- The paper introduces an information density-driven masking paradigm that selectively targets high-information tokens using a smart noise scheduler.
- It employs LLM-based extraction and complementary masking to generate paired logical and syntactic samples for improved reasoning.
- Experimental results show up to a 7% boost in benchmark performance with minimal annotation, highlighting efficiency in diffusion LLM training.
Motivation and Problem Statement
Traditional diffusion LLMs (DLLMs) optimize denoising by applying a uniform random mask, agnostic to the information density within input sequences. This results in suboptimal allocation of optimization resources: high-entropy regions, such as logical pivot points in code or core mathematical operations in math reasoning tasks, are under-trained, while low-density syntactic glue receives disproportionate attention. The work introduces an Information Density Driven Smart Noise Scheduler that systematically prioritizes noise injection into information-dense spans, extracted through rule-based or LLM-guided identification. The approach employs Complementary Priority Masking, generating paired logical and syntactic samples by logical inversion of masks, ensuring effective learning of deep reasoning and structural language properties.
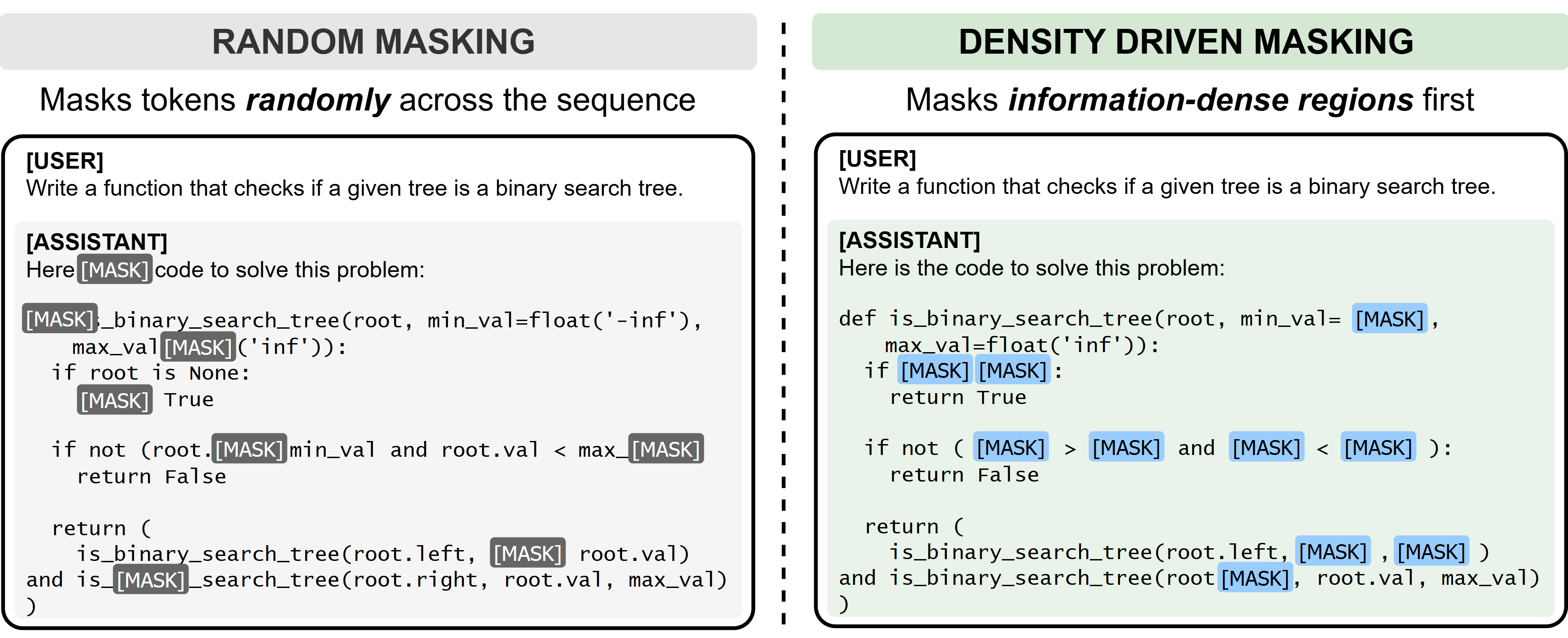
Figure 1: Comparison between random masking and density driven masking demonstrates targeted allocation of masking to information-rich regions.
Methodology: Extraction and Scheduling
The pipeline commences with LLM-based Information-Dense Region Extraction. For each sample, a binary indicator vector C∈{0,1}N classifies tokens by their information density; regions of interest are identified using domain-adapted prompts (e.g., control flow and algorithmic pivots in code, intermediate and final results in math tasks). This extraction module is designed for plug-and-play extensibility, supporting future AST-based or confidence-driven extraction strategies.
Subsequent Complementary Priority Noise Scheduling applies a probabilistic masking distribution, modulated by bias weight w, assigning higher noise probabilities to information-dense regions. To maintain the scheduler's global noise ratio σt, base mask probability pbase is dynamically balanced. The complementary masking step duplicates the sample, generating logically opposed training pairs: XM (information-focused, with dense spans masked) and XMˉ (structure-focused, with grammatical glue masked). This decouples optimization into two mutually reinforcing trajectories: deep deduction and syntactic structuring.
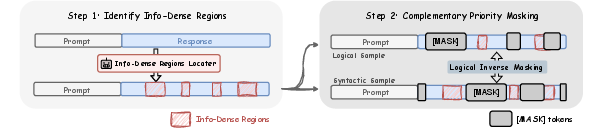
Figure 2: Workflow of the Information Density Driven Noise Scheduler: dense-region extraction is followed by logical and syntactic sample generation with complementary masking.
