KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Abstract: Making deep learning recommendation model (DLRM) training and inference fast and efficient is important. However, this presents three key system challenges - model architecture diversity, kernel primitive diversity, and hardware generation and architecture heterogeneity. This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architectures. KernelEvolve does so by operating at multiple programming abstractions, from Triton and CuTe DSL to low-level hardware agnostic languages, spanning the full hardware-software optimization stack. The kernel optimization process is described as graph-based search with selection policy, universal operator, fitness function, and termination rule, dynamically adapts to runtime execution context through retrieval-augmented prompt synthesis. We designed, implemented, and deployed KernelEvolve to optimize a wide variety of production recommendation models across generations of NVIDIA and AMD GPUs, as well as Meta's AI accelerators. We validate KernelEvolve on the publicly-available KernelBench suite, achieving 100% pass rate on all 250 problems across three difficulty levels, and 160 PyTorch ATen operators across three heterogeneous hardware platforms, demonstrating 100% correctness. KernelEvolve reduces development time from weeks to hours and achieves substantial performance improvements over PyTorch baselines across diverse production use cases and for heterogeneous AI systems at-scale. Beyond performance efficiency improvements, KernelEvolve significantly mitigates the programmability barrier for new AI hardware by enabling automated kernel generation for in-house developed AI hardware.

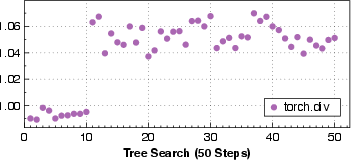
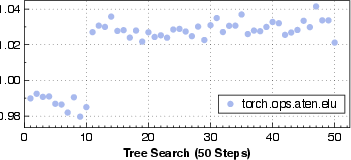
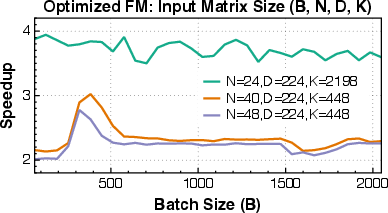
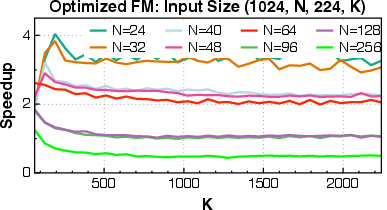
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper describes a system (called “black” in the paper, and referred to as KernelEvolve in the title) that uses AI to automatically write and improve tiny, high‑speed computer programs called “kernels.” These kernels are the building blocks that make machine learning models run fast on different kinds of computer chips (like NVIDIA and AMD GPUs, and Meta’s own MTIA chips). The goal is to speed up training and prediction for recommendation systems (the models that help decide which ads or posts you see), while making it much easier to support new hardware.
Think of a kernel like a very short recipe that tells the computer exactly how to mix and move data. KernelEvolve is like a smart cooking assistant that can read a recipe idea, test it on different stoves and ovens, tweak it many times, and finally serve the fastest, most reliable version—without a human chef having to hand‑craft every step for every type of stove.
What questions did the researchers ask?
They focused on a few simple but important questions:
- How can we make recommendation models run much faster across many different types of chips?
- Can AI automatically write and improve the low‑level “kernel” code, instead of human experts spending weeks per kernel?
- How do we handle the huge variety of model types and operations (not just matrix math), and the differences between hardware from NVIDIA, AMD, and Meta’s MTIA?
- Can this system be accurate and safe enough for real products, not just lab demos?
How did they do it? (Methods explained simply)
Here are the main ideas, in everyday language:
- Kernels and accelerators:
- A kernel is a small, super‑optimized program that does one specific task (like turning a list of IDs into usable numbers, or doing a math operation on tensors).
- Accelerators (like GPUs and custom chips) are powerful “engines” that can run these kernels very quickly, but each engine has different controls and quirks. What works best on one may not work best on another.
- Multiple “languages” and tools:
- The system can write kernels in several programming tools that are good for accelerators, especially a language called Triton (which is portable across NVIDIA, AMD, and MTIA). It can also use more specialized tools when needed.
- Think of Triton as a friendly cookbook that lets you write recipes that work on many ovens. Sometimes, the assistant switches to more advanced cookbooks for special oven features.
