Learning Dexterous Manipulation Skills from Imperfect Simulations
Abstract: Reinforcement learning and sim-to-real transfer have made significant progress in dexterous manipulation. However, progress remains limited by the difficulty of simulating complex contact dynamics and multisensory signals, especially tactile feedback. In this work, we propose \ours, a sim-to-real framework that addresses these limitations and demonstrates its effectiveness on nut-bolt fastening and screwdriving with multi-fingered hands. The framework has three stages. First, we train reinforcement learning policies in simulation using simplified object models that lead to the emergence of correct finger gaits. We then use the learned policy as a skill primitive within a teleoperation system to collect real-world demonstrations that contain tactile and proprioceptive information. Finally, we train a behavior cloning policy that incorporates tactile sensing and show that it generalizes to nuts and screwdrivers with diverse geometries. Experiments across both tasks show high task progress ratios compared to direct sim-to-real transfer and robust performance even on unseen object shapes and under external perturbations. Videos and code are available on https://dexscrew.github.io.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robot hands to do tricky, touch-heavy tasks—like turning a nut onto a bolt and using a screwdriver—even when computer simulations of the real world aren’t perfect. The authors introduce a method called DexScrew that first learns the basic “turning motion” in a simple simulation, then uses that skill to help a human collect real-world data with touch, and finally trains a new robot policy that uses touch to work reliably on real objects.
What questions does the paper ask?
- Can a robot learn delicate hand skills (like twisting and turning) even if our simulation of physics isn’t accurate enough to model every tiny detail?
- How can we combine the strengths of simulation (fast, safe practice) and real-world data (true physics and touch) to make robots more reliable?
- Is touch sensing (tactile feedback) important for success on contact-heavy tasks like fastening nuts and driving screws?
- Will a robot trained this way work on different shapes and still handle disturbances (like bumps or slips)?
How did they do it?
Think of this like learning a sport:
- First, practice the basic move safely in a game-like simulator.
- Then, use that move to help collect examples from the real world, where you can feel what’s happening.
- Finally, learn a polished version that uses “feel” (touch) to adapt and succeed.
Here’s the three-stage approach:
- Stage 1: Learn the motion in a simplified simulation
- The robot learns a “turning” skill (a finger gait) by practicing on simplified objects—like a nut attached by a hinge—rather than trying to simulate every thread and tiny contact.
- This is “reinforcement learning,” which means the robot improves by trial and error (like a player getting better by playing many rounds).
- They also add variation (like changing friction and size) so the skill is more robust.
- Stage 2: Use that skill to collect real data with a person’s help
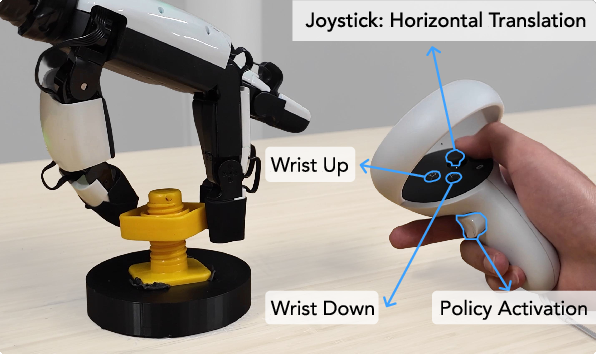
- A human uses a VR controller to move the robot arm’s wrist.
- The robot’s simulated “turning” skill controls the fingers.
- Together, they perform real tasks while recording what the robot feels with its fingertip touch sensors (tactile signals), plus joint positions.
- This makes it much easier to collect high-quality demonstrations, because the tough finger coordination is handled by the learned skill, and the human focuses on positioning.
- Stage 3: Train a touch-aware policy from the real data
- The robot learns to copy good examples from the real world (“behavior cloning”).
- This final policy uses:
- Proprioception (the robot’s sense of its own joint positions),
- Tactile sensing (touch), and
- A short history of recent observations (so it can understand motion over time).
- No camera vision is used here; it’s all about hand position and touch.
