- The paper introduces SATLUTION, an autonomous framework leveraging LLM agents to iteratively evolve SAT solvers across large codebases.
- It employs a multi-agent system with planning and coding agents along with a dynamic rulebase to ensure performance improvements and correctness.
- Empirical results demonstrate that evolved solvers outperform human-designed competitors in SAT competitions through enhanced efficiency and scalability.
Autonomous Code Evolution for SAT Solving: The SATLUTION Framework
Introduction
The paper "Autonomous Code Evolution Meets NP-Completeness" (2509.07367) presents SATLUTION, an agentic framework for repository-scale, autonomous code evolution targeting Boolean Satisfiability (SAT) solving. SATLUTION leverages LLM agents to iteratively improve entire SAT solver repositories, encompassing hundreds of files and tens of thousands of lines of C/C++ code. The system orchestrates planning and coding agents, guided by a rulebase encoding domain knowledge and correctness constraints, to autonomously generate, verify, and evaluate solver modifications. SATLUTION demonstrates the ability to evolve solvers that decisively outperform human-designed winners of the SAT Competition 2025, despite being trained only on 2024 codebases and benchmarks.
SATLUTION Architecture and Evolution Process
SATLUTION is structured as a multi-agent system with two primary LLM-driven agents: a Planning Agent and a Coding Agent. The Planning Agent formulates high-level improvement strategies based on performance feedback and domain-specific rules, while the Coding Agent implements these strategies by directly modifying the solver repository. The evolution process is governed by a static and dynamically self-evolving rulebase, which encodes SAT-specific heuristics, correctness requirements, and repository structure constraints.
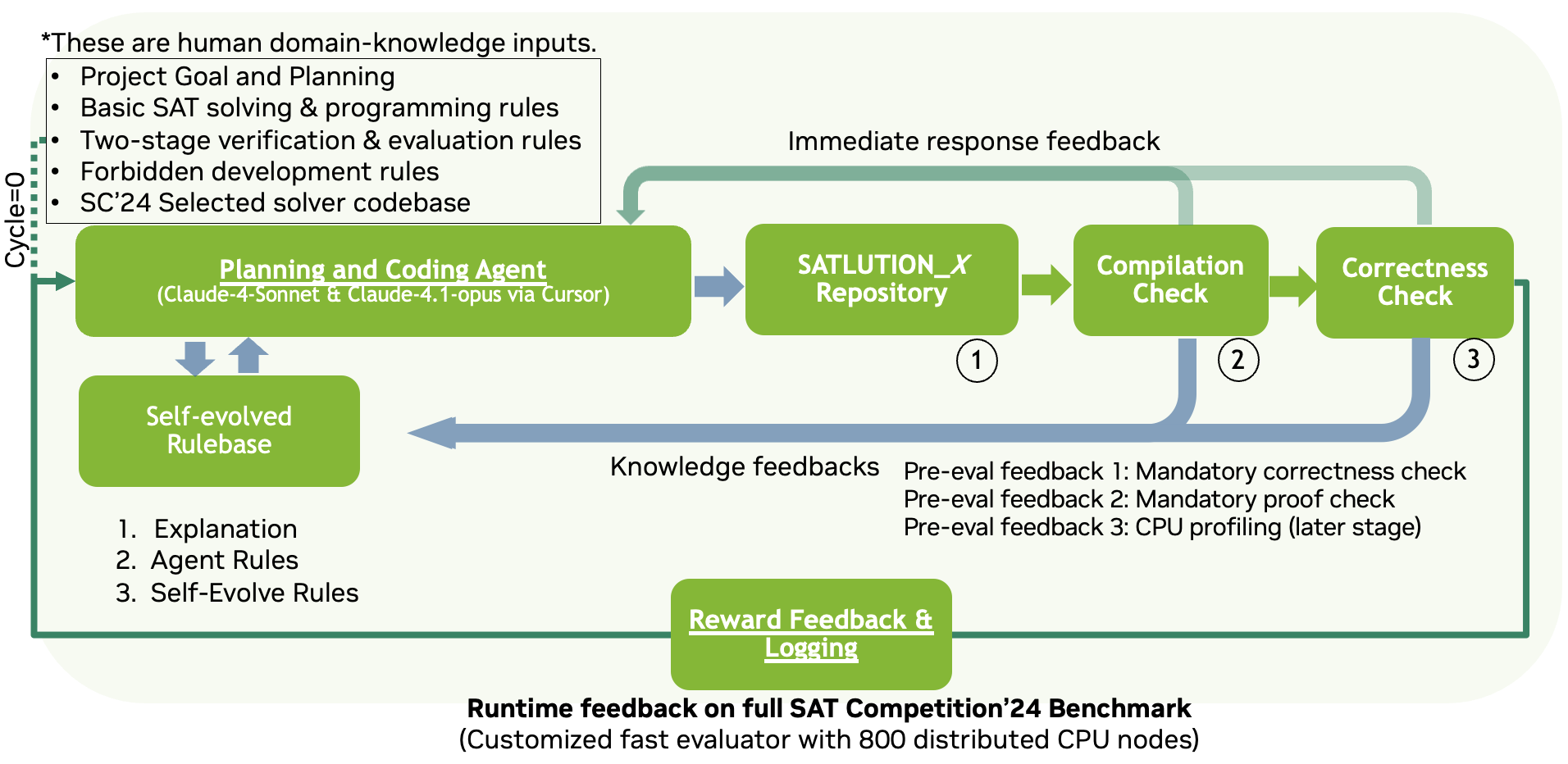
Figure 1: SATLUTION's self-evolving agent framework, illustrating the iterative loop of planning, coding, verification, evaluation, and feedback.
