NanoGS: Training-Free Gaussian Splat Simplification
Abstract: 3D Gaussian Splat (3DGS) enables high-fidelity, real-time novel view synthesis by representing scenes with large sets of anisotropic primitives, but often requires millions of Splats, incurring significant storage and transmission costs. Most existing compression methods rely on GPU-intensive post-training optimization with calibrated images, limiting practical deployment. We introduce NanoGS, a training-free and lightweight framework for Gaussian Splat simplification. Instead of relying on image-based rendering supervision, NanoGS formulates simplification as local pairwise merging over a sparse spatial graph. The method approximates a pair of Gaussians with a single primitive using mass preserved moment matching and evaluates merge quality through a principled merge cost between the original mixture and its approximation. By restricting merge candidates to local neighborhoods and selecting compatible pairs efficiently, NanoGS produces compact Gaussian representations while preserving scene structure and appearance. NanoGS operates directly on existing Gaussian Splat models, runs efficiently on CPU, and preserves the standard 3DGS parameterization, enabling seamless integration with existing rendering pipelines. Experiments demonstrate that NanoGS substantially reduces primitive count while maintaining high rendering fidelity, providing an efficient and practical solution for Gaussian Splat simplification. Our project website is available at https://saliteta.github.io/NanoGS/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces NanoGS, a simple way to shrink 3D scenes made with “Gaussian splats” without retraining any model or needing the original photos. It turns big, heavy 3DGS scenes (which can have millions of tiny ellipsoid-like “splats”) into much smaller ones while keeping the scene looking almost the same. Smaller scenes are faster to render, easier to share, and use less storage.
What questions did the researchers ask?
They focused on a few plain questions:
- Can we cut down the number of splats in a 3D scene without retraining and without using any images or camera data?
- How do we decide which splats to merge so the scene still looks right and keeps its shape?
- Can this work fast on regular CPUs and still plug into existing 3DGS renderers with no special changes?
How did they do it?
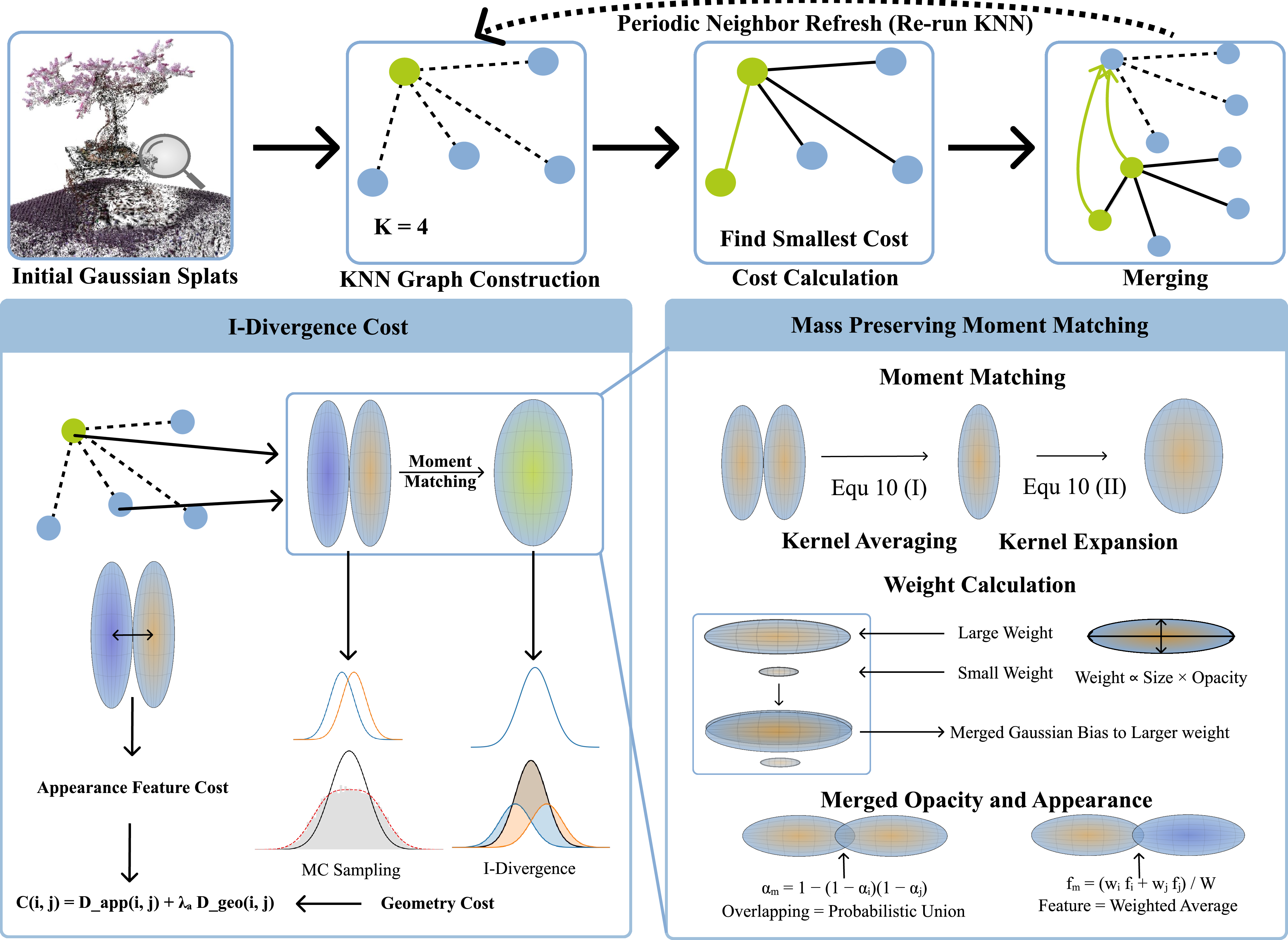