Key terms in simple language:
- Simulation: a video-game-like world where robots can practice fast and safely.
- Reinforcement learning: learning by trial and error with rewards for doing well.
- Teleoperation: a human remotely controls part of the robot.
- Behavior cloning: the robot learns by copying examples.
- Tactile sensing: feeling touch and pressure with fingertip sensors.
What did they find, and why is it important?
Main results:
- Just transferring the simulation policy directly to the real world (without touch) could spin nuts or handles, but it couldn’t finish tasks that require reacting to real contact (for example, moving the nut down along the bolt threads).
- When the final policy used touch and a short history of recent signals, it worked much better:
- It reached very high completion rates on both nut-and-bolt fastening and screwdriving.
- It was faster and more stable.
- It handled new shapes it hadn’t been trained on (like different nut shapes).
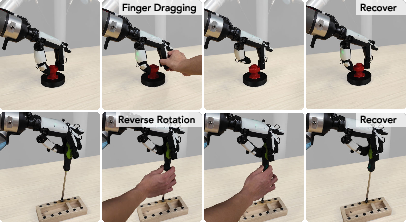
- It recovered from disturbances (like being bumped or the screwdriver briefly slipping).
- Touch was especially helpful on harder shapes and situations where contact is unstable. The short history helped the robot understand ongoing motion (for example, tracking how far it has turned and how contact is changing), which improved speed and reliability.
Why this matters:
- It shows you don’t need a perfect simulator to teach robots complex hand skills. You can learn the “core move” in a simple sim and finish the job with real-world touch data.
- It makes collecting real data easier: the robot handles finger coordination while a human just guides the wrist.
- It highlights that touch is crucial for contact-rich tasks, where tiny slips and forces matter a lot.
What’s the impact and what’s next?
Impact:
- This approach could help robots perform real, everyday hand tasks (like assembly) more reliably, even when simulations can’t capture all the tiny physical details.
- It provides a practical path: start with simple simulations, gather real touch data efficiently, and train a final touch-savvy policy that generalizes to new objects and resists disturbances.
Limitations and future steps:
- A human is still needed to help collect the real-world data. Automating that step would scale things up.
- The paper assumes the nut is already on the bolt and the screwdriver is already engaged. Extending to longer, more complex tasks will likely need cameras (vision) and possibly high-accuracy force sensors.
- Testing on more tasks would show how broadly this method applies.
In short: Learn the basic twist in a simple “game,” use it to gather real touch experiences, then train a robot that can feel and adapt. That combination—motion from sim, judgment from touch—lets robots master delicate, real-world handwork.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item highlights what remains missing, uncertain, or unexplored, with actionable specificity for future work.
- Quantify the sim-to-real gap introduced by the revolute-joint abstraction (vs. true thread mechanics), including how different simplified shapes influence learned gaits and downstream real-world performance.
- Establish a principled methodology to design or automatically learn the “minimal” simulated object abstractions that best induce transferable motion primitives for a given real task.
- Model and detect true thread engagement, cross-threading, and over-torque conditions; incorporate axial displacement and torque measurements to validate correct fastening beyond rotation count.
- Expand evaluation metrics beyond progress ratio and completion time to include physical quality metrics (e.g., torque profile, axial displacement per turn, engagement integrity, wear).
- Systematically assess sensitivity to domain randomization choices (e.g., friction, mass, PD gains) and identify which parameters most affect transfer and robustness.
- Analyze sample efficiency: how many and which kinds of demonstrations are needed for robust BC performance; provide learning curves w.r.t. dataset size, diversity, and operator variability.
- Reduce reliance on assisted teleoperation for data collection; explore autonomous data acquisition, active learning, or self-supervised strategies that leverage tactile feedback safely.
- Learn a high-level policy for when to trigger/terminate the rotation skill and when to reposition the arm, instead of relying on human activation decisions during data collection.
- Integrate vision to handle long-horizon assembly steps (finding the bolt, aligning the nut, inserting the screwdriver) and study how visuotactile fusion impacts performance and generalization.
