AVO: Agentic Variation Operators for Autonomous Evolutionary Search
Abstract: Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents. Rather than confining a LLM to candidate generation within a prescribed pipeline, AVO instantiates variation as a self-directed agent loop that can consult the current lineage, a domain-specific knowledge base, and execution feedback to propose, repair, critique, and verify implementation edits. We evaluate AVO on attention, among the most aggressively optimized kernel targets in AI, on NVIDIA Blackwell (B200) GPUs. Over 7 days of continuous autonomous evolution on multi-head attention, AVO discovers kernels that outperform cuDNN by up to 3.5% and FlashAttention-4 by up to 10.5% across the evaluated configurations. The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation and yielding gains of up to 7.0% over cuDNN and 9.3% over FlashAttention-4. Together, these results show that agentic variation operators move beyond prior LLM-in-the-loop evolutionary pipelines by elevating the agent from candidate generator to variation operator, and can discover performance-critical micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations on today's most advanced GPU hardware.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “AVO: Agentic Variation Operators for Autonomous Evolutionary Search”
Overview
This paper is about teaching an AI “coding agent” to improve very fast computer programs all by itself. The programs it focuses on power “attention,” a core step in Transformer models (the kind used by many modern AI systems). These programs run on NVIDIA’s latest GPUs (very powerful graphics chips) and are already tuned by experts. The authors show that their AI agent can keep editing, testing, and fixing the code on its own for days and still find ways to make it run faster than the best human-made versions.
Key goals and questions
Here are the main things the authors wanted to find out:
- Can a self-directed AI agent do more than just suggest code once, and instead act like a smart “variation operator” that plans, edits, tests, and improves code over many steps?
- Can this agent find real, low-level speedups in highly optimized “attention” kernels on new NVIDIA Blackwell (B200) GPUs?
- Do the improvements it discovers for one attention style (multi-head attention) carry over to a related style (grouped-query attention) with little extra work?
How they did it (methods, in simple terms)
Think of the agent like a very diligent robot coder in a workshop:
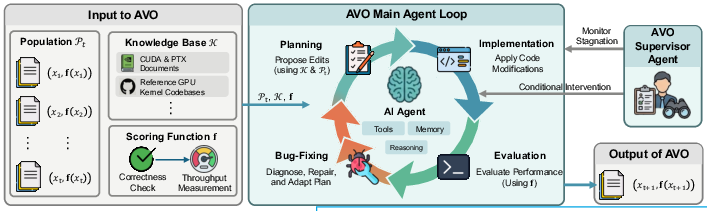
- It has a toolbox: it can read manuals (GPU documentation), look at old versions of the code, compile and run programs, check correctness, and measure speed.
- It works in loops: plan a change, make the change, test it, read feedback, and try again. It keeps going for days, building on what worked and dropping what didn’t.
- It keeps a timeline of “best so far” versions. Only versions that are correct and at least as fast as the current best get saved.
- If the agent gets stuck or keeps chasing bad ideas, a simple “supervisor” nudges it to try different strategies.
Some terms explained:
- Attention: a way for AI models to decide which parts of the input are most important to focus on.
- GPU: a specialized chip that can do tons of math in parallel very quickly.
- Kernel: a tiny, performance-critical program that runs on the GPU.
- Throughput/TFLOPS: how much math the program can do per second (higher is faster).
The team ran the agent for 7 days straight on Blackwell B200 GPUs. It repeatedly edited and tested a GPU “attention kernel,” comparing it to top expert-made baselines from cuDNN (NVIDIA’s library) and FlashAttention-4 (a cutting-edge open-source implementation).
