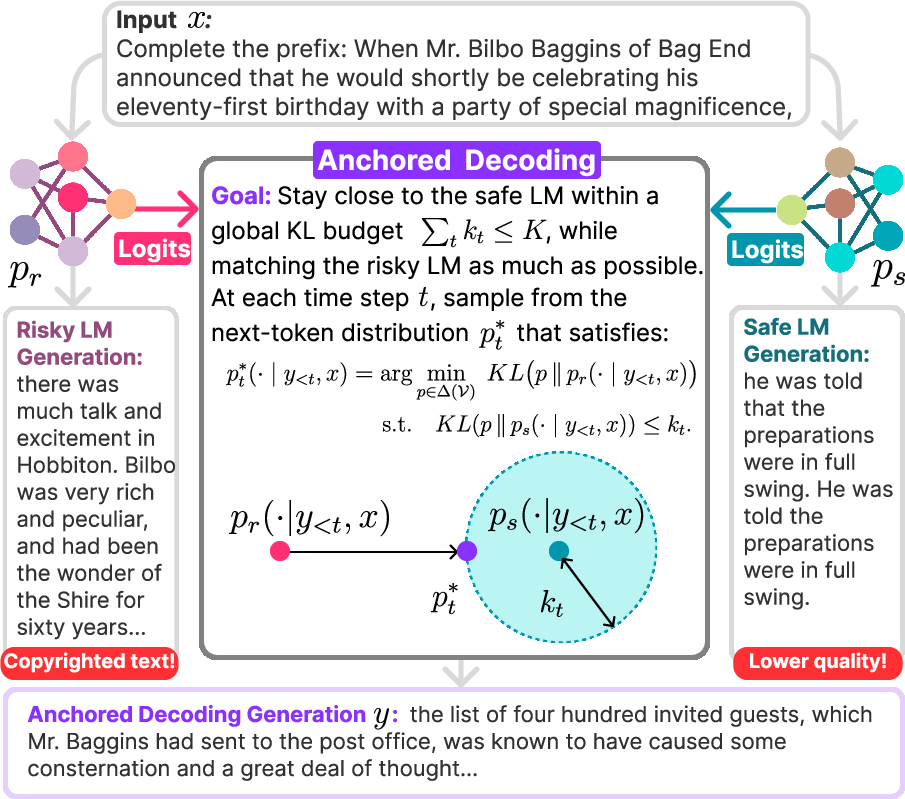
Anchored Decoding: Provably Reducing Copyright Risk for Any Language Model
Abstract: Modern LMs tend to memorize portions of their training data and emit verbatim spans. When the underlying sources are sensitive or copyright-protected, such reproduction raises issues of consent and compensation for creators and compliance risks for developers. We propose Anchored Decoding, a plug-and-play inference-time method for suppressing verbatim copying: it enables decoding from any risky LM trained on mixed-license data by keeping generation in bounded proximity to a permissively trained safe LM. Anchored Decoding adaptively allocates a user-chosen information budget over the generation trajectory and enforces per-step constraints that yield a sequence-level guarantee, enabling a tunable risk-utility trade-off. To make Anchored Decoding practically useful, we introduce a new permissively trained safe model (TinyComma 1.8B), as well as Anchored${\mathrm{Byte}}$ Decoding, a byte-level variant of our method that enables cross-vocabulary fusion via the ByteSampler framework (Hayase et al., 2025). We evaluate our methods across six model pairs on long-form evaluations of copyright risk and utility. Anchored and Anchored${\mathrm{Byte}}$ Decoding define a new Pareto frontier, preserving near-original fluency and factuality while eliminating up to 75% of the measurable copying gap (averaged over six copying metrics) between the risky baseline and a safe reference, at a modest inference overhead.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Anchored Decoding: Provably Reducing Copyright Risk for Any LLM”
Overview
This paper tackles a big problem with modern AI writing tools (LLMs): sometimes they copy chunks of their training text word-for-word. If that text is copyrighted—like parts of popular books—this can cause legal and ethical issues. The authors introduce a new way to generate text, called Anchored Decoding, that helps any LLM avoid copying while still producing high-quality output.
Goals and questions
The paper asks:
- Can we guide a powerful but “risky” model (one trained on a mix of licensed and copyrighted data) to be safer without retraining it?
- Can we do this while keeping its useful abilities (fluency, facts, and style)?
- Can we provide a clear safety guarantee—a rule you can set that limits how far the model is allowed to drift into risky behavior?
How the method works
Think of writing with two helpers:
- A “safe” helper, trained only on openly licensed and public-domain text. It rarely copies but isn’t as skillful.
- A “risky” helper, trained on everything. It’s great at writing but more likely to copy.
Anchored Decoding blends these two, step-by-step, while keeping the risky helper on a short leash.
Here’s the idea in everyday terms:
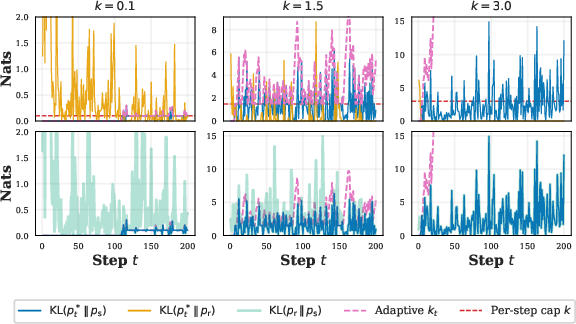
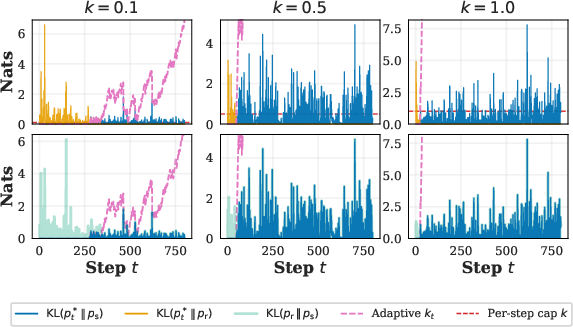
- A safety budget: Imagine you set a budget, like “stay within units of distance from the safe helper.” That budget controls how similar the final output must be to the safe model’s behavior. The bigger the budget, the more freedom (and potential risk). The smaller the budget, the safer (and possibly less polished) the result. The paper calls this rule K-NAF, which is a formal way of saying: “don’t stray too far from the safe reference.”
