Optimized Minimal 4D Gaussian Splatting
Abstract: 4D Gaussian Splatting has emerged as a new paradigm for dynamic scene representation, enabling real-time rendering of scenes with complex motions. However, it faces a major challenge of storage overhead, as millions of Gaussians are required for high-fidelity reconstruction. While several studies have attempted to alleviate this memory burden, they still face limitations in compression ratio or visual quality. In this work, we present OMG4 (Optimized Minimal 4D Gaussian Splatting), a framework that constructs a compact set of salient Gaussians capable of faithfully representing 4D Gaussian models. Our method progressively prunes Gaussians in three stages: (1) Gaussian Sampling to identify primitives critical to reconstruction fidelity, (2) Gaussian Pruning to remove redundancies, and (3) Gaussian Merging to fuse primitives with similar characteristics. In addition, we integrate implicit appearance compression and generalize Sub-Vector Quantization (SVQ) to 4D representations, further reducing storage while preserving quality. Extensive experiments on standard benchmark datasets demonstrate that OMG4 significantly outperforms recent state-of-the-art methods, reducing model sizes by over 60% while maintaining reconstruction quality. These results position OMG4 as a significant step forward in compact 4D scene representation, opening new possibilities for a wide range of applications. Our source code is available at https://minshirley.github.io/OMG4/.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OMG4, a way to store and show moving 3D scenes (like videos you can look around in) using much less memory. It builds on a technique called 4D Gaussian Splatting, which draws scenes using millions of tiny soft “blobs” (Gaussians) that exist in 3D space and across time (that’s the 4th dimension). The problem is: using so many blobs takes up huge amounts of memory—often gigabytes. OMG4 cuts that down to just a few megabytes while keeping the scene looking almost the same and still running fast.
Key Questions
The paper asks simple but important questions:
- Can we pick only the most useful blobs that actually matter for the final picture?
- Can we remove or combine blobs that are similar or unnecessary?
- Can we pack the blobs’ properties (like color, size, and how they change over time) into a smaller form without losing quality?
How It Works (Methods and Analogies)
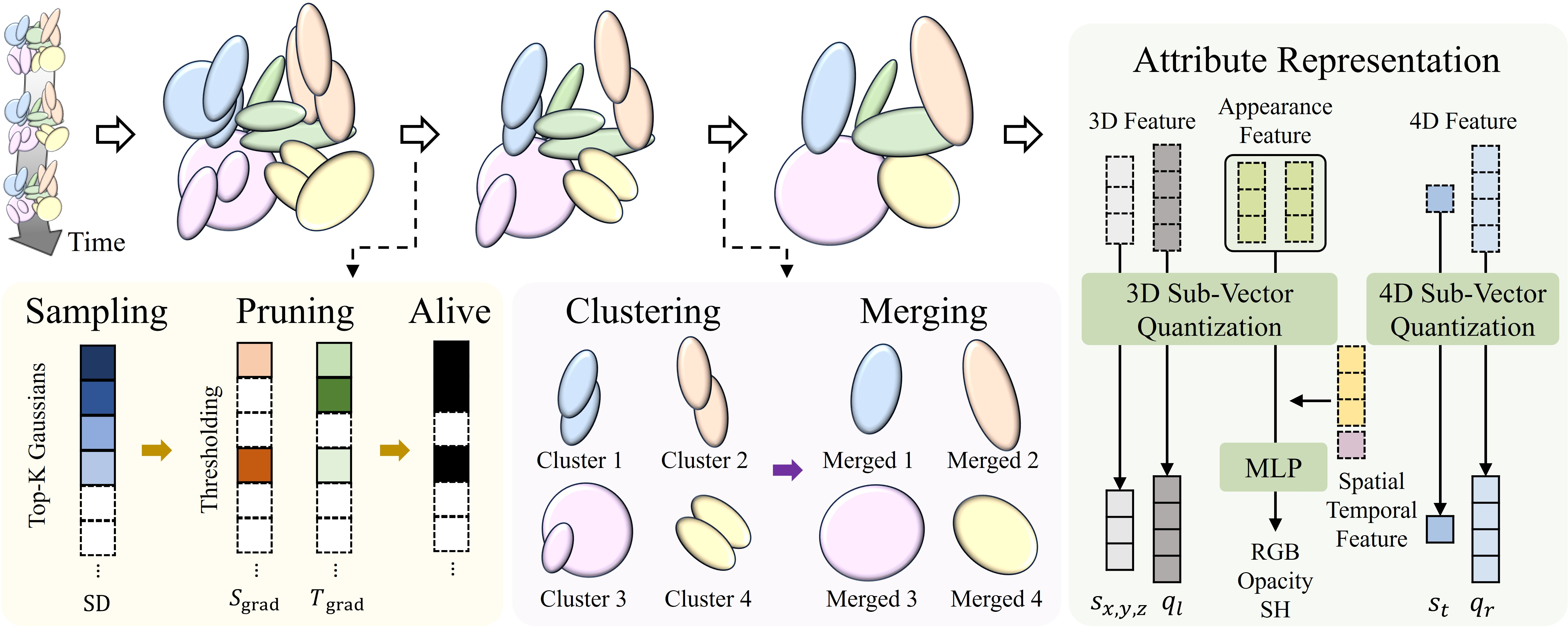
Think of a 4D scene like a moving hologram made of millions of soft, colored snowballs (Gaussians). Each snowball has a position in space, a time it’s active, a size/shape, and color. OMG4 uses four steps to shrink this hologram:
- First, an idea: a “gradient” is just a measure of how much the final image changes if we slightly move a blob or adjust its time. If changing a blob doesn’t change the image much, that blob isn’t very important.