Each evolution cycle consists of the following steps:
- Planning: The agent analyzes current solver performance and proposes targeted modifications.
- Coding: The agent edits the repository, updates build scripts, and documents changes.
- Verification: A two-stage pipeline checks compilation, basic functionality, and correctness (SAT/UNSAT validation, DRAT proof checking).
- Evaluation: The solver is benchmarked on distributed clusters, and multi-faceted feedback is returned.
- Rulebase Update: The rule system is refined based on observed failures and successes, enabling adaptive evolution.
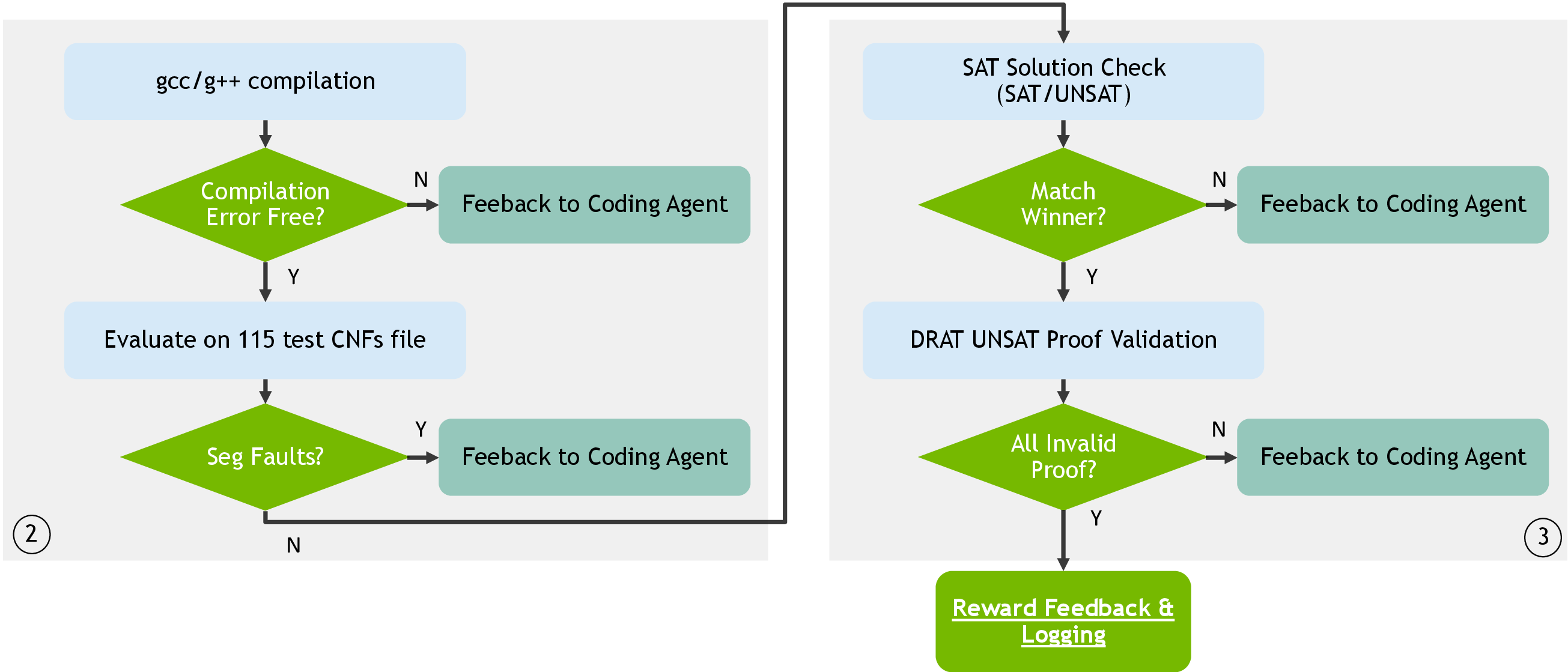
Figure 2: Two-stage verification pipeline for solver correctness, ensuring only sound and robust solvers proceed to evaluation.
SATLUTION's evolved solvers were evaluated on the SAT Competition 2025 benchmark, achieving the lowest PAR-2 scores among all entrants. Notably, the system was trained exclusively on 2024 benchmarks and codebases, yet demonstrated strong generalization to the unseen 2025 benchmark set.