- Investigate whether recurrent or transformer-based policies (longer temporal context) outperform the current short-history, feedforward hourglass encoder for contact-rich control.
- Exploit the spatial structure of the tactile arrays (rather than flattening) using architectures tailored to spatiotemporal tactile patterns; quantify gains and robustness to sensor noise/latency.
- Provide systematic robustness testing under controlled perturbations (force magnitudes, misalignment angles, surface lubricity), with thresholds for stability and recovery rather than qualitative demonstrations.
- Evaluate cross-hardware transfer: different robot hands (kinematics, compliance, tactile layouts) and arms; characterize portability of learned skills and required adaptation procedures.
- Compare against stronger baselines (e.g., diffusion policies with tactile, residual learning/RMA, model-predictive control, high-fidelity simulation) to isolate the contribution of the proposed pipeline.
- Assess generalization across broader task families (e.g., bottle-cap twisting, valves, doorknobs) and mechanical variations (thread pitch, diameters, tolerances, worn/damaged threads, material differences, lubrication).
- Study completion detection from tactile and proprioception (without human labeling), including criteria for “tight enough,” failure detection (slippage, cross-threading), and safe recovery policies.
- Characterize the effects of control and sensing rates (policy inference latency, tactile sampling frequency, low-level PD loop rate) on stability and success; design latency compensation mechanisms.
- Explore real-world fine-tuning (safe online RL or offline RL with tactile) to reduce residual gaps after BC, with explicit analysis of safety constraints and sample efficiency.
- Provide ablations on the action-chunking horizon and history window length (K, H) to understand trade-offs between responsiveness, prediction stability, and success rate.
- Examine the impact of demonstration curation (e.g., filtering, weighting of successful segments) on BC performance and failure modes, including operator skill differences.
- Develop standardized benchmarks and release multisensory (tactile + proprio) datasets to facilitate reproducibility and broader comparison across methods.
- Analyze long-term reliability (sensor drift, mechanical wear, repeatability over many trials), and propose maintenance/calibration routines for tactile sensing in sustained deployments.
- Incorporate wrist force–torque sensing and impedance control strategies; quantify the added value of F/T signals relative to tactile alone for alignment, engagement, and safety.
Glossary
- Abduction/adduction: Lateral movement of fingers away from or toward the hand’s midline; in robot hands, specific lateral DOFs enabling side-to-side finger motion. "Only the thumb and index provide abduction/adduction."
- Ablations: Controlled experimental variants used to isolate the effect of specific components or design choices. "We conclude with qualitative experiments that provide additional analysis and design ablations in simulation."
- Action chunking: A strategy where the policy predicts a sequence of future actions over a horizon rather than a single-step action. "We also apply an action chunking strategy~\cite{zhao2023learning,chi2025diffusion}, where the policy predicts a sequence of future actions $\hat{\bm{a}_{t:t+H}$ rather than a single-step action."
- Adam: A stochastic optimization algorithm that adapts learning rates using estimates of first and second moments. "We train the policy using Adam~\cite{kingma2014adam} for 200 epochs and normalize observations following~\cite{barreiros2025careful}."
