- The paper introduces SkipGS which selectively skips redundant backward passes based on per-view loss deviation, saving up to 42% training time.
- The method employs a plug-and-play view-adaptive gating mechanism with a minimum backward budget to maintain optimization stability.
- Experimental results across benchmark datasets show SkipGS accelerates training without compromising reconstruction quality, with negligible changes in PSNR, SSIM, and LPIPS.
SkipGS: Efficient Post-Densification Backward Skipping for 3D Gaussian Splatting
Motivation and Problem Statement
3D Gaussian Splatting (3DGS) has emerged as a state-of-the-art approach for real-time novel-view synthesis, leveraging millions of anisotropic Gaussians with a differentiable rasterizer. While real-time rendering is efficient, training remains computationally expensive, especially during the post-densification refinement phase, where the backward pass—required for gradient updates—dominates the runtime.
Profiling standard 3DGS pipelines reveals a significant redundancy in the post-densification phase: most sampled views have nearly plateaued losses and contribute little additional gradient information, but full backpropagation is still performed at every iteration. This leads to substantial wasted computation, constraining practical deployment in interactive scene capture, benchmarking, and pipelines requiring repeated scene fitting.
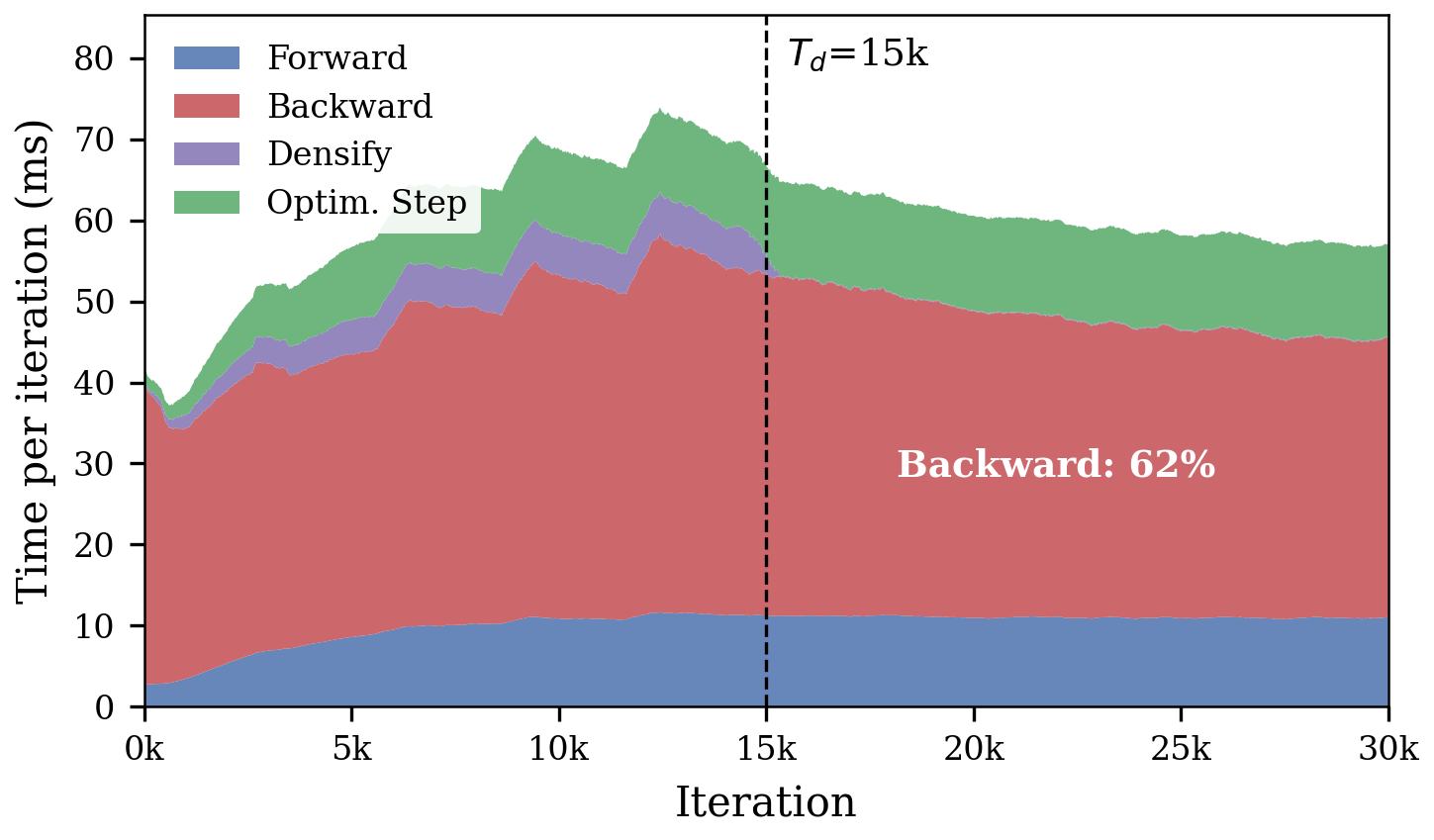
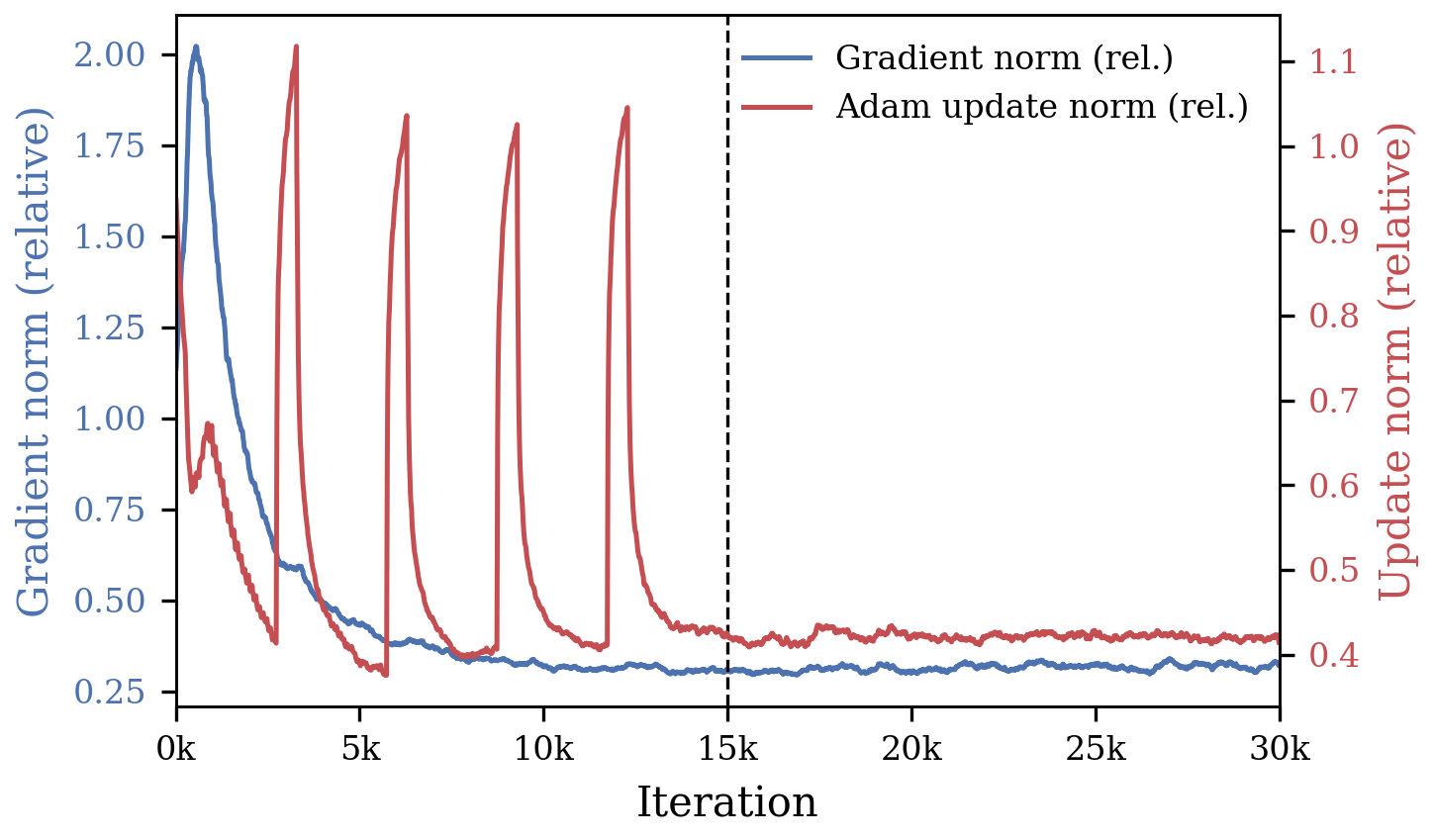
Figure 1: The backward pass dominates per-iteration runtime after densification; post-densification gradients become nearly flat, while optimizer updates remain stable, indicating the prevalence of redundant backward passes.