- Blending per step: The model writes one token (word-piece) or byte at a time. At each step, it mixes the risky and safe predictions. If the risky helper looks like it’s about to copy, the method automatically leans more on the safe helper. If things look fine, it allows more help from the risky one. Under the hood, this mixing uses a measure called KL divergence, which is just a number that says “how different are these two prediction patterns?”
- Adaptive “spending”: If a step seems safe, it “spends” little or none of the budget. That saves budget for later steps that might need more help from the risky model to stay fluent. If a step looks risky, it spends more. This is like saving your allowance when you don’t need it, then using it when you do.
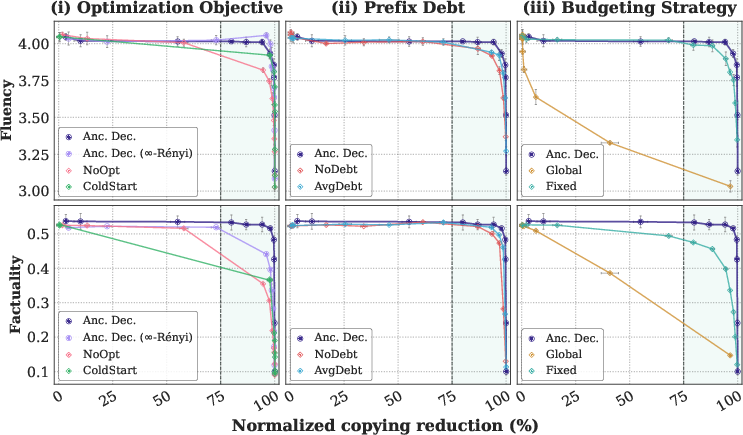
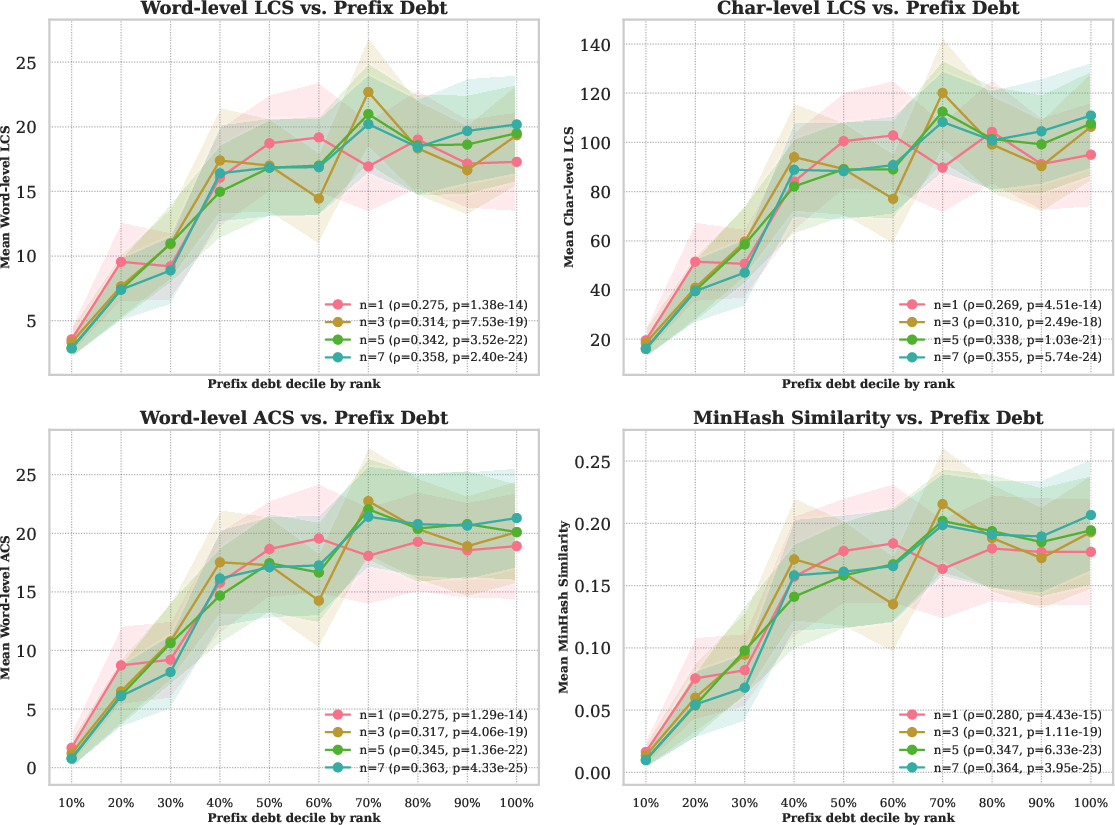
- Prefix debt: Some prompts are very likely to trigger copying—like starting with the famous opening line of a book. Anchored Decoding detects signs of this early and treats the prompt as if it already “spent” part of the safety budget. That means it starts out more cautious and relies more on the safe helper in the first few steps, which is where copying most often happens.
- Byte-level version for compatibility: Not all models use the same “vocabulary” (tokenizer). To blend models that don’t match, the authors also create Anchored (a byte-level version), which works at the level of raw bytes instead of tokens. It uses ByteSampler to build a clean probability over the next byte so you can still fuse models safely.