Step 1: Gaussian Sampling
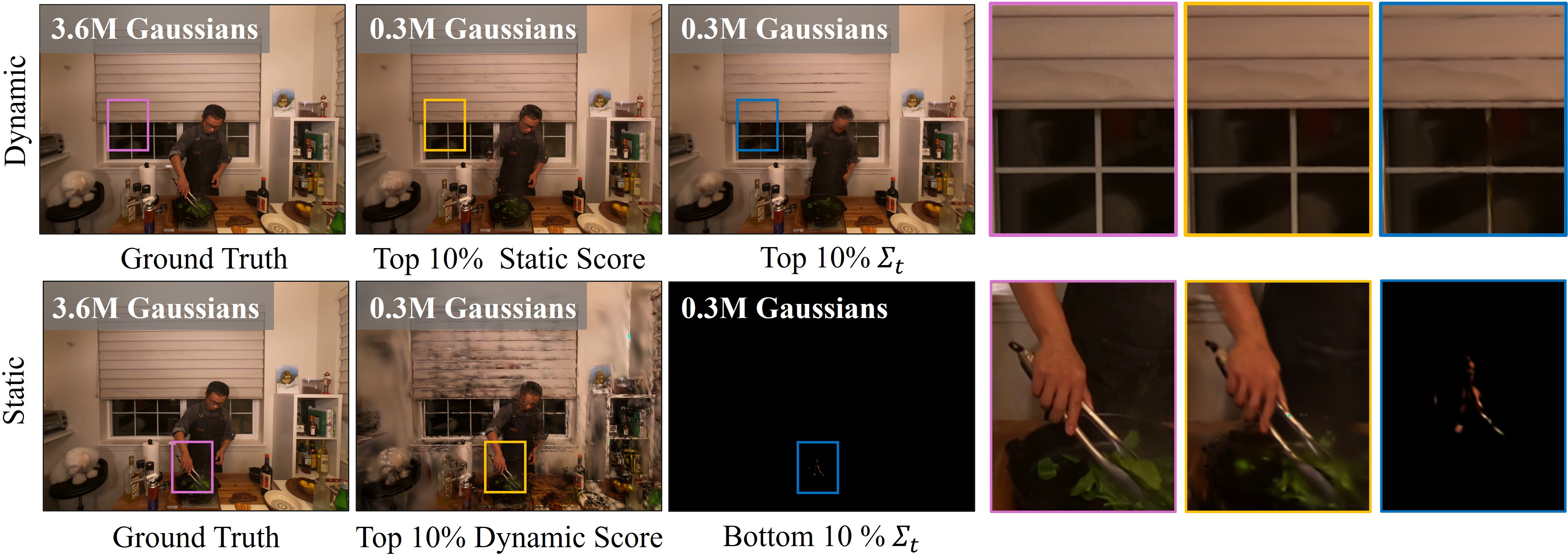
The team creates an “SD-Score” (Static–Dynamic Score) for each blob:
- Static score: How much the image changes if we nudge the blob’s position across many views and times. This finds blobs that matter in stable, background areas.
- Dynamic score: How much the image changes if we nudge the blob’s time. This finds blobs that matter in motion-heavy areas (like moving hands or cars).
They keep only the blobs with high SD-Score (about 20% of the original), then fine-tune them. It’s like keeping the best players on a team and training them more.
