DexDrummer: In-Hand, Contact-Rich, and Long-Horizon Dexterous Robot Drumming
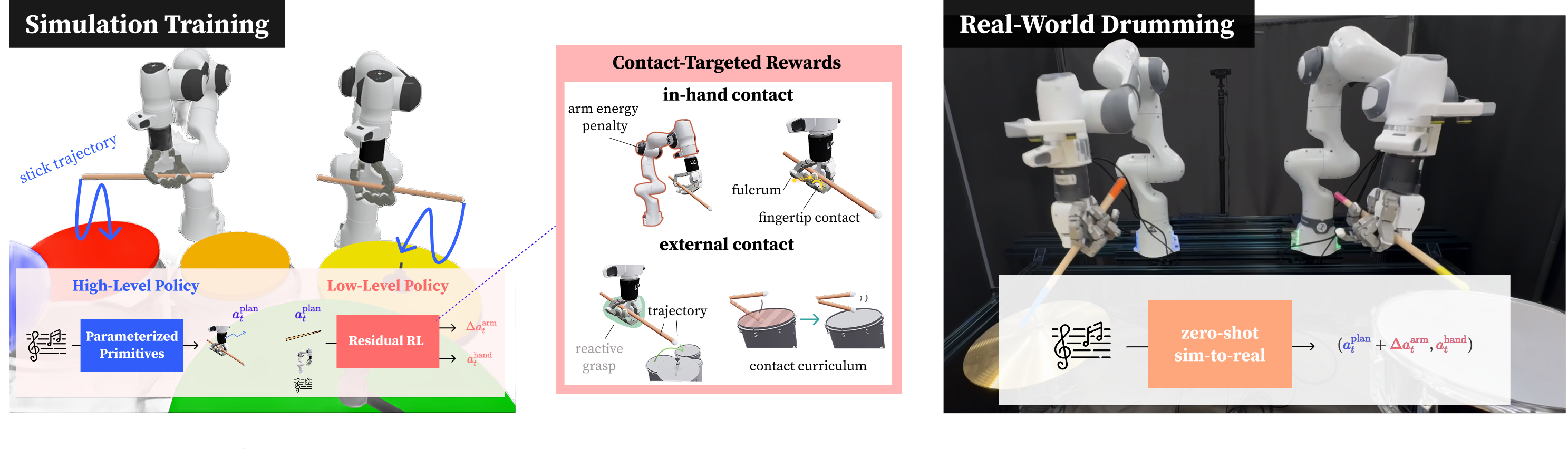
Abstract: Performing in-hand, contact-rich, and long-horizon dexterous manipulation remains an unsolved challenge in robotics. Prior hand dexterity works have considered each of these three challenges in isolation, yet do not combine these skills into a single, complex task. To further test the capabilities of dexterity, we propose drumming as a testbed for dexterous manipulation. Drumming naturally integrates all three challenges: it involves in-hand control for stabilizing and adjusting the drumstick with the fingers, contact-rich interaction through repeated striking of the drum surface, and long-horizon coordination when switching between drums and sustaining rhythmic play. We present DexDrummer, a hierarchical object-centric bimanual drumming policy trained in simulation with sim-to-real transfer. The framework reduces the exploration difficulty of pure reinforcement learning by combining trajectory planning with residual RL corrections for fast transitions between drums. A dexterous manipulation policy handles contact-rich dynamics, guided by rewards that explicitly model both finger-stick and stick-drum interactions. In simulation, we show our policy can play two styles of music: multi-drum, bimanual songs and challenging, technical exercises that require increased dexterity. Across simulated bimanual tasks, our dexterous, reactive policy outperforms a fixed grasp policy by 1.87x across easy songs and 1.22x across hard songs F1 scores. In real-world tasks, we show song performance across a multi-drum setup. DexDrummer is able to play our training song and its extended version with an F1 score of 1.0.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “DexDrummer: In‑Hand, Contact‑Rich, and Long‑Horizon Dexterous Robot Drumming”
Overview
This paper is about teaching a robot to play the drums in a natural, drummer‑like way. That means the robot must hold and adjust a drumstick with its fingers, hit drums repeatedly without dropping the stick, and keep a steady rhythm over longer songs. The authors use drumming as a “testbed” (a tough, real‑world challenge) to push forward robot hand skills, also called dexterous manipulation.
What questions does the paper ask?
- Can a robot learn to control a drumstick with its fingers while hitting drums again and again, without losing the stick?
- How do we make the robot’s fingers (not just the arms) do most of the quick, precise work needed for fast drumming?