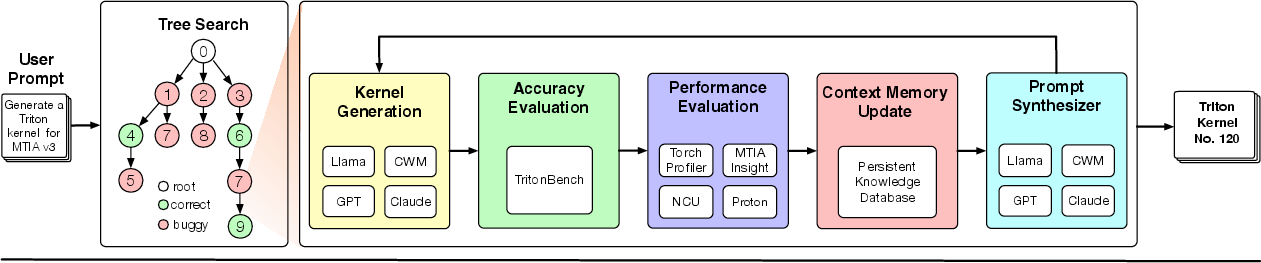
- AI agent that searches for the best version:
- The system treats kernel creation like exploring a branching path in a video game. It tries a version, tests it, learns from the results, then tries another. This is called a “tree search.”
- Selection policy: It picks the most promising next attempts based on past scores (like choosing the best path to explore first).
- Universal operator: Instead of having separate “fix bugs” and “make faster” modes, it uses one flexible AI step that adapts its behavior based on what’s going wrong or where the time is spent. This makes it smarter and less rigid.
- Fitness function: Each kernel gets a score based on how much faster it is than a solid baseline (like PyTorch), but only if it’s correct. If it fails tests, it gets a score of zero.
- Termination rule: It stops when it hits time or step limits, or when the kernel is good enough.
- Retrieval‑augmented prompts (using a knowledge base):
- The AI doesn’t try to remember everything. Instead, it looks up exactly what it needs (like a cook checking a cookbook or a note about the oven’s limits).
- This knowledge base includes hardware rules (what a chip can do), past optimization tips, and code examples organized like a library. The AI uses this to write better prompts and code.
- Careful testing and profiling:
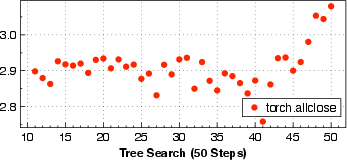
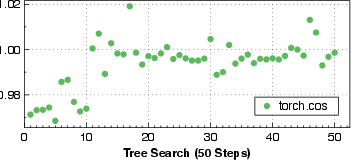
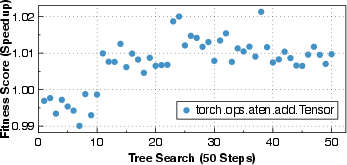
- Every generated kernel is checked for correctness against trusted reference code.
- The system measures performance at different levels (overall system time, kernel execution details, and even instruction‑level behavior) to find bottlenecks like slow memory access or too many synchronizations.
- It saves all versions and their test results so it can learn over time and avoid repeating mistakes.
Main findings and why they matter
Here are the key results the authors report:
- Big speedups across real workloads:
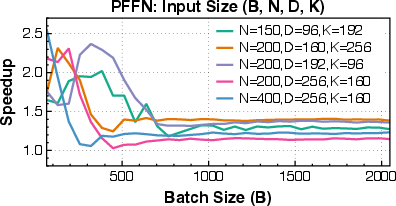
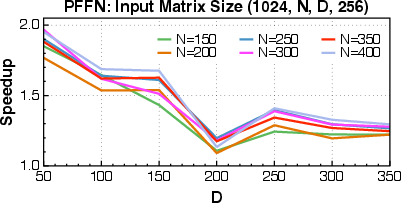
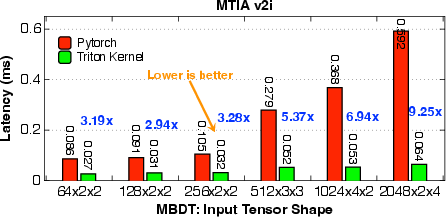
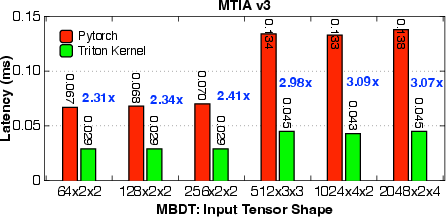
- The system achieved 1.25× to 17× speedups compared to standard PyTorch baselines on a wide range of tasks: attention in LLMs, convolutions, ranking model operations, and crucial data preprocessing steps.