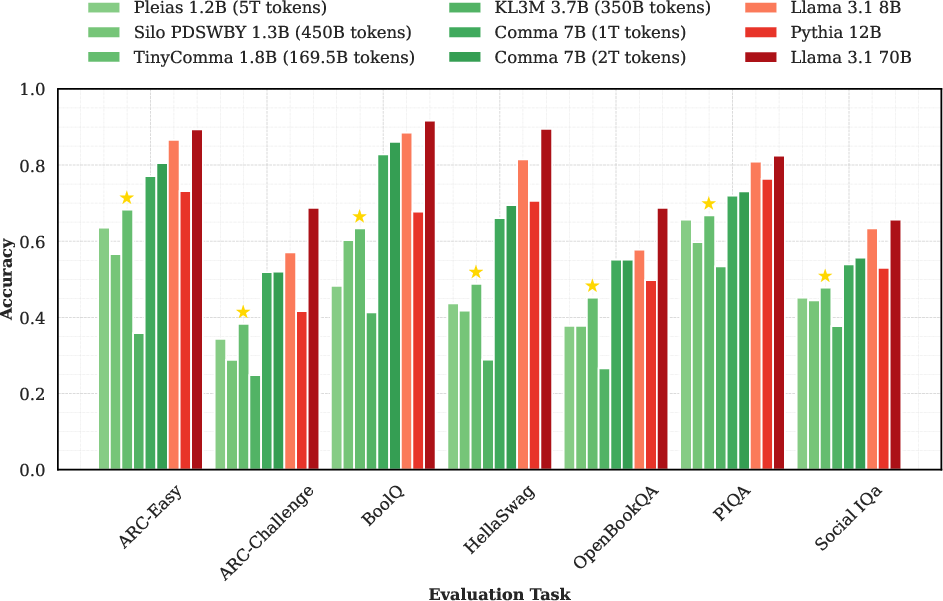
To make this work in practice, the authors also release a safe model called TinyComma 1.8B, trained only on permissively licensed data, and designed to be compatible with popular models for easy blending.
Main findings and why they matter
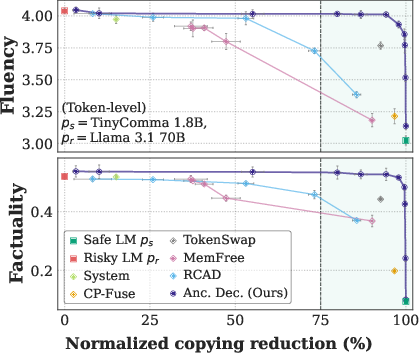
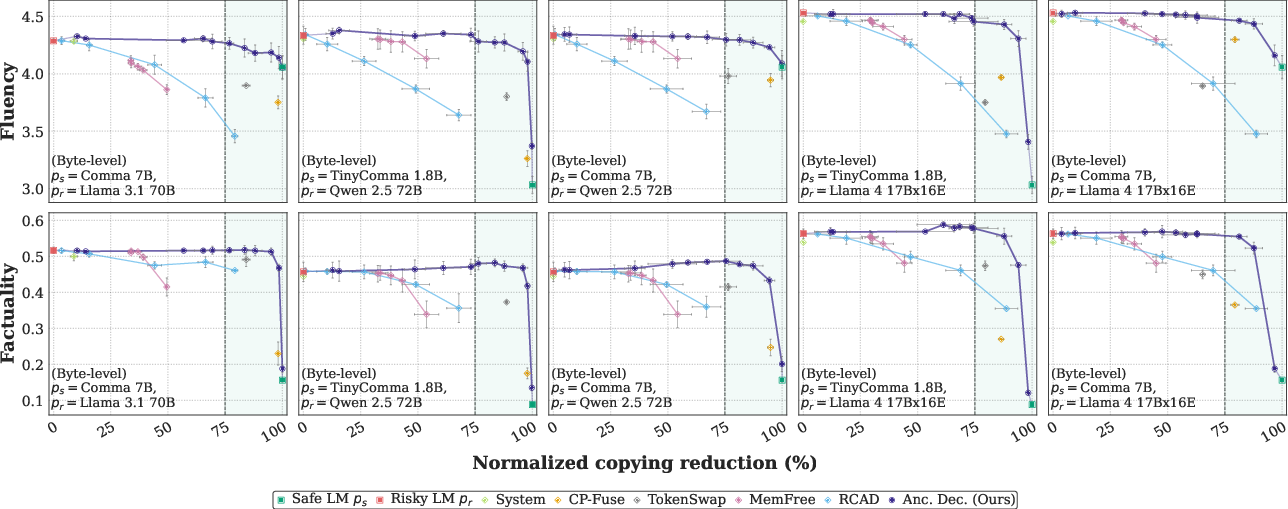
In tests across six pairs of safe/risky models, including big names like Llama and Qwen, Anchored Decoding and its byte-level counterpart consistently delivered the best balance of safety and usefulness.
Key results:
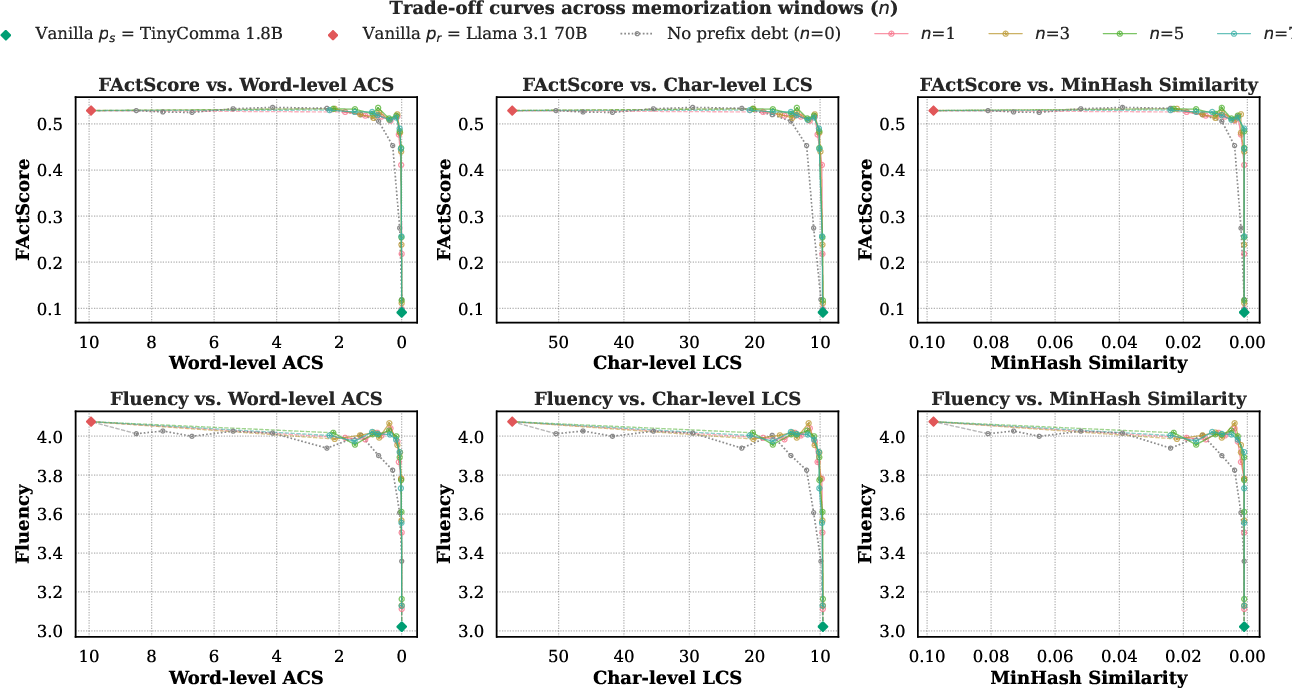
- Copying reduced by up to about 75% on average across six different “copying” metrics, compared to the risky model alone.
