- The paper introduces a two-stage adaptation pipeline combining structured human-guided trajectory refinement with residual reinforcement learning to bridge the sim-to-real gap.
- It achieves the highest F1 scores on five piano pieces with only 30 minutes of real-world interaction, outperforming purely simulation-driven and non-adaptive baselines.
- The approach leverages targeted residual corrections and domain-informed heuristics to enable precise, robust bimanual manipulation on non-specialized hardware.
HandelBot: Fast Adaptation of Dexterous Robot Policies for Real-World Piano Playing
Introduction
Dexterous manipulation utilizing multi-fingered robot hands represents a persistently challenging domain, particularly when deployed in the physical world for tasks that require both spatial and temporal accuracy. Piano playing, as a paradigm, necessitates precise coordination, fine contact timing, and robust long-horizon control. Historically, teleoperation and imitation learning approaches have served as the primary means for achieving such dexterity, but these techniques either demand significant high-quality human demonstration data or suffer from substantial embodiment gaps. Reinforcement learning (RL) in high-throughput simulation alleviates data acquisition constraints but is fundamentally limited by the sim-to-real transfer gap, which is catastrophic at millimeter precision.
The paper "HandelBot: Real-World Piano Playing via Fast Adaptation of Dexterous Robot Policies" (2603.12243) introduces a hybrid learning architecture explicitly designed to overcome the limitations of sim-to-real transfer for piano playing with bimanual robot hands. The approach leverages a two-stage adaptation pipeline: (1) structured, human-in-the-loop trajectory refinement exploiting domain priors, and (2) real-world residual RL for fine-grained error correction. Systematic evaluation demonstrates that this method achieves robust piano playing across five musical pieces with as little as 30 minutes of real-world interaction data, consistently outperforming purely simulation-driven or non-adaptive baselines.
Methodology
The central methodological innovation in HandelBot is the decomposition of transfer learning into sequentially staged adaptation, leveraging efficient pretraining in simulation and lightweight but targeted real-world fine-tuning. The procedure is outlined as follows:
- Reinforcement Learning in Simulation: Fast, parallel RL (PPO) is conducted in a physics simulator (ManiSkill), with reward shaping prioritizing correct key presses and penalizing energy use. Control is realized in terms of delta joint actions, with scripted end-effector trajectories defined from sheet music.
- Structured Policy Refinement: Upon direct deployment, simulation-trained policies display systematic spatial misalignments. A human-defined lateral joint correction steps in, iteratively updating open-loop joint trajectories using the MIDI feedback from the real piano. Temporal chunking and anticipatory spatial adjustment are incorporated to ensure motion smoothness and rapid convergence, reducing bias errors without additional learning.
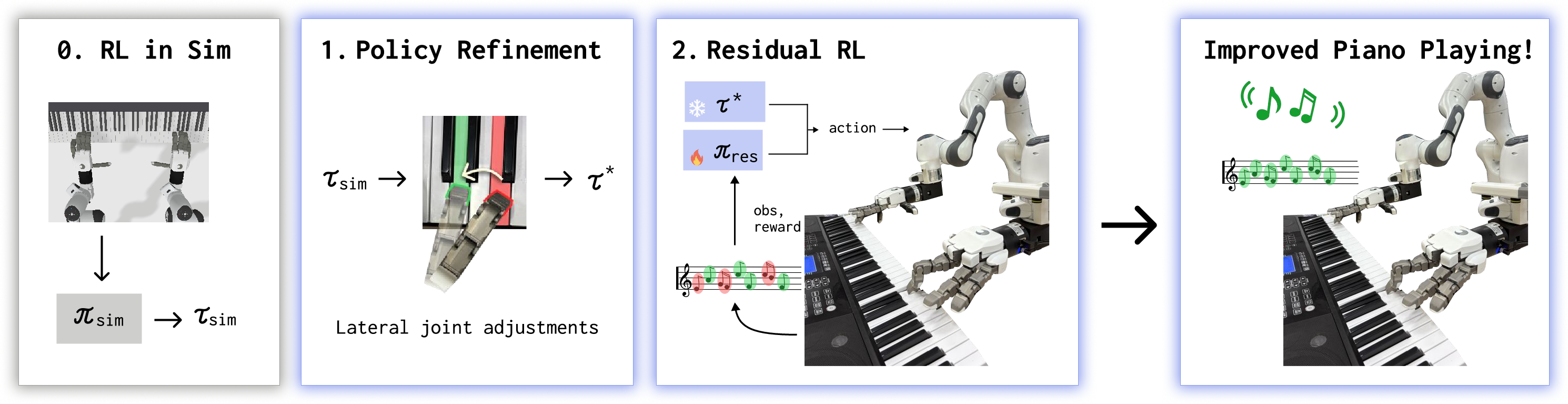
Figure 1: HandelBot's two-stage pipeline with simulation RL, structured policy refinement, and residual RL.