Think of a 3D scene as a cloud made of many soft, colored “blobs” (the splats). NanoGS carefully merges nearby blobs into fewer, slightly bigger blobs that cover the same space and look the same to the camera.
Here’s the approach in simple steps:
- First, remove “almost invisible” splats: If a splat barely shows up (very low opacity), it’s likely not important. They prune these first to reduce noise.
- Build a neighborhood map: Each splat finds its k closest neighbors in 3D space. This creates a small local network so the method only tries to merge splats that are actually near each other (saves time and avoids bad matches).
- Score how good a merge would be:
- Geometry score: Imagine the two splats together as a small two-blob shape. Now ask, “How well could a single blob represent both?” If the two splats overlap and are similar, one blob can replace them with little difference (good!). If they’re far apart, replacing with one blob would look wrong (bad!). They measure this with an “information difference” score (you can think of it as how much the single-blob version would change the original shape).
- Appearance score: They also check if the splats’ colors/appearance are similar. If they’re very different, merging could cause color problems.
- Merge the best pairs using Mass Preserved Moment Matching (MPMM): This is a careful way of combining two blobs:
- The new blob’s center and shape are “weighted” by how big and opaque each original blob was. Bigger, more visible blobs influence the result more—like mixing two blobs of clay where the larger one shifts the final center more.
- The new blob’s size keeps both the original sizes and the distance between them in mind, so it still covers the same area and doesn’t leave holes.
- Opacity is combined like a “probabilistic union,” which prevents the merged splat from becoming too opaque but keeps it visible.
- Do merges in batches and refresh neighborhoods: They repeatedly pick many non-overlapping low-cost pairs to merge at once, then update the neighbor map so new nearby pairs can be found. This continues until they reach the target size (for example, 10×, 100×, or 1000× fewer splats).
What did they find?
Across 21 scenes from four standard benchmarks, NanoGS made scenes much smaller while keeping image quality high:
- They tested three “compaction ratios” (how many splats remain compared to the original): 0.1 (10%), 0.01 (1%), and 0.001 (0.1%).
