- The paper introduces a multi-teacher knowledge distillation framework to compress 3D Gaussian Splatting models while improving novel view synthesis quality.
- It employs diverse teacher models and spatial distribution loss to achieve up to 0.62 dB PSNR improvement and an 86–89% reduction in Gaussian primitives.
- The approach enables real-time, memory-efficient rendering, making it ideal for VR/AR and mobile applications with high fidelity.
Distilled-3DGS: Multi-Teacher Knowledge Distillation for Efficient 3D Gaussian Splatting
Introduction
Distilled-3DGS introduces a multi-teacher knowledge distillation framework for 3D Gaussian Splatting (3DGS), targeting the dual objectives of high-fidelity novel view synthesis and significant reduction in memory/storage requirements. The method leverages ensembles of teacher models—standard, noise-perturbed, and dropout-regularized 3DGS variants—to supervise a compact student model. The framework addresses the unique challenges posed by the explicit, unstructured nature of 3DGS representations, including unordered Gaussian primitives and scene-dependent distributions, by proposing geometry-aware distillation strategies and a spatial distribution consistency loss.
Multi-Teacher Distillation Framework
The core architecture of Distilled-3DGS consists of two stages: (1) training diverse teacher models and (2) distilling their knowledge into a lightweight student model.
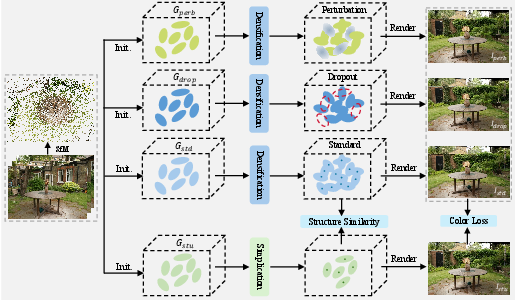
Figure 1: The architecture of multi-teacher knowledge distillation framework for 3DGS, showing the two-stage process and the integration of spatial distribution distillation.
Teacher Model Diversity
Three teacher models are trained independently:
- Standard 3DGS (Gstd): Optimized with photometric and structural similarity losses.
- Perturbed 3DGS (Gperb): Gaussian parameters are randomly perturbed during training, enhancing robustness to input variations.
- Dropout 3DGS (Gdrop): Gaussian primitives are randomly deactivated during training, promoting distributed scene representation and generalization.
Each teacher model produces high-quality, dense point clouds, which are subsequently fused to generate pseudo-labels for student supervision.
Student Model Training
The student model is pruned aggressively using importance scores (e.g., Mini-Splatting criteria), resulting in a much sparser set of Gaussians. Supervision is provided via:
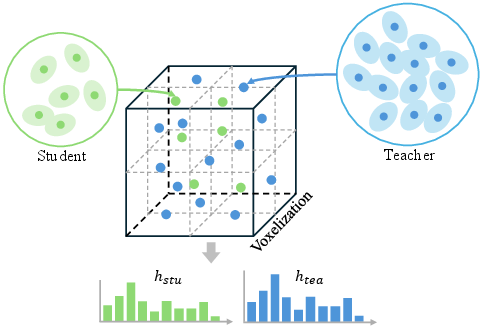
Spatial Distribution Distillation
Direct point-wise correspondence is infeasible due to the unordered and variable nature of Gaussian primitives. Instead, the method discretizes the 3D space into voxels and computes occupancy histograms for both teacher and student point clouds. The cosine similarity between normalized histograms serves as the structural loss, robustly capturing global and local geometric consistency regardless of point density or sampling noise.
Experimental Results
Distilled-3DGS is evaluated on Mip-NeRF360, Tanks and Temples, and Deep Blending datasets. The method consistently achieves superior rendering quality and storage efficiency compared to both NeRF-based and 3DGS-based baselines.

Figure 3: Visualized comparison on the Bicycle, Garden, and Kitchen scenes, demonstrating superior detail preservation by Distilled-3DGS.
Key quantitative results:
- PSNR improvements: +0.55 dB (Mip-NeRF360), +0.62 dB (Tanks and Temples), +0.46 dB (Deep Blending) over vanilla 3DGS.
- Gaussian reduction: 86–89% fewer Gaussians than vanilla 3DGS, with comparable or better fidelity.
- SSIM and LPIPS: Consistently higher SSIM and lower LPIPS, indicating improved structural and perceptual quality.
Ablation studies confirm the complementary benefits of teacher diversity and the critical role of spatial distribution distillation. Removal of either the perturbation or dropout teacher, or the structural loss, leads to measurable drops in PSNR and perceptual quality.

Figure 4: Visual comparison with different teacher models, highlighting the degradation in rendering quality when teacher diversity is reduced.
Implementation Considerations
- Training Overhead: Multi-teacher distillation requires pre-training several high-capacity teacher models, increasing computational and memory demands by a factor of N (number of teachers).
- Student Model Efficiency: The student model achieves real-time rendering and is suitable for deployment on resource-constrained devices due to its compactness.
- Structural Loss Scalability: Voxel grid resolution impacts both memory usage and structural fidelity; higher resolutions yield better quality at increased computational cost.
- Generalization: The framework is robust to scene complexity and point density variations, making it applicable to a wide range of real-world scenarios.
Theoretical and Practical Implications
Distilled-3DGS demonstrates that knowledge distillation can be effectively adapted to explicit, unstructured 3D representations, overcoming the limitations of conventional KD approaches reliant on latent feature spaces. The spatial distribution distillation strategy provides a generalizable mechanism for structure-aware supervision in point-based models. Practically, the method enables high-quality view synthesis with minimal storage, facilitating deployment in VR/AR, robotics, and mobile applications.
Future Directions
Potential avenues for further research include:
- End-to-End Distillation: Integrating teacher and student training into a unified pipeline to reduce training overhead.
- Adaptive Pruning: Dynamic adjustment of Gaussian counts during training for optimal trade-off between quality and efficiency.
- Generalization to Other Representations: Extending spatial distribution distillation to other explicit 3D representations (e.g., meshes, voxels).
Conclusion
Distilled-3DGS establishes a robust framework for compressing 3DGS models via multi-teacher knowledge distillation and spatial distribution consistency. The approach achieves state-of-the-art rendering quality with drastically reduced memory requirements, validated across diverse datasets and scene types. The method's scalability and efficiency position it as a practical solution for real-time, memory-constrained 3D scene synthesis, with promising directions for further optimization and generalization.