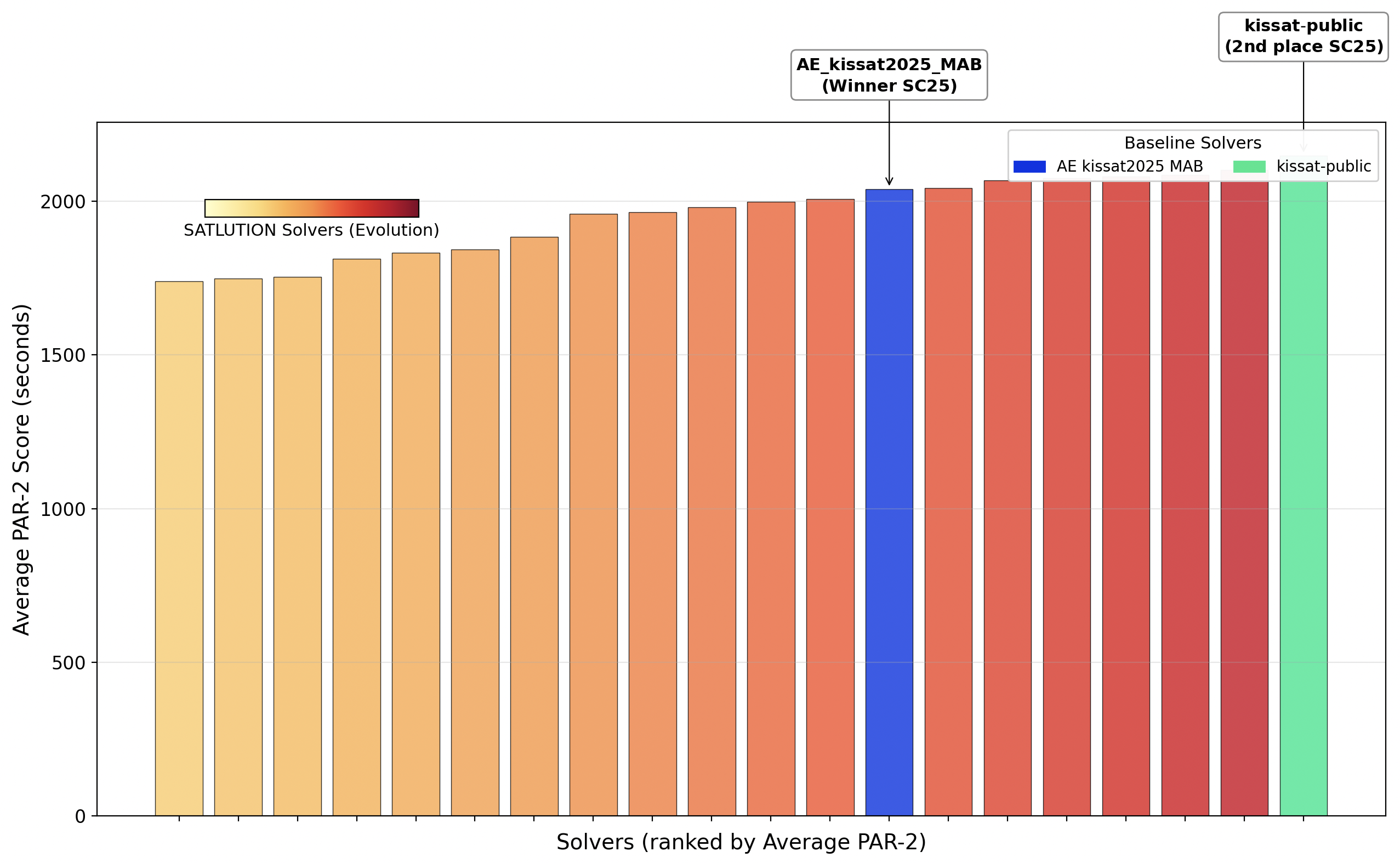
Figure 3: SAT Competition 2025 overall results. SATLUTION attained the lowest PAR-2 score, outperforming the top-2 2025 winning solvers.