- Residual Reinforcement Learning: The refined trajectory is then augmented by learning small additive corrections in joint space via a residual policy, trained with TD3 on real hardware. The policy operates with a constrained action space for safe and sample-efficient exploration, driven solely by the real piano's MIDI reward. Guided noise is introduced along human-prioritized axes to facilitate rapid adaptation. Critically, this "residual over structure" paradigm enables precise real-world adaptation while preserving the robust coordination structure learned in simulation.

Figure 2: Experiment hardware: two Tesollo DG-5F hands, two Franka arms, and a MIDI-enabled keyboard for closed-loop reward calculation.
Experimental Results
HandelBot is benchmarked on five canonical piano pieces, with each task involving bimanual, three-fingered posture due to physical constraints. The primary metrics are F1 scores (aggregated over five rollouts), capturing the accuracy and timing of note presses.
Main Findings
Visualization of evaluation rollouts indicates HandelBot's error modes shift from consistent systematic offsets (sim-only) to rare timing or reach errors that predominantly arise in more complex musical pieces requiring large inter-key jumps.
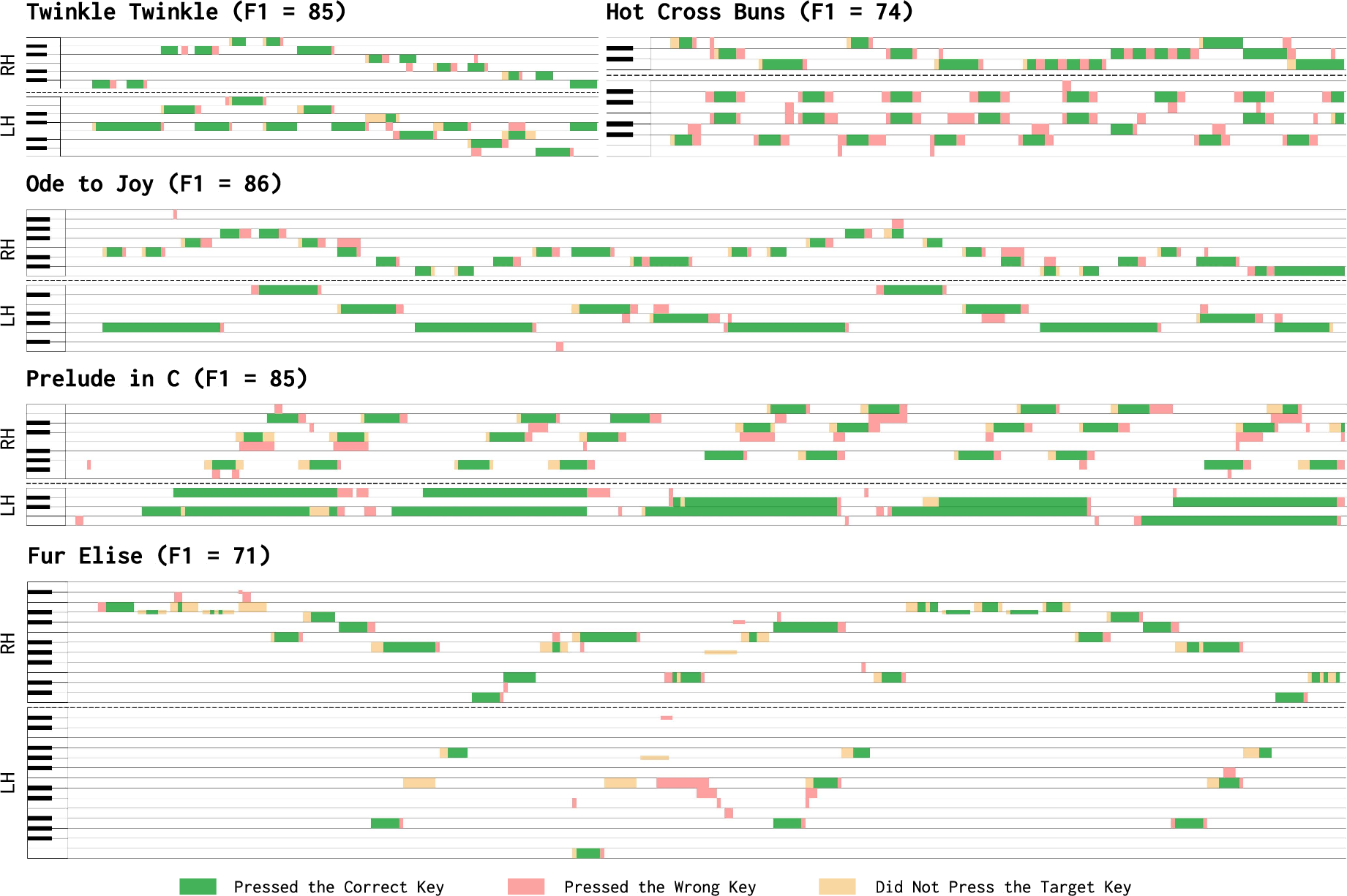
Figure 4: Example song evaluation—correct, incorrect, and missed notes by each hand across time. HandelBot generally maintains target key accuracy except during challenging large-span transitions.
Learning curves over training time illustrate rapid convergence, with the majority of adaptation occurring within the first few tens of real trajectories.

Figure 5: HandelBot trajectories during residual RL training show quick reduction of left-hand errors within a limited number of physical trials.
Ablations
Systematic ablation confirms:
- Lower RL discount factors result in jerkier, less stable motions.
- The inclusion of guided noise is not a sensitive hyperparameter, but always biasing exploration can degrade sample efficiency.
- Initializing the residual policy with increasingly refined trajectories significantly improves both training stability and final accuracy.
- Sim-to-real transfer methods employing hybrid observation (parallel sim) yield marginal improvements over direct transfer, but their performance remains clearly suboptimal compared to any strategy incorporating even minimal real-world data.
