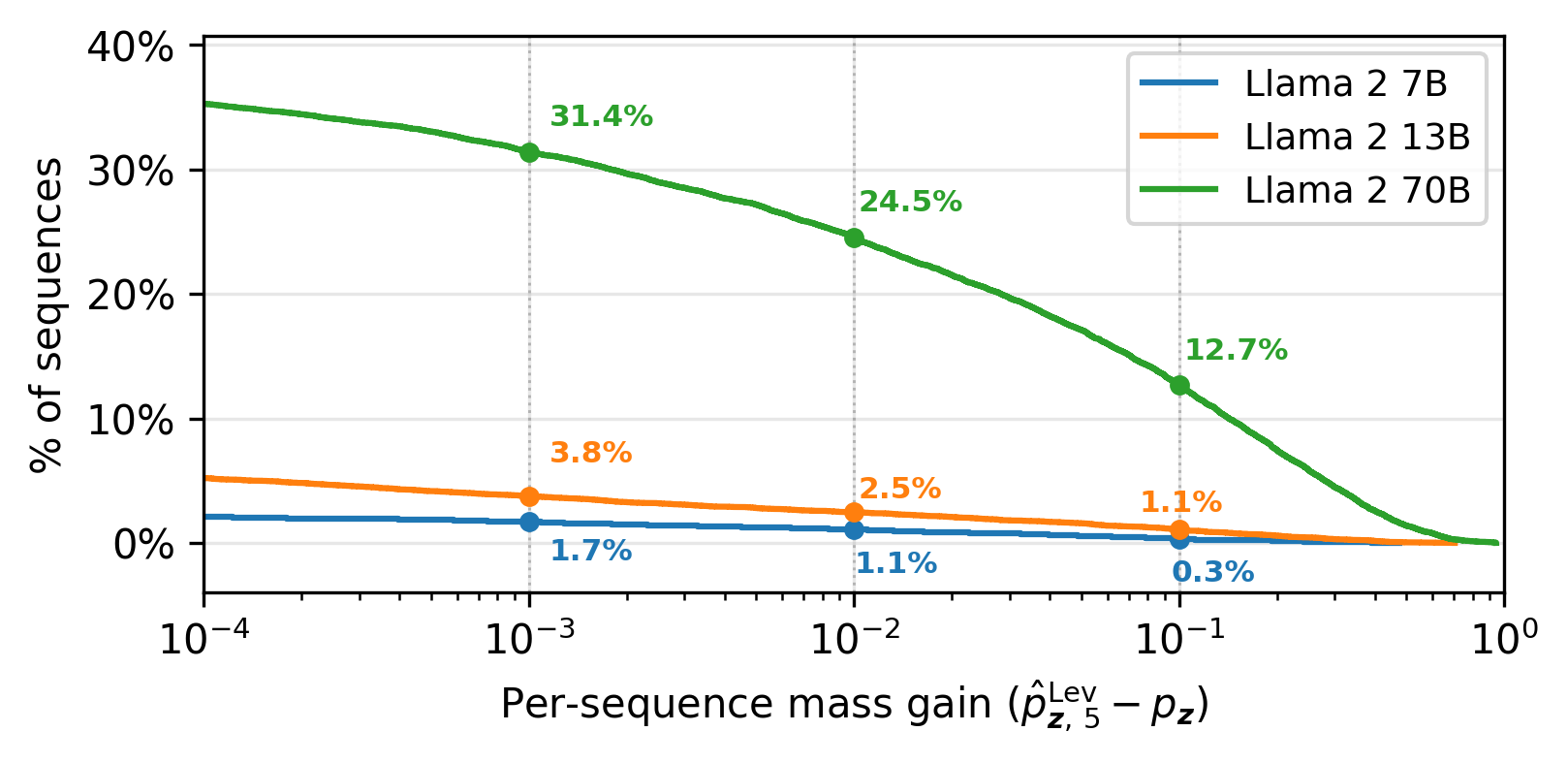
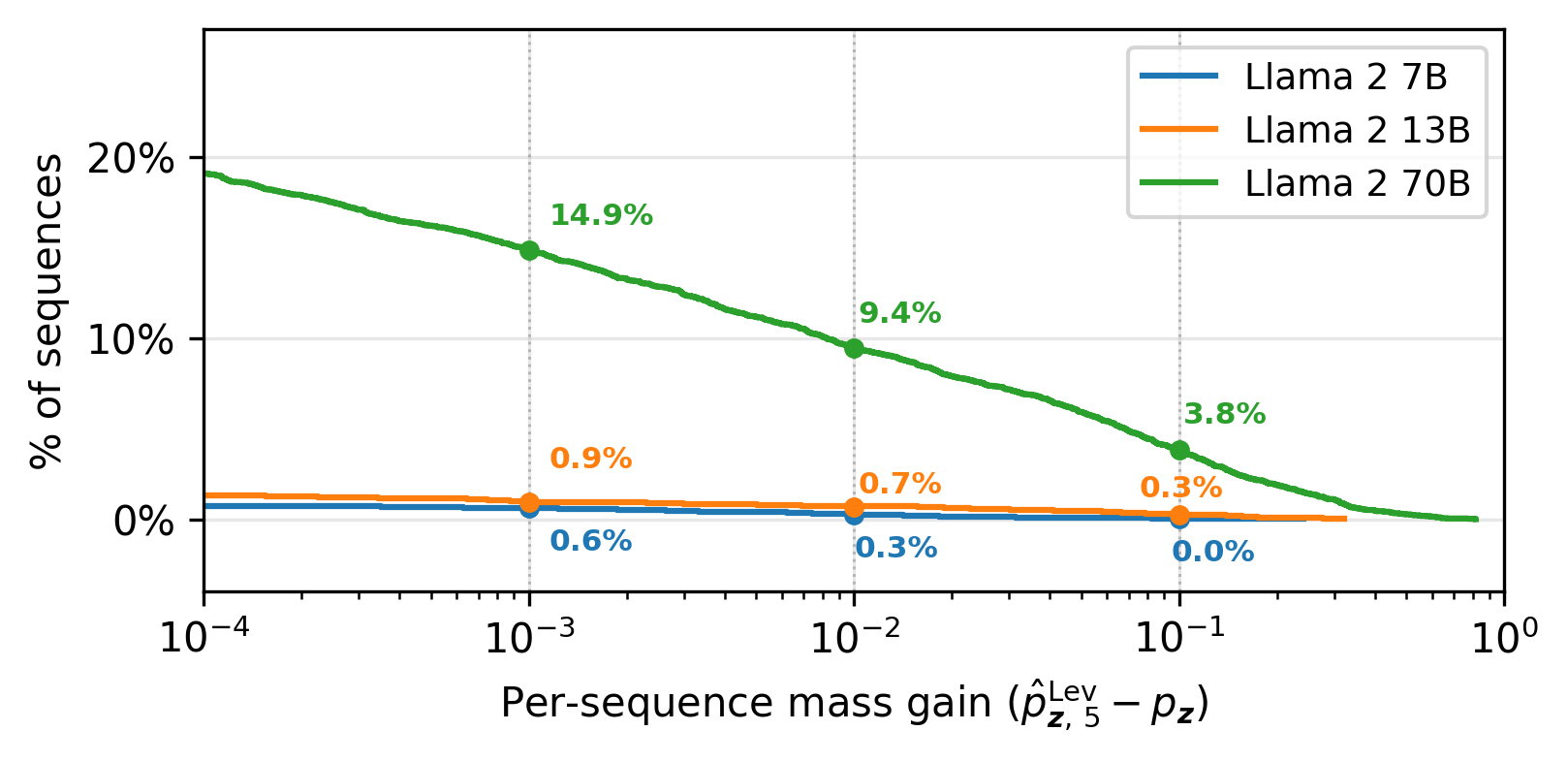
Figure 5: The CCDF of per-sequence near-verbatim mass gain for Llama~2 confirms systematically increased risk with scale.
Risk Structure and Scaling
The verbatim share of total extraction mass decreases with model scale, especially on structured book text; newly extractable cases tend to be unlocked by DCBS due to increased variation and coverage of near-matches as model parameters grow.
Moreover, inspecting extraction risk across distances reveals that mass can be distributed heterogeneously: for OLMo 2 on Wikipedia, median verbatim share among extractable sequences is often under 5%, with higher near-verbatim risk primarily responsible for extraction.
Negative Controls
Experiments on data not seen during training (Wikipedia pages posted after the OLMo 2 cutoff, or recent books for Llama 2/3) confirm that DCBS does not surface false positives, establishing its conservativeness and reliability as a risk estimator.
Practical and Theoretical Implications
DCBS not only closes a methodological gap by aligning extraction models with real risk (as defined legally and in data privacy), but also offers a practical tool for model assessment and model development workflows. The insights about risk scaling and the structure of memorized output distribution indicate that larger models generalize extraction risk more diffusely, increasing both concern around privacy (private details stored in non-verbatim form) and copyright (substantially similar reproduction). Moreover, the algorithm's efficiency allows its deployment at scale for ongoing model auditing and potentially in the loop during training.
Future Directions
The results open several avenues:
- Active Risk Auditing: Use DCBS as part of continuous privacy/copyright-risk assessment for in-training and deployed models.
- Understanding Memorization Mechanisms: Further investigation into why and how near-verbatim risk structures emerge with model scaling and cross-dataset heterogeneity.
- Extension to Other Decoding Policies: Adapting DCBS to non-top-ϕ5 decoding, such as nucleus sampling, and incorporating other metrics for “semantic” similarity.
Conclusion
This work precisely quantifies the substantial, previously underestimated near-verbatim extraction risk in LLMs, via an efficient, deterministic, and scalable algorithmic framework. DCBS reveals that classical verbatim approaches significantly underrepresent both the prevalence and the magnitude of memorization risk, particularly as models and datasets scale. The methods introduced provide both a robust practical risk diagnostic and a theoretical lens on the evolution of memorization behavior in generative models.
Refer to (2603.24917) for further implementation and experimental details.