- NanoGS achieved the best image quality (measured by PSNR, a “higher is better” picture-accuracy score) at every ratio compared to other methods they tested.
- On average, NanoGS improved PSNR by about +2.4 dB at 10%, +4.84 dB at 1%, and +5.46 dB at 0.1% versus the next-best method, which is a meaningful boost.
- It also held up especially well when scenes were compressed very aggressively (down to 1% or 0.1% of the splats), where other methods tended to break up surfaces or leave artifacts.
- It runs on CPU, needs no retraining, and keeps the standard 3DGS format, so the simplified scenes can be rendered right away with existing tools.
Why this matters: Better quality at smaller sizes means faster rendering, quicker downloads, and easier use on laptops, phones, or VR devices.
Why does it matter?
This work can help anyone who wants high-quality 3D scenes to be:
- Smaller to store and faster to share: Good for web apps, games, and VR/AR.
- Faster to render: Fewer splats means less work for the computer each frame.
- Easier to use in many pipelines: No retraining or special formats—just plug it into your usual 3DGS renderer.
- Compatible with other compression: After simplifying the structure, you can still apply standard file-size compression to shrink it even more.
Looking ahead, the authors suggest:
- Speeding up parts on the GPU for even faster processing.
- Smarter merge decisions that consider human perception.
- Extending the method to handle moving (dynamic) scenes.
In short, NanoGS shows that you can shrink 3D Gaussian-splat scenes a lot, keep them looking good, and do it quickly without retraining or extra data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, formulated to guide follow‑up research:
- Runtime and scalability: No wall‑clock simplification times, asymptotic or empirical scaling on large models (e.g., 10–50M splats), or memory usage during simplification are reported; CPU-only implementation limits deployment insights.
- Hyperparameter sensitivity: The method lacks a systematic study of key hyperparameters (e.g., KNN k, opacity threshold, merge batch size, neighborhood refresh frequency/radius) on quality vs. speed trade‑offs.
- Merge cost weighting: The relative weighting between geometry (I‑divergence) and appearance (feature L2) in the merge cost is not specified or tuned; guidelines for dataset‑ or content‑adaptive weighting are absent.
- Monte Carlo estimation details: The number of samples S for I‑divergence, estimator variance, and its impact on stability/quality vs. runtime are not analyzed; no variance‑reduction or adaptive sampling strategies are explored.
- Determinism and reproducibility: Effects of random seeds (Monte Carlo sampling, tie‑breaking) on final models are not reported; no discussion of run‑to‑run variability.
- Greedy matching suboptimality: The greedy disjoint‑pair selection is order‑dependent and may be suboptimal; comparisons to approximate/global matchings (e.g., maximal/maximum weighted matchings) or merge‑ordering strategies are missing.
- Locality metric: KNN uses Euclidean center distance only; anisotropy-, covariance-, or Mahalanobis‑distance‑based neighborhoods are not explored to avoid cross‑surface merges between nearby but disjoint structures.
- Visibility/topology awareness: The method is unaware of occlusion, surface topology, or visibility; merges can occur across depth discontinuities. Training‑free cues (e.g., normals from covariances, occupancy grids) are not leveraged.
- Thin structures and edges: Potential blurring or loss of fine/thin geometry due to covariance inflation is not quantified; no geometric metrics (e.g., Chamfer, edge/silhouette accuracy) are reported.
- View‑dependent appearance: Appearance discrepancy uses view‑agnostic SH coefficient L2; handling of highly specular, glossy, or emissive content is not addressed; no perceptual metrics (e.g., LPIPS/FLIP) or directional error analyses are provided.
- Opacity aggregation dynamics: Repeated Porter–Duff union during many merges may drive α toward 1; the effect on transmittance ordering, depth compositing, and haloing is not analyzed or bounded.