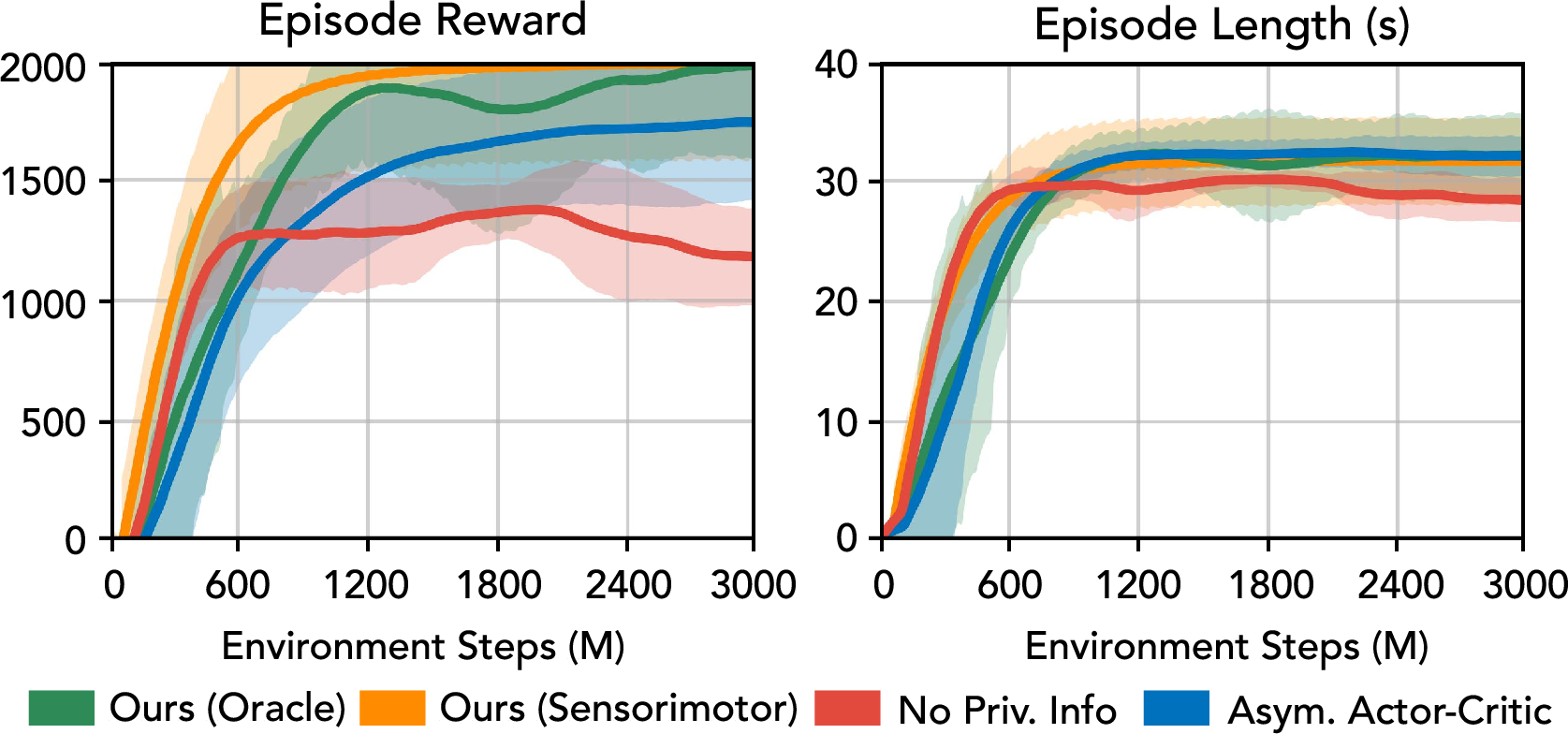
- Asymmetric actor-critic: An RL architecture where the critic has access to richer (e.g., privileged) information than the actor to improve learning. "using an asymmetric actor-critic~\cite{pinto2017asymmetric} architecture where the critic has access to full tactile information while the actor does not."
- Behavior cloning (BC): Imitation learning by supervised regression from observations to actions using expert demonstrations. "With the dataset $\mathcal{D}_{\text{Real}$ collected using the skill-based assisted teleoperation, we can train a behavior cloning (BC) policy $\pi_{\text{BC}$ using the paired multisensory observations and expert actions."
- Center of mass: The point representing the average position of mass in an object, critical for dynamics and control. "including object attributes (e.g., position, scale, mass, center of mass, friction coefficients)"
- DAgger: Dataset Aggregation; an imitation learning algorithm that iteratively collects corrective expert labels during policy rollout. "We train the policy using DAgger~\cite{ross2011reduction}: at each step, the sensorimotor policy acts in the environment, while the oracle policy provides target actions and ground-truth privileged embeddings."
- Degrees of Freedom (DoF): The number of independent joint variables or motion parameters available to a mechanism. "Our system consists of a UR5e robot arm (6 DoF) and a 12-DoF XHand."