Step 2: Gaussian Pruning
Even after sampling, some blobs are still not helpful. The paper sets simple cutoffs on the static and dynamic scores and removes blobs that are low on both. Think of this like a second pass of cleaning your room—anything still not pulling its weight goes.
Why separate Step 1 and Step 2? Doing them one after another, with a bit of training in between, leads to more stable and better results than doing them at the same time.
Step 3: Gaussian Merging
Now, the method looks for blobs that are very similar and close to each other in space and time. It groups them in a 4D grid (space + time) and merges each group into a single “representative” blob:
- Similarity is based on distance and color likeness.
- The new blob’s position and color are weighted averages of the group.
- Other attributes (like shape and rotation) are taken from the most representative member.
This is like combining duplicate notes into one cleaner, stronger note.
Step 4: Attribute Compression
Even after reducing the number of blobs, each blob still stores many numbers (attributes). OMG4 compresses those:
- Small neural networks (MLPs) predict a blob’s appearance (color and opacity) from its position and time, instead of storing everything directly.
- Sub-Vector Quantization (SVQ): Imagine splitting a long code into smaller chunks and storing dictionary references for each chunk. This packs data tightly. OMG4 extends this idea to 4D (including time-related attributes).
- To keep training stable, they first quantize 3D attributes, then 4D ones. Finally, they use standard “zip” techniques (Huffman + LZMA) to shrink files further.
Main Findings and Why They Matter
- Huge memory savings: OMG4 shrinks models from around 2 GB to about 3 MB (a 99% reduction) on a popular dataset (N3DV), while keeping the image quality similar.
- Competitive or better quality: Compared to recent strong methods (like GIFStream), OMG4 uses about 65% less storage (10.0 MB down to 3.61 MB) and slightly improves quality by a common metric (PSNR).
- Faster rendering: Even without special speed tricks, scenes render about 4.3× faster than the baseline because there are fewer blobs to process.
- Works on other systems too: Applying OMG4 to another method (FreeTimeGS) cuts storage by about 90% while keeping quality high.
These results mean you can store and stream longer, higher-quality free-viewpoint videos and dynamic scenes on devices with limited memory (like phones, AR/VR headsets, or the web).
Implications and Impact
- Better streaming and VR/AR: Smaller, high-quality models are easier to send over the internet and run in real time on headsets or phones, making immersive experiences smoother and more widely available.
- Longer, richer content: Since scenes take much less space, creators can share longer videos or more detailed worlds without hitting memory limits.
- Building blocks for future methods: The idea of carefully selecting, pruning, merging, and compressing 4D blobs can be combined with other techniques (like visibility masks) to push speed and quality even further.
In short, OMG4 shows that you don’t need millions of blobs to get great-looking, real-time 4D scenes. With smart selection, merging, and compression, you can keep the magic while dropping the weight.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, articulated so future researchers can act on them:
- Dataset scope and diversity
- Evaluation is limited to N3DV and a single MPEG sequence (Bartender, first 65 frames); no results on longer-duration, higher-motion, or more varied dynamic content (e.g., occlusion-rich, highly specular, outdoor scenes, crowd scenes).
- FreeTimeGS results rely on reproduced models due to unavailable code/models; cross-method comparisons may be biased and are not fully reproducible.
- No experiments on other prominent 4D paradigms (e.g., deformation-based 4DGS baselines, anchor- or context-driven methods) to establish generality.
- Runtime and scalability characterization
- Training/preprocessing time, memory usage during optimization, and computational cost of each stage (SD-Score calculation across all frames/views, clustering/merging, staged SVQ) are not reported, leaving practical deployment budgets unquantified.
- Inference-time breakdown (rasterization vs. MLP inference vs. decompression) and energy consumption are missing, especially for real-time and mobile/edge scenarios.
- Attribute compression alone triggers OOM on full Real-Time4DGS (millions of Gaussians); the paper does not propose scalable block-wise, streaming, or hierarchical compression strategies that can handle large primitive counts without prior pruning.
- Hyperparameter sensitivity and adaptivity
- Fixed, globally applied hyperparameters (e.g., sampling ratio τ_GS, quantile thresholds τ_S/τ_T, similarity threshold τ_sim, grid sizes, merge rounds M, weight λ) lack sensitivity analyses; performance under different scene statistics and content types is unknown.
- No mechanism to adapt thresholds or grid sizes based on scene complexity, motion speed, or visibility patterns; an automatic, data-driven scheduler or meta-optimizer is not explored.