- Strong correctness and coverage:
- 100% pass rate on 250 KernelBench problems across difficulty levels.
- 100% correctness for 160 PyTorch operators tested across three hardware platforms (480 operator–platform combinations total).
- Much faster development:
- Kernel creation time dropped from weeks to hours, letting teams support many more models and chips without a huge manual effort.
- Better deployment architecture:
- By generating kernels for “preprocessing” operations (like hashing IDs or trimming lists), models can run fully on accelerators instead of splitting work between different servers. This avoids extra network delays (often 10–20 ms per request), which really matters when you need sub‑second responses.
- Works across heterogeneous hardware:
- The system supports NVIDIA and AMD GPUs and Meta’s MTIA chips, even when the AI hasn’t seen those chips before, thanks to the knowledge base of hardware constraints.
Why this matters: Meta runs trillions of ad‑ranking inferences every day. Tiny kernel improvements can save millions of dollars in power and hardware costs, and also improve how fast users see results. Removing delays and making models run on one machine instead of many improves reliability too.
Implications and potential impact
- For companies: Faster, automated kernel optimization means new models can launch sooner on new chips. This reduces cost and makes it easier to keep up with rapidly changing hardware.
- For engineers and researchers: It shows that AI agents can handle real, messy production problems—not just simple benchmarks—by combining search, testing, profiling, and a well‑organized knowledge base.
- For users: Faster recommendation systems can mean a snappier experience when browsing and seeing personalized content or ads.
- For the broader ecosystem: Smarter, energy‑efficient computing can reduce data center power use. Supporting more kinds of hardware encourages healthy competition and innovation in AI accelerators.
In short, KernelEvolve/black is like a skilled, tireless coding assistant that writes and perfects the low‑level programs needed to run AI models fast on many kinds of chips, turning a complex, weeks‑long expert task into an automated, hours‑long process—without sacrificing correctness or reliability.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future research could address:
- Evaluation baselines and fairness:
- Lack of direct comparisons against expert hand-tuned CUDA/CuTe kernels, vendor libraries (e.g., cuDNN, cuBLASLt, rocBLAS/MIOpen), and compiler systems (TVM, AITemplate, TensorRT, TorchInductor baseline variants) on identical workloads, driver versions, and flags.
- No ablation quantifying how much the universal operator, retrieval augmentation, MCTS vs greedy vs evolutionary search, and MPP profiling each contribute to final performance.
- Speedup claims appear relative mostly to “PyTorch compiled” baselines; it is unclear whether the baselines are state-of-the-art for each operator/platform or representative of production-optimized alternatives.
- Correctness guarantees and validation scope:
- Definition of “100% correctness” is unspecified: numerical tolerances, stochastic operators, mixed precision modes, and cross-platform numerical drift are not characterized.
- No evidence of adversarial, property-based, or metamorphic testing for corner cases (e.g., empty/jagged inputs, extreme sequence lengths, overflow/underflow, NaN propagation).
- Absence of long-run and distributional validation (e.g., correctness stability across evolving input distributions and model versions).
- Dynamic shapes, jagged tensors, and runtime variability:
- Limited details on handling dynamic batching, variable-length sequences, and jagged tensors at compile and runtime (e.g., caching strategies, shape guards, autotune policy under shape churn).
- Unclear compile-time and autotuning overhead impacts on P95–P99 tail latency, especially in cold-start scenarios.
- End-to-end impact and production SLOs:
- Operator-level speedups are reported, but end-to-end improvements (P50/P95/P99 latency, throughput under load, SLO adherence, TCO/energy reductions) are not systematically quantified across representative services.
- No sensitivity analysis that isolates the effect of kernel speedups on full pipeline latency when other bottlenecks (networking, data loading, memory bandwidth) dominate.
- Coverage and prioritization of preprocessing operators:
- The breadth of coverage across the 200+ preprocessing operators is not enumerated; criteria for prioritizing which operators to generate/optimize first are not specified.
- Handling of complex control-flow-heavy preprocessing (e.g., feature-specific branches, set/n-gram operations with data-dependent behavior) is not detailed.
- Portability and extensibility beyond NVIDIA/AMD/MTIA:
- No evaluation or roadmap for Intel GPUs, Gaudi/HPU, TPUs, FPGAs, or CPU-only acceleration paths.