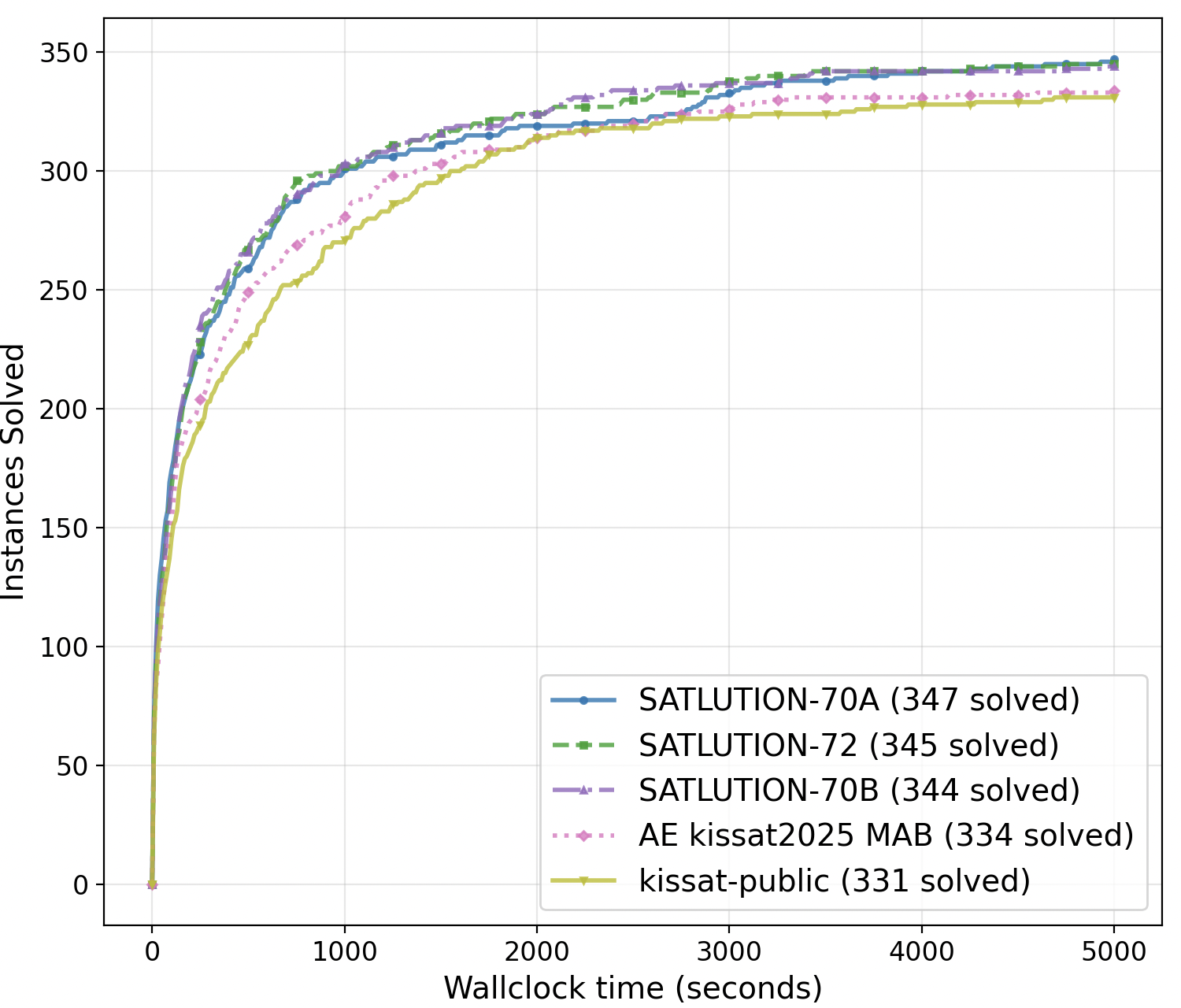
Figure 4: Cactus plot comparing SATLUTION's best evolved solvers with the 2025 gold and silver medalists, showing superior instance-solving rates across runtime thresholds.
SATLUTION's solvers consistently solved more instances and did so faster than the competition winners, with pronounced advantages in the medium-to-hard runtime regime. The breakdown by satisfiable and unsatisfiable instances further highlights balanced improvements:
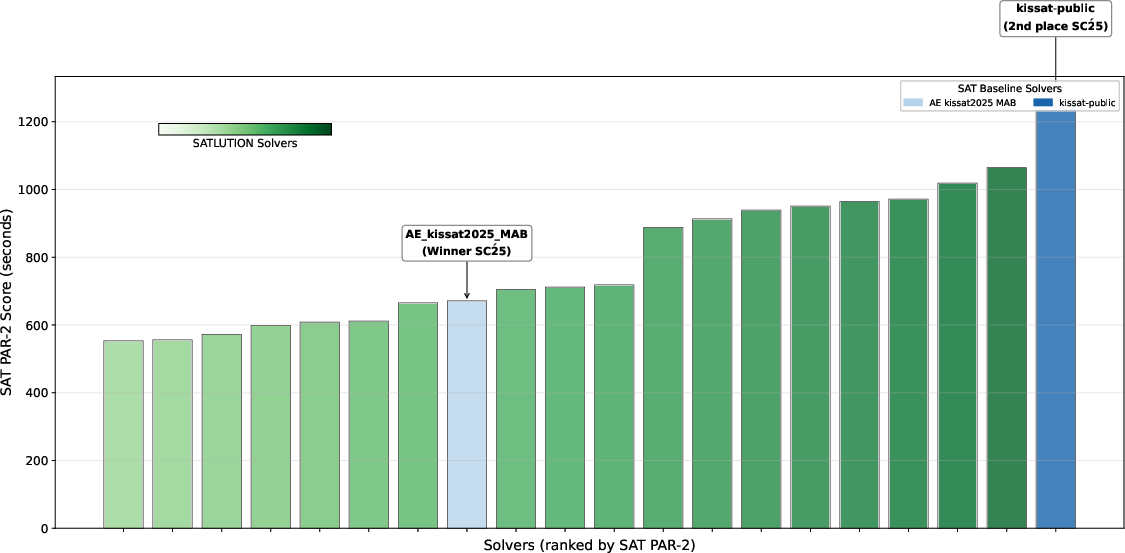
Figure 5: SATLUTION achieves the best PAR-2 performance on satisfiable instances in the 2025 benchmark.