- Staged SVQ schedule (3D at 9k iterations, 4D at 10k) is fixed without justification or automatic tuning; how schedule impacts stability and final RD is unclear.
- SD-Score design and limitations
- Importance scoring uses gradients w.r.t. projected 2D coordinates and time; it ignores gradients w.r.t. opacity, covariance/scale, rotation, and higher-order SH/view-dependent attributes—potentially missing saliency in view-dependent or anisotropic regions.
- The signed temporal gradient is claimed to mitigate flicker, but there is no quantitative evaluation of temporal stability or flicker reduction to substantiate the claim.
- Computational overhead of SD-Score (accumulation across all frames/views) and its robustness to noise, occlusions, and visibility changes are not analyzed; approximate or visibility-aware saliency is not investigated.
- Gaussian merging design choices
- Similarity Score uses only position and zero-th order SH (RGB) with a fixed λ; it ignores covariance/shape, opacity, rotation, higher SH/view dependence, and temporal attribute differences—risking merges that degrade geometry or view-dependent effects.
- Merging sets non-position/non-color attributes to the representative Gaussian (a_r(C_q)); weighted blending or uncertainty-aware fusion of covariance/opacity/rotation is not explored.
- Clustering relies on a fixed spatio-temporal grid; no analysis of grid resolution effects, temporal binning strategy, or adaptive/learned neighborhood definitions.
- No assessment of artifacts introduced by merging (ghosting, softened edges, temporal lag), nor diagnostics that quantify when merging is harmful.
- Temporal fidelity and perceptual quality
- Only per-frame PSNR/SSIM/LPIPS are reported; no temporal metrics (e.g., tLPIPS, warping error, temporal SSIM) or user studies to quantify flicker, temporal coherence, or VR/AR visual comfort.
- No analysis of motion-specific failure cases (fast motion, topological changes, occlusions appearing/disappearing), or view-dependent/specular/reflection-heavy scenarios.
- Rate–distortion and bit allocation
- No per-attribute storage breakdown or bit allocation analysis (means, covariance, SH, opacity, rotation, temporal scales, MLP params); targeting high-impact components is difficult without this.
- Codebook sizes and SVQ partitioning are inherited from prior work; end-to-end, learned rate–distortion optimization (e.g., learned entropy models, rate-aware training) is not explored.
- Huffman+LZMA are generic compressors; potential gains from learned entropy coding or scene-aware probabilistic models remain unexplored.
- Quantization of means and geometric fidelity
- Means are kept in full precision “for stability”; strategies to safely quantize means (e.g., predictive coding, multi-resolution anchoring, error-bounded quantization) are not studied, leaving potential storage savings untapped.
- No geometric accuracy metrics (e.g., surface/occupancy error, boundary sharpness) to quantify how pruning/merging/quantization affect scene geometry and occlusion boundaries.
- Visibility masking and gating
- Visibility masks (e.g., 4DGS-1K’s approach) are acknowledged as boosting FPS but deemed out-of-scope; integrating visibility-aware gating with OMG4 while preserving quality is an open direction.
- Training-from-scratch under compression constraints
- The pipeline is post-hoc compression of pretrained models; joint training from scratch with compression-aware objectives (e.g., sparsity/merging priors, rate penalties) is not investigated, which could further improve RD and stability.
- Implementation details and reproducibility gaps
- Missing specifics on clustering deduplication (subset removal criteria), weight initialization/regularization for w_ix and w_if, normalization schemes, and optimization stability safeguards.
- The appendix is referenced for merging details but not provided; this hampers exact replication and targeted improvements.
- Deployment and streaming considerations
- No evaluation on mobile/embedded hardware or latency under decompression and MLP inference; hardware-aware model designs and acceleration strategies are not addressed.
- The bitstream structure (chunking, random access, progressive refinement, scene updates) and integration with streaming protocols remain unspecified, despite targeted use-cases (VR/AR, free-viewpoint video).
- Failure analysis and diagnostics
- The paper hypothesizes that sampling/pruning acts as a regularizer but does not provide diagnostics identifying “noisy” Gaussians or conditions under which pruning harms detail; guidelines and detectors for risky merges/prunes are absent.
Practical Applications
Immediate Applications
- Real-Time View Synthesis in VR/AR
- Sector: Virtual Reality/Augmented Reality
- Description: The method can be deployed immediately for real-time photorealistic scene rendering in VR and AR applications, reducing the storage size and improving rendering speed.