- Unknown how the system bootstraps for a brand-new architecture lacking mature Triton backends or when DSL support is incomplete.
- DSL and backend fragmentation:
- It is unclear how code migrates or co-optimizes across Triton, Triton-TLX, CuTe, and emerging DSLs; policy for choosing the best abstraction per hardware/operator is unspecified.
- No methodology to automatically translate or cross-check kernels across DSLs for functional and performance equivalence.
- Knowledge base construction and maintenance:
- Procedures for creating, validating, and versioning hardware constraints and optimization patterns (especially for proprietary architectures) are not specified.
- No strategy to detect and resolve conflicting guidance, stale content after driver/firmware/compiler updates, or automated ingestion from vendor docs and microbenchmarks.
- Learning and policy improvement:
- The selection policy appears heuristic (greedy/MCTS/evolutionary) with no reported learning-to-search or RL fine-tuning to improve over time.
- Lack of meta-learning to predict promising transformations or cost models that proactively prune unproductive search branches.
- Profiling-to-action causality:
- Although MPP unifies profiling sources, the paper does not describe causal attribution from multi-level metrics to specific code transformations or an automated bottleneck-to-fix mapping.
- No cross-platform cost models that map hardware counters to performance predictions to guide search efficiently.
- Compute cost, carbon footprint, and orchestration:
- Absence of quantitative reporting on search time, GPU-hours, and energy consumption per kernel optimization; no budgeting or scheduling framework for multi-kernel portfolios.
- No discussion of multi-tenant scheduling, preemption, and quota enforcement when running search on shared clusters.
- Reliability, safety, and security:
- No formal safety checks for race conditions, incorrect synchronization (e.g., mbarriers), or out-of-bounds accesses beyond unit tests.
- Security risks of using external LLMs with proprietary hardware specs or code are not addressed (data governance, redaction, on-prem inference, auditability).
- Determinism and reproducibility:
- The paper does not discuss deterministic builds, reproducible search outcomes across LLM backends and seeds, or variance bands for performance metrics.
- Lack of reproducible pipelines (pinning compilers/drivers/firmware) and artifacts to ensure results persist across environment changes.
- Numerical stability and mixed precision:
- No analysis of stability under fp16/bf16/fp8/int8 quantization, accumulation strategies, and rounding modes, particularly for normalization and attention-like kernels.
- Missing evaluation of error amplification under long sequences or deep operator fusions.
- Memory footprint and fragmentation:
- Effects of tile sizes, shared memory utilization, and register pressure on peak memory and fragmentation are not reported; guidance for OOM avoidance is absent.
- No quantification of scratchpad usage vs. occupancy trade-offs across architectures.
- Fusion and graph-level optimization:
- The system’s strategy for multi-op fusion (correctness, schedule legality, register pressure control) is not defined, nor its interplay with framework-level fusers (e.g., Inductor/NVFuser).
- Absence of criteria to decide when fusion harms locality or precludes reuse of vendor-tuned primitives.
- Online deployment mechanics:
- Cold-start mitigation (JIT warmup, caching policies), rollback/canary protocols, and runtime guards for auto-generated kernels are not described.
- Missing policies for automatic fallback to safe kernels on performance regressions, correctness alerts, or driver regressions.
- Tail-focused optimization:
- No techniques described for P99-aware search (penalizing JIT overheads, synchronization spikes, and launch storms) or for robust scheduling under bursty traffic.
- Handling extremely large embeddings and memory-bound ops:
- Strategies for prefetching, pipelining, NUMA/HBM placement, and cross-device sharding are not detailed for >100 GB embedding tables and irregular access patterns.
- Lack of methods to mitigate cache/bandwidth contention when preprocessing and model compute co-reside on the accelerator.
- Integration with CI/CD and developer workflows:
- Unclear how generated kernels are code-reviewed, signed, tested in CI, and maintained over time; maintainability and readability of agent-generated kernels are not evaluated.
- No developer tooling for explaining/visualizing agent decisions and code transformations to aid human oversight.
- Vendor/compiler brittleness:
- Resilience to Triton/compiler/driver bugs is not discussed; no automated triage to detect and route around backend regressions or undefined behavior.
- Multi-objective optimization:
- The fitness function focuses on speedup; other objectives (energy, memory footprint, compile time, numerical robustness, determinism) are not jointly optimized or reported.
- No framework for per-service objective tuning (e.g., throughput vs latency targets) or hardware-aware Pareto optimization.