What they found
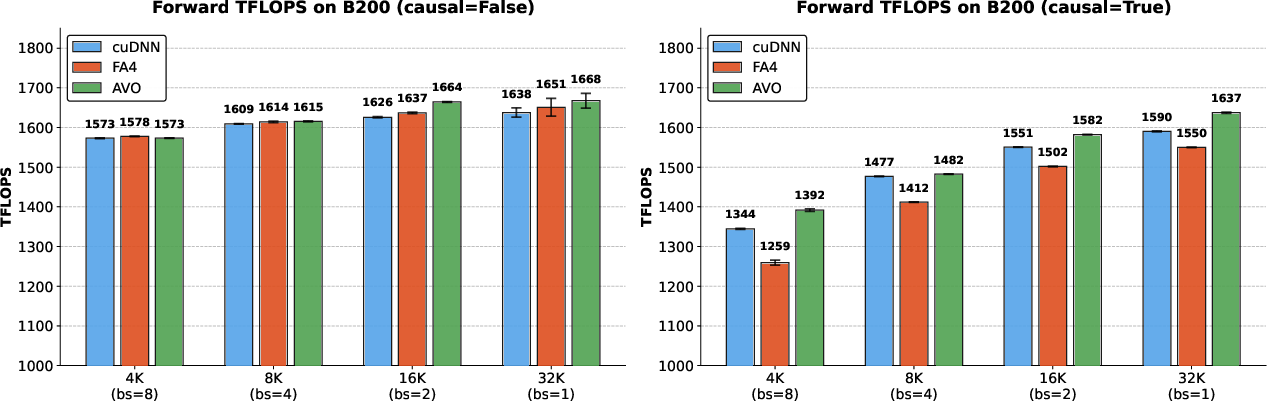
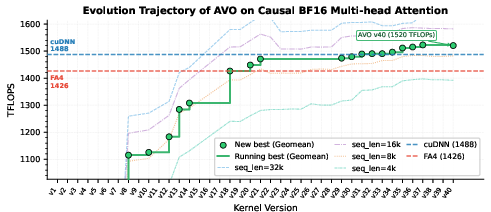
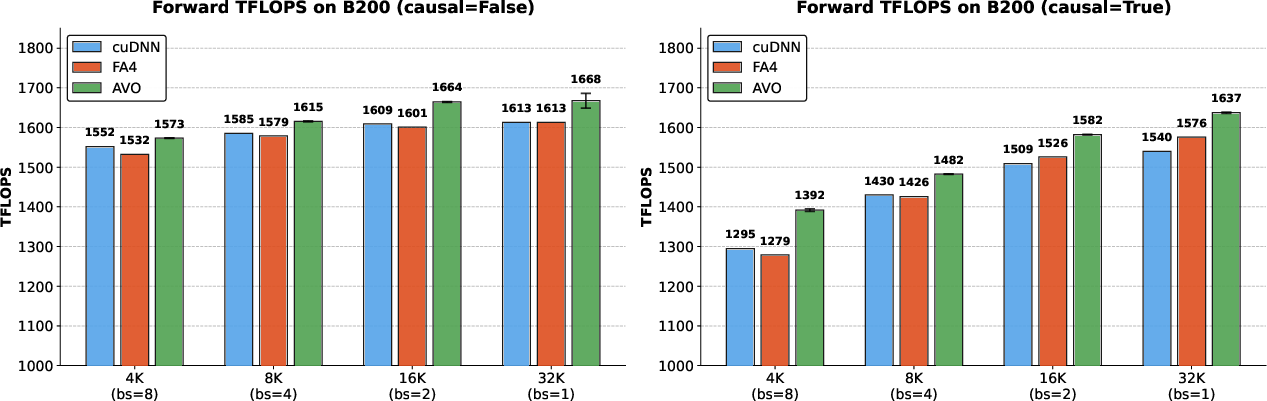
- The agent discovered faster versions of the attention kernel. In multi-head attention (MHA), it achieved up to 1668 TFLOPS and beat:
- cuDNN by up to 3.5%
- FlashAttention-4 by up to 10.5%
- The improvements weren’t just surface-level. The agent made deep, hardware-aware changes, such as:
- Removing unnecessary “if” checks so the GPU spends less time waiting (like skipping a stoplight when it’s obviously green every time).
- Overlapping tasks so different parts of the program work at the same time instead of standing in line (like two cooks working on different steps of a recipe in parallel).
- Rebalancing how the program uses very fast storage slots called “registers,” so the parts doing the most work get more of them (like giving the busiest teammates more tools).