- Error‑bounded stopping: Simplification uses a target count ratio ρ, not an error‑controlled criterion; no mapping between divergence/image error and stopping rules is provided.
- Multi‑way (cluster) merges: Only pairwise merges are considered; n‑ary cluster merges or hierarchical agglomerative schemes that could reduce order‑dependence and improve global optimality are not explored.
- Closed‑form or surrogate costs: Alternatives to Monte Carlo I‑divergence (e.g., analytic bounds/approximations, tighter surrogates than MSE) are not developed; the trade‑offs are only partially ablated.
- Neighborhood refresh policy: The “periodic refresh” schedule is underspecified; its frequency, locality, and computational cost vs. quality benefits are not quantified.
- Large‑scale/complex scene evaluation: Benchmarks exclude very large outdoor/city‑scale scenes, heavy foliage, glass/transparency, low‑light, or challenging specular environments where merges may fail differently.
- Failure mode analysis: No qualitative catalog of failure cases (e.g., cross‑surface merges, color bleeding, specular smear, depth artifacts) or conditions under which NanoGS underperforms.
- Combination with bit‑level compression: Although compatibility is claimed, there are no experiments quantifying end‑to‑end storage/fidelity when stacking NanoGS with codecs (e.g., Compressed3DGS, HAC/HAC++, CONTEXTGS) under fixed bitrate budgets.
- Renderer/runtime performance: Only FPS after compaction is reported; no analysis of rasterization overhead components (sorting cost, overdraw) or GPU memory bandwidth changes attributable to compaction choices.
- LOD and streaming: While progressive merges imply a hierarchy, no mechanism is provided for exporting/using multi‑LOD assets, error‑guided LOD selection, or streaming over networks.
- Applicability to diverse 3DGS variants: Generality across different parameterizations (e.g., varying SH degrees, alternative features, structured/learned encodings) is not evaluated.
- Generated/edited/converted assets: Although image‑free operation targets generative/editing/mesh‑to‑splat pipelines, no experiments verify robustness on such assets (e.g., DreamGaussian, mesh2Splat outputs).
- Semantic/feature preservation: Impact on auxiliary fields (e.g., semantics, feature splats) is untested; simple averaging may degrade downstream tasks that rely on high‑frequency or discriminative features.
- Depth ordering and compositing: Effects of merges on depth sorting/stability and view‑dependent occlusion errors are not quantified.
- Parameterization of “mass”: The mass term uses α and scale product; its interaction with rotated anisotropic covariances and edge cases (large, low‑opacity vs. small, high‑opacity splats) lacks theoretical analysis and stress tests.
- Topology‑preserving constraints: No constraints prevent merges across different surfaces/parts; methods to incorporate geometric proxies (normals, tangent planes) or learned compatibility tests are not investigated.
- Dynamic/4D scenes: Extension to temporally varying Gaussians (4DGS) is only suggested; challenges like temporal consistency, motion‑aware costs, and per‑frame vs. joint merges remain open.
- Metric diversity: Evaluations omit perceptual/image‑space metrics (LPIPS, FLIP), temporal flicker (for sequences), and user studies; correlation between I‑divergence and image error is not validated.
- Hyperparameter auto‑tuning: No procedures exist for automatically setting k, thresholds, or cost weights per scene; scene‑adaptive strategies remain unexplored.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage NanoGS’s training-free, CPU-efficient simplification of 3D Gaussian Splat (3DGS) models while preserving the standard 3DGS parameterization.
- Boldly smaller 3DGS assets for web and mobile viewing
- Sectors: software, media/entertainment, e-commerce, real estate, education
- Use case/workflow: Post-process trained or generated 3DGS assets with NanoGS to hit targeted compaction ratios (e.g., 0.1, 0.01) and serve via WebGPU/WebGL viewers for faster load times and reduced bandwidth.
- Tools/products: “gs-simplify” CLI or service; integration into existing WebGPU-based viewers; CDN pipeline hook that compacts at publish time.