- What kind of training helps a robot handle hard contacts (like stick‑on‑drum impacts) safely and reliably for a long time?
- Will skills learned in a computer simulation work on a real robot?
How did the researchers teach the robot?
Why drumming?
Drumming naturally combines three hard things:
- In‑hand control: the robot must hold and adjust the stick with fingers.
- Contact‑rich actions: the stick hits the drum surface over and over.
- Long‑horizon coordination: the robot must keep playing correctly across many beats and switch between drums smoothly.
The robot’s two‑level “brain”
Think of the robot having a coach and a performer:
- High‑level (the coach): Turns the song (music notes) into smooth paths for where the drumstick should go. It uses motion planning to move the robot’s arms along those paths. Then, a small “fix‑it” learner, called residual reinforcement learning, adds tiny corrections to handle fast moves and reduce mistakes. In simple terms, the planner draws the route, and the residual learner nudges the robot to stay exactly on track.
- Low‑level (the performer): Controls the hand and fingers to keep a good grip, angle the stick, and handle bouncy hits. It’s trained with rewards that specifically target useful contacts:
- In‑hand contact rewards: Encourage the fingertips to touch the stick, promote a “fulcrum” pinch between thumb and index finger (like human drummers do), and penalize unnecessary arm effort so the fingers do the fine work.
- External contact rewards: Guide the stick tip to follow a hit‑shaped path and introduce a “contact curriculum.” The curriculum is like practice: first learn the motion in the air (no drum contact), then add drum hits later. This prevents the stick from just resting on the drum and blocking learning.
Training and testing
- The team trains everything in simulation first (this is faster and safer), then transfers to the real world (called “sim‑to‑real”). They use random variations during training so the robot becomes robust to real‑world messiness.
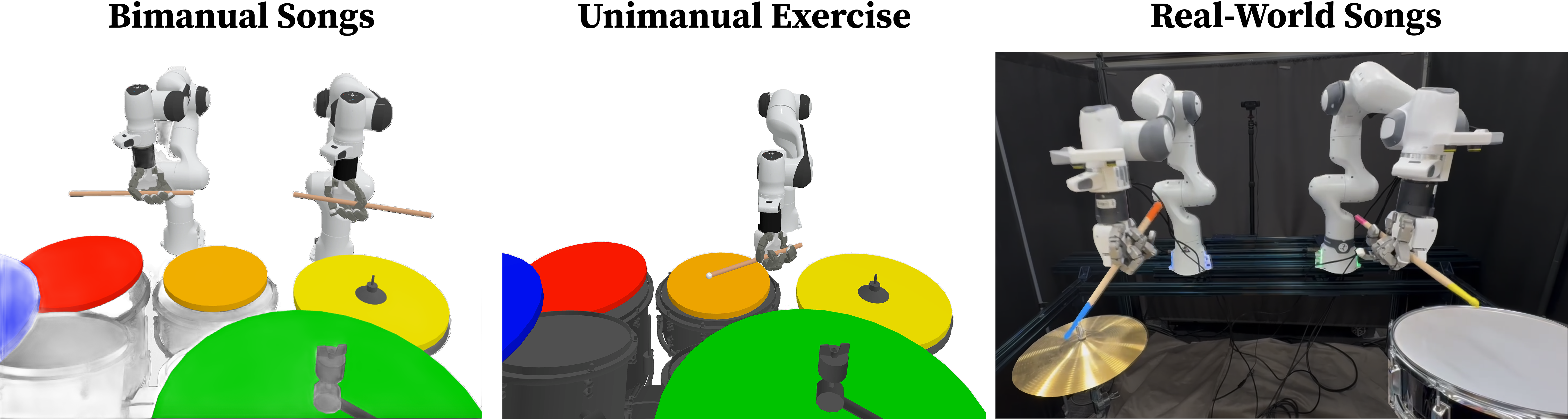
- They test two kinds of tasks:
- Bimanual songs in simulation with multiple drums.
- A single‑drum, high‑speed exercise to test finger dexterity, in both simulation and the real world.
- To score performance, they use:
- F1 score: a single number that measures how many hits were correct and on time (high is better).
- Stick‑hold ratio: how long the robot keeps holding the stick.
- Trajectory error: how closely the stick follows the planned path.
- Energy use: lower is safer and more efficient.
What did they find, and why is it important?