- Workload representativeness and disclosure:
- Production workloads are referenced but not sufficiently described for external reproducibility; it is unclear how representative the selected cases are of the broader model fleet.
- Algorithm selection and termination:
- No empirical guidance on when to use greedy vs MCTS vs evolutionary search, or adaptive switching; stopping criteria and plateau detection are unspecified and unvalidated.
- Naming and clarity:
- The paper title (KernelEvolve) and system name (black) are inconsistent, creating ambiguity about the artifact identity and lineage for future replication and citation.
- Roadmap for new architectures:
- Procedures to onboard entirely new accelerators (initial probing, microbenchmarking, constraint extraction, and knowledge base seeding) are not provided.
- Legal and compliance aspects:
- Licensing terms, openness of the system/benchmarks, and protocols for using third-party LLMs with proprietary code/hardware data are not addressed.
Glossary
- agentic: In AI systems, referring to autonomous, tool-using agents that plan and act to achieve goals (e.g., for code generation/optimization). "an agentic kernel coding framework"
- AMDGCN/HSACO: AMD GPU instruction set (AMDGCN) and code object binary format (HSACO) used for compiled kernels. "AMD (AMDGCN/HSACO)"
- ATen: PyTorch’s foundational tensor and operator library (C++ API) used to implement and dispatch ops. "PyTorch ATen operators"
- autoregressive decoding: Sequential token generation process where each output token is conditioned on previously generated tokens. "autoregressive decoding"
- BoxCox: A statistical power transform used for variance stabilization and normalization of continuous features. "BoxCox"
- CUBIN: NVIDIA CUDA binary format containing compiled device code for GPUs. "PTX/CUBIN"
- CUDA: NVIDIA’s GPU programming model and runtime, exposing a thread-block execution model and memory hierarchy. "CUDA's thread-block model"
- CuTe DSL: NVIDIA’s domain-specific language for tensor layouts and transformations (layout algebra), targeting modern GPU architectures. "CuTe DSL"
- DeepGEMM: A specialized library for high-performance dense matrix multiplication beyond standard BLAS. "DeepGEMM"
- DLRM: Deep Learning Recommendation Model architecture combining embeddings, MLPs, and interaction layers for recommendation tasks. "deep learning recommendation model (DLRM) training and inference"
- FBGEMM: Facebook/Meta’s high-performance library of quantized and dense linear algebra kernels for inference/training. "FBGEMM"
- GEMM: General Matrix-Matrix Multiplication, the core dense linear algebra primitive widely optimized in HPC/ML. "dense matrix multiplication (GEMM) operations"
- Infinity Cache: AMD’s large on-die cache acting as an L3-equivalent to improve effective memory bandwidth. "Infinity Cache"
- Jagged attention: Attention mechanisms operating on variable-length (ragged/jagged) sequences typical in recommender histories. "jagged attention mechanisms"
- Jagged tensor: Tensors with variable-length rows (ragged structure), used for sparse lists and sequence features. "jagged tensor operations"
- KernelBench: A benchmark suite assessing LLM/agent capabilities for GPU kernel generation across difficulty levels. "KernelBench"
- LLM: LLM; foundation models used here for code synthesis and optimization guidance. "LLM training corpora"
- MCTS: Monte Carlo Tree Search; a search algorithm balancing exploration and exploitation via random rollouts and statistics. "Monte Carlo Tree Search (MCTS)"
- mbarriers: Asynchronous memory barrier primitives on NVIDIA Hopper enabling fine-grained pipeline synchronization. "mbarriers"
- MLIR: Multi-Level Intermediate Representation, a compiler infrastructure for building modular IR dialects and transformations. "MLIR"
- MPP (Multi-Pass Profiler): Meta’s federated profiling framework that unifies instrumentation across compiler, runtime, and hardware layers. "MPP (Multi-Pass Profiler)"
- MTIA: Meta Training and Inference Accelerator, Meta’s custom AI accelerator for training/inference. "Meta Training and Inference Accelerator (MTIA)"
- NCU: NVIDIA Nsight Compute, a low-level GPU kernel profiler for metrics like occupancy and memory throughput. "NCU"
- NVBit: NVIDIA Binary Instrumentation Tool for dynamic analysis of GPU binaries. "NVBit"
- operator fusion: Combining multiple operations into a single kernel to reduce memory traffic and launch overhead. "operator fusion"