- Fluency and factuality stayed close to the original risky model—often much better than other safety methods.
- The method adds only modest speed overhead during generation (around 1.1× in one representative setup).
- It creates a new Pareto frontier, which means: among all methods tested, it offers the strongest trade-off between low copyright risk and high-quality output.
The authors also show why it works:
- A technical “difference score” (KL divergence) between the risky and safe models is a good early warning for copying.
- Copying tends to happen near the beginning of the output, which is why the “prefix debt” and cautious first steps help a lot.
Implications and impact
Anchored Decoding is practical:
- It’s plug-and-play at inference time (no retraining required).
- It works with many models, including those that don’t share the same tokenizer (thanks to the byte-level variant).
- It gives a user-controlled safety knob with a mathematical guarantee, which is helpful for developers and organizations that need compliance and trust.
Beyond copyright:
- The same idea—keeping a powerful generator close to a trusted “anchor”—could be used for safety in other areas too, like privacy, medical text, or any situation that needs strong guardrails.
- The framework is general: it doesn’t depend on a specific language, tokenizer, or even modality.
In short, Anchored Decoding shows a clear, tested path to safer AI text generation without throwing away the strengths that make modern LLMs useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what the paper leaves uncertain or unexplored, phrased to guide actionable future work:
- Applicability without logit access: Anchored Decoding requires logits from both models; how to adapt to black-box APIs (e.g., only next-token sampling, top-k, or logprob access)?
- Calibration of to real-world copyright risk: How do specific values of map to empirical probabilities of verbatim or near-verbatim copying, and to legally relevant thresholds (e.g., fair use, de minimis)?
- Legal interpretability of -NAF: To what extent does a KL- (or Rényi-) bounded divergence from a “safe” model translate into reduced infringement liability under different jurisdictions and legal doctrines?
- Robustness of the prefix-debt heuristic: Sensitivity to the choice of n (top-n LLRs), stability across domains, and susceptibility to adversarially crafted prompts or paraphrased copyrighted openers.
- Generalization beyond verbatim copying: Systematic evaluation of non-literal copying (e.g., close paraphrases, style mimicry, plot-level reproduction) beyond brief appendix mentions; development of stronger detectors.
- Cross-lingual and non-Latin scripts: Does byte-level anchoring retain efficacy and acceptable utility for languages with different byte/token ratios, complex scripts, or segmentation (e.g., CJK, Arabic)?
- Decoding hyperparameters: Interaction with temperature, top-p, top-k, and repetition penalties when sampling from fused distributions; effects on risk and utility are unreported.
- Variable-length and multi-turn settings: How to set and renew , , and for unknown/streaming lengths and conversational contexts; budgeting across turns and sessions.
- Retrieval-augmented generation (RAG): Behavior when retrieved passages contain copyrighted material; does anchoring to a safe LM sufficiently mitigate regurgitation in RAG pipelines?
- Privacy leakage vs. copyright: Do the guarantees and empirical reductions transfer to PII leakage or membership inference risk, or are separate controls needed?
- Safe-model contamination risk: Auditable evidence that the safe corpus is truly free of copyrighted content; what happens if leakage exists in the “safe” anchor?
- Utility and domain coverage of safe anchors: How anchor size/quality/domain match (e.g., TinyComma 1.8B vs. Comma 7B) affects Pareto trade-offs; minimal anchor capability needed to retain utility.
- Automated per-prompt tuning: Methods to automatically set , , and prefix debt for each prompt based on risk signals, with guarantees that hold under online decisions.
- Budget allocation optimality: Is there a provably optimal per-step spending policy (beyond adaptive banking) that yields better risk–utility; can offline planning given the prompt outperform local myopic rules?
- Numerical stability and failure modes: Convergence issues in root-finding for λ, behavior under extreme distributions (e.g., near-degenerate logits), and safeguards for stability.
- Tokenizer assumptions in Anchored (byte-level): ByteSampler assumes BPE-style tokenizers; how to handle unigram or other tokenization schemes and ensure exactness/efficiency?
- Efficiency at the byte level: Precise wall-clock, memory, and throughput costs of Anchored across hardware and languages; opportunities for kernel fusion, caching, or distillation to reduce overhead.
- Sensitivity to domain shift: Anchoring to permissively trained models may skew style or content distributions (e.g., fewer contemporary topics); quantify shifts and utility loss across diverse tasks.
- Bias and fairness: Anchoring to datasets of permissive texts may change demographic representation and stylistic norms; measure impacts on bias, toxicity, and cultural coverage.
- Applicability to instruction-tuned/chat models: Results are on base LMs; assess anchoring impacts in RLHF/instruction settings, multi-turn dialogues, and tool-use workflows.
- Composability with training-time mitigations: How anchoring interacts with deduplication, unlearning, data filtering, or watermarking; whether effects are additive, redundant, or conflicting.