SkipGS: View-Adaptive Backward Gating
SkipGS addresses this inefficiency by introducing a view-adaptive backward gating mechanism during post-densification. The key aspects of the method are:
- Per-View Deviation Score: For every sampled view, an exponential moving average (EMA) of loss is tracked. A deviation score is computed as the ratio between the current loss and recent EMA baseline. If the deviation exceeds one—signifying loss increase—the backward pass is executed; otherwise, it is tentatively skipped.
- Minimum Backward Budget: To prevent the optimizer from being starved of meaningful gradient signals, a strict minimum backward pass schedule is maintained. During a short warmup phase, the backward ratio for each view is measured to adaptively calibrate the minimum required number of backpropagations.
- Plug-and-Play Design: SkipGS modifies only the schedule for backward passes—not the renderer, representation, or loss function. This orthogonality ensures compatibility with other 3DGS acceleration techniques, enabling additive speedups.
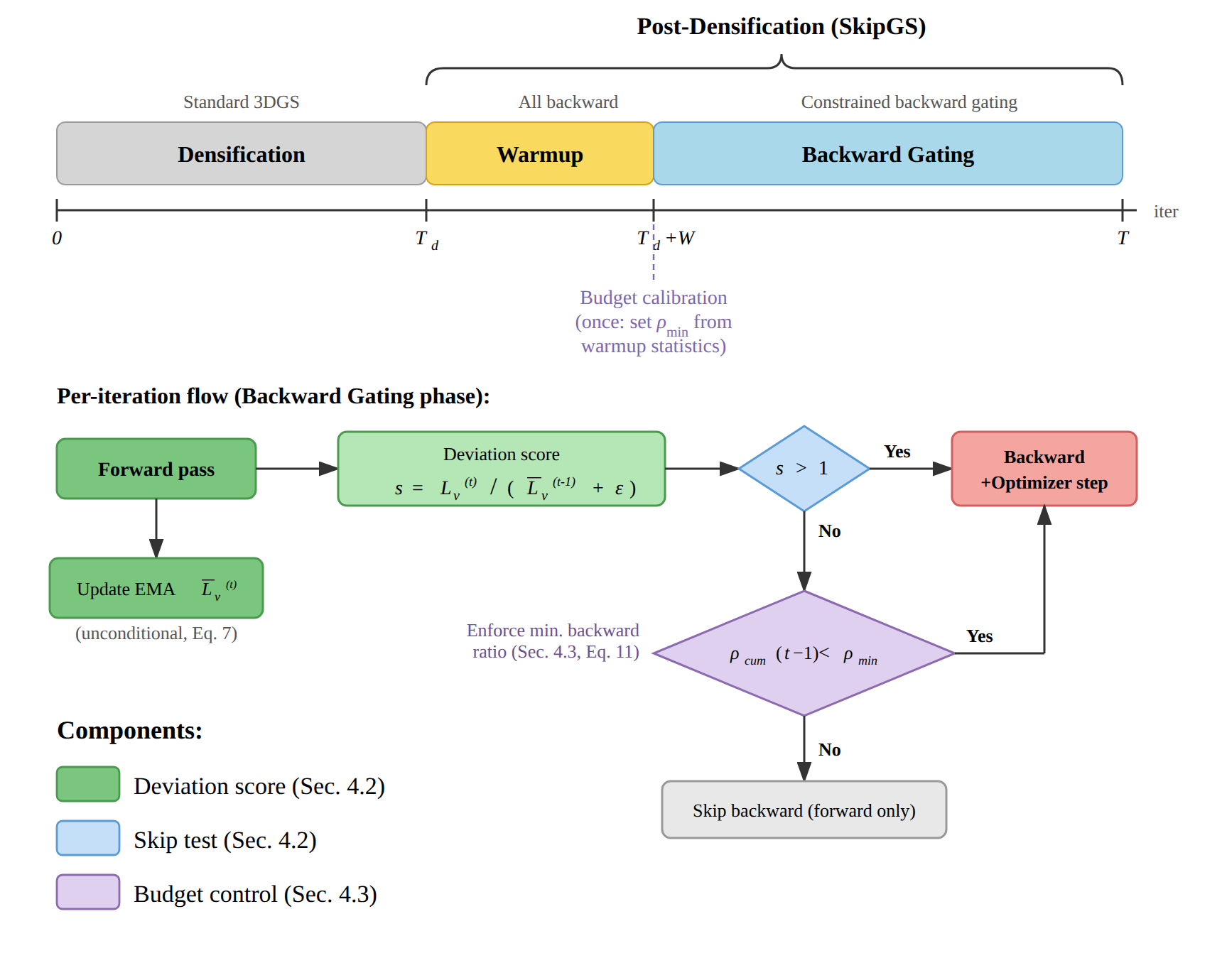
Figure 2: SkipGS workflow: after densification, a warmup window calibrates backward schedule; per-iteration, a decision is made to execute or skip the backward pass based on view loss statistics and a minimum budget.
