- The paper introduces the GS-Adapter, which fuses input-view diffusion features with 3D Gaussian-rendered features to ensure structural consistency.
- The methodology lifts diffusion features into 3D space and applies adaptive cross-attention and gating to reduce multi-view inconsistencies and camera pose errors.
- Empirical results demonstrate significant improvements in PSNR, translation error, and Chamfer Distance over existing methods, establishing robust novel view synthesis.
Geometry-Grounded Diffusion for Robust Novel View Synthesis
Motivation and Problem Statement
Novel View Synthesis (NVS) aims to generate photorealistic images from unseen camera viewpoints, maintaining strict geometric coherence absent in the observed imagery. Conventional methods—NeRF, 3D Gaussian Splatting (3D-GS)—are constrained by dense-view requirements and suffer from overfitting when presented with sparse inputs, with their generalization restricted to viewpoints proximate to the reference. Feed-forward geometry methods and generative approaches based on video diffusion models have advanced the state-of-the-art, but multi-view inconsistency and poor camera controllability remain unresolved, particularly in low-overlap and sparse-view scenarios. Integration of explicit geometry priors is recognized for improving structural consistency but prior techniques predominantly perform input-level fusion, which introduces artifacts due to view-dependent color noise, resulting in hallucinated structures.
GeoNVS and GS-Adapter: Architecture and Principle
GeoNVS addresses the geometric fidelity and controllability gap via feature-space coupling of geometry priors and video diffusion. The central innovation, the Gaussian Splat Feature Adapter (GS-Adapter), lifts input-view diffusion features to 3D Gaussians, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features, correcting geometrically inconsistent representations during the denoising trajectory.
The approach comprises three steps: uplift reference-view diffusion features onto 3D Gaussians, rasterize geometry-aware features via Gaussian splatting, and fuse the geometry-aware with original diffusion features using an adaptive gating mechanism. Feature-level modulation enables the diffusion model to be anchored to explicit 3D structure, significantly reducing view inconsistencies and improving camera pose adherence.
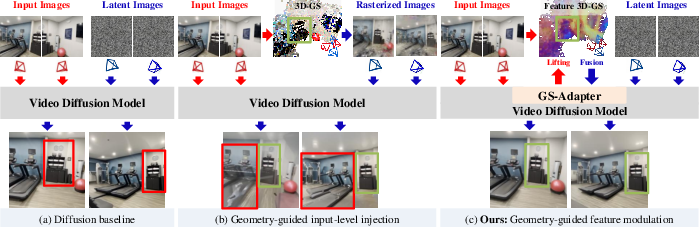
Figure 1: Geometry-guided generative NVS—GS-Adapter enables feature-space modulation, avoiding artifacts from input-level image fusion.
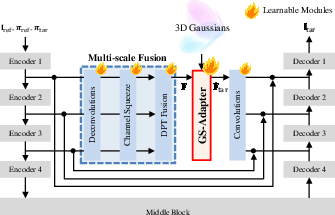
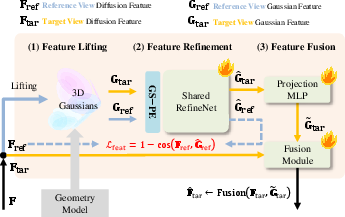
Figure 2: Architecture overview—GS-Adapter pipeline, including feature lifting, refinement, and adaptive fusion within the denoising loop.
Adaptive Feature Fusion and Robustness
GS-Adapter employs adaptive cross-attention and per-pixel gating, ensuring that unreliable geometric priors do not propagate errors. The residual formulation maintains original generative feature integrity unless structural guidance is locally trustworthy, while the gating function learns pixel-wise confidence. This plug-and-play module is compatible with diverse feed-forward geometry estimators and video diffusion models, and supports zero-shot generalization to new geometry backbones without retraining—contrasting prior works that are tightly coupled to specific geometry models.
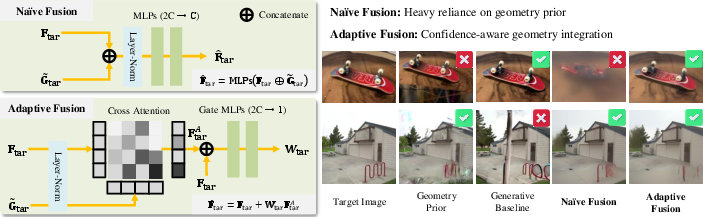
Figure 3: Feature fusion module—comparison of naive versus adaptive fusion, emphasizing robustness to unreliable geometric prior.
Empirical Evaluation
GeoNVS is benchmarked on SEVA and CameraCtrl diffusion backbones across 9 scenes and 18 settings. The model achieves 11.3% and 14.9% improvement in synthesis quality (PSNR) over SEVA and CameraCtrl, with up to 2× reduction in translation error and 7× in Chamfer Distance, evidencing superior geometric consistency and camera controllability. The model also extrapolates structural cues to non-co-visible regions, providing up to +2.08 dB PSNR improvements.
Notably, qualitative results illustrate significant gains in both appearance and spatial coherence on diverse datasets. Long-trajectory generation demonstrates consistent, non-flickering outputs, with performance scaling favorably as reference views increase.

Figure 4: Qualitative results of GeoNVS with SEVA highlight improved structural consistency and photometric stability.