- Broader task coverage: Utility assessed on Books (fluency) and Bios (factuality); evaluate on reasoning, coding, math, long-context summarization, and safety-critical tasks.
- Adversarial evaluation: Resistance to prompts designed to evade prefix-debt detection or to maintain low per-step KL while still steering toward memorized sequences.
- Closed-form choice of divergence: Exploration of other f-divergences (e.g., Jensen–Shannon, χ²) for guarantees and trade-offs; conditions for closed-form solutions and better empirical behavior.
- Theoretical suboptimality of local approximation: Quantify the gap between the local per-step constrained solution and the intractable global optimum; conditions where local composition is tight/loose.
- EOS and special-token handling: The impact of budget allocation and projections around EOS, newline, and whitespace tokens (not specified in detail) on both risk and fluency.
- Languages and token-to-byte ratio variability: The assumption is English-centric; derive language-aware budgets and validate guarantees across scripts.
- Scaling to very large risky models: When in capability, identify limits where anchoring degrades utility; principled guidelines for choosing anchor size and pairing strategies.
- Black-box surrogates: Can approximate anchoring be achieved with only top-k tokens or sampled continuations (e.g., using rejection sampling, distillation, or proxy classifiers) when logits are unavailable?
- Multimodal generalization: The method is claimed modality-agnostic but untested for images, audio, or code; define safe anchors and risk metrics, and validate -NAF in those domains.
- Human and legal expert evaluation: Reliance on LLM-as-a-judge for fluency and automated overlap metrics for risk; need human studies and legal expert annotation to assess true infringement risk and usability.
- Threshold choice for “high protection”: The 75% NCR operating point is arbitrary; determine principled risk thresholds tied to policy or product requirements and analyze sensitivity.
Practical Applications
Immediate Applications
The following applications can be deployed now with moderate engineering effort, using the paper’s plug-and-play inference-time methods (Anchored Decoding and its byte-level variant Anchored), the K-NAF safety guarantee, the adaptive budgeting and prefix-debt mechanisms, and the provided safe anchor model (TinyComma 1.8B).
Industry
- LLM provider “Anchored Mode” for commercial APIs (SaaS)
- Sectors: software, media, marketing, customer support
- What: Offer a server-side decoding mode that fuses a high-utility risky LM with a permissively trained safe anchor (e.g., TinyComma 1.8B or Comma 7B via byte-level Anchored) to suppress regurgitation while maintaining fluency and factuality; expose a user-tunable K “originality slider.”
- Tools/workflows: ProjectKL fusion step at each token/byte; adaptive budget and prefix-debt computation; per-response logging of realized KL spend; K policy presets.
- Dependencies/assumptions: Access to logits for both models; modest extra compute (≈1.1× at token level, higher at byte level); availability and verification of permissively trained safe anchors; governance around K defaults.
- CMS, marketing, and content production pipelines with built-in copyright risk control
- Sectors: media, advertising, e-commerce
- What: Integrate Anchored Decoding into content workflows (blog posts, ads, product descriptions) with automatic risk scorecards and auditable traces of information budget use.
- Tools/workflows: Batch generation with per-step KL telemetry; dashboards for NCR-like risk metrics and K-spend traces; safe-start behavior enforced by prefix-debt.
- Dependencies/assumptions: Integration with existing CMS; acceptance of divergence-based guarantees as a compliance control; throughput targets.
- Search and answer engines that avoid verbatim copying in snippets
- Sectors: search, news, knowledge bases
- What: Use Anchored Decoding during snippet/fact answer generation to reduce verbatim overlap with source pages while preserving factual accuracy.
- Tools/workflows: Combine with retrieval-Augmented Generation (RAG); tune K by domain (e.g., lower K for news); audit using NCR-like metrics and claim-precision (FActScore).
- Dependencies/assumptions: Access to model logits; careful K tuning to avoid utility loss; monitoring for domain shift.
- Enterprise assistants with auditable compliance for summarization and drafting
- Sectors: finance, legal, healthcare, HR, internal knowledge management
- What: Enable enterprise chat and summarization tools to generate “near-safe” outputs bounded by a permissive anchor, with per-response audit logs for legal review.
- Tools/workflows: Policy-configured K budgets per business unit; prefix-debt-based safe-start for high-risk prompts (e.g., pasted proprietary text).
- Dependencies/assumptions: On-prem or VPC deployment with safe anchor available; role-based K policies; legal sign-off on divergence-based control.
- Code assistant with license-aware generation
- Sectors: software engineering
- What: Reduce risk of copying non-permissive code by anchoring to a code LM trained on permissive licenses (e.g., a safe-code anchor), while deriving utility from a high-capability code LM.
- Tools/workflows: Anchored Decoding or byte-level Anchored if tokenizers diverge; integrate with IDEs; surface “license-safety” indicators per suggestion.
- Dependencies/assumptions: Availability of a permissive-only code anchor; tokenizer compatibility or ByteSampler integration; complementary license scanners still recommended.
- Synthetic data generation with low copyright leakage
- Sectors: ML data vendors, model training teams
- What: Use Anchored Decoding to produce synthetic corpora with constrained divergence from a permissive anchor to reduce downstream copyright risk in fine-tuning.
- Tools/workflows: K-tuned bulk generation pipelines; risk-utility validation using NCR-like metrics.
- Dependencies/assumptions: Throughput and cost budgets; validation that synthetic distributions meet task needs.
Academia
- Memorization auditing and dataset forensics
- What: Use per-step KL(p_r || p_s) as a diagnostic to flag prompts and continuations likely influenced by memorized training data; run controlled audits across domains.
- Tools/workflows: Prefix-debt scoring as a tail-statistic; analysis notebooks for KL histograms and CCDFs; CopyBench/Books-like long-form evaluations.
- Dependencies/assumptions: Access to a suitable permissive anchor; compute for paired forward passes.
- Baseline safe anchor for research on permissive-only training
- What: Employ TinyComma 1.8B as a reproducible safe baseline to compare safe-only pretraining strategies and data-cleaning techniques.
- Tools/workflows: Standard benchmarks and memorization probes; cross-tokenizer experiments via Anchored.