- Dexterous manipulation: Fine, coordinated object handling using multi-fingered hands involving complex contacts and motions. "Reinforcement learning and sim-to-real transfer have made significant progress in dexterous manipulation."
- Domain randomization: Training technique that randomizes simulation parameters to improve robustness and transfer to reality. "We apply domain randomization during training to improve the robustness of the RL policy~\cite{peng2018sim}."
- Embedding: A learned vector representation of information (e.g., privileged state) used to condition a policy. "The oracle policy is trained with access to an embedding of privileged information~\cite{chen2020learning} ."
- Episode length: The number of timesteps in an RL episode, often used as a stability or performance indicator. "We compare episode reward and episode length across these training strategies."
- Finger gaits: Coordinated, periodic motion patterns of fingers that enable stable in-hand object rotation or repositioning. "First, we train reinforcement learning policies in simulation using simplified object models that lead to the emergence of correct finger gaits."
- Filtered behavior cloning: Training BC using only successful or high-quality trajectories to improve performance over the original policy. "This phenomenon, where a behavior cloning policy surpasses the policy that generated the data, is consistent with filtered behavior cloning~\cite{kumar2022should}."
- Hourglass encoder: A neural architecture that compresses and then expands features to capture multi-scale information. "The fused feature vector is then processed by an hourglass encoder~\cite{newell2016stacked}, which outputs the action predictions."
- IsaacGym: A GPU-accelerated physics simulation platform for large-scale parallel RL training. "We train our policies in IsaacGym~\cite{makoviychuk2021isaac} using 8{,}192 parallel environments."
- Kinematically constrained: Motion restricted by mechanical linkage or geometry; lack of constraint can make tasks less stable. "Compared to nut-bolt fastening, screwdriving is inherently less stable: the shaft is not kinematically constrained along the screw axis"
- Latent code: A compact, inferred representation that captures hidden or privileged state information for policy conditioning. "The sensorimotor policy receives proprioceptive states and a latent code $\hat{\bm{z}_t = \bm{\phi}(\bm{h}_t)$ inferred from a 30-timestep history."
- Multisensory: Combining multiple sensing modalities (e.g., proprioception and touch) for richer policy inputs. "we can train a behavior cloning (BC) policy $\pi_{\text{BC}$ using the paired multisensory observations and expert actions."
- Oracle policy: A teacher policy trained with privileged information unavailable at deployment, used for supervision or distillation. "We first train an oracle policy and then distill it into a sensorimotor policy."
- PD controller: Proportional–Derivative controller converting position commands into torque using proportional and derivative gains. "This command is sent to the robot and converted into torque via a low-level PD controller."
- PD gains: The proportional and derivative coefficients in a PD controller that determine control response. "we randomize the nut/handle mass, center of mass, friction coefficient, size, and PD gains, and we also add observation noise."
- Privileged information: Ground-truth or additional state available during training but not at test time, used to facilitate learning. "The oracle policy is trained with access to an embedding of privileged information~\cite{chen2020learning} ."
- Progress ratio: A task-specific metric measuring fraction of required rotations completed toward fastening or tightening. "we measure the progress ratio, defined as the number of successful rotations divided by the total number of rotations required for full fastening."
- Proprioceptive: Relating to internal sensing of joint positions, velocities, and forces within the robot. "The sensorimotor policy receives proprioceptive states and a latent code $\hat{\bm{z}_t = \bm{\phi}(\bm{h}_t)$ inferred from a 30-timestep history."
- Proximal Policy Optimization (PPO): A policy gradient RL algorithm that stabilizes training via clipped objectives. "We train the oracle policy using proximal policy optimization (PPO)~\cite{schulman2017proximal} with the reward described above."
- Residual model: A learned correction term added to a nominal model or policy to compensate for discrepancies (e.g., sim-to-real). "build a residual model from real-world interactions to compensate for the sim-to-real gap and achieve robust in-hand manipulation."