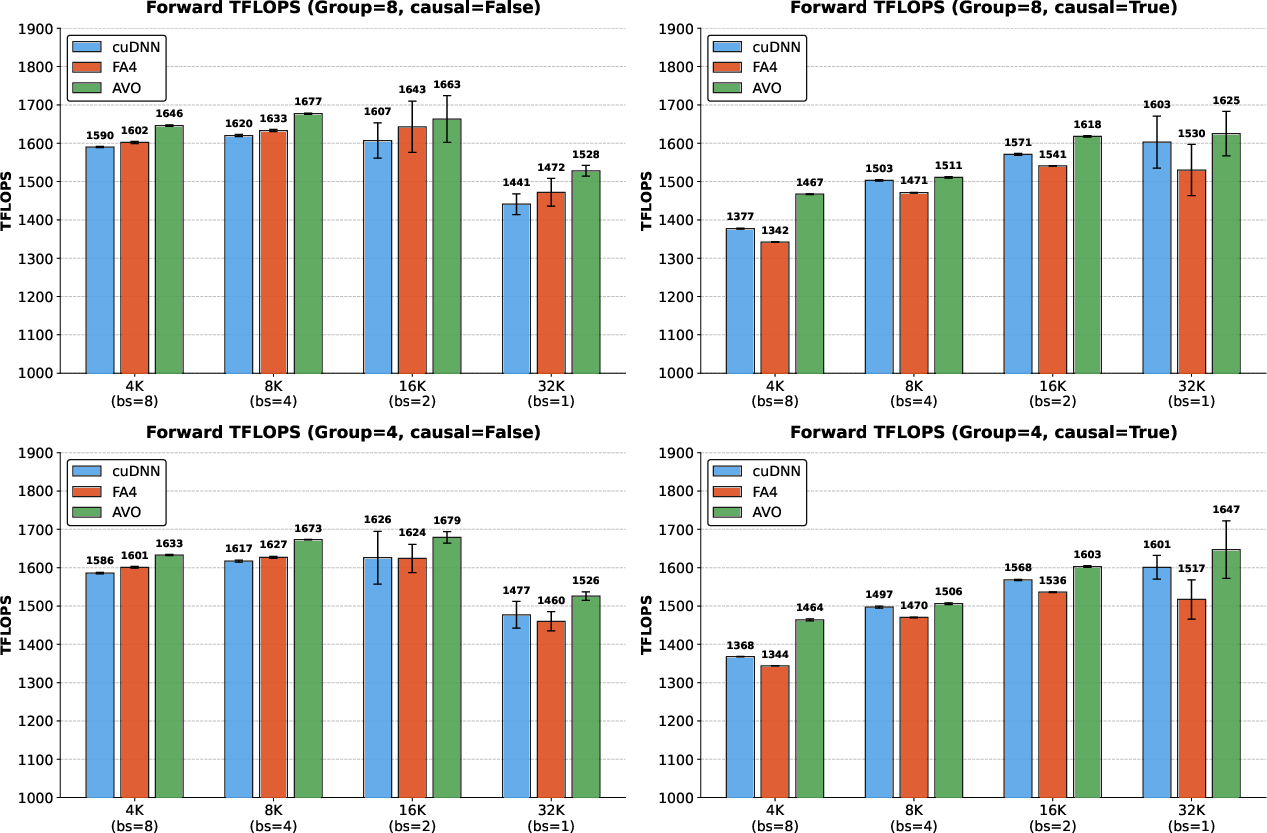
- These ideas transferred to grouped-query attention (GQA). With about 30 minutes of extra autonomous editing, the agent produced a GQA version that beat:
- cuDNN by up to 7.0%
- FlashAttention-4 by up to 9.3%
Why small percentages matter: When you run these kernels millions or billions of times across big AI systems, a 3–10% speedup saves huge amounts of time and money.
Why it matters
- It shows AI can be more than a one-shot code writer. As a true “agent,” it can plan, read docs, diagnose problems, and iterate—like a junior engineer that learns by doing and measuring.
- Even against expert-tuned, state-of-the-art code on the newest hardware, the agent found meaningful improvements. That suggests this approach could help optimize many other performance-critical programs.
- Faster attention means faster or cheaper AI training and inference, which benefits everything from research to real-world apps.
- The method is general: the same kind of agent could be used to tune other kernels, libraries, or even different kinds of software and hardware.
In short: the paper introduces a smarter way to search for better code—by making the AI itself the “variation operator” that plans and improves over time. It worked: the agent found real speedups in some of the most optimized AI code out there and transferred its tricks to related tasks with very little extra effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the paper, framed so that future researchers can act on each item.
- Population-level evolution is not evaluated: AVO is studied in a single-lineage regime only; there is no empirical comparison to archive-based or island-based population strategies, nor analysis of how branching, diversity maintenance, or archive management would impact search efficiency and solution quality.
- Absence of controlled ablations isolating “agentic” contributions: The paper does not compare AVO against (a) single-turn LLM generators with identical compute budgets, (b) scripted multi-step LLM workflows, or (c) heuristic mutation operators, leaving the specific gains attributable to autonomy, persistent memory, or tool use unquantified.
- Limited domain scope (only attention kernels): Claims of generality are not substantiated beyond MHA/GQA on NVIDIA Blackwell; it remains unknown how AVO performs on other kernels (e.g., MLP/activation, layer norm, fused ops, convolutions), other operator classes (sparse, graph), or outside GPU kernel optimization (e.g., compilers, systems).
- Hardware generalization is untested: Results are only on NVIDIA B200; there is no evaluation on Hopper/Ampere GPUs, AMD GPUs, CPUs, TPUs, or specialized accelerators, nor a study of portability across architectures and driver/CUDA versions.
- Backward pass and training workloads are omitted: Only forward prefilling throughput is optimized; backward kernels, end-to-end training throughput, and stability under mixed-precision training are not evaluated.