- PTX: NVIDIA’s virtual GPU ISA (Parallel Thread Execution) used as an intermediate target before device binaries. "PTX/CUBIN"
- retrieval-augmented prompt synthesis: Dynamically enriching LLM prompts with retrieved context (specs, logs, prior runs) to guide code generation. "retrieval-augmented prompt synthesis"
- RISC-V: Open instruction set architecture; here, the target ISA for MTIA binaries in Triton’s toolchain. "RISC-V"
- ROCm/HIP: AMD’s GPU compute stack; ROCm platform with HIP CUDA-like API for portability to AMD GPUs. "ROCm/HIP"
- RMSNorm: Root Mean Square Layer Normalization variant used in transformers and optimized kernels. "RMSNorm 2D backward"
- Tensor Memory Accelerator (TMA): NVIDIA Hopper hardware engine for asynchronous bulk tensor transfers between memory spaces. "Tensor Memory Accelerator (TMA)"
- TileLang/TLX/Gluon: Emerging DSLs/abstractions for GPU/accelerator kernel programming beyond CUDA/Triton. "TileLang/TLX/Gluon"
- Torch Profiler: PyTorch’s performance profiling tool capturing CPU/GPU activity and operator timelines. "Torch Profiler"
- Total Cost of Ownership (TCO): Comprehensive infra cost metric (capex/opex) impacted by kernel efficiency. "Total Cost of Ownership (TCO)"
- Triton: A high-level, tile-oriented GPU kernel DSL/compiler with multi-target backends (NVIDIA, AMD, MTIA). "Triton multi-target compilation architecture."
- Triton Proton: An intra-kernel tracer/profiler for Triton exposing instruction-level behavior. "Triton Proton"
- Triton-MLIR: Triton’s MLIR-based intermediate representation/dialect used in progressive lowering. "Triton-MLIR"
- Triton-TLX: A Triton extension targeting low-level, hardware-specific tuning while retaining portability. "Triton-TLX"
- TritonBench: An evaluation harness that validates correctness and speedups of generated Triton kernels. "TritonBench"
- Twine: Meta’s internal serving/runtime platform used to host LLM backends. "Twine"
- UCT: Upper Confidence bounds applied to Trees; the bandit-based selection rule used within MCTS. "upper confidence bounds for trees (UCT)"
- universal operator: A single, context-adaptive transformation operator for generation, debugging, and optimization guided by retrieval. "Universal Operator"
- warp-group: NVIDIA Hopper’s 128-thread execution grouping to support WGMMA and advanced pipelines. "warp-group"
- WGMMA: Warp-Group Matrix Multiply Accumulate; Hopper tensor-core instruction class for group-wide matrix ops. "WGMMA tensor operations"
Practical Applications
Immediate Applications
The findings and system described in the paper enable the following deployable applications across industry, academia, policy, and daily life. Each item includes sector tags, potential tools/products, and key assumptions or dependencies.
- Monolithic accelerator-side preprocessing for recommendation/inference pipelines — co-locate data preprocessing and model computation on GPUs/MTIA to eliminate CPU tiers and network hops (10–20 ms savings shown), improving P99 latency and reliability
- Sectors: advertising, social media, e-commerce, content ranking
- Tools/products/workflows: “Preprocessing Operator Pack” of Triton kernels (hashing, bucketization, top-k, jagged ops), model-serving blueprints for unified accelerator tiers
- Assumptions/dependencies: Triton backend availability on target accelerators; adequate GPU/accelerator memory bandwidth; operator correctness tests; alignment with existing feature pipelines
- Automated kernel coverage expansion for heterogeneous accelerators — generate missing ATen and custom ops for NVIDIA, AMD, MTIA to unblock model deployment on new hardware
- Sectors: cloud/infra, software, silicon vendors, ML platforms
- Tools/products/workflows: “KernelEvolve Service” (agentic codegen + search), retrieval-augmented knowledge base of hardware constraints, production-grade unit/integration test harnesses
- Assumptions/dependencies: access to platform compilers/runtimes (CUDA/ROCm/Triton-MLIR/MTIA toolchains), correctness oracles, CI integration with rollback gates
- LLM and transformer inference acceleration — use agent-generated Triton kernels for attention (SDPA), MLP, conv1d/2d to lower inference cost and latency (reported 1.25–6.5× speedups)
- Sectors: GenAI, conversational AI, search, media generation
- Tools/products/workflows: optimized kernels packaged as PyTorch/Triton wheels, inference service templates, autotuning configs per hardware SKU and shape range
- Assumptions/dependencies: stable Triton backends across vendors; production profiling to choose variants per shape/batch; numerical parity acceptance criteria