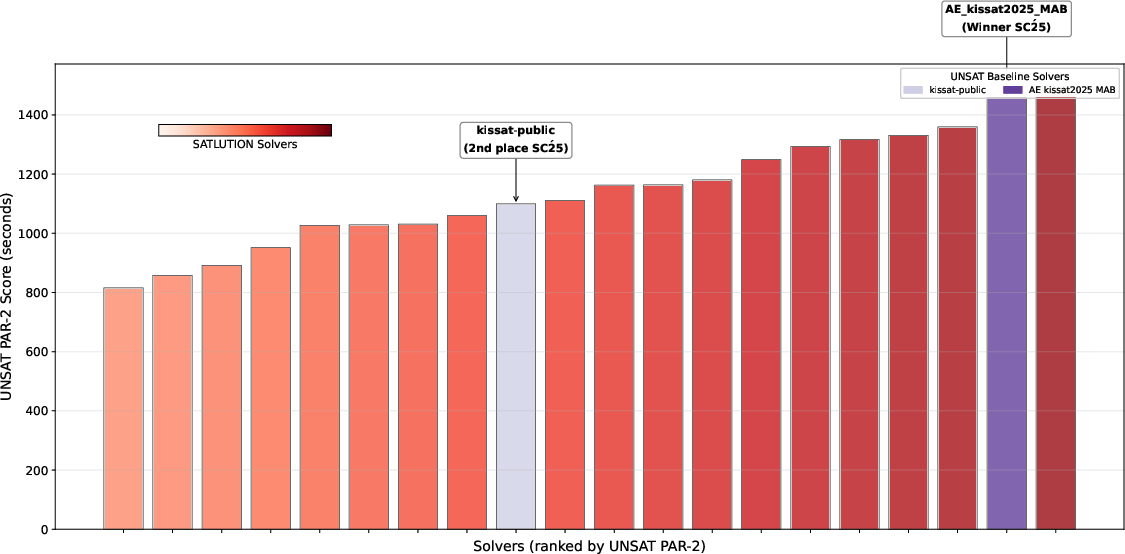
Figure 6: SATLUTION demonstrates superior efficiency on unsatisfiable instances as well.
On the SAT Competition 2024 benchmark, SATLUTION also outperformed both the 2024 and 2025 champions, indicating robust improvements across multiple years and instance distributions.