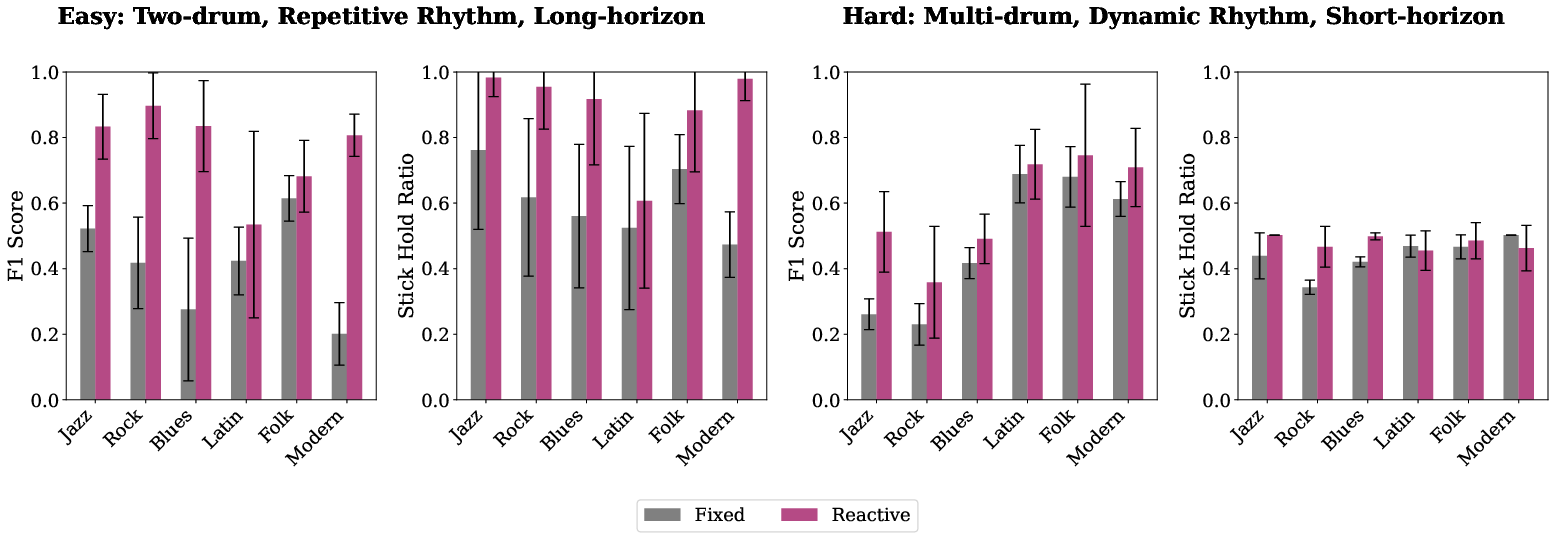
- Reactive grasp (fingers keep adjusting) beats fixed grasp (fingers frozen):
- In simulated songs, the dexterous, finger‑reactive policy outperformed a fixed‑grip approach by about 1.87× on easier long songs and 1.22× on harder songs (measured by F1 score).
- It also held onto the stick longer. This shows that real drumming needs active finger control, not just arm swings.
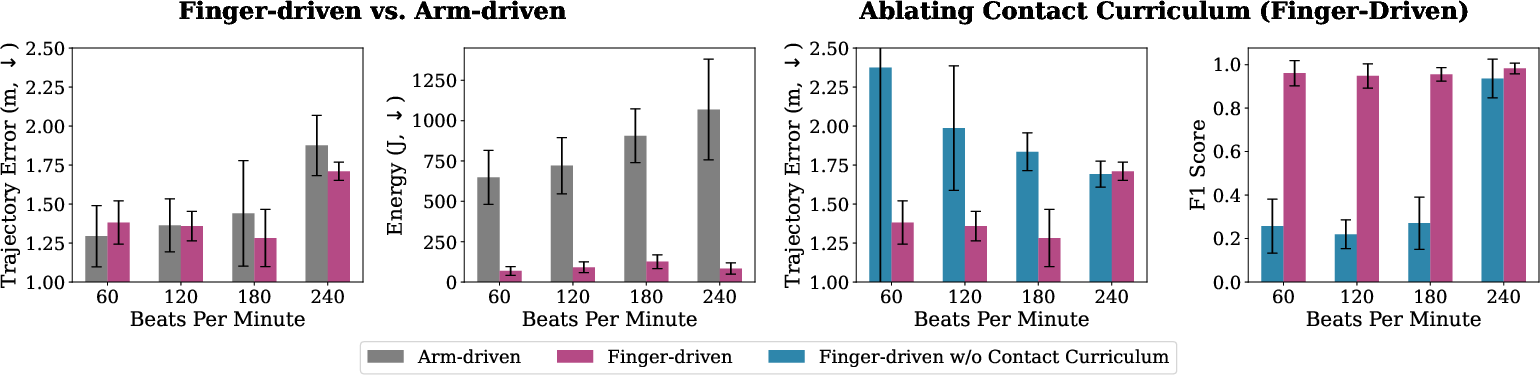
- Fingers matter more as the tempo gets faster:
- On a fast single‑drum exercise, finger‑driven control had lower trajectory error and used much less energy than arm‑driven control, especially at higher beats per minute (BPM). In other words, as the music speeds up, the fingers become essential.