- Critical inference scenarios are missing: No results for autoregressive decode (KV-cache reuse), variable-length batching, sliding-window/paged attention, cross-attention, or dynamic shapes—all common deployment settings.
- Narrow configuration space: Benchmarks fix BF16 precision, head dimension 128, and specific sequence lengths totaling 32k tokens; performance for other head dimensions, precisions (FP8/FP16/INT8), larger/smaller contexts, and different batch/sequence mixes is unreported.
- Limited GQA validation: GQA transfer is demonstrated on two configurations only (group sizes 8 and 4) and for the forward pass; broader coverage (e.g., MQA, other group sizes, backward pass) is not provided.
- Potential benchmark overfitting: The agent commits only when it improves a fixed benchmark suite, but generalization beyond the chosen configurations is only lightly tested (GQA); there is no held-out shape suite or cross-workload validation to detect over-specialization.
- No statistical significance analysis: Although averages and standard deviations are mentioned, figures lack error bars and significance tests; speedups near “measurement noise” are not rigorously distinguished from variance.
- Reproducibility is unclear: The paper does not state whether code, evolved kernels, prompts, knowledge base contents, agent configurations, or seeds will be released; the use of an internal frontier LLM further challenges replication.
- Compute/energy cost and scalability are unspecified: The number of GPUs/SMs used, parallelism level, energy consumption, and wall-clock to speedup trade-offs are not reported, making it difficult to assess practicality and cost-effectiveness versus expert engineering.
- Supervisor mechanism is underspecified: The “self-supervision” component that detects stalls and reorients search is not detailed (criteria, algorithms, thresholds), leaving its contribution and reproducibility unknown.
- Evaluation metrics are single-objective: Optimization targets only TFLOPS; impacts on latency (especially at small batch), memory footprint, peak allocation, power, thermal throttling, and determinism are not measured or jointly optimized.
- Robustness of correctness checks is not detailed: Tolerances, test distributions, edge cases (extreme values, long sequences), and cross-precision consistency are not described; only forward numerical correctness is enforced, with no formal verification or stress-testing.
- Stability across toolchain changes is untested: Kernel performance and correctness under different CUDA versions, compilers, drivers, and microcode revisions are not evaluated; resilience to future hardware/driver updates is unknown.
- Portability risks from micro-architectural tuning: Several optimizations exploit Blackwell-specific behavior (e.g., register budgets, fences); the extent to which these kernels degrade or fail on other architectures is not investigated.
- Risk of brittle code is not assessed: The maintainability, readability, and long-term supportability of agent-evolved kernels are not analyzed (e.g., complexity, reliance on undefined behavior, sensitivity to small codegen changes).
- Limited profiler-driven transparency: While Nsight-like profiling is implied, the paper does not disclose full kernel-level metrics (occupancy, SM efficiency, memory throughput, stall reasons) for baseline vs AVO, constraining diagnostic replicability.
- Fairness of baseline tuning is uncertain: It is unclear whether FA4/cuDNN were exhaustively tuned for the exact shapes, driver versions, and flags used; details on autotuning budgets and environment parity are missing.
- Seed program dependency and knowledge-base bias: The starting implementation(s) and contents of the domain-specific knowledge base (including FA4 code) may strongly steer outcomes; dependence on pre-existing high-quality kernels is not quantified.
- LLM dependence and model choice are opaque: The specific models, context lengths, function calling/tools, and memory mechanisms are not disclosed; it is unknown whether comparable results are achievable with open-source models.
- Failure mode characterization is limited: Beyond qualitative notes on stalling/cycling, the paper lacks quantitative analyses of failure frequency, recovery rates, or the distribution of dead-end explorations.
- No theoretical framing or guarantees: The agentic operator is described operationally without convergence analysis, sample-efficiency theory, or connections to bandit/MDP formulations that could guide principled improvements.
- Integration into compilers and autotuners is unexplored: How AVO interplays with or augments systems like TVM/Ansor, Triton, CUTLASS, or vendor autotuners (e.g., seeding schedules, hybrid search) is not evaluated.
- Multi-objective and constrained optimization is unaddressed: Incorporating constraints (e.g., memory caps, latency targets, determinism, numerical stability) or Pareto-front search is not demonstrated.
- Multi-kernel and graph-level co-optimization is absent: Potential gains from jointly optimizing interacting kernels (e.g., fused attention + MLP, epilogue fusion) or end-to-end graph schedules are not studied.
- Scaling beyond days-long runs: The effect of longer/shorter runs, adaptive budget allocation, or parallel agent ensembles on final performance and search diversity is not quantified.
- Security and safety of autonomous tool use: The agent executes shell commands and edits code; sandboxing, permissioning, and mitigations against destructive actions or data exfiltration are not described.