- Assumptions/dependencies: Consumer devices must support 3DGS rendering; starting asset must already be a valid 3DGS model; fidelity targets must match use context.
- Level-of-Detail (LOD) tiers for interactive XR and games
- Sectors: gaming, XR/VR, software
- Use case/workflow: Generate multiple LOD variants (e.g., ρ∈{0.1, 0.01, 0.001}) with NanoGS and stream/switch LODs based on camera distance or device capability.
- Tools/products: Unity/Unreal plugins that call NanoGS during asset import; runtime LOD manager for 3DGS content.
- Assumptions/dependencies: Runtime supports 3DGS LOD switching; consistent lighting/appearance between LODs is acceptable for the experience.
- Edge-device deployment of 3D scenes
- Sectors: robotics, mobile AR, IoT, education
- Use case/workflow: Compact 3DGS reconstructions to meet memory and compute budgets on AR headsets, mobile phones, or robot onboard systems.
- Tools/products: On-device/offline compaction step; pre-installed asset packs with compact 3DGS models.
- Assumptions/dependencies: 3DGS renderer available on device; static scene assumptions hold (current method targets static scenes).
- Cost-efficient cloud distribution of 3D content
- Sectors: cloud infrastructure, media/entertainment, SaaS platforms
- Use case/workflow: Reduce storage and egress costs by compacting 3DGS assets before archival and distribution without retraining.
- Tools/products: CI/CD pipeline stage (e.g., GitHub Actions) invoking NanoGS; object storage policies that store both full and compacted assets.
- Assumptions/dependencies: Bit-level codecs (e.g., Compressed3DGS) can be layered on top for additional gains; compacted assets stay compatible with existing renderers.
- Faster iterative 3D content creation
- Sectors: VFX/film, design, 3D content studios, education
- Use case/workflow: After generation (e.g., DreamGaussian), use NanoGS to quickly preview compact variants, enabling faster iteration and review on commodity hardware.
- Tools/products: Blender/Unreal/Unity add-ons to run NanoGS as a post-processing operator; review tools with “compact preview” toggle.
- Assumptions/dependencies: Generated 3DGS assets have sufficient quality; artists accept slight approximations during iteration.
- Scalable 3D digitization for museums and cultural heritage portals
- Sectors: public sector, culture, education, tourism
- Use case/workflow: Publish compact representations to increase accessibility (reduced download sizes) while keeping higher-fidelity versions for research.
- Tools/products: Public portal pipelines that auto-generate compact and archival variants; offline batch compaction on CPU.
- Assumptions/dependencies: Legal permissions for public sharing; viewer infrastructure capable of 3DGS visualization.
- E-commerce product visualization with lower data usage
- Sectors: retail, e-commerce, advertising
- Use case/workflow: Use NanoGS to slim 3D product scenes for mobile shoppers, decreasing bounce rates in low-connectivity contexts.
- Tools/products: CMS plugins that compact new 3D product assets on upload; A/B testing pipelines to pick optimal compaction levels per product.
- Assumptions/dependencies: Acceptable trade-off between fidelity and speed; standardized lighting across models for consistent UX.
- Robotics/offline mapping asset pruning for simulation and replay
- Sectors: robotics, simulation, autonomous systems
- Use case/workflow: Compact reconstructed environments (from multi-view capture) for faster simulation replay and scenario sharing among teams.
- Tools/products: ROS-compatible asset processing nodes; dataset toolchains integrating NanoGS.
- Assumptions/dependencies: Maps are primarily static; perception stacks expect 3DGS-compatible viewers/simulators.
- Academic dataset release and benchmarking
- Sectors: academia, open science
- Use case/workflow: Release both full and NanoGS-compact variants to reduce download sizes and compute requirements for baseline reproduction and teaching.
- Tools/products: Dataset packaging scripts; compacted benchmark tracks (e.g., for courses or student projects).