- The contact curriculum is key:
- Without first practicing hits “in the air,” the policy often failed to learn clean finger motions; the stick would rest on the drum and block exploration. With the curriculum, it learned smoother, more natural strikes.
- Planning plus small learned corrections works best:
- Motion planning gives a good overall route.
- The residual learner makes tiny on‑the‑fly fixes. Together they achieved perfect F1 = 1.0 in some tests.
- Removing residual learning dropped F1 to about 0.8, and training only with reinforcement learning (no planner) dropped it further (around 0.5).
- Real‑world success and generalization:
- On a real robot with a drum pad and a cymbal, the learned policy could play its training song and a longer version perfectly (F1 = 1.0).
- It also handled new hit sequences (not seen during training) better than simply replaying simulated actions.
- The robot adapted its grip: looser for cymbal hits (lighter contact), firmer for drum pad hits (stronger contact). That’s a human‑like adjustment.
What does this mean going forward?
- A strong testbed: Drumming is an excellent, realistic challenge that pushes robots to master in‑hand control, tough impacts, and long sequences.
- A useful recipe: Combining planning (for big moves) with small learned corrections and contact‑aware rewards (for fine, safe finger control) can help robots handle other real tasks like assembly and cooking tools.
- Limits today: The robot isn’t yet at human speed or full song length, and real‑world setups were limited (e.g., two drums in the final demo). Closing the sim‑to‑real gap further, speeding up, and scaling to full drum kits are promising next steps.
In short, DexDrummer shows that with the right training and structure, robots can learn drummer‑like finger skills, hit reliably over time, and adapt to changing contacts—important steps toward truly dexterous robots in everyday tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain, missing, or unexplored in the paper, organized by theme to help guide future research.
Task scope and musical capability
- Long-horizon performance: Real-world evaluations are limited to short sequences (~20 seconds); robustness over full songs (3–5 minutes) with sustained rhythmic stability and low drift is untested.
- Speed limits: The system cannot play multi-drum songs at human-level tempos; it is unclear what algorithmic or hardware changes (e.g., control frequency, compliance, rebound exploitation) are necessary to reach higher BPM.
- Dynamic expressivity: The framework targets hit timing (F1) but does not explicitly control or measure hit intensity/velocity, dynamics (accents/ghost notes), or microtiming (timing jitter), all critical for musical quality.
- Drumming techniques: Techniques such as rolls, flams, rebound control, Moeller strokes, rimshots, cross-sticking, and stick rebound exploitation are not modeled or evaluated.
- Bimanual coordination on hardware: Real-world results are restricted to a two-instrument setup; full bimanual coordination across a multi-drum kit, including crossovers and stick collision avoidance, is not demonstrated.
- Real-time music interaction: The policy follows pre-planned MIDI timing; synchronization to live audio, tempo tracking, and adaptation to human musicians are not explored.
Control, sensing, and embodiment
- Low control frequency: Policy inference at 20 Hz may limit high-speed dexterous control; the impact of higher control rates or multi-rate control (e.g., higher-rate finger control) is unstudied.
- Position vs. torque/impedance control: The system uses PID position control; the benefits of torque/impedance control for safer, more compliant, and more precise contact-rich drumming are not investigated.
- Lack of tactile feedback: No tactile sensing or slip/force estimation is used; the ability to detect and respond to incipient slip, contact force profiles, or rebound behavior remains unexplored.
- Vision robustness: Stick-tip tracking relies on color segmentation and a single camera; robustness to occlusions, lighting changes, motion blur, and multi-view fusion is not evaluated.
- Grip adaptability: The policy enforces a fulcrum near the center; adaptability to different grips (matched/traditional), shifts of fulcrum for different tempos/techniques, and regrasping strategies are not studied.
- Safety and contact forces: Peak forces, equipment wear, and safety risks (e.g., “clunky and dangerous” arm-driven motions) are not quantified or constrained by explicit limits.