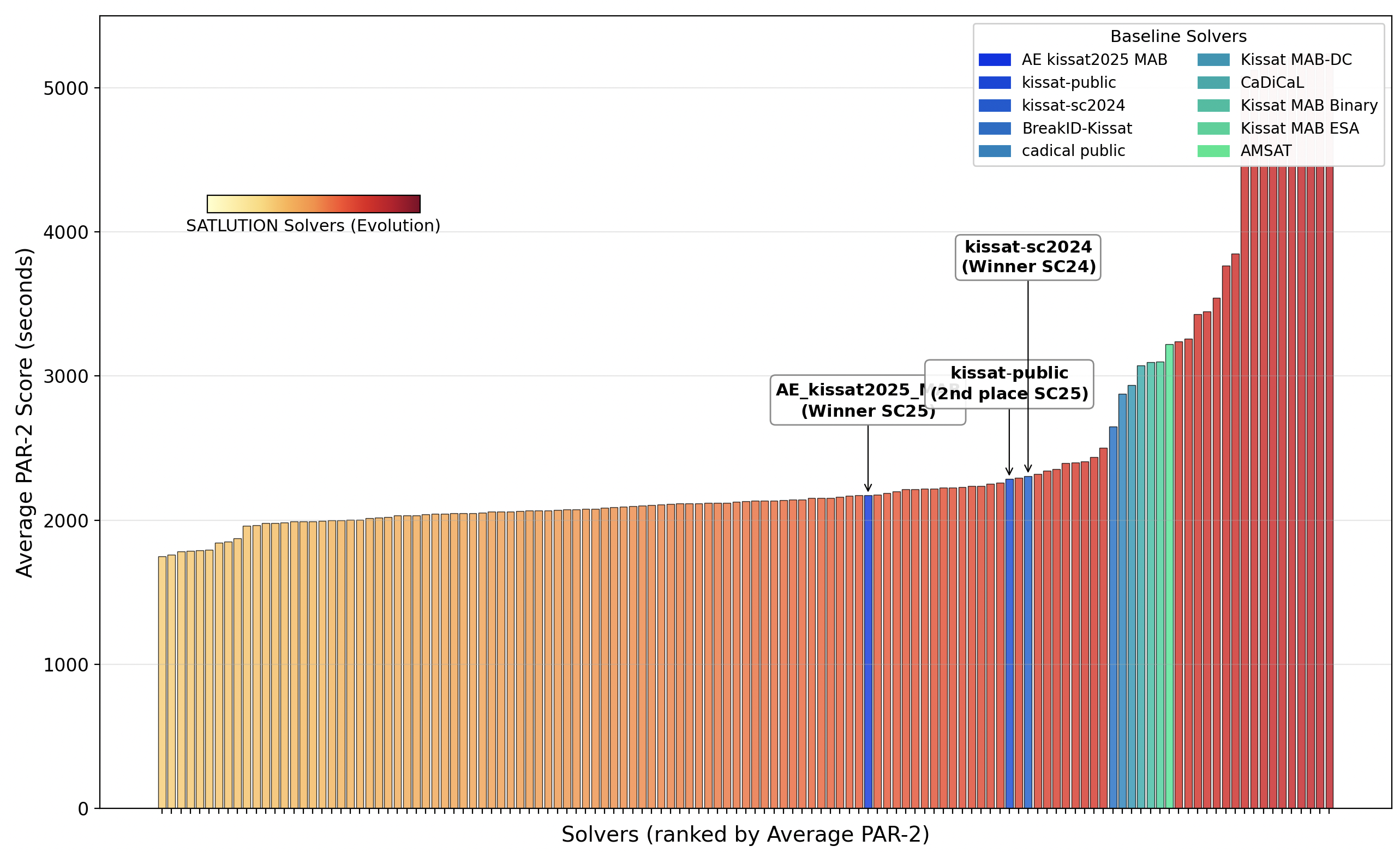
Figure 7: SATLUTION achieves the lowest PAR-2 score on the 2024 benchmark, surpassing both the 2024 and 2025 winners.
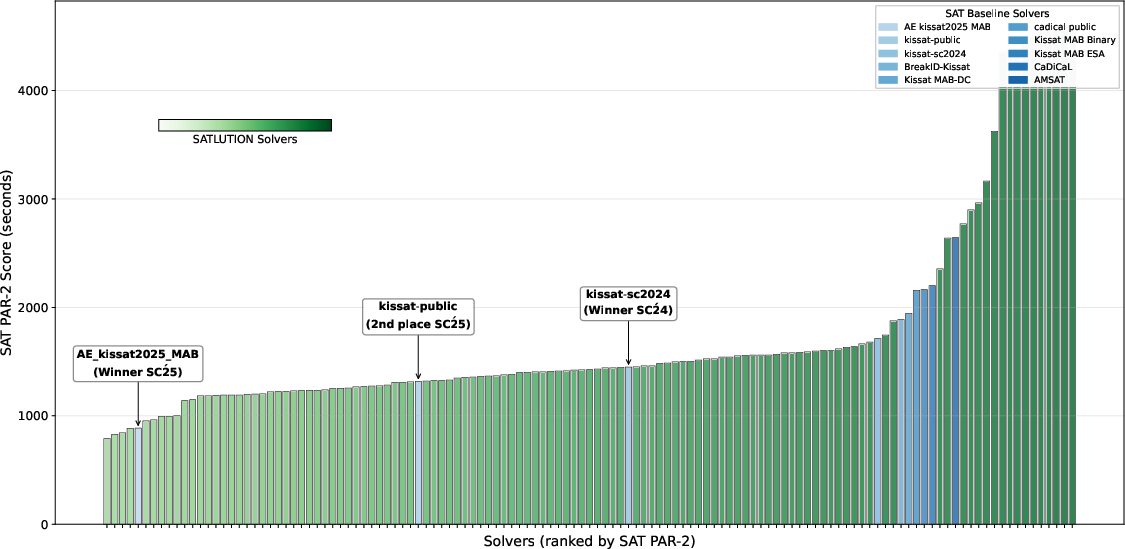
Figure 8: SATLUTION shows clear improvement in solving satisfiable instances from the 2024 benchmark.