- Dependencies/assumptions: Availability and licensing of TinyComma; consistent preprocessing pipelines.
Policy and Governance
- Internal AI governance controls with a tunable information budget
- What: Define policy profiles (e.g., “marketing K=low,” “internal drafting K=medium,” “R&D K=custom”) with auditable K-spend and prefix-debt thresholds; route high-risk generations for human review.
- Tools/workflows: Compliance dashboards; alerting when realized spend spikes; evidence packs for audits.
- Dependencies/assumptions: Alignment of legal/compliance teams on K-NAF as a control; threshold calibration by use case.
- Takedown-mitigation workflows
- What: Deploy Anchored Decoding to proactively reduce verbatim overlap with copyrighted materials that trigger DMCA-like actions.
- Tools/workflows: Post-deployment monitoring of overlap metrics; automated rollback to lower K when risk rises.
- Dependencies/assumptions: Reliable measurement proxies; incident response processes.
Daily Life
- Writing assistants with an “originality” slider
- What: End-user tools (extensions, desktop apps) that expose a simple control for how closely outputs may follow risky LMs; stronger safe-start in the first sentences.
- Tools/workflows: UI for K; per-output risk badges; local logging for transparency.
- Dependencies/assumptions: Latency tolerance for two-model decoding; availability of a lightweight safe anchor.
- Education tools that avoid plagiarism
- What: Homework helpers and study aids that generate novel explanations without copying from textbooks or novels.
- Tools/workflows: Strict K defaults; teacher-visible originality reports; early-step clamping via prefix-debt.
- Dependencies/assumptions: Policy and UX alignment with academic integrity norms.
Long-Term Applications
These applications likely require further research, scaling, standardization, or ecosystem development (e.g., domain-specific anchors, regulatory acceptance, or training-time integration).
Industry
- Multimodal anchoring for images, audio, and video
- Sectors: media, advertising, entertainment
- What: Extend the K-NAF-bounded fusion to generative image/audio/video models by anchoring high-capability models to safe, permissive-only reference distributions to reduce style/content regurgitation.
- Tools/workflows: Continuous-distribution analogs of ProjectKL; byte/patch-level or latent-space anchoring; domain-specific safe anchors.
- Dependencies/assumptions: Theory and engineering for non-discrete spaces; robust permissive multimodal datasets; compute overhead management.
- Training-time anchoring and distillation (“compliance-by-design” models)
- Sectors: software, cloud AI
- What: Distill the anchored behavior into a single model via KD/RL objectives that penalize divergence from the safe anchor, reducing runtime overhead and removing dual-pass inference.
- Tools/workflows: Loss terms approximating cumulative K budget; teacher–student pipelines; post-hoc auditing.
- Dependencies/assumptions: Stable training objectives; verification that distillation preserves guarantees.
- Domain-specific safe-anchor marketplaces
- Sectors: healthcare, legal, finance, education
- What: Curate and certify safe anchors trained exclusively on permissive, domain-specific corpora (e.g., public medical guidelines, open legal opinions) for vertical products.
- Tools/workflows: Corpus provenance audits; sector-tuned K policies; integration kits for heterogeneous tokenizers.
- Dependencies/assumptions: Availability of high-quality permissive corpora; sector-specific evaluation standards.
- Privacy-leak mitigation using PII-free anchors
- Sectors: healthcare, HR, customer support
- What: Bound outputs against anchors trained without PII to reduce privacy leakage risk when prompts contain sensitive text.
- Tools/workflows: Joint privacy-and-copyright budgets; PHI-aware prefix-debt variants; red-team pipelines.
- Dependencies/assumptions: Reliable PII-free anchors; legal and ethical review.
- Insurance and risk-quantification products
- Sectors: finance, enterprise risk
- What: Use logged K budgets and realized per-step spend as quantitative features for underwriting AI copyright-liability insurance or for vendor risk scoring.
- Tools/workflows: Standardized telemetry; actuarial models; compliance attestations (e.g., “K-NAF Level X”).
- Dependencies/assumptions: Industry-wide benchmarks; regulatory acceptance.
- API standards for risk telemetry and auditing
- Sectors: software platforms, cloud
- What: Standardize streaming of per-step KL and K-spend metadata to enable interoperable auditing across vendors and integrators.
- Tools/workflows: SSE/GRPC extensions; audit log schemas; reference verifiers.
- Dependencies/assumptions: Community consensus and standard bodies’ involvement.
- On-device/edge “anchored” assistants
- Sectors: mobile, IoT
- What: Deploy compact safe anchors locally and fuse with remote risky models, or deploy a distilled single anchored model on-device for low-latency compliant generation.
- Tools/workflows: Model compression and distillation; split-compute protocols; privacy-preserving telemetry.
- Dependencies/assumptions: Efficient anchors; connectivity constraints; security posture.
- Robotics and operations planning bounded by safe policies
- Sectors: robotics, operations, energy grid ops
- What: Use anchoring concepts to bound action-sequence generation against a verified safe reference policy (e.g., conservative planner), reducing unsafe action sequences.
- Tools/workflows: Extension of K-NAF to control/action spaces; per-step divergence budgets in policy rollouts.
- Dependencies/assumptions: Theoretical and empirical validation for continuous/action spaces; real-time constraints.
Academia
- Memorization theory and benchmarks based on divergence tails
- What: Formalize and study the relationship between per-step KL tails and regurgitation across tasks, languages, and modalities; build standardized datasets for evaluation.
- Tools/workflows: Public benchmark suites; analysis of early-position copying and prefix-debt detectors; open-source tooling.
- Cross-lingual and low-resource safe anchoring
- What: Develop anchors for non-English and low-resource languages using permissive corpora; quantify trade-offs in high-morphology settings.
- Tools/workflows: Byte-level anchoring adaptations; tokenization-agnostic methods; culturally specific evaluations.
- Dependencies/assumptions: Curated permissive datasets; community partnerships.
Policy and Regulation
- Certification and labeling frameworks (e.g., “K-NAF Level X”)
- What: Define certifications for generation systems that provably bound divergence from safe anchors under audited K budgets; require for certain verticals (e.g., education, government).