Reward design and evaluation metrics
- Reward sensitivity: The paper does not analyze sensitivity to reward weights (e.g., the small arm energy penalty) or how these choices affect learned strategies across tasks and tempos.
- Limited task objectives: Rewards focus on contact occurrence and trajectory following; there is no objective for hit force/velocity profiles, stick rebound dynamics, timing jitter minimization, or sound quality metrics.
- Curriculum effects: While a contact curriculum is proposed, its schedule, generality across tasks, and robustness to different contact models are not characterized.
- Evaluation gaps: Metrics omit audio-based evaluation (e.g., onset accuracy from microphone signals), velocity accuracy, groove consistency, or perceived musicality—F1 alone may mask timing and dynamic errors.
Planning, residual RL, and hierarchy
- Planner–residual interaction: The magnitude limits, stability, and failure modes of residual corrections are not analyzed, especially under large planning errors or delays.
- Primitive expressivity: Parameterized, sinusoid-inspired stick trajectories might limit expressivity; how to represent more complex through-the-arc stick motions for advanced techniques is open.
- Generalization to novel transitions: Residual RL helps with fast transitions, but performance under drastically different drum layouts, large spatial errors, or unforeseen kinematic constraints is not reported.
- Alternative hierarchies: The benefits of other architectures (e.g., task-space MPC with learned residuals, learned keyframe schedulers, or skill libraries) are not compared.
Simulation fidelity and sim-to-real transfer
- Contact modeling fidelity: Drumhead and cymbal dynamics (compliance, damping, vibration) are simplified; how fidelity gaps affect learned behaviors and transfer is not quantified.
- Domain randomization details: The extent and types of randomization (contact parameters, friction, mass, drum compliance, stick properties) are not fully specified or ablated.
- Material and embodiment variability: Generalization to different sticks (length, mass, grip, surface), drumheads, cymbal types, and mounting configurations is untested.
- Sensor latency and calibration: Effects of perception latency, camera–robot extrinsic errors, and online calibration drift on timing and accuracy are not studied.
Learning procedure, generalization, and baselines
- Sample efficiency and compute: Training time, data requirements, and computational budget are not reported; scalability to larger kits and longer songs is uncertain.
- Baseline breadth: Comparisons are limited (e.g., fixed vs. reactive grasp); missing baselines include imitation learning from human demonstrations, model-based control/MPC, and other hierarchical RL frameworks.
- Generalization to unseen songs: Real-world tests include limited unseen transitions between two instruments; generalization to new genres, rhythms, and multi-drum patterns is not systematically evaluated.
- Multi-task/continual learning: How a single policy can accumulate skills across many songs, kits, and techniques without catastrophic forgetting remains open.
Physical constraints and hardware considerations
- Hand/arm hardware limits: The interplay between hand dexterity limits (20-DOF DG-5F) and required drumming performance at high BPM is not quantified; hardware upgrades or actuation specs are not discussed.
- Wear and durability: Longevity under repeated impacts (stick wear, hand mechanism strain, drum surface wear) and maintenance needs are unaddressed.
Reproducibility and clarity
- Ambiguity on real-world setup: There is inconsistency regarding unimanual vs. bimanual real-world evaluations; exact hardware configurations and task definitions should be clarified.
- Implementation details: Precise planner parameters, residual action ranges, curriculum schedules, and the full set of domain randomization parameters are not provided, limiting replicability.
Practical Applications
Immediate Applications
The following applications can be deployed with modest adaptation of the methods, code, and workflows described in the paper. They leverage the hierarchical planning + residual RL design, contact-targeted reward shaping, contact curriculum, and the sim-to-real pipeline demonstrated on real robot hardware.
- Timed motion-primitive scheduler for robots (software, robotics)
- Convert symbolic, time-stamped event streams (e.g., MIDI, PLC signals, conveyor triggers) into parameterized end-effector trajectories, then execute them with motion planning plus residual RL for precise timing.
- Example uses: synchronized station tasks, pick-and-place aligned to conveyors, stamping/pressing sequences with strict timing.
- Assumptions/Dependencies: Existing motion planner (e.g., ROS/MoveIt), real-time control at ~100 Hz, low-latency state estimation, modest offline training time in sim.
- Residual RL “correction layer” for high-speed transitions (software, robotics)
- Drop-in residual policy that sits atop kinematic planners to improve tracking during fast, dynamic moves, reducing missed contacts and overshoot.
- Example uses: rapid tool repositioning across workcells, fast camera-based alignment tasks, dynamic button/trigger pressing.