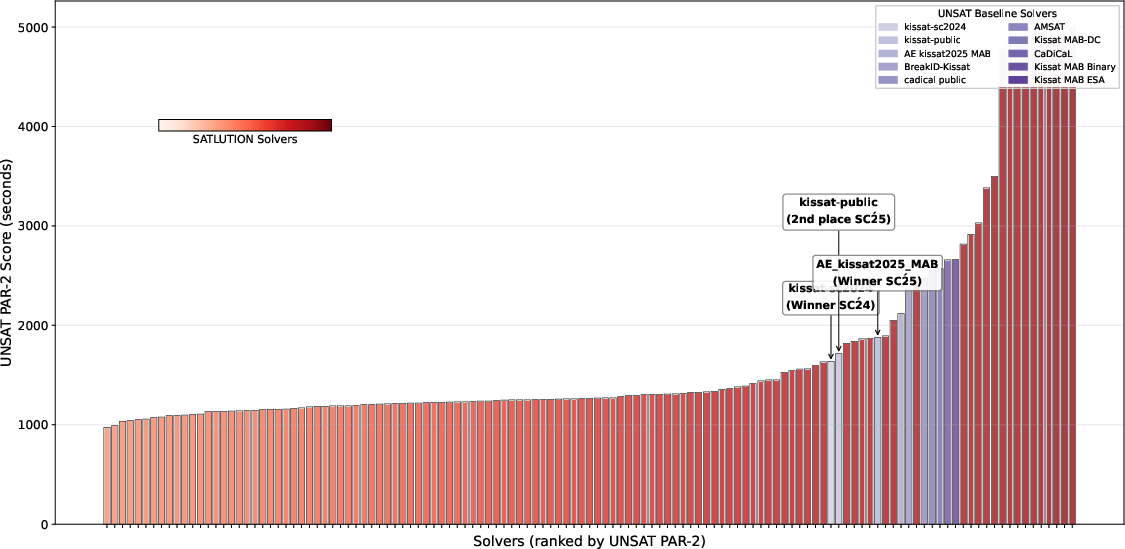
Figure 9: SATLUTION demonstrates lower average time to prove unsatisfiability than baseline solvers on the 2024 benchmark.
Evolution Trajectory and Optimization Dynamics
The evolutionary trajectory of SATLUTION reveals rapid initial progress, followed by diminishing returns as the agent tackles more subtle optimizations. The process is monotonic and stable, with no catastrophic regressions once correctness safeguards are in place.
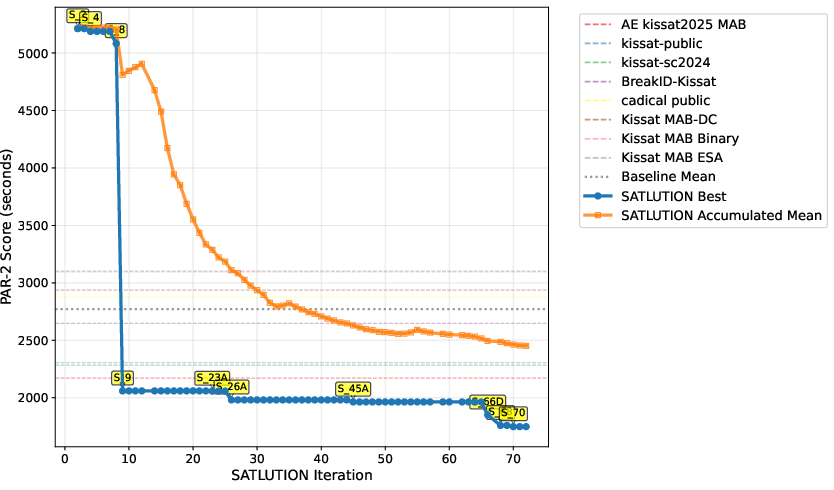
Figure 10: Evolution curve of SATLUTION's PAR-2 performance over successive iterations, showing steady improvement and surpassing all baselines.
The agent's optimization is driven by a composite feedback signal, including PAR-2 scores, solved-instance distributions, and memory usage. Reward design is critical: early cycles focused on total solved instances, favoring UNSAT performance, while later cycles incorporated PAR-2 and finer-grained metrics, shifting emphasis toward medium-to-hard SAT instances where improvements most impact aggregate scores.
Rule System and Verification
A central innovation of SATLUTION is its rule system, which combines static initialization rules (encoding domain knowledge and correctness constraints) with dynamic, self-evolving rules that adapt to observed failures and successes. The rulebase enforces strict guarantees: no instance-specific optimizations, mandatory DRAT proof generation, and comprehensive documentation. Rule compliance is checked automatically, and new failure patterns are codified as forbidden rules in subsequent cycles.
The two-stage verification pipeline is indispensable for safe evolution, catching both shallow and deep errors before performance evaluation. This design prevents reward hacking and ensures that only sound, competition-grade solvers are propagated.
Learned Techniques and Solver Innovations
SATLUTION's evolution yielded a suite of solver-design insights and techniques, many of which extend or refine traditional human-engineered heuristics:
- Multi-UIP Clause Learning: Adaptive selection among multiple unique implication points, improving learned clause quality.
- Bandit-Tuned Heuristics: Lightweight bandit controllers for UIP depth, vivification effort, and multi-domain coordination, enabling dynamic adaptation to instance characteristics.
- Vivification Sensitivity: Aggressive vivification benefits UNSAT proofs but can hinder SAT search; adaptive scheduling mitigates trade-offs.
- Reward Design: Transition from variable coverage proxies to conflict- and propagation-aware signals, with ADAM-like updates for robustness.
- Compressed Watch Architecture: Memory-efficient watch list representations, improving scalability on large formulas.
- BreakID Symmetry Integration: Static symmetry-breaking predicates to exploit CNF structure, enabling more efficient search on symmetric instances.
These innovations were integrated into later solver generations, with cumulative code modifications exceeding 10,000 lines compared to initial baselines.