- Revolute joint: A single-axis rotational joint constraining motion to rotation about one axis. "we approximate their interaction with a revolute joint that connects two simple geometric shapes"
- Sensorimotor policy: A deployable policy that maps sensor inputs (without privileged info) to motor commands. "The sensorimotor policy operates without privileged sensing and instead conditions on a predicted embedding"
- Sim-to-real gap: The mismatch between simulated dynamics/sensing and reality that degrades transfer performance. "However, as the task becomes more dynamic, the sim-to-real gap grows~\cite{wang2024lessons}, and simulation alone becomes insufficient."
- Sim-to-real transfer: Training policies in simulation and deploying them on real robots, often with robustness techniques. "Reinforcement learning (RL) paired with sim-to-real transfer has recently delivered a number of promising results in dexterous manipulation"
- Skill primitive: A reusable, higher-level motion module invoked within a larger control or teleoperation framework. "We then use the learned policy as a skill primitive within a teleoperation system to collect real-world demonstrations"
- Stability controllers: Controllers or policies designed to maintain stable contact/behavior during manipulation. "Yin et al.~\cite{yin2025dexteritygen} use simulation-trained policies as stability controllers to enable complex manipulation skills."
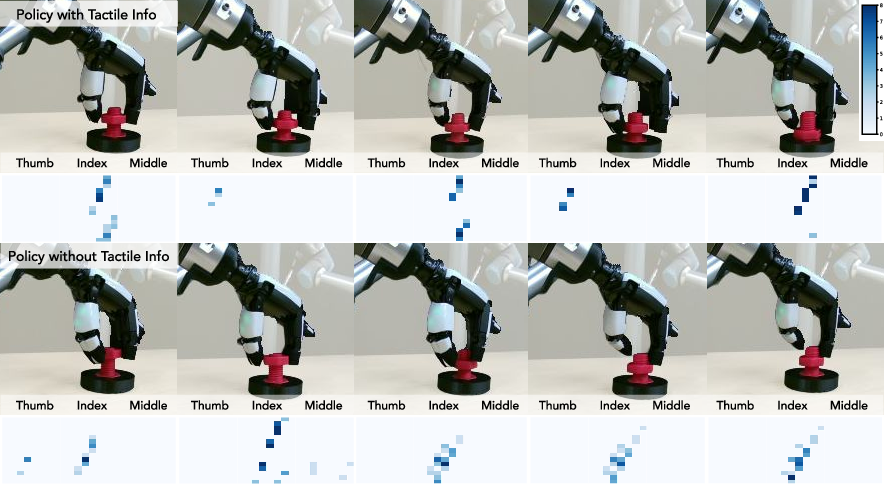
- Tactile array: A grid of touch sensors measuring forces across multiple axes at the fingertip. "Each fingertip is equipped with a pressure-based tactile array comprising 120 sensing elements, each measuring three-axis forces"
- Tactile feedback: Touch-based signals used to inform control, detect contact state, and refine manipulation. "progress remains limited by the difficulty of simulating complex contact dynamics and multisensory signals, especially tactile feedback."
- Teleoperation: Human-in-the-loop remote control of a robot, often to collect demonstrations or assist tasks. "teleoperation and imitation learning~\cite{chi2025diffusion,zhao2023learning} remove the need for simulation entirely."
- Termination conditions: Criteria that end an RL episode to avoid unrecoverable states and accelerate training. "we terminate an episode when any of the following conditions are met:"
- Trajectory optimization: Optimization method that computes motion paths satisfying dynamics and constraints to achieve tasks. "demonstrate screwdriver turning by combining learning with trajectory optimization."
- UR5e: A 6-DoF industrial robotic arm model used as the manipulator platform. "Our system consists of a UR5e robot arm (6 DoF) and a 12-DoF XHand."
- XHand: A 12-DoF robotic hand with built-in tactile sensors used for dexterous manipulation. "Our system consists of a UR5e robot arm (6 DoF) and a 12-DoF XHand."
Practical Applications
Immediate Applications
Below is a set of concrete, deployable use cases that build directly on the paper’s methods and results. Each item specifies a sector, actionable scenario, prospective tools/workflows, and key assumptions or dependencies.