Experimental Results
SkipGS is validated across Mip-NeRF 360, Deep Blending, and Tanks and Temples datasets, comparing both vanilla and accelerated 3DGS pipelines. The method is also composed with state-of-the-art efficiency techniques—e.g., FastGS, GaussianSpa, LightGaussian, Speedy-Splat, and Taming 3DGS—demonstrating further wall-clock reductions without compromising reconstruction quality.
Acceleration Without Quality Loss
- On Mip-NeRF 360, SkipGS reduces end-to-end training time by 23.1% (42.0% for post-densification) versus vanilla 3DGS, with negligible impact on reconstruction quality (PSNR/SSIM/LPIPS within ±0.02, Table 1).
- Across all tested pipelines and datasets, SkipGS delivers consistent wall-clock reductions in both full and post-densification training—with typical speedups between 5–27%, depending on base efficiency.
- Importantly, final Gaussian set sizes and rendering costs remain unchanged; all speedups are attributable to backward pass gating alone.




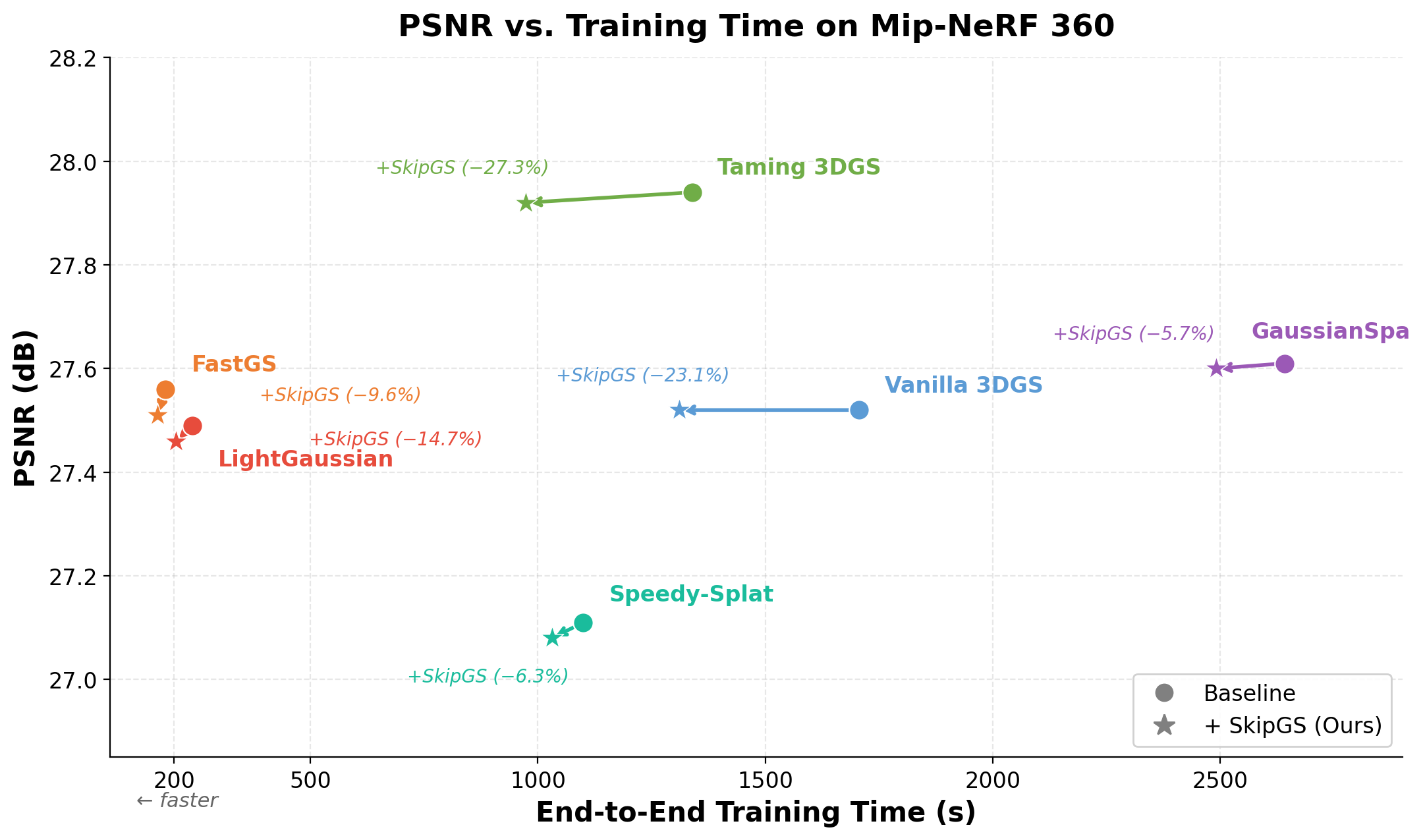
Figure 3: SkipGS accelerates diverse 3DGS pipelines with negligible quality loss. Left: Qualitative results for Mip-NeRF 360, visually indistinguishable from baselines. Right: PSNR vs. training time for six baselines, showcasing time savings.
Qualitative Analysis
Rendered outputs across datasets and various efficiency baselines reveal that results of SkipGS-augmented pipelines are visually indistinguishable from their full backward counterparts, confirming that loss-driven core updates are not neglected despite aggressive skipping.



Figure 4: Qualitative comparison across datasets and baselines: SkipGS preserves output fidelity despite substantial post-densification time reductions.
Ablation Study
Disabling the minimum backward budget causes excessive skipping—leading to marked degradation in PSNR, SSIM, and LPIPS. The budget controller preserves optimization stability with only a minor increase in compute, confirming its critical role in balancing speed and quality.
Implications and Future Directions