Resource Requirements and Cost Analysis
SATLUTION's evolution required substantial computational resources: approximately 90,000 CPU hours on a distributed cluster and 1,938.4 USD in token usage for agentic coding. The total cost, including compute and agent tokens, was less than 20,000 USD, significantly lower than the implicit cost of human expert labor for comparable solver development.
Limitations and Future Directions
While SATLUTION demonstrates robust autonomous evolution, fully automated operation remains challenging. The agents lack deep domain-specific reasoning, necessitating targeted human intervention for conceptual guidance. The verifier, manually engineered prior to evolution, is critical for correctness; future work should focus on enabling agents to autonomously construct and adapt verification pipelines, particularly for mission-critical domains such as electronic design automation (EDA).
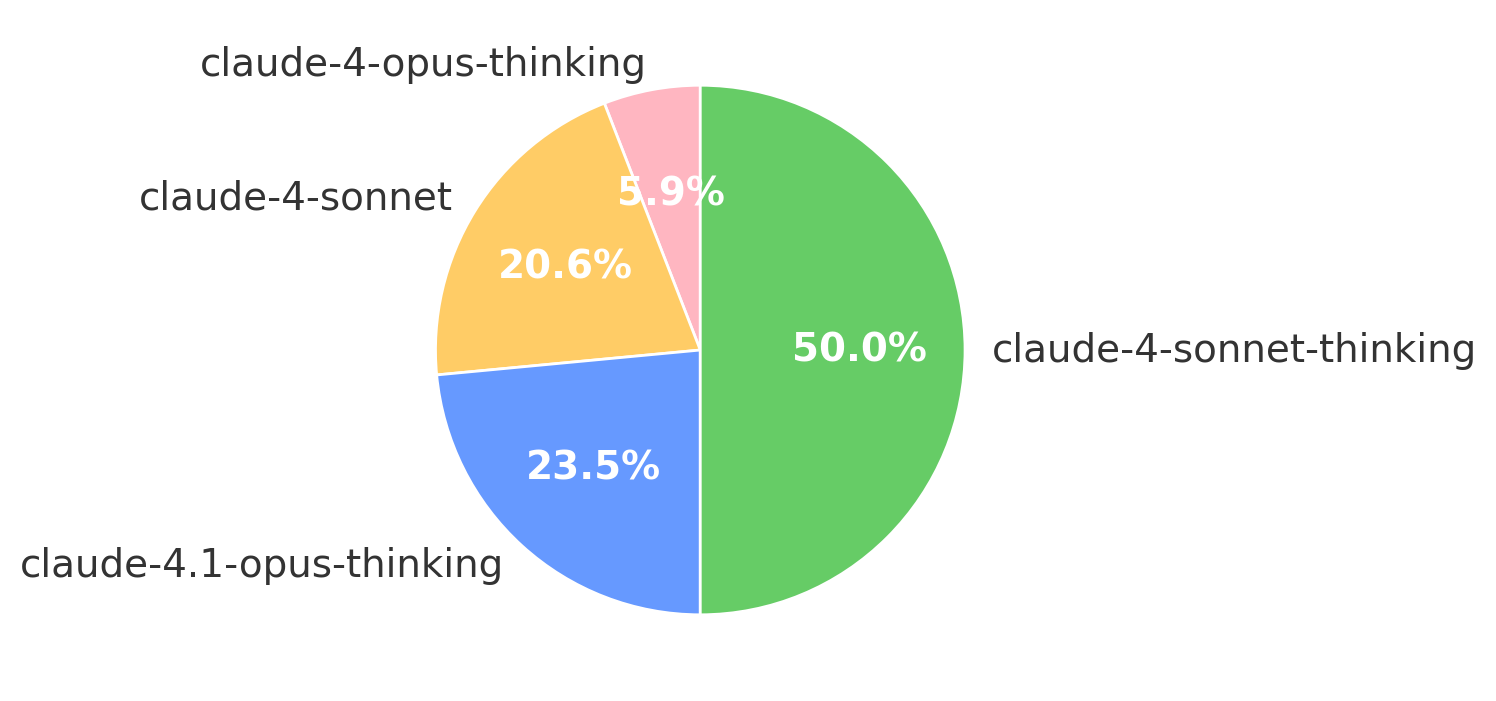
Figure 11: Distribution of model usage in the SATLUTION evolution process, highlighting the division of labor among Claude models.
Conclusion
SATLUTION establishes a new paradigm for autonomous, repository-scale code evolution in NP-complete problem solving. By orchestrating LLM agents under a rule-governed, feedback-driven framework, SATLUTION evolves SAT solvers that decisively outperform state-of-the-art human-designed solutions on competition benchmarks. The system's architecture, verification pipeline, and learned techniques provide a blueprint for future agentic frameworks in algorithmic discovery and scientific programming. Key challenges remain in scaling domain reasoning and verifier construction, but the demonstrated generalization and efficiency gains suggest broad applicability to other combinatorial optimization domains and automated scientific software development.