- IP/compliance considerations for evolved kernels: Given the use of proprietary docs and code references, the legal and licensing status of agent-generated kernels and their redistributability is not discussed.
Practical Applications
Immediate Applications
Below are deployable use cases that can be adopted with today’s tools and hardware, grounded directly in the paper’s results on NVIDIA Blackwell (B200) GPUs and the AVO workflow.
- Bold-line production speedups for Transformer inference (prefill path) — Sectors: software, AI infrastructure, cloud — Tools/products/workflows: integrate the AVO-evolved MHA/GQA kernels into TensorRT-LLM, PyTorch extensions, or custom inference servers to shave 3–10%+ latency/cost on B200 for BF16 attention; create CI jobs that swap in AVO kernels for specific shapes (e.g., head dim 128, 16 heads) where they outperform cuDNN/FA4 — Assumptions/dependencies: access to B200 GPUs; correctness harnesses and numeric tolerance checks; guardrails for inline PTX; workloads match or are close to the benchmarked regimes (forward prefilling, BF16)
- Rapid adaptation of attention variants (e.g., GQA) via agent-led retargeting — Sectors: software, AI infrastructure — Tools/products/workflows: “AVO adaptation jobs” that auto-port an optimized MHA kernel to GQA or minor model variants during model rollout; workflow triggered after model shape changes — Assumptions/dependencies: domain-specific knowledge base (KB) describing the variant; reproducible benchmarking scripts; agent sandboxing
- Continuous performance regression triage and auto-remediation — Sectors: software, DevOps/MLOps — Tools/products/workflows: add an AVO-based “perf guard” stage in CI/CD that (a) runs Nsight Compute/FA4 benchmarks, (b) detects regressions, (c) launches a bounded agentic optimization loop to recover or beat baseline — Assumptions/dependencies: stable perf baselines; profiler access on dedicated runners; strict time/compute quotas; automatic rollback
- Targeted micro-architectural optimization campaigns for hot kernels — Sectors: software, HPC, AI systems — Tools/products/workflows: run 48–168 hour AVO sprints focused on specific ops (e.g., KV-cache update, RMSNorm, rotary embeddings, small GEMMs, fused epilogues), harvesting agent-discovered tactics (branchless rescaling, pipeline overlap, register rebalancing) into CUTLASS/Triton templates — Assumptions/dependencies: high-quality test oracles; hardware counters; expert review for safety and maintainability
- Compiler/autotuner augmentation (TVM/Ansor, Triton, CUTLASS) — Sectors: software, compilers — Tools/products/workflows: plug AVO in as a learned “variation backend” to explore schedule/codegen changes beyond parameter sweeps; export agent commits as reproducible schedule recipes — Assumptions/dependencies: integration APIs; deterministic builds; search budgets; legal clarity for generated code reuse
- Vendor and library feedback loops (kernel template hardening) — Sectors: semiconductors, systems software — Tools/products/workflows: mine AVO trajectories to extract portable heuristics (e.g., branchless correction paths, warp-group register budgets) and upstream them into cuDNN/CUTLASS/TensorRT templates — Assumptions/dependencies: access to internal/perf docs; IP review; reproducibility across driver versions
- Academic teaching labs for GPU optimization — Sectors: education, academia — Tools/products/workflows: course modules where students inspect agent trajectories (commits, profiler traces, design notes) to learn warp specialization, fencing, and scheduling; “agent vs. human” lab assignments — Assumptions/dependencies: sanitized datasets of agent logs; affordable GPU time; simplified harnesses
- Open benchmarking and reproducible research baselines — Sectors: academia, open-source — Tools/products/workflows: release “AVO-bench for kernels” with standardized harnesses (like FA4’s scripts), versioned seeds, and scoring; enable fair comparison of agentic search methods — Assumptions/dependencies: permissive licensing for seeds/harnesses; hosted artifacts and runner scripts
- Datacenter energy and cost efficiency tuning — Sectors: energy, cloud ops, policy within organizations — Tools/products/workflows: treat AVO optimizations as a “software efficiency credit”; incorporate into fleet planning to reduce energy/cost per token served — Assumptions/dependencies: the organization’s workload mix includes B200 attention-heavy inference; metering that ties micro-speedups to energy KPIs
- Developer-quality-of-life via pre-optimized open kernels — Sectors: daily life (developers), open-source — Tools/products/workflows: ship prebuilt wheels/whls with AVO kernels for popular shapes; toggle via an environment flag — Assumptions/dependencies: compatibility with user drivers/CUDA; fallbacks to vendor kernels; shape guards
Long-Term Applications
Below are higher-impact directions that need further research, scaling, or engineering before broad deployment.