- Assumptions/Dependencies: Simulator to pretrain residuals; domain randomization or calibration for sim-to-real; safety interlocks for higher accelerations.
- Contact curriculum and reward templates for contact-rich RL (academia, software)
- Reuse the paper’s staged contact curriculum and contact-targeted reward shaping (in-hand vs. external contact) to stabilize training on impact-heavy tasks.
- Example uses: tapping/pressing QA routines, impact-insertion tasks, polishing with intermittent contacts.
- Assumptions/Dependencies: Physics simulator with contact toggling; task-specific reward tuning.
- Object-centric dexterity benchmark (DexDrummer testbed) (academia, robotics R&D)
- Use drumming as a standardized, reproducible benchmark for in-hand manipulation under repeated impact and long horizons, with clear metrics (F1 timing, hold ratio, trajectory error, energy).
- Example uses: evaluating new robotic hands, comparing RL vs. imitation pipelines, stress-testing sim-to-real techniques.
- Assumptions/Dependencies: ManiSkill or equivalent sim; basic percussive setup (sim or real); access to the released codebase.
- Factory quality inspection via rhythmical tapping (manufacturing)
- Adapt the stick/hammer tool to perform consistent, timed taps for acoustic/structural resonance testing of parts (a known NDT approach).
- Assumptions/Dependencies: Tooling to measure vibration/acoustics; calibrated force envelope; safety guarding.
- Energy-aware control policies for safer, cheaper operation (robotics, energy)
- Apply the arm energy penalty technique to shift motion burden to fine, local manipulations when appropriate, reducing overall energy and wear.
- Example uses: repeated cycles in assembly lines where gross arm motions are costly or hazardous.
- Assumptions/Dependencies: Reward shaping access during training; monitoring tools for joint torques/velocities.
- Digital-twin–light sim-to-real workflow (software, robotics)
- Reproduce the paper’s low-cost pipeline: simple digital twin alignment, domain randomization, and monocular/RealSense color-segmentation to track tool pose for state estimation.
- Example uses: fast prototyping of contact tasks without full metrology stack; tool-tip tracking in labs.
- Assumptions/Dependencies: Calibrated camera; robust color segmentation or fiducials; modest lighting control.
- Human-robot interaction demos and edutainment (entertainment, education)
- Robotic drumming for museum installations, STEM outreach, and music technology education showing closed-loop dexterity and rhythm following.
- Assumptions/Dependencies: Safety barriers, speed limiting; simplified single-drum setups for robustness.
- Music education aids (technique demonstration) (education, music)
- Demonstrate grip adjustment (“fulcrum” control) and finger-driven strokes at different tempos for learners; compare arm-driven vs. finger-driven motions visually.
- Assumptions/Dependencies: Single-arm/hand platform with drum pad; curated lesson scripts; operator supervision.
- Rapid evaluation of robotic hand designs (robotics R&D)
- Use “hold ratio,” F1 timing, and trajectory-tracking error as objective metrics to assess slippage resistance, contact robustness, and dexterous bandwidth across hand prototypes.
- Assumptions/Dependencies: Repeatable drumming sequences; identical control stack across hands.
- Scheduling from symbolic inputs beyond music (software)
- Treat MIDI-like inputs as a general timing spec for any sequence of contacts; use the paper’s trajectory generator as a generic “symbolic-to-motion” adapter.
- Assumptions/Dependencies: Event source integration; timing accuracy; controller tuning for target hardware.
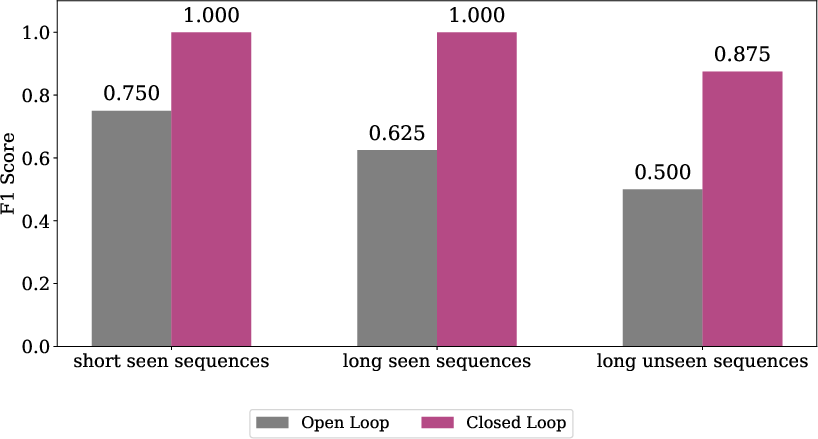
- Closed-loop over open-loop process control (robotics)
- Immediate lesson for deployment: prefer reactive, closed-loop controllers over open-loop replay for tasks with variable contact dynamics (as shown by real-world F1=1.0 vs. inferior open-loop).