- Industry — collaborative robot fastener tightening on assembly lines
- What: Use DexScrew-style tactile policies to rotate and tighten nuts and screws on fixtures with varied geometries (square, hex, cross, triangular), improving reliability over direct sim-to-real.
- Tools/products/workflows:
- “Tactile Fastening Controller” (BC policy with tactile + short history) running on a UR-class cobot and a multi-fingered hand.
- “Skill-based Teleop Data Collector” for rapid domain-specific data acquisition: operators guide wrist, robot handles finger rotation via sim-trained primitive.
- “Rotation Skill Library” with pre-trained gaits for different fastener shapes, integrated into ROS/industrial PLC workflows.
- Assumptions/dependencies:
- Availability of dexterous hand hardware with fingertip tactile sensing and safe arm-hand integration.
- Fasteners pre-positioned (e.g., nut on bolt, screwdriver engaged), as in the paper’s setup; no long-horizon perception.
- Sufficient compute/training time for initial sim training and BC (e.g., Isaac Gym-like parallel simulation).
- Safety procedures for human-robot collaboration (torque limits, workspace constraints).
- Field service and light maintenance — reliable rotational tool use
- What: Mobile manipulators use tactile policies to turn knobs, operate handles, and perform screwdriving in equipment racks, lab benches, and light maintenance contexts where geometry varies.
- Tools/products/workflows:
- On-robot “Assisted Rotation” mode that blends autonomous finger rotation with operator-guided wrist positioning for rapid adaptation.
- “Few-hour Data-to-Policy” workflow: simulate simplified object (revolute joint proxy), collect 50–70 teleop demos, train tactile BC, deploy.
- Assumptions/dependencies:
- Stable contact-rich execution without vision, or basic pre-alignment by an operator.
- Task geometry predominantly rotational; minimal translational threading beyond what the wrist can manage.
- Quality assurance in fastening — tactile anomaly detection
- What: Use spatiotemporal tactile patterns to detect misalignment, slipping, or cross-threading during rotation; flag and correct in-line.
- Tools/products/workflows:
- “Tactile Pattern Monitor” that watches for learned stable activation signatures (alternating thumb/index contacts) and triggers corrective wrist adjustments.
- Integration with MES/QA systems to log tactile telemetry and error events.
- Assumptions/dependencies:
- Calibrated tactile arrays and low-latency feedback; mapping from tactile patterns to acceptable torque/contact regimes.
- Standardized fixtures to reduce false alarms.
- Academia — reproducible tactile dexterity benchmark and pipeline
- What: Adopt the DexScrew pipeline as a practical benchmark for contact-rich manipulation with tactile sensing and imperfect simulation.
- Tools/products/workflows:
- Open-source sim environments with simplified object models (revolute joints) for gait induction.
- Reference datasets and BC baselines (hourglass encoder + action chunking).
- Course/lab modules on sim-to-real under sensing gaps.
- Assumptions/dependencies:
- Access to dexterous hands (e.g., XHand/Shadow/Allegro) and tactile hardware.
- Compute for PPO-oracle + DAgger sensorimotor distillation and BC training.
- Workforce training — skill-based teleoperation for dexterous tasks
- What: Train technicians to supervise wrist positioning while the robot executes learned rotational finger gaits, reducing the barriers to teleoperating multi-fingered hands.
- Tools/products/workflows:
- VR-controller UI for wrist pose and skill activation.
- “Human-in-the-loop Fastening” SOPs with quick handover between teleop and autonomous modes.
- Assumptions/dependencies:
- Ergonomic teleop hardware and low-latency control; policies robust to operator variability.
- Clear safety and escalation procedures.
- Makerspaces/repair labs — automated repetitive screwdriving
- What: Deploy dexterous robots to perform repetitive screwdriving in prototyping and small-batch repair work, reducing technician fatigue.
- Tools/products/workflows:
- Task-specific rotation gaits trained via simplified sim plus short real data collection on target screws.
- Tactile BC policy with history for robust contact under perturbations.