- End-to-end “self-driving performance engineer” for the ML stack — Sectors: software, AI infrastructure — Tools/products/workflows: an always-on agent that tunes attention, matmul fusions, data loaders, NCCL collectives, and caching strategies across training and inference stacks — Assumptions/dependencies: richer KBs spanning compilers, kernels, runtimes, distributed systems; robust multi-objective scoring (throughput, memory, accuracy, cost)
- Cross-architecture retargeting (AMD ROCm, Apple/Qualcomm NPUs, TPUs, custom ASICs) — Sectors: semiconductors, edge, mobile — Tools/products/workflows: AVO variants that learn ISA-, memory-, and scheduler-specific playbooks for each backend; auto-port attention optimizations across vendors — Assumptions/dependencies: access to toolchains/profilers/docs; vendor cooperation; different precision and memory models; retooled test oracles
- Population-level agentic evolution and design-space exploration — Sectors: software, research platforms — Tools/products/workflows: extend single-lineage AVO to island/archive regimes for broader, parallel exploration with novelty search and automated deduplication — Assumptions/dependencies: orchestration at scale; result merging; diversity metrics; robust failure isolation
- Automated co-design of algorithms and kernels — Sectors: software, research — Tools/products/workflows: agents that propose algorithmic refactors (e.g., attention tiling strategies, online softmax variants) jointly with kernel schedules to unlock new performance frontiers — Assumptions/dependencies: flexible correctness specs; multi-run ablations; acceptance criteria for algorithmic changes in production models
- Hardware–software feedback for next-gen ISAs and SM micro-architecture — Sectors: semiconductors — Tools/products/workflows: mine agent-discovered pain points (fences, register budgets, warp roles) to inform future tensor core ops, barriers, or TMA features; “AVO-in-the-loop” micro-arch design — Assumptions/dependencies: simulators, pre-silicon models; IP firewalls; long hardware lead times
- Verified, safety-certified agentic optimization frameworks — Sectors: policy, compliance, critical infrastructure — Tools/products/workflows: formal guardrails (capability sandboxing, code signing, provenance tracking), conformance test suites, and audit trails for autonomous code changes — Assumptions/dependencies: standards bodies buy-in; third-party certification; reproducible builds; secure runners
- Generalization to training/backward passes and mixed-precision regimes — Sectors: AI infrastructure — Tools/products/workflows: extend AVO to backward attention, optimizer steps, and different dtypes (FP8/INT8) with calibration-aware correctness — Assumptions/dependencies: numerics-sensitive oracles; stability checks; more complex kernels and dataflows
- Self-optimizing cloud fleets and per-SKU specialization — Sectors: cloud, operations — Tools/products/workflows: fleet services that auto-learn best kernel variants per GPU SKU and workload pattern; dynamic dispatch guided by online telemetry — Assumptions/dependencies: safe canarying; live A/B; model- and tenant-aware policy; version skew handling
- Autonomously maintained performance templates for compilers — Sectors: compilers, OSS ecosystems — Tools/products/workflows: agents that continuously refresh Triton/TVM/CUTLASS schedules as drivers/firmware change; PR bots with full ablation reports — Assumptions/dependencies: maintainer trust processes; reproducibility across environments; governance for generated code
- Application to non-ML HPC domains (CFD, genomics, weather, sparse linear algebra) — Sectors: HPC, scientific computing — Tools/products/workflows: AVO agents specializing on domain kernels (FFT, sparse SpMM, stencil ops), integrating domain-specific correctness suites and physics constraints — Assumptions/dependencies: high-fidelity test harnesses; mixed CPU–GPU pipelines; domain-expert-curated KBs
- On-device/edge continuous optimization for robotics and AR/VR — Sectors: robotics, edge, consumer devices — Tools/products/workflows: constrained AVO agents that adapt kernels to device thermal envelopes and battery limits; periodic offline re-optimization pushed via updates — Assumptions/dependencies: resource-constrained agents; strict safety limits; opaque vendor drivers
- Economic and environmental policy levers for software efficiency — Sectors: policy, sustainability — Tools/products/workflows: encourage adoption of autonomous optimization (e.g., procurement guidelines rewarding verified efficiency gains; carbon accounting that credits software-side savings) — Assumptions/dependencies: standardized measurement protocols; third-party verification; interoperability with existing ESG reporting
Notes on Key Dependencies and Assumptions Spanning Many Applications
- Hardware and toolchain access: Results are demonstrated on NVIDIA B200 with CUDA 13.1; porting requires equivalent profilers (Nsight), compilers, and ISA docs on other platforms.