Implications and Future Directions
HandelBot demonstrates that efficiently combining simulation priors with minimal, targeted real-world intervention is essential for bridging the gap in high-precision dexterous manipulation domains. The results highlight the severe limitations of sim-to-real transfer in tasks where even sub-millimeter misalignments compromise performance, validating the necessity of explicit structured refinement and local correction via RL. The impact extends beyond piano playing; the staged adaptation paradigm is broadly applicable to other fine-motor tasks with deterministic spatial mappings and observable rewards.
Practically, HandelBot provides evidence that bimanual, general-purpose robot hands can perform temporally and spatially constrained tasks on non-specialized hardware—with limited data—by exploiting human domain knowledge for trajectory initialization and RL for task-specific adaptation. However, certain limitations remain, notably reliance on hand-tuned end-effector scripts and lateral correction heuristics, and restriction to a reduced finger set due to embodiment mismatch.
Future research directions include:
- Learning end-effector trajectories or enabling adaptive orientation and more complex fingerings to facilitate performance of advanced musical compositions.
- Automatic policy refinement via learned models (e.g., vision-LLMs) to minimize human intervention and generalize to novel environments or tasks.
- Extending residual RL to address multi-modality policy correction and more expressive action spaces.
Conclusion
HandelBot provides a technically compelling demonstration of high-precision policy adaptation for complex dexterous manipulation. Through a principled synergy of simulation-based structural learning, structured error correction, and real-world residual RL, it achieves robust, bimanual piano playing with minimal physical trials. The staged adaptation framework established here sets a foundation for broader deployment of dexterous robots in tasks demanding severe spatial and temporal accuracy, signaling a promising direction for rapid, safe, and scalable sim-to-real transfer in robotics.
Reference:
"HandelBot: Real-World Piano Playing via Fast Adaptation of Dexterous Robot Policies" (2603.12243)