The primary contribution of SkipGS is a principled schedule for post-densification backward passes, leveraging empirical findings that many per-view losses stabilize quickly, rendering further per-view backpropagation unnecessary for convergence.
Implications include:
- Plug-and-Play Efficiency: SkipGS complements orthogonal acceleration approaches—pruning, compaction, densification control—yielding stackable improvements without re-engineering the 3DGS pipeline.
- Resource-Efficient Fitting: Large-scale or resource-constrained settings (e.g., mobile, real-time capture) benefit directly by achieving faster convergence and high-quality renders at lower compute cost.
- Adaptive Learning Schedules: The architecture-agnostic gating mechanism suggests generalizability to other multi-view, redundancy-rich optimization paradigms.
- Scalability: By reducing the backward pass frequency, distributed and large-batch training paradigms could capitalize on even greater wall-clock savings.
Future research may extend such view-adaptive gating to earlier phases, consider dynamic granularity (e.g., primitive- or region-level gating), or integrate more sophisticated convergence prediction models to further sharpen compute focus. Additionally, synergistic use with emerging compact scene representations or hybrid neural-field architectures warrants examination.
Conclusion
SkipGS introduces a post-densification, per-view backward gating scheme that selectively skips redundant backward passes in 3D Gaussian Splatting training, achieving substantial training acceleration while preserving reconstruction quality. By constraining this process with a minimum backward budget, SkipGS avoids optimization instability. The method is fully orthogonal to current acceleration strategies, enabling their seamless composition. These results demonstrate a practical path toward scalable, efficient novel-view synthesis using point-based radiance field methods.
Reference: "SkipGS: Post-Densification Backward Skipping for Efficient 3DGS Training" (2603.08997)