Figure 5: GeoNVS integrated with CameraCtrl illustrates enhanced adherence to intended camera trajectories and reduced geometric distortions.
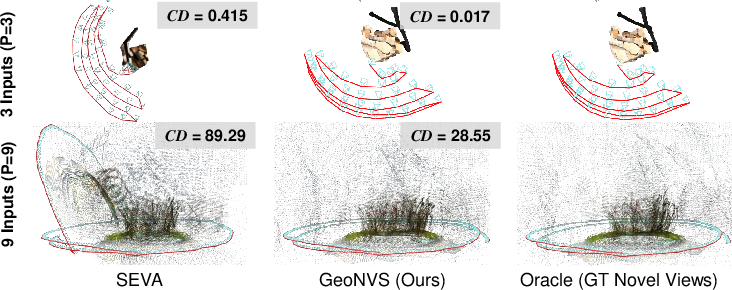
Figure 6: Visualized 3D reconstruction and camera trajectory from GeoNVS outputs, evidencing improved geometric fidelity.
Ablation Studies and Feature Analysis
GeoNVS's modular design allows evaluation of fusion strategies, geometry prior compatibility, loss components, and multi-scale aggregation. Results confirm that adaptive fusion is critical for robustness against unreliable priors, and explicit 3D structural cues (GS-PE, feature consistency loss) are essential for fine-grained detail recovery. Multi-scale feature integration further enhances synthesis quality.
Feature-level modulation via GS-Adapter is compared against input-level image injection, showing unequivocally that input-level fusion degrades both camera controllability and geometric consistency due to contaminating color noise. GS-Adapter's feature-space grounding consistently reduces pose errors and Chamfer Distance across all datasets, and is less sensitive to geometry prior quality.
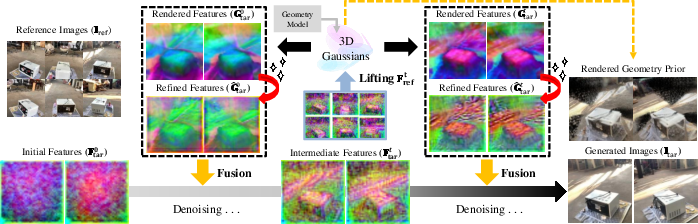
Figure 7: Feature modulation—GS-Adapter stages visualized during denoising, showing improved spatial structure anchoring.

Figure 8: Visualization of intermediate features—adaptive fusion balances geometric guidance and generative flexibility as denoising proceeds.
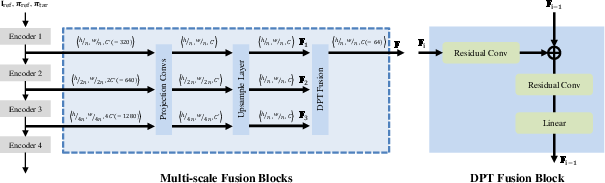
Figure 9: Multi-scale fusion module—hierarchical aggregation strategy for combining geometry-guided with diffusion features across spatial resolutions.
Practical Implications and Theoretical Contributions
GeoNVS's modularity enables seamless integration with arbitrary geometry models and video diffusion architectures, facilitating rapid adoption and enhanced robustness in downstream NVS systems. The approach's ability to extrapolate geometric priors to unseen regions extends the reach of structural guidance to inpainting and generalized synthesis. Pose-free operation via SfM methods further broadens applicability where intrinsic/extrinsic calibration is unavailable.
Runtime analysis demonstrates that inference overhead is principally tied to geometry prior complexity, but can be mitigated using voxel-based Gaussian pruning, achieving a 2.2× speedup at negligible performance cost.
Limitations and Future Directions
GeoNVS's synthesis fidelity is susceptible to degradation in regions significantly distant from input views, where feature rendering uncertainty increases. Thin structures and heavily occluded zones remain challenging due to incomplete geometric representation and insufficient prior guidance. Incorporation of uncertainty estimation for 3D-GS and advanced inpainting strategies are prospective avenues for further research.
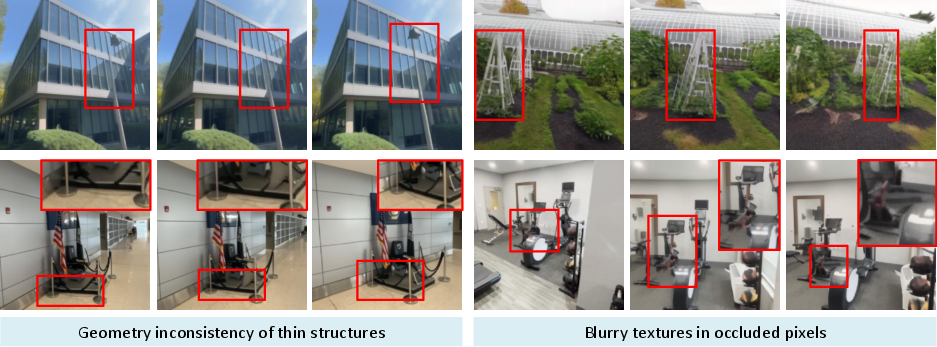
Figure 10: GeoNVS limitations—geometry inconsistency in thin structures and blurry textures in occluded regions highlight areas for improvement in 3D prior estimation.
Conclusion
GeoNVS exemplifies an effective architecture for geometry-grounded diffusion in novel view synthesis, substantially reducing multi-view inconsistencies and improving camera controllability. The GS-Adapter's feature-space modulation establishes robust structural anchoring within generative models, decoupling geometry prior dependency and enabling broad compatibility. Theoretical implications encompass principled integration of explicit geometry with video generative models, laying the groundwork for scalable, robust NVS under sparse and unconstrained views (2603.14965). Practical advances extend to efficient, pose-agnostic NVS, with demonstrated state-of-the-art performance across established benchmarks.
GeoNVS's framework and methodological insights are likely to inform the design of future generative vision models targeting robust, structure-consistent image and video synthesis in high-dimensional settings.