- Assumptions/dependencies:
- Economic feasibility of dexterous hardware in small shops; standardized setups where pre-insertion/alignment is feasible.
Long-Term Applications
The following applications require additional research, scaling, or integration (e.g., perception, planning, rugged hardware) before widespread deployment.
- Industry/manufacturing — end-to-end long-horizon assembly with perception
- What: Full workflows that include perception-driven pick/place, thread alignment, nut placement, and fastening across varied parts.
- Tools/products/workflows:
- Vision + force-torque + tactile fusion; perception modules for part localization and alignment.
- Library of rotational and translational skill primitives chained with task planners.
- Assumptions/dependencies:
- Robust pose estimation in clutter; accurate threading models or tactile-driven alignment; policy recovery under large disturbances.
- Energy sector — hazardous and remote maintenance (wind, offshore, nuclear)
- What: Ruggedized dexterous manipulators perform bolt tightening, valve turning, and control operations in hazardous/remote environments.
- Tools/products/workflows:
- Teleop-assisted autonomous rotation with tactile BC; remote supervision and fallback modes.
- Fleet-level “fastener skill packs” customized per site.
- Assumptions/dependencies:
- Environmental hardening (weather, radiation), strict safety certification, reliable comms; mobile platforms with stable manipulation bases.
- Construction and infrastructure — on-site fastening/adjustment tasks
- What: Robots perform rotational tasks during construction (e.g., bracket installation, panel adjustments) where parts and conditions vary.
- Tools/products/workflows:
- On-the-fly skill adaptation via rapid teleop data collection; robust policies against dust, vibration, and variability.
- Assumptions/dependencies:
- Vision and planning for part discovery; handling non-rigid structures and variable tolerances.
- Space and underwater robotics — dexterous tool operations
- What: Extravehicular maintenance (unscrew/replace components) or subsea valve operations using tactile-guided rotational manipulation.
- Tools/products/workflows:
- Low-gravity/underwater-specific simulation-to-skill induction with tactile BC refined from teleop sessions.
- Specialized end-effectors and seals; redundancy for fault tolerance.
- Assumptions/dependencies:
- Extreme environment compatibility; limited communications; rigorous validation and fault recovery.
- Healthcare — device and instrument manipulation (non-surgical)
- What: Dexterous robots adjust knobs, connectors, and threaded components on medical devices in hospital labs or sterilization departments.
- Tools/products/workflows:
- Tactile policies to ensure correct engagement and avoid cross-threading; anomaly detection from tactile signature deviations.
- Assumptions/dependencies:
- Regulatory compliance, stringent safety and sterility; integration with clinical workflows; robust error handling.
- Household/general-purpose robotics — furniture and appliance assembly
- What: Assistive robots perform furniture assembly (IKEA-style), appliance panel screwdriving, and cap/knob operations.
- Tools/products/workflows:
- Consumer-grade dexterous hands with cost-effective tactile sensing; combined vision + tactile pipelines.
- “Skill marketplace” distributing rotation primitives for common household fasteners.
- Assumptions/dependencies:
- Affordability and reliability of dexterous hardware; compact training pipelines; strong safety guarantees.
- Software and standards — tactile simulation and policy certification
- What: Data-driven tactile models and standards enabling reproducible training/evaluation and certifiable deployment of dexterous policies.
- Tools/products/workflows:
- Shared tactile datasets; standardized revolute-joint proxy environments for gait induction; certification tests for contact-rich skills.
- Assumptions/dependencies:
- Cross-vendor sensor calibration standards; industry buy-in; benchmarks covering diverse geometries and conditions.
- Workforce and policy — reskilling and deployment guidelines
- What: Policy frameworks for safe deployment of dexterous robots in assembly; reskilling programs for operators to use skill-based teleop.
- Tools/products/workflows:
- Training curricula on assisted teleoperation and tactile diagnostics; safety protocols for mixed autonomy.
- Assumptions/dependencies:
- Collaboration among manufacturers, regulators, and unions; clear liability and compliance pathways; accessible training resources.
Collections
Sign up for free to add this paper to one or more collections.