- Assumptions/dependencies: Community adoption of 3DGS viewing tools; explicit documentation of compaction ratios and metrics.
- Sustainable computing practices via reduced storage and transfer
- Sectors: sustainability, cloud ops, public sector (policy-adjacent)
- Use case/workflow: Adopt NanoGS as a standard post-process to lower storage footprints and data transfer energy for 3D content platforms.
- Tools/products: Green-compute dashboards that report savings; policy-compliant workflows for government-funded digitization projects.
- Assumptions/dependencies: Verified measurement frameworks for energy and emissions accounting; organizational commitment to sustainability targets.
Long-Term Applications
Below are forward-looking opportunities that may require additional research, engineering, or standardization.
- Real-time, on-device compaction for AR/robotics
- Sectors: robotics, mobile AR/XR
- What it looks like: GPU-accelerated NanoGS enabling live scene simplification as maps update, keeping memory bounded during extended missions.
- Tools/products: Embedded GPU kernels for KNN graph and merge; integration with SLAM/visual-inertial pipelines.
- Assumptions/dependencies: Extension to dynamic scenes; tight real-time constraints; robust scheduling with perception tasks.
- Dynamic/4D Gaussian Splat compaction
- Sectors: media/entertainment, telepresence, sports broadcasting
- What it looks like: Extending MPMM and merge costs to time-varying Gaussians for efficient 4D scene streaming and storage.
- Tools/products: Temporal-aware merge cost; video-like rate–distortion control for 4DGS streaming.
- Assumptions/dependencies: New formulations for temporal coherence; handling motion and appearance changes without artifacts.
- Perception/quality-aware compaction (task-adaptive)
- Sectors: gaming, XR, autonomous systems, healthcare (training/simulation)
- What it looks like: Merge criteria tuned to human perception (e.g., saliency, foveation) or downstream tasks (e.g., navigation, object interaction).
- Tools/products: Learned merge costs conditioned on perceptual or task metrics; eye-tracking-driven compaction for XR.
- Assumptions/dependencies: Collection of perceptual labels or task reward signals; integration with gaze/attention systems.
- Progressive streaming and rate–distortion optimized pipelines
- Sectors: cloud infrastructure, CDNs, media platforms
- What it looks like: Multi-scale, progressively refinable 3DGS streams where NanoGS generates a base mesh of splats plus refinements for adaptive bitrate.
- Tools/products: Streamable 3DGS container format with embedded LODs; server-side packagers and client-side adaptive renderers.
- Assumptions/dependencies: Industry consensus and tooling for streamable 3DGS formats; standardization across browsers/devices.
- Joint compaction + entropy coding stacks
- Sectors: software, cloud, media/entertainment
- What it looks like: Pipelines that run NanoGS first (primitive reduction) followed by state-of-the-art codecs (e.g., Compressed3DGS, HAC++) to maximize gains.
- Tools/products: End-to-end “compress and compact” toolchains with RD dashboards and automatic ratio tuning.
- Assumptions/dependencies: Careful ordering and parameter tuning to avoid compounding artifacts; compatibility tests across renderers.
- Standardized 3DGS LOD and archival conventions
- Sectors: policy, public sector digitization, standards bodies
- What it looks like: Guidelines and certification for archival and dissemination of 3DGS content that include NanoGS-like compaction as a normative step.
- Tools/products: Open specifications and reference implementations; procurement language for public projects (e.g., museums, urban digital twins).
- Assumptions/dependencies: Multi-stakeholder coordination; longevity and backward compatibility guarantees.
- Healthcare/medical training content distribution (non-diagnostic)
- Sectors: healthcare education, medical device training
- What it looks like: Compact 3DGS-based anatomy/OR simulations for remote training and rehearsal where bandwidth is limited.
- Tools/products: Training content pipelines that compact assets for tablet/AR-headset deployment; integrated viewers in LMS platforms.
- Assumptions/dependencies: Clear scope: non-diagnostic usage; content derived from 3DGS-friendly pipelines (e.g., scans → mesh → splats) with proper de-identification.