- Tools/workflows: Third-party auditors; test suites; reporting templates; incident disclosure norms.
- Dependencies/assumptions: Regulator engagement; legal codification; harmonization across jurisdictions.
- Procurement and compliance mandates
- What: Public-sector and enterprise procurement to require anchored decoding (or equivalent guarantees) for generative systems handling sensitive or copyright-exposed use cases.
- Tools/workflows: RFP language; compliance evidence packs; periodic re-certification.
- Dependencies/assumptions: Market readiness; vendor ecosystem support.
Daily Life
- OS-level originality controls and transparency
- What: System-wide settings enforcing anchored generation across apps, with visible risk meters and controls for K budgets.
- Tools/workflows: Platform APIs; unified telemetry; parental/educator controls.
- Dependencies/assumptions: Platform adoption; user education.
- Education platforms with exam-safe assistants
- What: Integrate anchored decoding into LMS and proctoring systems to allow constrained assistance that avoids plagiarism in take-home contexts.
- Tools/workflows: Institution-set K policies; proctoring integrations; originality logs accessible to instructors.
- Dependencies/assumptions: Institutional policies; student privacy and fairness considerations.
- Creator-compensation ecosystems
- What: Combine anchored outputs with licensing rails that favor permissive sources and compensate contributors, using the safe-anchor provenance as a signal.
- Tools/workflows: Attribution and payout infrastructure; anchor provenance proofs.
- Dependencies/assumptions: Industry partnerships; standards for provenance and attribution.
Notes on key assumptions across applications:
- Logit access is required for fusion; closed models may need vendor-side implementation.
- Byte-level Anchored removes tokenizer alignment constraints but increases decoding steps (≈4× tokens in English), affecting latency.
- K-NAF bounds divergence from a safe anchor, not legal liability per se; legal acceptance and threshold setting require policy work.
- Safe anchor quality matters: anchors must be trained on verified permissive corpora and be sufficiently capable to preserve utility.
- Risk metrics (e.g., NCR, ROUGE/LCS/MinHash proxies) are indicators; human/contextual review remains important in high-stakes settings.
Glossary
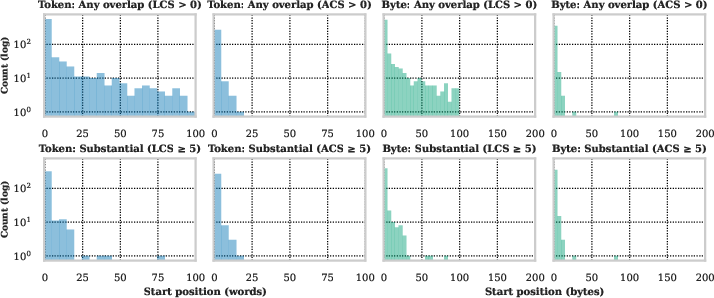
- Accumulated Common Substring (ACS): A copying metric that measures near-duplicate overlap by accumulating common substrings between texts. "word-level Accumulated Common Substring (ACS) measure near duplicate copying"
- Anchored: A byte-level, tokenizer-agnostic fusion method introduced in the paper that enforces a global copyright-safety budget while operating over next-byte distributions. "We introduce Anchored, a byte-level, -NAF compliant analogue of Anchored Decoding."
- Anchored Decoding: A plug-and-play inference-time method that fuses safe and risky LLMs to suppress verbatim copying under a provable divergence budget. "We propose Anchored Decoding, a plug-and-play inference-time method for suppressing verbatim copying"
- Autoregressive LLM: A model that generates sequences by predicting each next token conditioned on the previously generated tokens. "We consider token-level autoregressive LLMs that operate over a fixed vocabulary ."
- Byte Pair Encoding (BPE): A subword tokenization technique that builds a vocabulary by iteratively merging frequent byte or character pairs. "have Byte Pair Encoding (BPE) tokenizers that induce a mapping from tokens to UTF-8 byte strings."
- ByteSampler: A framework that converts token-level distributions into exact next-byte distributions by marginalizing over valid tokenizations. "Anchored builds upon the ByteSampler framework~\citep{hayase2025samplinglanguagemodelbyte} and bypasses tokenizer mismatch by operating on the next-byte distribution."
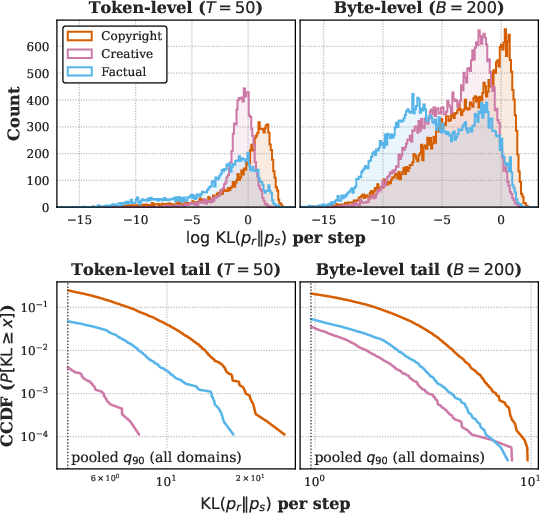
- CCDF (Complementary cumulative distribution function): The function that gives, for each threshold, the probability that a random variable is at least that large; used to analyze heavy-tail behaviors. "Bottom: Unconditional CCDF of per-step , shown for ."
- Chain rule of KL divergence: A decomposition property that expresses sequence-level KL divergence as a sum of per-step conditional divergences. "The sequence-level constraint in \cref{eq:global_opt} can be decomposed via the chain rule of KL divergence into a sum of per-step conditional divergences."
- CP-Fuse: A two-model fusion baseline that minimizes the maximum divergence to two equally capable models, assuming disjoint training data shards. "We consider CP-Fuse~\citep{abad2025copyrightprotected}, a -NAF-inspired fusion method that selects a next-token distribution by balancing proximity to two LMs of equal utility."
- EOS (End Of Sequence): A special termination token indicating the end of generation. "where denotes termination."