- Assumptions/Dependencies: Sensing for the manipulated object/tool; robust state estimation; contingency handling.
Long-Term Applications
The following opportunities require further research, scaling, hardware advances, or broader validation to reach production-grade maturity.
- General dexterous tool-use in manufacturing (manufacturing, robotics)
- Extend finger-driven control + hierarchical planning to sanding, deburring, scraping, stapling, cable harnessing, and snap-fit assembly with in-hand regrasp during contact.
- Dependencies: Tactile sensing integration for better contact estimation; faster control loops; ruggedized multifinger hands; longer-horizon stability.
- Household and food-service robots for contact-rich tasks (consumer, food industry)
- Apply the same in-hand + external contact synergy to whisking, stirring, flipping, and scrubbing where continuous impacts and slippage are common.
- Dependencies: Food-safe hardware, spill/mess robustness, compliant control and force limits, improved sim-to-real for deformable media.
- Prosthetics and rehabilitation (healthcare)
- Adapt finger-driven, energy-efficient controllers to powered prosthetic hands or exoskeletons performing rhythmic, contact-intense tasks; use rhythmic cues for motor rehab.
- Dependencies: Human-in-the-loop learning, compact onboard compute, robust intent decoding, medical certification.
- Surgical and micro-manipulation assistants (healthcare)
- Transfer contact curriculum and object-centric policies to precise, impact-sensitive tool handling (e.g., tapping, clipping, or instrument repositioning at micro-scale).
- Dependencies: High-fidelity sensing, sub-millimeter control, strict safety and regulatory validation.
- Co-creative performance robots (entertainment, software)
- Real-time musical collaboration (responding to tempo and dynamics), multi-instrument play, and co-improvisation using learned contact models.
- Dependencies: Low-latency perception, prediction of human partners, fast online adaptation, expressive control of contact force.
- Dexterity SDK integrated with ROS/MoveIt/Isaac (software, robotics)
- Productize a “Dexterity Suite” with: symbolic-to-trajectory generator, residual RL wrappers, contact curriculum manager, and reward templates for in-hand/external contact tasks.
- Dependencies: Broad hardware driver coverage, user-friendly tuning tools, dataset/library of task templates.
- Energy- and wear-optimized factories (energy, manufacturing)
- Use energy-penalized policies at scale to lower peak loads and mechanical wear across fleets, especially for repetitive, rhythmic operations.
- Dependencies: Fleet-wide monitoring, predictive maintenance integration, ROI studies; standardized KPIs.
- Standards and certification for contact-rich dexterous robots (policy, safety)
- Establish evaluation suites using timing F1, hold ratios, and trajectory error over long horizons as acceptance tests for contact robustness and safety.
- Dependencies: Cross-industry consortia, test protocols and fixtures, insurer/regulator buy-in.
- Education platforms for RL and control (academia, education)
- Curriculum kits using the drumming testbed to teach hierarchical control, residual RL, curriculum learning, and sim-to-real practices.
- Dependencies: Affordable hardware bundles, cloud training resources, classroom content.
- Adaptive timing for human-robot synchronization (HRI, healthcare)
- Robots that align with human rhythms (e.g., gait cues or exercise timing) using the paper’s symbolic timing -> motion pipeline plus closed-loop corrections.
- Dependencies: Robust human state estimation, safety compliance, personalization algorithms.
- Multi-minute, high-speed dexterous sequences (robotics, entertainment, manufacturing)
- Scale from 20–40s to 3–5 minutes with human-level tempos through improved policies, sensing, and hardware, enabling complex production or performance tasks.
- Dependencies: Policy stability over long horizons, thermal management, error recovery and regrasp strategies.
Each application’s feasibility hinges on hardware capabilities (multi-DOF hands and reliable arms), sensing (vision/tactile for tool state), real-time control bandwidth, safe operation near people, and access to simulation for pretraining with domain randomization. As shown in this work, combining motion planning with residual RL, using contact-targeted rewards, and staging contact curricula are broadly useful patterns that can generalize well beyond drumming to contact-rich dexterous tasks.
Glossary
- Arm energy penalty: A reward-shaping term that discourages large arm motions to encourage finger-dominant control. "an arm energy penalty that promotes finger-dominant control."