- Kernel developer copilot for Triton/CuTe/TLX — boost productivity from weeks to hours using agentic synthesis, deep search (MCTS/evolutionary), and retrieval-based prompts
- Sectors: software/DevEx, silicon enablement, HPC
- Tools/products/workflows: IDE extensions, code-review bots for kernels, “universal operator” prompt packs, lint/CI bots tied to fitness and correctness
- Assumptions/dependencies: secure LLM access (internal or hosted), knowledge base curation, governance for auto-generated code changes
- Cross-stack performance diagnosis with MPP (Multi-Pass Profiler) — unify MLIR, Triton Proton, NCU/NVBit, and system timelines to pinpoint bottlenecks
- Sectors: performance engineering, SRE/production ops
- Tools/products/workflows: “Profiling Workbench” dashboards, standardized traces, automated experiment runners that surface optimization hints to the agent
- Assumptions/dependencies: profiler support per platform; low-overhead tracing in production-like settings; trace storage/PII controls
- Accelerator onboarding toolkit for new chips — rapidly attain baseline kernel coverage on proprietary or new architectures even if absent from LLM training corpora
- Sectors: semiconductor, hyperscale/cloud, OEMs
- Tools/products/workflows: vendor-specific constraint packs, sample kernels, ABI/ISA adapters, validation harnesses against PyTorch references
- Assumptions/dependencies: vendor documentation or collaboration for memory hierarchy and ISA details; Triton or equivalent DSL support; NDAs as needed
- CI/CD “KernelOps” pipeline — continuous search, regression testing, and promotion of best-performing kernels; checkpointing and rollbacks for safe deployment
- Sectors: platform engineering, MLOps
- Tools/products/workflows: fitness dashboards, correctness gates, artifact lineage (search graph), canary deployments with perf SLOs
- Assumptions/dependencies: robust test datasets; performance SLOs defined per model/operator; build farm capacity for search and profiling
- Infrastructure TCO and energy reduction — leverage 1.2–17× speedups to reduce accelerator fleet size or defer capex, lower power draw in multi-megawatt data centers
- Sectors: cloud/infra, sustainability, finance (FP&A)
- Tools/products/workflows: “Energy–SLO Planner” mapping kernel gains to fleet right-sizing and carbon savings; CFO-facing ROI reports
- Assumptions/dependencies: accurate baseline measurements; steady-state traffic profiles; power modeling per accelerator generation
- CUDA-to-DSL modernization at scale — accelerate migration to Triton/CuTe/TLX for maintainability and cross-vendor portability, reducing legacy CUDA burden
- Sectors: software, platform modernization
- Tools/products/workflows: code translation recipes, auto-porting agents with regression tests, deprecation playbooks
- Assumptions/dependencies: coverage of performance-critical kernels; parity performance on newer DSLs; developer training/adoption
- Academic adoption for systems and ML courses — hands-on labs on agentic kernel search, profiling, and heterogeneity using KernelBench and open ATen ops
- Sectors: academia, education
- Tools/products/workflows: course modules, lab containers, reproducible benchmarks, grading rubrics around correctness/perf trade-offs
- Assumptions/dependencies: access to compatible GPUs; open or academic-licensed tools; simplified knowledge base without proprietary content
- Internal procurement and platform policy improvements — evaluate accelerators using realistic operator coverage and monolithic deployment ability (not just GEMM peak)
- Sectors: enterprise IT policy, vendor management
- Tools/products/workflows: RFP checklists including preprocessing operator support, cross-platform Triton readiness, profiling evidence
- Assumptions/dependencies: cooperation from vendors; standardized evaluation harnesses; alignment with product latency SLOs
- Tangible user experience gains — faster, more consistent feed ranking and ad delivery from reduced P99 latencies and fewer cross-tier failures
- Sectors: daily life, consumer apps
- Tools/products/workflows: rollout playbooks tying kernel upgrades to UX KPIs (time-to-first-content, scroll smoothness)
- Assumptions/dependencies: guardrails to avoid regressions; canarying and A/B infra; alignment with privacy and safety policies
Long-Term Applications
These opportunities require further research, scaling, standardization, or ecosystem development before broad deployment.