- FActScore: A fine-grained factuality metric that decomposes outputs into atomic claims and verifies each against evidence. "FActScore is a fine-grained metric that decomposes each output into a set of atomic, verifiable claims"
- FLOPs/token: A compute-efficiency measure estimating the number of floating-point operations per generated token. "We report the time to first token (TTFT), throughput slowdown ratio relative to (TPS Ratio), and FLOPs/token estimate"
- Geometric mean (weighted): A multiplicative mixture of distributions used as the closed-form fusion solution under a KL constraint. "the optimal distribution that solves \cref{eq:token_level_opt} is a weighted geometric mean:"
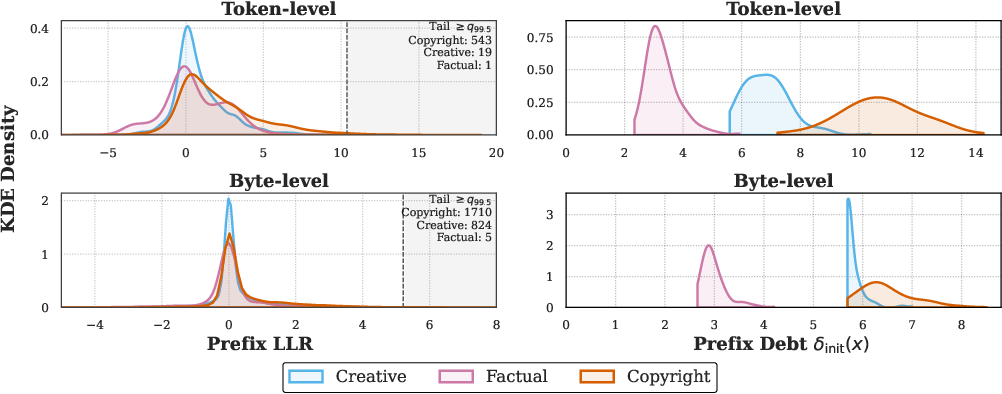
- KDE (Kernel density estimate): A nonparametric method to estimate a distribution’s density, used to visualize LLR and debt distributions. "Left: KDEs of per-step prefix log-likelihood ratios (LLR) at the token and byte levels."
- K-Near Access-Freeness (K-NAF): A framework that bounds the divergence of a model’s generated sequence distribution from a safe reference by a global budget K. "We adopt the -NAF framework introduced by \citet{vyas2023provablecopyrightprotectiongenerative}, which bounds the total divergence"
- Kullback–Leibler divergence (KL divergence): An information-theoretic measure of how one probability distribution diverges from another. "We primarily consider , the Kullback-Leibler (KL) divergence~\citep{Kullback51klDivergence}."
- Lagrange multiplier: The dual variable in constrained optimization that controls the trade-off between objectives; here, associated with the KL budget. "where is a normalization constant and is the dual variable (Lagrange multiplier) associated with the KL constraint."
- LLM-as-a-judge: An evaluation paradigm where a LLM assesses outputs according to a rubric. "Prometheus-v2~\citep{kim2024prometheus}, an LLM-as-a-judge~\citep{zheng2023judging} that scores output along a five-point rubric"
- Log-likelihood ratio (LLR): The log of the ratio of two models’ conditional probabilities, used to detect memorization in prompts. "we focus on the largest log-likelihood ratios (LLRs) in the prefix."
- Logits: The pre-softmax scores output by a neural network, representing unnormalized log-probabilities over tokens. "retrofits to any off-the-shelf LM with exposed logits."
- Longest Common Substring (LCS): A copying metric measuring exact-match overlap by the length of the longest shared substring. "word-level and character-level Longest Common Substring (LCS) measure the extent of exact match."
- MemFree: A decoding baseline that prevents exact n-gram regurgitation by blocking tokens that would complete listed n-grams. "MemFree~\citep{ippolito-etal-2023-preventing} is a decoding method that blocks exact -gram regurgitation"
- MinHash similarity: A locality-sensitive hashing based similarity metric used to detect near-duplicate text. "MinHash similarity~\citep{broder1997resemblance}"
- Newton–Raphson algorithm: An iterative root-finding method used (with safeguards) to solve for the fusion weight under the KL constraint. "using a safeguarded Newton-Raphson algorithm to ensure fast convergence to a feasible solution"
- Normalized Copyright Reduction (NCR): An aggregate score quantifying the fraction of copying risk eliminated relative to a risky and safe reference. "we assign equal weight to each metric and aggregate them into a single normalized copying reduction (NCR) score"
- Pareto frontier: The set of operating points where no method can improve risk reduction without sacrificing utility, and vice versa. "Anchored and Anchored define a new Pareto frontier, preserving near-original fluency and factuality"
- Prefix debt: A conservative initial offset to the global safety budget based on prompt-specific memorization signals. "a one-time, prompt-dependent prefix debt that reduces the initial budget"
- RCAD (Reversed Context Aware Decoding): A single-model baseline that downweights tokens favored by a retrieved context by contrasting logits with and without that context. "Reversed Context Aware Decoding~\citep{wei2024evaluating}, or RCAD, contrasts logits with and without a blocklisted context"
- ROUGE-L: A recall-oriented overlap metric that measures the longest common subsequence; used to assess copying risk at thresholds. "ROUGE-1 and ROUGE-L~\citep{lin-2004-rouge} above a set threshold "
- Support (of a distribution): The set of outcomes with non-zero probability; here, assumed shared across safe and risky models. " and are assumed to induce the same support over "
- TokenSwap: A two-model baseline that replaces probabilities of selected common tokens from a small model while retaining others from a large model. "TokenSwap~\citep{prashant2025tokenswap} constructs a hybrid next-token distribution by swapping a manually defined set of common tokens"
- UTF-8: A character encoding standard; here, used to map tokens to byte strings for byte-level fusion. "a mapping from tokens to UTF-8 byte strings."
- Valid Covering Tree: A traversal structure used to exactly marginalize token-level distributions into next-byte probabilities given tokenizer constraints. "implement this marginalization using a Valid Covering Tree traversal, which efficiently produces an exact next-byte distribution"
Collections
Sign up for free to add this paper to one or more collections.