- Tools/Products: VR headsets, AR glasses that require real-time rendering for immersive environments.
- Assumptions/Dependencies: Requires sufficient computational power for real-time processing and compatible devices for deployment.
- Free-Viewpoint Video Streaming
- Sector: Media and Entertainment
- Description: Leveraging OMG4 can enhance free-viewpoint video streaming by significantly reducing the data size while maintaining visual fidelity.
- Tools/Products: Streaming platforms that provide interactive viewing experiences, gaming consoles.
- Assumptions/Dependencies: Assumes widespread network infrastructure capable of handling interactive streaming.
Long-Term Applications
- Autonomous Driving Simulation
- Sector: Automotive
- Description: Potential application in autonomous driving for simulating realistic 4D environments with reduced memory and computational requirements.
- Tools/Products: Autonomous driving training systems, simulation software.
- Assumptions/Dependencies: Further research needed on the integration with existing autonomous driving frameworks and real-world scenario databases.
- Enhanced Visual Odometry Systems
- Sector: Robotics
- Description: The approach could improve the precision and efficiency of visual odometry systems, aiding in navigation and mapping.
- Tools/Products: Drones, autonomous robots.
- Assumptions/Dependencies: Requires advancements in real-time scene understanding and more robust implementations for varying environments.
- Education and Training Simulators
- Sector: Education
- Description: Using OMG4 in educational simulators could provide students with realistic and interactive learning environments.
- Tools/Products: Educational VR platforms, training programs.
- Assumptions/Dependencies: Development of pedagogy-appropriate content and wider adoption of VR headsets in educational settings.
This structured approach identifies both immediate and potential future applications of the research, based on the improvements in dynamic scene representation and rendering described in the paper. Each application points toward likely sectors where benefits can be realized, contingent on certain dependencies and assumptions.
Glossary
- 3D Gaussian Splatting (3DGS): A rendering and scene representation technique that uses many anisotropic 3D Gaussian primitives to achieve real-time, high-fidelity novel view synthesis. "3D Gaussian Splatting (3DGS) enables high-fidelity scene reconstruction with real-time rendering, using 3D Gaussians as fundamental primitives."
- 4D Gaussian Splatting: An extension of Gaussian splatting that models both space and time to represent dynamic scenes for real-time rendering. "4D Gaussian Splatting has emerged as a new paradigm for dynamic scene representation, enabling real-time rendering of scenes with complex motions."
- Anchor-based structure: A representation that organizes local primitives around learned anchor points to reduce redundancy and enable compact modeling. "ADC-GS adopts an anchor-based structure and hierarchical approach for modeling motions at various scales"
- Anisotropic 4D covariance: A covariance matrix with directionally dependent variances in 4D (space-time), defining the shape/orientation of a 4D Gaussian. "defined by a 4D mean at spatio-temporal space, an anisotropic 4D covariance, an opacity, and spherical harmonics (SH) coefficients."
- Attribute compression: Techniques that reduce storage of per-primitive attributes (e.g., color, opacity, rotation) while maintaining rendering quality. "followed by attribute compression."
- Deformation field: A learned mapping that displaces canonical primitives over time to model motion in dynamic scenes. "Deformation-based methods employ a canonical set of 3D Gaussians and learns a deformation field that predicts per-primitive displacement and maps canonical primitives to each time step"
- Deformation-based approach: Methods that represent dynamics by deforming static 3D primitives over time rather than optimizing them directly in 4D. "ADC-GS adopts an anchor-based structure and hierarchical approach for modeling motions at various scales to compress a deformation-based approach (e.g., \citep{4dgs})."
- Free-viewpoint video: Video representations enabling rendering from arbitrary viewpoints at any time, often requiring spatio-temporal coherence. "such as free-viewpoint video"
- Gaussian Merging: A stage that clusters and fuses similar Gaussians into representative proxies to further reduce redundancy. "and (3) Gaussian Merging to fuse primitives with similar characteristics."
- Gaussian primitives: The basic elements (Gaussians with position, covariance, opacity, and appearance) used to represent scenes. "optimizes a set of 4D Gaussian primitives, extending 3D Gaussians to the time axis for temporally varying appearance"
- Gaussian Pruning: A stage that removes low-importance or redundant Gaussians based on thresholded importance scores. "and (2) Gaussian Pruning to remove redundancies"
- Gaussian Sampling: A selection step that retains only salient Gaussians according to an importance score to reduce model size with minimal quality loss. "Gaussian Sampling to identify primitives critical to reconstruction fidelity"
- Hash grid: A spatial encoding that uses hashing to efficiently map coordinates to learned features, capturing local coherence at multiple scales. "HAC leverages a hash grid to capture spatial consistencies among the anchors."