- Smart city and AEC digital twins at scale
- Sectors: architecture/engineering/construction (AEC), urban planning, utilities
- What it looks like: City-scale radiance-field twins compacted for interactive planning dashboards and public transparency portals.
- Tools/products: Twin management platforms with compaction services; per-zone LOD scheduling and multi-user streaming.
- Assumptions/dependencies: Integration with GIS and BIM systems; policies for privacy and data governance.
- Telepresence and remote inspection
- Sectors: enterprise collaboration, manufacturing, energy
- What it looks like: Compact 3DGS captures of facilities for quick remote walkthroughs and maintenance planning on constrained networks.
- Tools/products: Capture-to-compact pipelines; enterprise viewers with offline caching and delta updates.
- Assumptions/dependencies: Safety/privacy controls; periodic recapture or dynamic scene support for change tracking.
- Generative 3D pipelines with compaction-aware diffusion
- Sectors: creative tools, media, gaming
- What it looks like: 3D generation models that co-design with compaction (e.g., generating splats that simplify well), reducing post-hoc losses.
- Tools/products: Training-time regularizers that predict/penalize high merge cost; autoregressive pipelines producing compact-friendly primitives.
- Assumptions/dependencies: Joint training datasets and metrics; openness of generative model APIs for integration.
Cross-cutting assumptions and dependencies
- Input availability: NanoGS requires an existing 3DGS model; it does not reconstruct from images.
- Scene characteristics: Current method assumes static scenes; dynamic/4D cases need research.
- Rendering compatibility: Works best where 3DGS rendering is supported (desktop, WebGPU, mobile XR).
- Quality targets: Selection of compaction ratio (ρ) should be guided by domain-specific tolerances (visual fidelity vs. speed/bandwidth).
- Compute trade-offs: While CPU-friendly, very large scenes may still benefit from GPU acceleration for the KNN graph and merge batches.
- Stack integration: For maximal storage gains, combine compaction with parameter-level compression; ensure pipeline order is validated.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit scene representation that models surfaces with many 3D Gaussian “splats” to enable real-time novel view synthesis. Example: "Real-time radiance field rendering has been fundamentally reshaped by 3D Gaussian Splatting (3DGS) \cite{3dgs}."
- adaptive density control: A training strategy that adjusts the number or density of Gaussians during optimization to improve quality and efficiency. Example: "anisotropic 3D Gaussians optimized with adaptive density control"
- anchor-based predictors: Codec-side predictors that use reference “anchors” to estimate parameters for more efficient compression. Example: "including anchor-based predictors and hierarchical entropy models"
- anisotropic: Having direction-dependent properties; anisotropic Gaussians have different variances along different axes. Example: "anisotropic 3D Gaussians"
- batched non-overlapping edge collapses: Parallel merging of disjoint edges in a graph to simplify a structure in steps. Example: "Batched non-overlapping edge collapses."
- Bregman divergences: A family of distance-like measures (including KL) used for clustering and mixture reduction. Example: "including Bregman divergences and information-theoretic co-clustering"
- calibrated images: Images with known camera intrinsics and extrinsics used to supervise optimization. Example: "GPU-intensive post-training optimization with calibrated images"
- co-clustering (information-theoretic co-clustering): Jointly clustering two sets (e.g., data points and features) using information-theoretic criteria. Example: "information-theoretic co-clustering"
- compaction: Reducing the number of primitives to simplify the model while maintaining rendering quality. Example: "compaction methods focus on reducing the number of Gaussian primitives while preserving rendering quality"
- compression: Reducing storage size and bandwidth via parameter quantization and coding. Example: "Compression methods aim to reduce the storage footprint and transmission bandwidth of 3DGS assets"
- codebooks: Shared finite sets of vectors used to quantize parameters efficiently. Example: "reduced bases, codebooks, or alternative primitive formulations"
- context models: Probabilistic models that condition on surrounding information to improve entropy coding. Example: "learned or engineered context models"
- differentiable rendering: Rendering processes designed to be differentiable for gradient-based learning. Example: "differentiable rendering signals"
- entropy coding: Lossless compression that exploits symbol probabilities (e.g., arithmetic coding). Example: "vector quantization, entropy coding, adaptive spherical-harmonic reduction"
- Gaussian mixture reduction: Approximating a Gaussian mixture with fewer components while preserving statistical properties. Example: "classical approaches for Gaussian mixture reduction and clustering"
- greedy matching: A heuristic that selects locally optimal disjoint pairs for merging without backtracking. Example: "selects disjoint low-cost pairs through greedy matching for scalable simplification."