- End-to-end agentic compiler and graph-level optimization — automatic operator fusion, scheduling, and per-request autotuning across heterogeneous backends
- Sectors: software compilers, ML platforms
- Tools/products/workflows: graph-level IR optimizers that call the kernel agent, online autotuners with dynamic shape handling
- Assumptions/dependencies: stable multi-IR pipelines (e.g., MLIR integration), reliable online profiling/feedback loops, robust correctness guards
- Cross-paradigm portability beyond GPUs (TPUs/NPUs/FPGAs/edge) — extend agentic synthesis and knowledge bases to additional DSLs/ISAs and on-device accelerators
- Sectors: mobile/edge, robotics, IoT, automotive
- Tools/products/workflows: new backends (e.g., VPU/Hexagon, FPGA HLS), hardware adapters, edge-friendly profilers
- Assumptions/dependencies: DSL maturity on target devices; access to toolchains and counters; memory and power constraints on-device
- Online self-optimizing kernels using live traffic feedback — RL or Bayesian optimization in production to adapt to drift in shapes, mixes, and hardware health
- Sectors: cloud/infra, high-availability services
- Tools/products/workflows: safe exploration frameworks, shadow traffic evaluation, constrained RL (latency/error budgets)
- Assumptions/dependencies: strict safety rails; rapid rollback; unbiased telemetry; privacy-preserving metrics
- Shared, standardized hardware constraint knowledge bases — cross-vendor schema and APIs for memory hierarchies, synchronization primitives, and performance hints
- Sectors: semiconductor, standards bodies, open-source
- Tools/products/workflows: schema specs, vendor-contributed packs, conformance suites
- Assumptions/dependencies: IP concerns and NDAs; governance models; incentives for vendor participation
- Energy-aware schedulers and carbon-aware inference — integrate kernel-level efficiency signals into cluster schedulers to minimize energy per inference
- Sectors: sustainability, cloud orchestration
- Tools/products/workflows: scheduler plugins, energy KPIs per operator, carbon-intensity-aware routing
- Assumptions/dependencies: trustworthy power metering; workload predictability; organizational carbon goals
- Verifiable and certifiable kernel generation for regulated domains — formal verification or proof-carrying code for numerical stability and memory safety
- Sectors: healthcare, finance, automotive, aerospace
- Tools/products/workflows: SMT/verification backends for Triton/CuTe kernels, certification artifacts for auditors
- Assumptions/dependencies: formal semantics of DSLs; tractable proof generation; regulatory acceptance pathways
- Secure kernel marketplace and provenance — signed, sandboxed, and reproducibly benchmarked kernels with lineage from search graphs and profiling evidence
- Sectors: software marketplaces, enterprise IT
- Tools/products/workflows: signing and SBOMs, reproducibility harnesses, trust scores, vulnerability scanning
- Assumptions/dependencies: standardized packaging; reproducible environments; legal frameworks for liability
- Automated model-to-hardware co-design — agent explores architectural choices (memory sizes, interconnects) together with kernel synthesis to guide future chip designs
- Sectors: semiconductor R&D, EDA
- Tools/products/workflows: co-simulation loops, design-space exploration linking kernel fitness to hardware parameters
- Assumptions/dependencies: high-fidelity simulators; early-access ISAs; long design cycles
- Education and workforce upskilling at scale — standardized curricula for agentic systems, heterogeneous programming, and performance engineering
- Sectors: academia, professional training
- Tools/products/workflows: MOOCs, lab kits with multi-backend Triton, capstone projects on kernel search
- Assumptions/dependencies: accessible hardware/time-sharing; open educational licenses; instructor training
- Democratized acceleration for prosumers — consumer-grade tools that auto-optimize LLM/recs models on gaming GPUs for creators and small businesses
- Sectors: daily life, SMB software
- Tools/products/workflows: one-click optimization CLI/GUI, curated kernel packs for common models (e.g., SDPA, MLPs), local profiling
- Assumptions/dependencies: simplified UX; safe defaults; driver/toolchain compatibility across consumer GPUs
- Policy frameworks for automated code generation in production — guidance on safety, monitoring, and auditability of AI-written kernels in critical services
- Sectors: policy/regulation, enterprise governance
- Tools/products/workflows: compliance checklists (correctness gates, rollback plans, telemetry), third-party audits
- Assumptions/dependencies: consensus on best practices; alignment with existing software safety standards; incident reporting norms
Collections
Sign up for free to add this paper to one or more collections.