- Huffman encoding: A lossless entropy coding algorithm applied to further compress quantized model data. "Finally, we compress the quantized elements using Huffman encoding"
- Implicit appearance modeling: Using learned functions (e.g., MLPs) to predict appearance attributes from compact latent features rather than storing them explicitly. "we incorporate implicit appearance modeling and generalize Sub-Vector Quantization (SVQ) to 4D representations"
- LZMA compression: A lossless compression algorithm (Lempel–Ziv–Markov chain algorithm) used after entropy coding for additional size reduction. "followed by LZMA compression"
- Multi-layer perceptron (MLP): A small neural network used to predict per-Gaussian attributes (e.g., opacity, color) from features and coordinates. "predicts their attributes with lightweight MLPs"
- Novel view synthesis: Rendering new viewpoints of a scene from a learned representation without explicit geometry reconstruction. "3D novel view synthesis and reconstruction"
- Opacity: A per-primitive attribute controlling transparency, influencing compositing during rendering. "defined by a 4D mean at spatio-temporal space, an anisotropic 4D covariance, an opacity, and spherical harmonics (SH) coefficients."
- Photorealistic novel view synthesis: High-fidelity novel view synthesis that closely matches real-world appearance and lighting. "enabling photorealistic novel view synthesis in real time."
- Rasterization: The process of projecting and compositing Gaussians into image space during rendering. "only those Gaussians are involved in rasterization, thereby dramatically reducing computational costs."
- Rate-distortion curve: A plot showing the trade-off between storage/bitrate (rate) and reconstruction error (distortion) across methods. "The rate-distortion curve shows that OMG4 achieved significant improvements over recent state-of-the-art methods"
- Rotation quaternion: A four-parameter representation of rotation used for compact and stable orientation encoding of Gaussians. "including the additional rotation quaternion and temporal-axis scales introduced in Real-Time4DGS to model scene motion."
- Similarity Score: A measure combining spatial and appearance proximity to cluster Gaussians for merging. "We define a Similarity Score to quantify the similarity among Gaussians"
- Spatio-temporal coherence: Consistency of appearance and geometry across space and time, crucial for stable dynamic rendering. "where spatio-temporal coherence and real-time rendering are crucial."
- Spatio-temporal grid: A 4D partitioning of space-time used to limit clustering/merging to locally coherent Gaussians. "Such a spatio-temporal grid can group Gaussians with temporal proximity, preventing the merging of temporally mismatched Gaussians and preserving temporal coherence"
- Spherical harmonics (SH) coefficients: Coefficients of basis functions on the sphere used to model view-dependent radiance efficiently. "defined by a 4D mean at spatio-temporal space, an anisotropic 4D covariance, an opacity, and spherical harmonics (SH) coefficients."
- Static–Dynamic Score (SD-Score): A hybrid importance metric combining spatial (static) and temporal (dynamic) gradient sensitivities to rank Gaussians. "we propose the StaticâDynamic Score (SD-Score), which combines a Static Score and a Dynamic Score to quantify each Gaussianâs contribution."
- Sub-Vector Quantization (SVQ): A quantization method that splits vectors into sub-vectors and quantizes each with small codebooks for higher compression efficiency. "we integrate implicit appearance compression and generalize Sub-Vector Quantization (SVQ) to 4D representations"
- Temporal-axis scales: Scale parameters along the time dimension used to model motion-dependent shape changes of Gaussians. "including the additional rotation quaternion and temporal-axis scales introduced in Real-Time4DGS to model scene motion."
- Vector Quantization (VQ): A compression technique that maps vectors to the nearest codebook entries to reduce storage. "adopts a learnable mask to remove unnecessary Gaussians and vector quantization (VQ) to condense geometry attributes."
- Visibility mask: A per-timestep selection that restricts rendering to Gaussians visible at that time, accelerating rendering. "due to its visibility mask, which identifies the visible Gaussians at a given timestamp , and only those Gaussians are involved in rasterization"
- Zero-th order spherical-harmonics (RGB) coefficient: The constant (order-0) SH term representing the view-independent color component of a Gaussian. "and is the zero-th order spherical-harmonics (RGB) coefficient of ."
Collections
Sign up for free to add this paper to one or more collections.