- hierarchical entropy models: Multi-level probability models used to improve compression efficiency. Example: "hierarchical entropy models"
- I-divergence: Information divergence (KL) measuring discrepancy between distributions. Example: "The geometry cost measures the I-divergence between the original two-splat mixture and its single-Gaussian approximation."
- k-nearest neighbor (KNN) graph: A graph connecting each node to its k closest neighbors to restrict merge candidates locally. Example: "sparse -nearest neighbor graph"
- level-of-detail (LOD) compression: Aggressive reduction strategy targeting coarser, lower-detail representations. Example: "more aggressive LOD-style compression."
- Mass Preserved Moment Matching (MPMM): A merge operator that matches mass-weighted moments to fuse two Gaussians while preserving coverage. Example: "The Mass Preserved Moment Matching(MPMM) merge operator fuses a selected pair"
- mesh simplification: Techniques that reduce mesh complexity, often via edge collapses. Example: "edge-collapse procedures in mesh simplification."
- moment matching: Approximating a distribution by matching its moments (e.g., mean and covariance). Example: "approximated by a single Gaussian via moment matching"
- Monte Carlo: Stochastic estimation technique using random sampling to approximate integrals. Example: "In Monte Carlo evaluation we draw samples per candidate pair"
- Neural Radiance Field (NeRF): A neural representation that maps 3D positions and viewing directions to density and radiance. Example: "Neural Radiance Field (NeRF) \cite{mildenhall2021nerf}"
- Octree: A hierarchical spatial partitioning structure for efficient neighborhood queries. Example: "Octree-based neighborhood selection"
- opacity pruning: Removing low-opacity splats that contribute negligibly to appearance to streamline models. Example: "first removes visually insignificant splats through opacity pruning"
- optimal transport: A framework for optimally moving mass between distributions, used here to guide merging. Example: "optimal-transport-based merging"
- Porter–Duff source-over ("over") rule: A standard compositing rule for combining colors and opacities. Example: "Porter--Duff source-over (``over'') rule"
- probabilistic union: Combining independent coverage probabilities to compute merged opacity. Example: "Opacity is aggregated as a probabilistic union"
- pruning: Removing less important elements (e.g., splats) to reduce model size. Example: "integrate pruning or sparsification into retraining pipelines"
- rasterization: Converting primitives into pixels/fragments in the graphics pipeline. Example: "rasterization-compatible formulation"
- spherical harmonics coefficients: Coefficients of basis functions on the sphere used for view-dependent appearance. Example: "spherical harmonics coefficients"
- sparsification: Encouraging or enforcing zeros to reduce complexity and computation. Example: "pruning or sparsification"
- transmittance: The fraction of light that passes through; in compositing, T = 1 − α. Example: "transmittances "
- unnormalized Gaussian: A Gaussian function scaled so it does not integrate to one, used as a mass density. Example: "unnormalized Gaussian mass density"
- vector quantization: Mapping continuous vectors to a finite codebook to reduce storage. Example: "vector quantization"
- volumetric ray sampling: Sampling along rays through a volume to render radiance fields. Example: "eliminating costly volumetric ray sampling"
Collections
Sign up for free to add this paper to one or more collections.