- Correctness and safety: High-quality, shape-complete test oracles; numeric stability checks for different masks/precisions; sandboxed execution of generated code.
- Compute budget and time: Multi-day autonomous runs (e.g., 7 days) require scheduled GPU time and job resilience; production integrations need tight caps and rollback plans.
- Knowledge base quality: Up-to-date CUDA/PTX/architecture references and baseline sources (e.g., FA4) meaningfully improve agent performance.
- Licensing/IP: Clarity around reuse of generated code and upstreaming into vendor or open-source libraries.
- Scope alignment: The paper focuses on forward-pass prefilling attention; extrapolations to training, other ops, or other hardware are promising but require validation.
Glossary
- Agentic Variation Operators (AVO): A family of evolutionary variation operators that replace fixed mutations/crossovers with an autonomous coding agent capable of planning, tool use, and iterative self-improvement. "Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents."
- Barrier-based signaling: A synchronization mechanism where threads/warps coordinate progress via barriers. "with barrier-based signaling to coordinate handoffs."
- BF16 precision: A 16-bit floating-point format (bfloat16) commonly used to accelerate deep learning on modern hardware. "achieving up to 1668 TFLOPS at BF16 precision"
- Blackwell (B200) GPUs: NVIDIA’s Blackwell-generation GPUs (model B200) targeted for advanced AI workloads. "on NVIDIA Blackwell (B200) GPUs."
- Boltzmann selection: An evolutionary selection strategy that samples candidates probabilistically based on fitness using a Boltzmann distribution. "LoongFlow similarly relies on a MAP-Elites archive with Boltzmann selection for "
- Branchless accumulator rescaling: An optimization that removes conditional branches when rescaling accumulators, reducing divergence and synchronization overhead. "Branchless accumulator rescaling"
- Bounded archive: A population archive with limited size that prunes lower-scoring members to maintain capacity. "possibly pruning low-score members to maintain a bounded archive."
- Causal attention: Attention with a causal mask preventing each token from attending to future tokens. "For causal attention, some K-block iterations are fully masked (no valid attention entries) and others are fully unmasked, leading to different execution paths within the same kernel."
- Correction warps: Specialized warps responsible for rescaling outputs during online softmax or normalization steps in attention kernels. "Correction warps rescale the output accumulator when the running maximum changes across K-block iterations (a requirement of the online softmax algorithm)."
- CUDA: NVIDIA’s parallel computing platform and programming model for GPUs. "each is a CUDA kernel implementation (source code with inline PTX)"
- cuDNN: NVIDIA’s library of highly optimized primitives for deep learning, including attention kernels. "We compare against two state-of-the-art baselines: (1) cuDNN: NVIDIA's closed-source attention kernel"
- Domain-specific knowledge base: A curated set of references (docs, specs, code) relevant to a particular technical domain. "a domain-specific knowledge base"
- Dual Q-stage design: A pipelining strategy where two query tiles are processed concurrently to increase utilization. "these groups operate concurrently across two Q-tiles (a dual Q-stage design), with barrier-based signaling to coordinate handoffs."
- Epilogue warps: Warps that handle the final stages of a kernel’s computation, often including data movement or writeback. "Load and epilogue warps handle data movement via the Tensor Memory Accelerator (TMA)."
- Evolutionary search: An optimization paradigm that iteratively improves a population of candidates using variation and selection. "Evolutionary search optimizes over a space of candidates by maintaining a population and iteratively expanding it with new solutions"
- FlashAttention-4 (FA4): A state-of-the-art attention kernel family optimized for modern NVIDIA GPUs. "both FlashAttention-4 (FA4) and cuDNN requiring months of manual optimization on the latest Blackwell architecture."
- Forward-pass prefilling throughput: The throughput metric (often in TFLOPS) for the forward prefilling phase of attention inference. "Multi-head attention forward-pass prefilling throughput (TFLOPS) on NVIDIA B200 with head dimension 128, 16 heads, and BF16 precision."
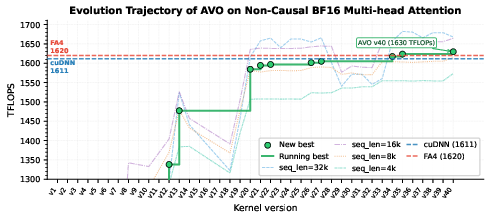
- Geometric mean throughput: A performance aggregation metric that uses the geometric mean across configurations to summarize throughput. "The solid green line tracks the running-best geometric mean throughput across all configurations;"
- Grouped-query attention (GQA): An attention variant where multiple query heads share a smaller set of key-value heads to reduce memory/compute. "The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation"
- Inline PTX: Embedding NVIDIA’s PTX assembly directly within CUDA C++ for fine-grained control. "each is a CUDA kernel implementation (source code with inline PTX)"
- Instruction pipeline scheduling: The arrangement of instructions to optimize overlapping execution stages and minimize stalls on the hardware pipeline. "including register allocation, instruction pipeline scheduling, and workload distribution,"
- Island-based evolutionary database: A population structure where multiple sub-populations (“islands”) evolve in parallel, exchanging solutions occasionally. "AlphaEvolve maintains an island-based evolutionary database inspired by MAP-Elites"
- MAP-Elites: An archive-based evolutionary algorithm that maintains diverse high-performing solutions across behavior niches. "inspired by MAP-Elites"
- Memory-bound: A regime where performance is limited by memory bandwidth/latency rather than compute capacity. "making the operation memory-bound for large sequence lengths ."