- Bimanual: Involving two robotic arms/hands coordinated under a single policy. "a hierarchical object-centric bimanual drumming policy"
- Closed-loop (control): A feedback-based control scheme that adapts actions online using current state observations. "we find that our closed-loop policy consistently outperforms the open-loop policy."
- Contact curriculum: A staged training strategy that initially removes contact to simplify learning, reintroducing it later to handle impacts. "we introduce a contact curriculum that stabilizes learning of impacts."
- Contact-rich: Characterized by frequent or complex physical interactions between objects and the robot. "in-hand, contact-rich, and long-horizon dexterous manipulation"
- Digital twin: A matched simulation of the real setup (geometry and placement) used to facilitate transfer. "We create a digital twin of the real world by matching the drum, cymbal, and stick positions and sizes."
- Discount factor: The scalar γ that exponentially down-weights future rewards in reinforcement learning. "We assume an environment with observation o_t, r_t per timestep t, and discount factor γ."
- Domain randomization: Varying simulation parameters during training to improve robustness when transferring to reality. "we do not incorporate sim-to-real techniques besides domain randomization"
- End-effector: The robot’s tool-bearing endpoint (e.g., hand) whose motion executes planned trajectories. "This trajectory is then transformed into corresponding end-effector motions via relative pose offsets"
- F1 score: A harmonic-mean metric of precision and recall used here to evaluate song-playing performance. "DexDrummer is able to play our training song and its extended version with an F1 score of 1.0."
- Fulcrum reward: A reward encouraging thumb–index placement at the stick’s pivot point to stabilize manipulation. "a fulcrum reward between the thumb and index finger"
- Hierarchical policy: A multi-level control structure that separates high-level planning from low-level dexterous control. "a hierarchical, two-stage policy for drumming."
- Kinematic planning: Planning based on geometry and motion without modeling dynamics or forces. "However, purely kinematic planning can fail"
- Lookahead horizon: The future planning window length used when feeding trajectory plans to the policy. "L denotes lookahead horizon"
- ManiSkill: A GPU-parallelized robotics simulation framework used to build the drumming environments. "We create a simulated drum environment in the ManiSkill framework"
- Motion planning: Computing feasible robot movements to reach targets while respecting constraints. "the full system that combines motion planning with residual RL achieves precise and stable drumming performance"
- Motion primitives: Parameterized building blocks of movement used to generate stick trajectories from musical inputs. "parameterized motion primitives that generate task-space drumstick trajectories from musical inputs."
- Object-centric: Framing control around the manipulated object’s state/trajectory rather than the robot’s joint space. "We formulate this as an object-centric task, where the drumstick trajectory serves as the primary reference for planning."
- Open-loop (control): Executing a precomputed action sequence without using feedback from the current state. "For our open-loop setting, we directly run the policy in simulation and replay actions"
- PID joint position controller: A proportional–integral–derivative controller commanding joint positions at high frequency. "we use a PID joint position controller that runs at 100 Hz."
- Proprioception: Internal sensing of the robot’s own state (e.g., joint positions) and here also the stick’s state. "To track the stick proprioception, we paint the end of the drumstick."
- Relative pose offsets: Position/orientation differences used to convert task-space stick trajectories into arm motions. "This trajectory is then transformed into corresponding end-effector motions via relative pose offsets"
- Residual RL: Learning corrective actions on top of a nominal planner to reduce tracking errors. "A residual RL policy then learns corrective adjustments on top of this planner to compensate for tracking errors during fast transitions between drums."
- Sim-to-real transfer: Training in simulation and deploying the learned policy on real hardware. "trained in simulation with sim-to-real transfer."
- Sparse reward: A reward that provides feedback only at specific events, such as successful hits. "we add a sparse hit reward"
- Stick-hold ratio: The fraction of time the stick remains grasped during an episode, indicating in-hand stability. "the stick-hold ratio, defined as the fraction of time the stick remains held in hand across the total duration"
- Task space: The operational (Cartesian) space in which desired end-effector or object trajectories are specified. "generate the desired stick trajectory in task space."
- Trajectory guidance reward: A reward encouraging the stick to follow a desired path to achieve effective strikes. "with a trajectory guidance reward to encourage drum strikes"
- Trajectory planning: Generating time-parameterized paths for the stick/robot to follow. "combining trajectory planning with residual RL corrections"
- Zero-shot transfer: Deploying a policy to the real robot without additional fine-tuning on real data. "transfer zero-shot to the real robot"
Collections
Sign up for free to add this paper to one or more collections.