- The paper introduces a novel framework that iteratively self-improves coding agents through empirical validation of code modifications.
- It integrates open-ended exploration with meta-learning, achieving significant performance gains on benchmarks like SWE-bench and Polyglot.
- The implementation prioritizes safety with sandboxing and human oversight while demonstrating transferable enhancements across models and languages.
Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
The paper "Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents" explores the development of autonomous AI systems that can iteratively improve themselves through self-modification and open-ended exploration. Building on concepts from biological evolution and foundational AI principles, this framework is implemented within the context of automating the evolution of coding agents, leveraging foundation models for enhanced functionalities.
Introduction
Modern AI systems, often bound by static, human-engineered architectures, lack the capability for autonomous self-improvement. Inspired by the concept of open-ended scientific progress and leveraging the theoretical framework of the Gödel Machine, the authors propose the Darwin Gödel Machine (DGM). This system departs from the impracticable necessity of formal proof for beneficial modifications, opting instead for empirical validation against coding benchmarks. The DGM is a marriage of meta-learning techniques with the self-improving theoretical propositions of the Gödel Machine, enriched by open-ended explorative strategies.
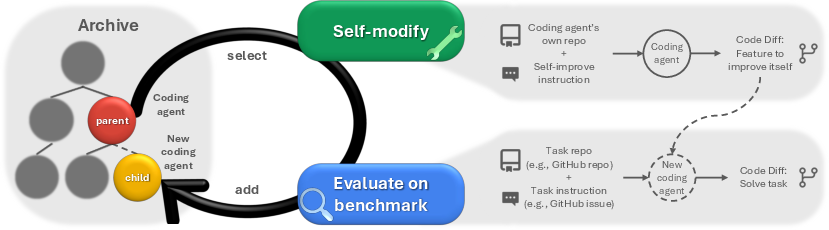
Figure 1: Darwin Gödel Machine. The DGM iteratively builds a growing archive of agents by interleaving self-modification with downstream task evaluation. Agents in the archive are selected for self-modification through open-ended exploration.
Methodology
Self-referential Self-improvement
The DGM initializes with a single coding agent embedded within a foundation model with tool-using capabilities. This Turing-complete agent can execute, read, and write code, thus enabling self-modification. Each self-improvement iteration involves an agent from the archive suggesting a modification to its codebase, leading to a new agent that is then evaluated on coding tasks. This empirical approach mimics biological evolution where successful modifications are retained based on performance metrics rather than theoretical guarantees.
Open-ended Exploration
The archive architecture allows DGM to maintain a diverse repository of coding agents. This design supports an open-ended exploration of the solution space, enabling the system to leverage diverse stepping stones as springboards for future innovations. The archive's role in maintaining a diverse set of solutions helps the DGM avoid stagnation in local optima, essential for sustained self-improvement.
Results
Empirical evaluations on two coding benchmarks, SWE-bench and Polyglot, demonstrate significant performance improvements, reinforcing the efficacy of the DGM architecture. Starting from baseline performances of 20.0\% on SWE-bench and 14.0\% on Polyglot, the DGM self-improved to achieve scores of 50.0\% and 30.7\%, respectively. These improvements were obtained while observing strict safety protocols, emphasizing the practical applicability of the proposed approach.
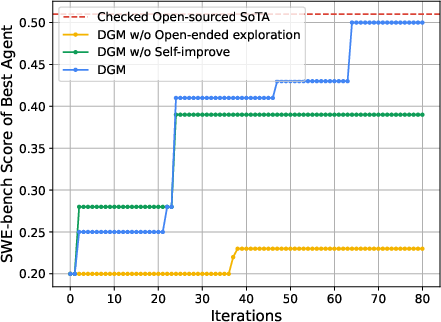
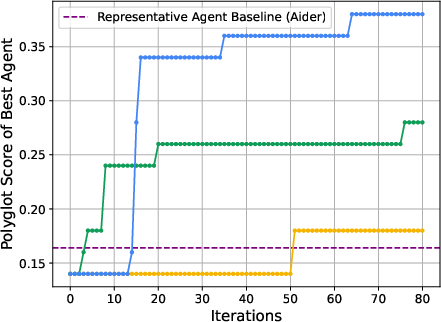
Figure 2: Self-improvement and open-ended exploration enable the DGM to continue making progress and improve its performance. The DGM automatically discovers increasingly better coding agents and performs better on both (Left) SWE-bench and (Right) Polyglot. It outperforms baselines that lack either self-improvement or open-ended exploration, showing that both components are essential for continual self-improvement.
The transferability of improvements across different foundation models and programming languages was also assessed, indicating that DGM-discovered enhancements are generalizable (Figure 3).
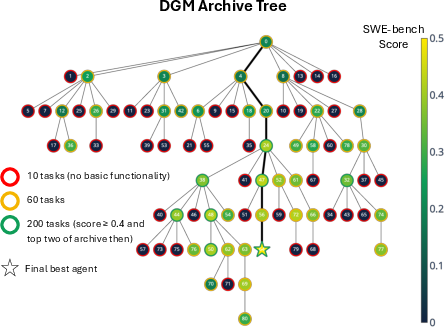
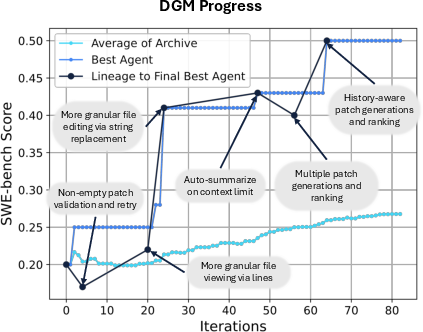
Figure 4: The DGM automatically self-improves to become a better coding agent. (Left) Archive of coding agents generated during the DGM run on SWE-bench. Each node represents a coding agent, with node 0 corresponding to the initial agent. Node color indicates performance on SWE-bench (percentage of solved tasks), while border color reflects the number of tasks for which the agent was evaluated. Edges show which agents self-modified to produce the offsprings. Many paths to innovation traverse lower-performing nodes, and key innovations (like node 24) lead to an explosion of innovations built on top of them.
Safety Considerations
The capacity for self-improvement in AI systems necessitates comprehensive safety measures. The DGM's ability to autonomously modify its code introduces potential risks, including the propagation of undesirable behaviors if evaluation functions do not capture safety and robustness comprehensively. The implementation includes sandboxing and continuous human oversight to mitigate these risks. The ultimate aim is advancing towards more secure, interpretable AI systems that evolve while retaining alignment with human values.
Conclusion
The Darwin Gödel Machine represents an innovative approach toward autonomous AI development, integrating empirical self-improvement with open-ended exploration. While significant advancements have been demonstrated, including performance comparable to handcrafted state-of-the-art solutions, challenges remain, particularly in computational complexity and safety assurance. Future work may address expanding self-modification to include more computationally intensive tasks and extending the domain applicability of such self-improving systems.