- Micro-architectural optimizations: Low-level hardware-aware refinements (e.g., registers, synchronization, scheduling) to improve performance. "micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations"
- MMA warps: Warps dedicated to matrix multiply-accumulate operations using tensor cores. "MMA warps execute the two core matrix multiplications via Blackwell's tensor core instructions"
- Non-blocking fence: A memory-ordering primitive that enforces ordering without waiting for completion of prior memory operations. "with a lighter non-blocking fence that merely enforces ordering."
- Non-causal attention: Attention without causal masking, allowing every token to attend to all others. "On non-causal attention, AVO achieves modest gains at longer sequences"
- Online softmax: An incremental softmax computation that maintains running statistics to avoid materializing full intermediate results. "applying the online softmax algorithm with a running row-maximum."
- PTX ISA: NVIDIA’s Parallel Thread Execution instruction set architecture for GPU assembly-level programming. "PTX ISA documentation"
- PUCT-based selection rule: A tree search policy (Predictor + UCT) guiding which nodes/candidates to expand based on value and exploration. "a PUCT-based selection rule determines which states to expand,"
- PV GEMM: The matrix multiplication of softmax probabilities P with V in attention (i.e., P times V). "and the PV GEMM (multiplying the softmax output by to accumulate the output )."
- Q-tiles: Tiled partitions of the query matrix processed in stages to enable pipelining and parallelism. "these groups operate concurrently across two Q-tiles (a dual Q-stage design)"
- QK GEMM: The matrix multiplication of Q and KT to compute attention scores. "the QK GEMM (producing scores )"
- QK-PV interleaving: An execution strategy that interleaves QK and PV phases to improve pipeline utilization. "the introduction of QK-PV interleaving with bitmask causal masking (version 8)"
- Register allocation: The assignment of variables to limited hardware registers to minimize spills and maximize throughput. "including register allocation, instruction pipeline scheduling, and workload distribution,"
- Register rebalancing across warp groups: Adjusting register budgets among warp groups to reduce spills and balance critical paths. "Register Rebalancing Across Warp Groups"
- Running row-maximum: The current maximum per row maintained during online softmax to ensure numerical stability. "maintaining a running softmax (with running row-maximum and row-sum)"
- Scoring function: The evaluation function that measures candidate quality (e.g., correctness and performance). "where is a scoring function that evaluates each candidate solution."
- Single-lineage setting: An evolutionary regime that maintains and improves a single chain of solutions rather than a diverse population. "In this paper we study the single-lineage setting to isolate the effect of the operator itself."
- Softmax warps: Warps dedicated to softmax computation within the attention kernel pipeline. "Softmax warps compute attention weights from the scores , applying the online softmax algorithm with a running row-maximum."
- Tensor core instructions: Specialized GPU instructions for matrix operations on tensor cores to accelerate GEMMs. "via Blackwell's tensor core instructions"
- Tensor Memory Accelerator (TMA): A hardware-assisted data movement engine used to efficiently transfer tensors. "Load and epilogue warps handle data movement via the Tensor Memory Accelerator (TMA)."
- TFLOPS: Trillions of floating-point operations per second, a throughput metric for compute performance. "producing MHA kernels achieving up to 1668 TFLOPS at BF16 precision"
- Tiling: Decomposing computation into blocks/tiles to improve locality and reduce memory overhead. "This tiling eliminates the need to store the full score matrix, shifting the bottleneck from memory bandwidth to compute throughput on modern GPUs."
- Warp divergence: When threads within a warp follow different control paths, reducing efficiency. "the agent also removed warp divergence in the correction path"
- Warp groups: Subsets of warps within a thread block assigned to different roles for specialization. "different warp groups within a thread block are assigned distinct roles in the attention pipeline."
- Warp specialization: Assigning distinct functional roles to different warps to pipeline and parallelize kernel stages. "employ warp specialization"
Collections
Sign up for free to add this paper to one or more collections.