Experimental Evaluation
The experimental setup utilizes LLaDA-2.0-mini as the backbone, trained on a code/math blend (OPC-SFT-Stage2 and GSM8K datasets, ~450K samples) with critical logic spans extracted from subsets using GPT-4o. Average proportion of information-dense regions per sample is reported (ρcode≈0.25, ρmath≈0.31).
Supervised fine-tuning reveals that density-driven mask scheduling achieves a 4% absolute increase in average accuracy across four code and math benchmarks compared to random masking, with pronounced gains in HumanEval (+7.31%) and MATH500 (+6.20%). Ablation studies dissect the impact of bias weight w—moderate values (w=2, w=0.5) yield optimal results, and empirical data confirms the theoretical symmetry between w and $1/w$ when complementary masking is used.
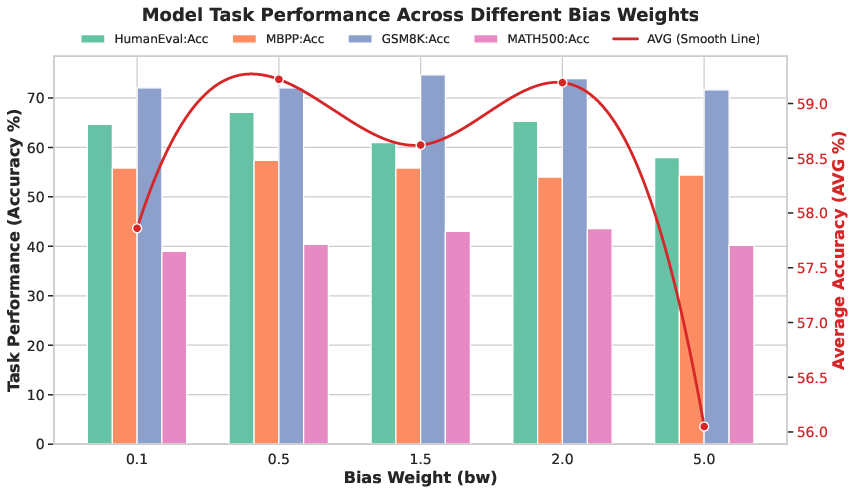
Figure 3: The impact of bias weight w on performance, showing optimal scores at w=2 and w=0.5 via density-aware masking.
Hard priority masking (w→∞) creates large contextual voids and induces collapse in block diffusion training, validating the necessity for probabilistic soft priority masking. Data scaling studies indicate that annotating as little as 10\% of the training set with dense-region masks suffices for substantial performance gains, and over-annotation induces domain shift and reduced generalization.
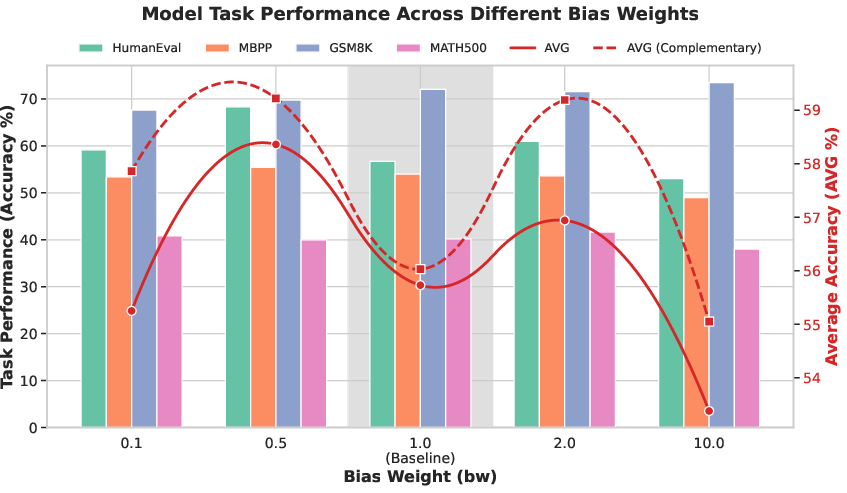
Figure 4: Comparison of performance with and without complementary masking, highlighting distribution asymmetry and superior outcomes from paired logical-syntactic masking.
Implications and Future Directions
The method efficiently unlocks enhanced reasoning capabilities in DLLMs while minimizing annotation cost. It exposes critical dynamics in block diffusion training, notably contextual collapse under deterministic masking and mathematical symmetry in joint probability modeling under complementary views. Practically, this paradigm enables targeted fine-tuning of DLLMs for complex reasoning tasks in code and mathematics, with minimal data engineering overhead.
Theoretically, density-driven masking reframes denoising objectives from uniform token-wise reconstruction to conditional modeling of logical and syntactic structures, suggesting new directions for self-interpreting mask networks and domain-adaptive extraction modules. Future work may focus on end-to-end learnable masking, integrated AST analysis for code, or adaptive masking by loss landscape and model confidence, eliminating dependence on external LLMs.
Conclusion
This work surpasses the limitations of uniform noise scheduling by introducing an information-density-aware masking paradigm tailored for discrete DLLMs. Through systematic identification and targeted masking of information-dense spans, coupled with complementary decoupling, it substantially improves supervised fine-tuning efficiency and generalization—evidenced by strong numerical results on reasoning benchmarks. The mechanistic insights into block diffusion optimization, and the demonstrated data efficiency, establish this mask-centric framework as a promising foundation for future research in diffusion-driven NLP.

